ML boot camp 2016 new to TOP 10
Not so long ago, the machine learning competition from Mail.ru ended. I took the 9th place, and, in fact, I would like to share with you how it turned out for me. In short, lucky.

And so, a little about my experience:
1) In general, I am a PHP programmer, and I know very little about python, only by participating in the Russian AI Cup 2015 , where I first wrote on python and won a T-shirt;
2) At work, I solved one problem to determine the tonality of the text, using scikit-learn;
3) Began to take a course on coursera.org from Yandex, on machine learning.
')
This is where my experience with python and machine learning ends.
I put myself python3 and notebook, and began to deal with pandas from the tutorial . I uploaded data, fed random woods, and got ~ 0.133 at the output
Everything, on this thought about the solution of the problem ended.
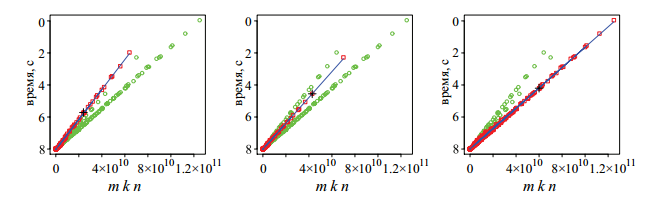
I return to the task, clinging to the line “ We have learned the idea of the problem from the work of A. A. Sidnev, V. P. Gergel ”. Actually, the book describes how to solve this problem. True, I did not understand how I could implement this idea, but I saw an interesting graph:
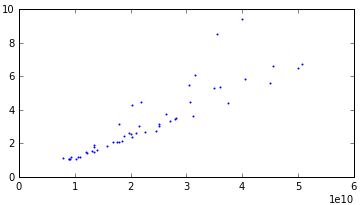
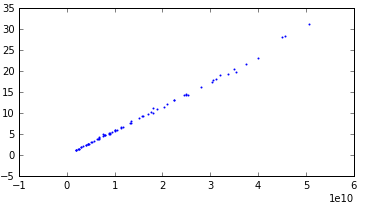
Hmm, but really, the dependence of time on the size of the matrices should be linear, I thought, and decided to see how things are with this with our data. Having grouped all the examples according to their characteristics, I found that there are only 92 groups. Having actually built graphs for each of the options, I saw that the half had a linear relationship with low emissions. And the other half also showed a linear relationship, but with a strong dispersion. There are many graphs, so I’ll give you just three examples.
With variance:
Linear:
With very strong dispersion:
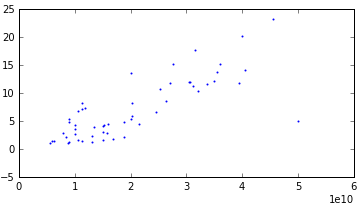
The last schedule was divided into a separate group, because on cross-validation, it showed poor results. I decided to do something special for this occasion (but in the end I did not do anything special).
Actually, I built linear regressions for each group, and got ~ 0.076. Here I thought that I had found the key to solving the problem, and began to adapt to the graphics. I tried almost all the regression models that were in scikit-learn (yes, there is no knowledge, so I solved the problem using the scientific method) the result was not particularly improved.
Even implemented a polynomial. I ran through all the groups, and with the help of GridSearchCV I looked for the best parameters for each group. I noticed that in some groups it does not bend at all as I would like. Started working with data. First, I noticed that there are lines with missing memory data (memtRFC, memFreq, memType). Using just logical inferences, I restored this data. For example, there was data with memtRFC equal to 'DDR-SDRAM PC3200' and 'DDR-SDRAM PC-3200'. Obviously, this is the same thing.
I hoped that this would reduce the number of groups, but it did not happen. Next, I started working with emissions. For good, you would have to write a method that automatically determines outliers, but I did everything with my hands. Drew charts for all groups, and visually determined outliers, and eliminated these points.
After all this, I ran into the problem that my tests show a result of 0.064, but in fact 0.073. Reassigned apparently. I wrote a class wrapper with the fit and predict methods within which I split the data into groups, trained the models for each group, and predicted the same for each group. This allowed me to use cross-validation. Actually after that the result of my tests and the loaded data was always very close.
It looked like this:
Now with the help of cross_validation.cross_val_score I could test my approach qualitatively.
Another small increase was given to me by working with data outside the conditions of the problem. By condition, Y cannot be less than one. Looking at the statistics, I saw that the minimum Y = 1.000085, and my predictions gave a result of less than 1. Not much, but there were some. I solved this problem again at random. The result was the following formula:
At some point, I realized that it was necessary not just to solve an abstract problem, but to solve a concrete one, that is, one should strive not to accurately predict time, but to minimize the error. This means that if the actual running time of the script is 10 seconds, and I was mistaken for 2, then my error is | 10-8 | / 10 = 0.2. And, if the time is really 2 seconds, and I was wrong by 0.1, then | 2-0.1 | / 2 = 0.95.
The difference is obvious. When I realized this, and for some reason this did not happen immediately, I decided to increase the accuracy for a short time. Added to its linear weight regression. The selection method yielded the following formula 1 / pow (Y, 3.1). That is, the more time, the less its importance. Adding to this an emission-resistant model, I ended up with a bunch of 4 models
Actually the average of these models gave me a result of 0.057. Then I jumped to the 14th place, after which I smoothly rolled down to 20.
Attempts to somehow improve the result by selecting the best parameters, changing models, their combinations, and even adding fake points did not succeed.
On clearly linear groups, the result was excellent, so it was necessary to work with data with a strong dispersion. I also decided to add dispersion with my prediction, for this I taught the ExtraTreesRegressor at all not clearly linear groups, I took the 36 most important parameters according to the model. I wrote a script that, in a loop, did cross-validation of data from only these 36 parameters, each time excluding one parameter. Thus, I saw, without which parameter, the best result is obtained. This iteration was repeated until the quality ceased to improve. Yes, this is not quite the right approach, because the parameter excluded in the first iteration could give an increase in the fifth one. For good it was necessary to check all the options, but it took too long, so having improved the quality by a couple of percent, I was pleased with the result.
Further, for nonlinear groups, another model was added, but with a special condition. If the time predicted by ExtraTreesRegressor was less than, the average time predicted by linear models, then I took the average between them, if it is more, then I took only the time predicted by linear models. (It is better to err on the downside, because if the real time is higher, then the error is less).
This threw me into 8th place, from where I again slipped to 10th. The rest of my attempts to somehow improve the result, also did not bear fruit. When recalculating all the test results, I was on the 9th place. Between the last of the TOP 10 and not included there, the difference in points is about 0.0002. This is very little, which indicates the great value of luck at this turn.
And so, the conclusions that I made for myself:
It’s good that the prizes were small and already for 10 places, which allowed me to squeeze into the prizes. I drove to the office of my mail for my hard drive, where Ilya ( sat2707 ) met me, handed me a prize, gave me some juice and showed a viewing platform. I was also assured that new contests with big prizes are planned, so we will wait.
I have everything, thank you all, good luck to all!
And so, a little about my experience:
1) In general, I am a PHP programmer, and I know very little about python, only by participating in the Russian AI Cup 2015 , where I first wrote on python and won a T-shirt;
2) At work, I solved one problem to determine the tonality of the text, using scikit-learn;
3) Began to take a course on coursera.org from Yandex, on machine learning.
')
This is where my experience with python and machine learning ends.
The beginning of the competition
Task
It is necessary to teach a computer to predict how many seconds two matrices of sizes mxk and kxn will multiply on a computer system, if it is known how long this problem was solved on other computer systems with different matrix sizes and other system and hardware parameters.
A set of features describing a separate computational experiment is given: the parameters of the problem (m, k, n) and the characteristics of the computing system on which the algorithm was run and the computation time. And the test sample for which you need to predict the time.
As a quality criterion for solving a problem, the smallest average relative error is used for implementations operating for more than one second:

A set of features describing a separate computational experiment is given: the parameters of the problem (m, k, n) and the characteristics of the computing system on which the algorithm was run and the computation time. And the test sample for which you need to predict the time.
As a quality criterion for solving a problem, the smallest average relative error is used for implementations operating for more than one second:
I put myself python3 and notebook, and began to deal with pandas from the tutorial . I uploaded data, fed random woods, and got ~ 0.133 at the output
Everything, on this thought about the solution of the problem ended.
Studying the subject and collecting additional information
I return to the task, clinging to the line “ We have learned the idea of the problem from the work of A. A. Sidnev, V. P. Gergel ”. Actually, the book describes how to solve this problem. True, I did not understand how I could implement this idea, but I saw an interesting graph:
Hmm, but really, the dependence of time on the size of the matrices should be linear, I thought, and decided to see how things are with this with our data. Having grouped all the examples according to their characteristics, I found that there are only 92 groups. Having actually built graphs for each of the options, I saw that the half had a linear relationship with low emissions. And the other half also showed a linear relationship, but with a strong dispersion. There are many graphs, so I’ll give you just three examples.
With variance:
Linear:
With very strong dispersion:
The last schedule was divided into a separate group, because on cross-validation, it showed poor results. I decided to do something special for this occasion (but in the end I did not do anything special).
Work with data
Actually, I built linear regressions for each group, and got ~ 0.076. Here I thought that I had found the key to solving the problem, and began to adapt to the graphics. I tried almost all the regression models that were in scikit-learn (yes, there is no knowledge, so I solved the problem using the scientific method) the result was not particularly improved.
Even implemented a polynomial. I ran through all the groups, and with the help of GridSearchCV I looked for the best parameters for each group. I noticed that in some groups it does not bend at all as I would like. Started working with data. First, I noticed that there are lines with missing memory data (memtRFC, memFreq, memType). Using just logical inferences, I restored this data. For example, there was data with memtRFC equal to 'DDR-SDRAM PC3200' and 'DDR-SDRAM PC-3200'. Obviously, this is the same thing.
I hoped that this would reduce the number of groups, but it did not happen. Next, I started working with emissions. For good, you would have to write a method that automatically determines outliers, but I did everything with my hands. Drew charts for all groups, and visually determined outliers, and eliminated these points.
Cross validation
After all this, I ran into the problem that my tests show a result of 0.064, but in fact 0.073. Reassigned apparently. I wrote a class wrapper with the fit and predict methods within which I split the data into groups, trained the models for each group, and predicted the same for each group. This allowed me to use cross-validation. Actually after that the result of my tests and the loaded data was always very close.
It looked like this:
class MyModel: def __init__(self): pass def fit(self, X, Y): # x, , def predict(self, X): # x, , def get_params(self, deep=False): return {} Now with the help of cross_validation.cross_val_score I could test my approach qualitatively.
Another small increase was given to me by working with data outside the conditions of the problem. By condition, Y cannot be less than one. Looking at the statistics, I saw that the minimum Y = 1.000085, and my predictions gave a result of less than 1. Not much, but there were some. I solved this problem again at random. The result was the following formula:
time_new = 1 + pow(time_predict/2,2)/10 At some point, I realized that it was necessary not just to solve an abstract problem, but to solve a concrete one, that is, one should strive not to accurately predict time, but to minimize the error. This means that if the actual running time of the script is 10 seconds, and I was mistaken for 2, then my error is | 10-8 | / 10 = 0.2. And, if the time is really 2 seconds, and I was wrong by 0.1, then | 2-0.1 | / 2 = 0.95.
The difference is obvious. When I realized this, and for some reason this did not happen immediately, I decided to increase the accuracy for a short time. Added to its linear weight regression. The selection method yielded the following formula 1 / pow (Y, 3.1). That is, the more time, the less its importance. Adding to this an emission-resistant model, I ended up with a bunch of 4 models
LinearRegression() # TheilSenRegressor() Pipeline([('poly', PolynomialFeatures()), ('linear', TheilSenRegressor())]) # GreadSearchCV Actually the average of these models gave me a result of 0.057. Then I jumped to the 14th place, after which I smoothly rolled down to 20.
Attempts to somehow improve the result by selecting the best parameters, changing models, their combinations, and even adding fake points did not succeed.
Finish line
On clearly linear groups, the result was excellent, so it was necessary to work with data with a strong dispersion. I also decided to add dispersion with my prediction, for this I taught the ExtraTreesRegressor at all not clearly linear groups, I took the 36 most important parameters according to the model. I wrote a script that, in a loop, did cross-validation of data from only these 36 parameters, each time excluding one parameter. Thus, I saw, without which parameter, the best result is obtained. This iteration was repeated until the quality ceased to improve. Yes, this is not quite the right approach, because the parameter excluded in the first iteration could give an increase in the fifth one. For good it was necessary to check all the options, but it took too long, so having improved the quality by a couple of percent, I was pleased with the result.
Further, for nonlinear groups, another model was added, but with a special condition. If the time predicted by ExtraTreesRegressor was less than, the average time predicted by linear models, then I took the average between them, if it is more, then I took only the time predicted by linear models. (It is better to err on the downside, because if the real time is higher, then the error is less).
This threw me into 8th place, from where I again slipped to 10th. The rest of my attempts to somehow improve the result, also did not bear fruit. When recalculating all the test results, I was on the 9th place. Between the last of the TOP 10 and not included there, the difference in points is about 0.0002. This is very little, which indicates the great value of luck at this turn.
Results
And so, the conclusions that I made for myself:
- Always use cross-validation;
- Try to minimize the error;
- It is necessary to work with data (outliers, or lack of data);
Prizes
It’s good that the prizes were small and already for 10 places, which allowed me to squeeze into the prizes. I drove to the office of my mail for my hard drive, where Ilya ( sat2707 ) met me, handed me a prize, gave me some juice and showed a viewing platform. I was also assured that new contests with big prizes are planned, so we will wait.
I have everything, thank you all, good luck to all!
Source: https://habr.com/ru/post/309008/
All Articles