Batch Normalization to accelerate neural network learning
In the modern world, neural networks find more and more applications in various fields of science and business. Moreover, the more complex the task, the more complex is the neural network.
Learning complex neural networks can sometimes take days and weeks for only one configuration. And in order to choose the optimal configuration for a specific task, it is required to start training several times - this can take months of calculations even on a really powerful machine.
At some point, while familiarizing myself with the Batch Normalization method from Google presented in 2015, for solving the problem of face recognition, I was able to significantly improve the speed of the neural network.
For details, I ask under the cat.
In this article I will try to combine two urgent tasks for today - this is the task of computer vision and machine learning. As I have already specified, Batch Normalization will be used as a neural network learning design to accelerate neural network learning. The training of the neural network (written using the Caffe library, which is popular within the computer vision), was conducted on the basis of 3 million faces of 14 thousand different people.
In my task, a classification into 14,700 classes was necessary. The base is divided into two parts: training and test samples. Known classification accuracy on the test sample: 94.5%. At the same time, this required 420 thousand iterations of training - which is almost 4 days (95 hours) on the NVidia Titan X video card.
Initially, for this neural network, some standard methods of learning acceleration were used:
- Increase learning rate
- Reducing the number of network parameters
- Change learning rate in the learning process in a special way
All these methods were applied to this network but then the ability to apply them came to naught, because began to decrease the accuracy of classification.
At this point, I discovered a new method of accelerating neural networks - Batch Normalization. The authors of this method tested it on the standard Inception network based on LSVRC2012 and got good results:
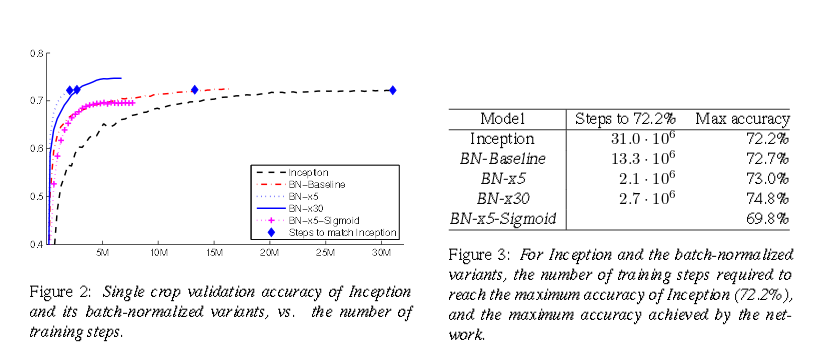
From the graph and the table it is clear that the network has learned 15 times faster and even achieved higher accuracy in the end.
What is Batch Normalization?
Consider a classic neural network with several layers. Each layer has multiple inputs and multiple outputs. The network is trained by the method of back propagation of the error, by the batch, that is, the error is considered for some subset of the training sample.
The standard method of normalization - for each k, consider the distribution of elements of the batch. Let us subtract the average and divide by the variance of the sample, obtaining the distribution with the center at 0 and the variance 1. Such a distribution will allow the network to learn faster, because all numbers are of the same order. But it is even better to introduce two variables for each attribute, summarizing the normalization as follows:

We obtain the mean, variance. These parameters will be included in the backpropagation algorithm.
Thus, we get a batch normalization layer with 2 * k parameters, which we will add to the architecture of the proposed network for face recognition.
The input to my task is a black and white image of a 50x50 pixel face. At the exit, we have 14,000 probability classes. The class with the maximum probability is considered the result of prediction.
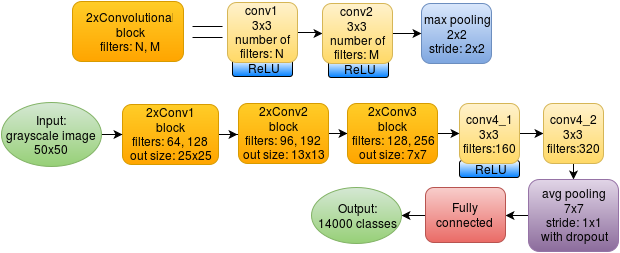
The original network looks like this:
8 convolutional layers are used, each 3x3 in size. After each convolution, ReLU: max (x, 0) is used. After a block of two bundles, there is a max-pooling with a cell size of 2x2 (without overlapping cells). The last pooling layer has a cell size of 7x7, which averages the values, but does not take the maximum. The result is an array of 1x1x320, which is served on a fully connected layer.
The network with Batch Normalization looks a bit more complicated:
In the new architecture, each block of two bundles contains a Batch Normalization layer between them. We also had to remove one convolutional layer from the second block, as the addition of new layers increased the memory consumption of the graphics card.
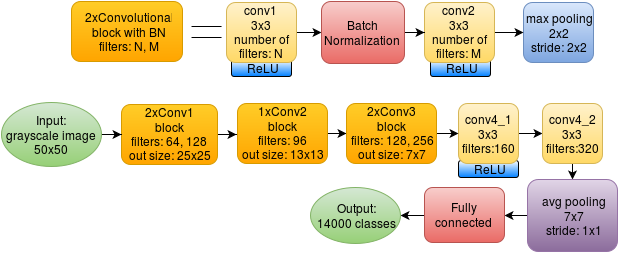
At the same time, I removed Dropout in accordance with the recommendations on the use of BN authors of the original article.
Experimental evaluation
The main metric is accuracy, we divide the number of correctly classified images by the number of all images in the test sample.
The main difficulty in optimizing a neural network with the help of the Batch Normalization layer is to select the learning rate and correctly change it during the network learning process. In order for the network to converge faster, the initial learning rate must be greater, and then decrease, so that the result is more accurate.
Several options for changing the rate of learning were tested:
| Name | Formula for changing learning rate | Iterations to 80% accuracy | Iterations to complete convergence | Maximum accuracy |
|---|---|---|---|---|
| original | 0.01 * 0.1 [ #iter / 150000] | 64000 | 420000 | 94.5% |
| short step | 0.055 * 0.7 [ #iter / 11000] | 45,000 | 180000 | 86.7% |
| multistep without dropout | 0.055 * 0.7 Nsteps | 45,000 | 230000 | 91.3% |
[x] - the whole part
#iter - iteration number
Nsteps - the steps specified manually at the iterations: 14000, 28000, 42000, 120000 (x4), 160000 (x4), 175000, 190,000, 210,000.
A graph showing the learning process: accuracy on a test sample depending on the number of iterations of neural network training performed:

The original network converges in 420000 iterations, and the learning rate for all time changes only 2 times at the 150000th iteration and at the 300000th. This approach was proposed by the author of the original network, and my experiments with this network showed that this approach is optimal.
But if the Batch Normalization layer is present, this approach gives poor results - the long_step graph. Therefore, my idea was to change the learning rate smoothly at the initial stage, and then make a few jumps (multistep_no_dropout schedule). The short_step chart shows that just a smooth change in the learing rate works worse. In fact, here I rely on the recommendations of the article and try to apply them to the original approach.
As a result of the experiments, I came to the conclusion that learning can be accelerated, but the accuracy will be a little worse anyway. You can compare the task of face recognition with the task described in the Inception articles ( Inception-v3 , Inception-v4 ): the authors compared the classification results for different architectures and it turned out that Inception-BN is still inferior to the new Inception versions without using Batch Normalization. In our problem, we get the same problem. But still, if the task is to get acceptable accuracy as quickly as possible, then BN can help: in order to achieve 80% accuracy, it takes 1.4 times less time compared to the original network (45000 iterations against 64000). This can be used, for example, for designing new networks and selecting parameters.
Software implementation
As I already wrote, in my work Caffe is used - a convenient tool for deep learning. Everything is implemented in C ++ and CUDA, which ensures optimal use of computer resources. For this task it is especially important, since if the program were not written optimally there would be no point in speeding up learning by changing the network architecture.
Caffe has a modularity - it is possible to connect any neural network layer. For the Batch Normalization layer, 3 implementations were found:
- BatchNorm in the original caffe (dated February 25, 2015)
- BN in caffe windows (from March 31, 2015)
- BatchNorm at CUDNN (November 24, 2015)
To quickly compare these implementations, I took the standard Cifar10 base and tested everything under the Linux x64 operating system using the NVidia GeForce 740M (2GB) graphics card, Intel® Core (TM) i5-4200U CPU @ 1.60GHz processor and 4GB RAM.
The implementation from caffe windows is built into the standard caffe, because tested under linux.
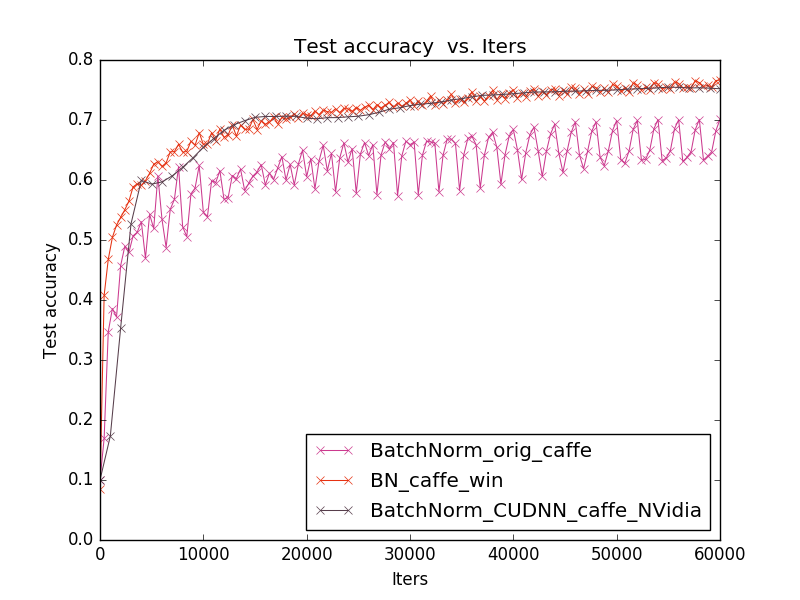
The graph shows that the 1st implementation is inferior to the 2nd and 3rd in accuracy, in addition, in the 1st and 2nd cases, the prediction accuracy changes jumps from iteration to iteration (in the first case, jumps are much stronger). Therefore, the 3rd implementation (from NVidia) was chosen as the most stable and newer for the facial recognition task.
These neural network modifications by adding layers of Batch Normalization show that it will take 1.4 times less time to achieve acceptable accuracy (80%).
')
Source: https://habr.com/ru/post/309302/
All Articles