Input lag during rendering and how to win
 Hello to all. Many of you are familiar with the input lag. This happens when you are once again killed in a computer game, and you shout: "Well, I pressed the block / attack / dodge." Well, then the joystick flies into the wall. Familiar? This happens because between pressing the keys and the appearance of the result on the screen a considerable time passes. In fact, when you look at the screen - you see the past state, which may absolutely not reflect reality.
Hello to all. Many of you are familiar with the input lag. This happens when you are once again killed in a computer game, and you shout: "Well, I pressed the block / attack / dodge." Well, then the joystick flies into the wall. Familiar? This happens because between pressing the keys and the appearance of the result on the screen a considerable time passes. In fact, when you look at the screen - you see the past state, which may absolutely not reflect reality.If you are developing your own game, or even do a render, and want to reduce input delays, then I strongly advise you to look under the cat.
So, Input lag in any game consists of:
- Delays on the controller
- Network lag (if it's an online game)
- Laga rendering.
In this article we will consider only the third lag associated with the render. We’ll have to go a little deeper into how the rendering is performed on a modern computer.
')
CPU + GPU
Modern GPU devices are asynchronous as possible. The CPU gives commands to the video driver, and goes to do its own business. The driver accumulates commands in batches, and sends them in packs to a video card. The graphics card draws, and the CPU at this time goes about its business. The maximum FPS you can get in this system is limited by one of the conditions:
1. The CPU does not have time to give commands to the video card, because the video card draws very quickly. And what for you bought such a powerful video card?
2. The video card does not have time to draw what the CPU gives it. Now the CPU is free ...
In order to see how beautifully a pair of CPU and GPU works - there are various profilers. We will use the GPUView, which comes as part of the Windows Performance Toolkit.
The log from GPUView may look something like this:
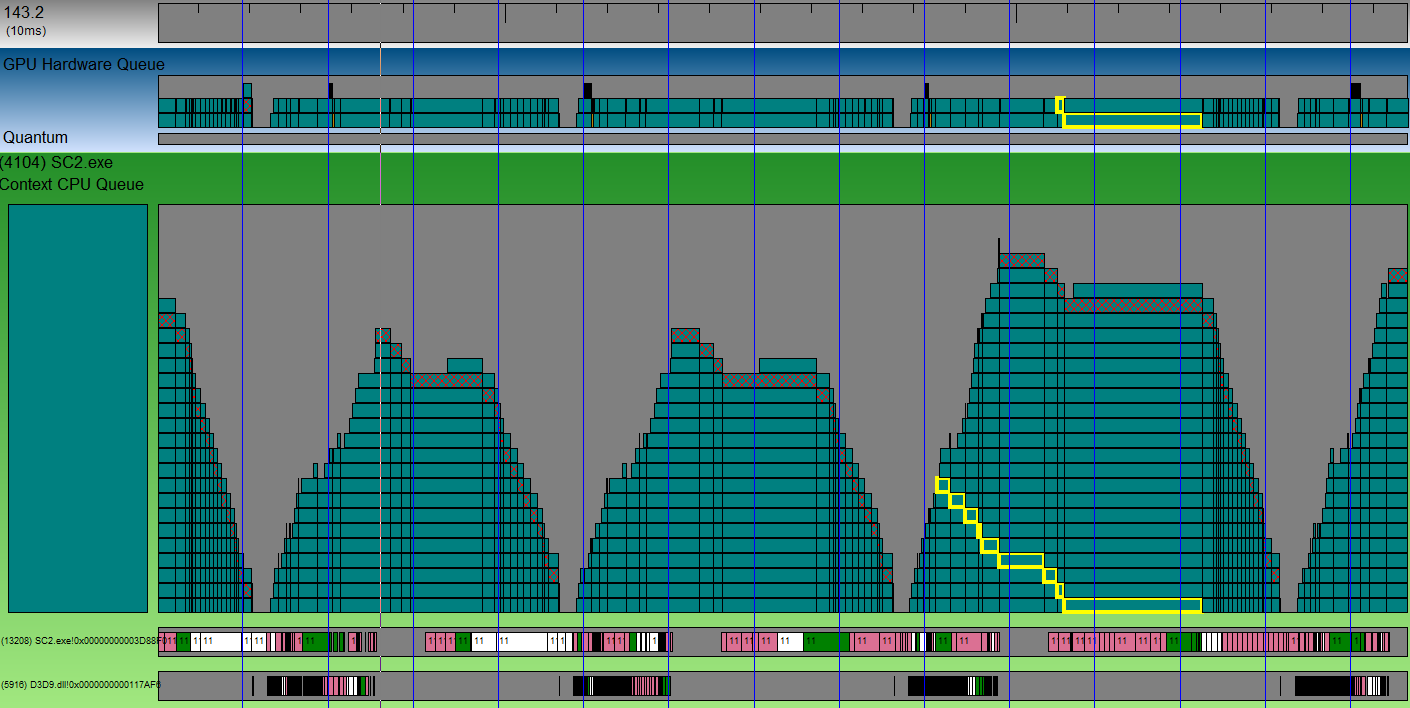
Vertical blue lines are VSync. Piled mountains of cubes are mountains of packages that will go to a video card when it is free. The shaded dice is a packet containing buffer switching. In other words - the end of the frame. Any cube can be selected, and see how it gradually descends in the stack, and is sent to the video card. See on the screenshot a cube with a yellow stroke? It was processed as much as 3 vsync-s. And the whole frame takes about 4 VSync-s (judging by the distance between different diced cubes). Between the two mountains of packages from different frames there is a small gap. This is the time when the GPU rested. This gap is small, and optimization on the CPU side will not give a big win.
But there are large gaps:

This is an example of a render from World of Warcraft. The distance between the packets in the queue is huge. A more powerful video card will not give a single FPS increase. But if you optimize the rendering on the CPU side, then you can get more than a double FPS increase on this GPU.
A little more detail you can read here , and we will go further.
So where is the lag?
It so happened that the gap in performance between the Hi-End and Low-End graphics cards is truly huge. Therefore, you will definitely have both situations. But the saddest situation is when the GPU fails. It looks like this:
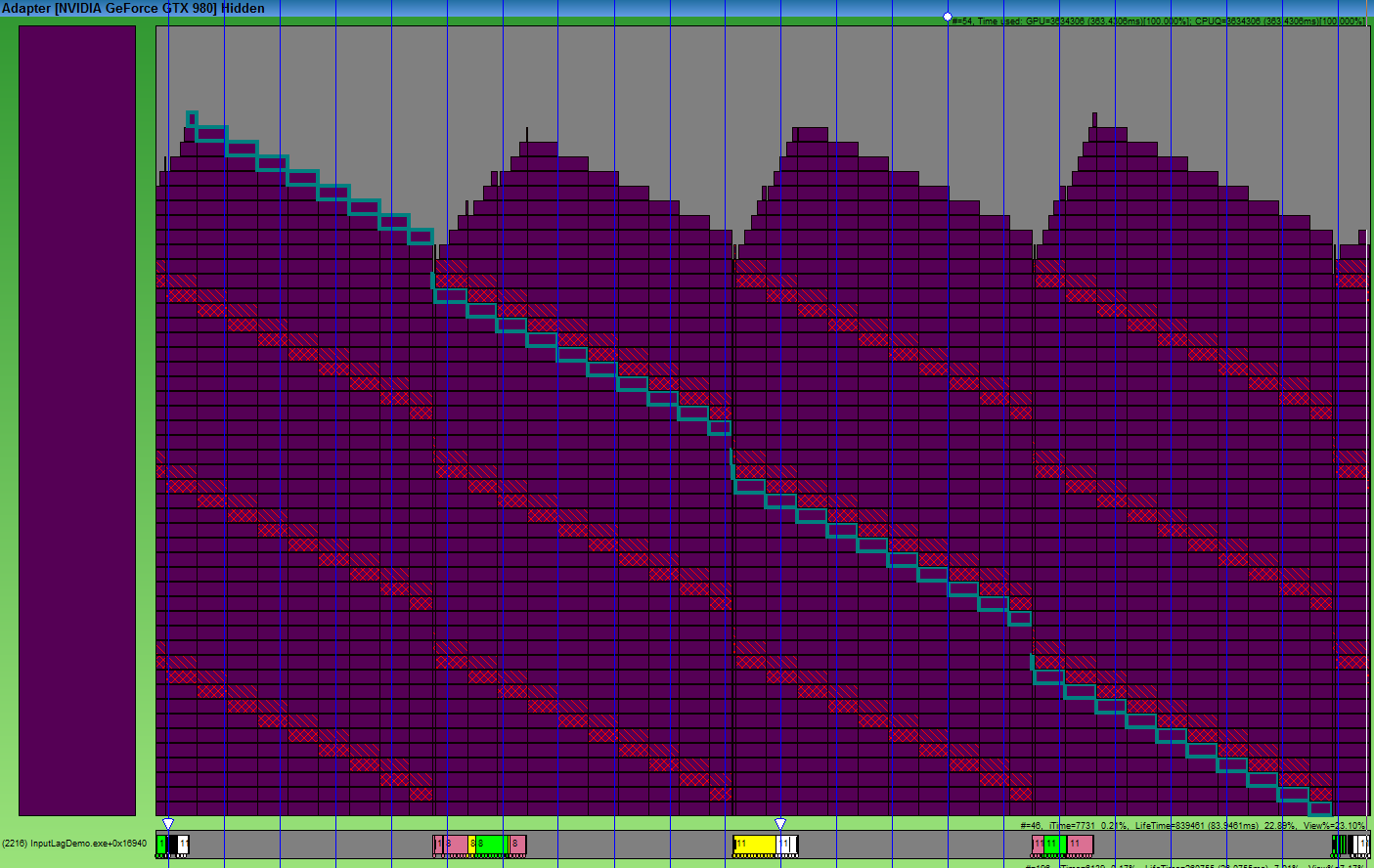
Notice how long it took to process a single batch. The frame takes 4 VSync, and the packet processing takes 4 times longer! DirectX (OpenGL behaves the same way) accumulates data as much as 3 frames. But after all, when we put a fresh frame in the queue - all previous frames are no longer relevant for us, and the video card will still waste time on drawing. Therefore, our action will appear on the screen after as many as 3 frames. Let's see what we can do.
1. Fair decision. IDXGIDevice1 :: SetMaximumFrameLatency (1)
I honestly can not imagine why to save data for 3 frames in the buffer. But MS apparently understood the error, and starting with DX10.1, we had the opportunity to set this number of frames using the special method IDXGIDevice1 :: SetMaximumFrameLatency. Let's see how this will help us:
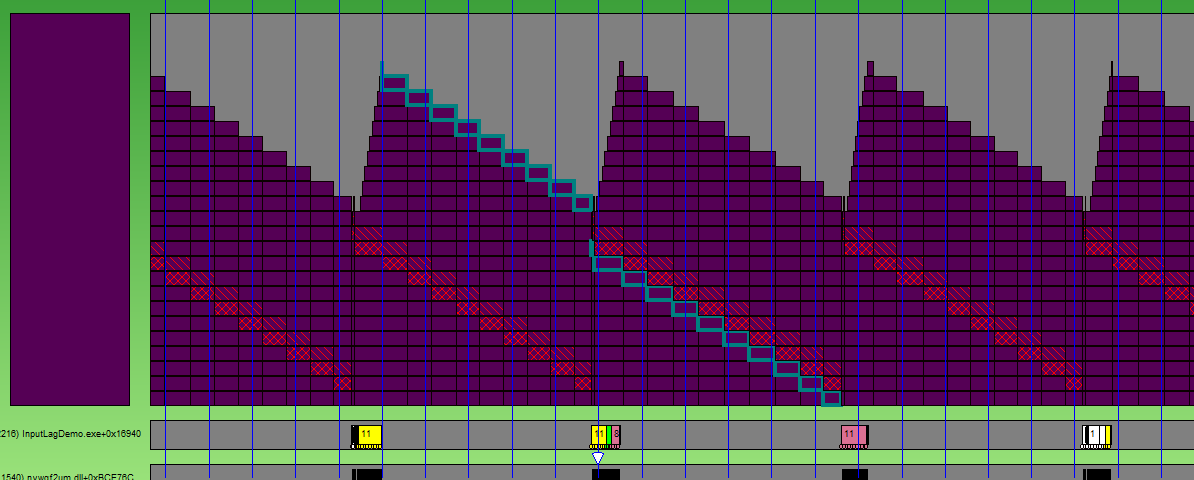
Well then. It became much better. But still not perfect, because still waiting for 2 frames. Another disadvantage of the solution is that it only works for DirectX.
2. The trick with ID3D11Query
The idea is that at the end of the frame we set D3D11_QUERY_EVENT. At the beginning of the next frame - we wait, constantly checking the event, and if it has passed, then only then we start giving commands for drawing, and with the latest Input data.
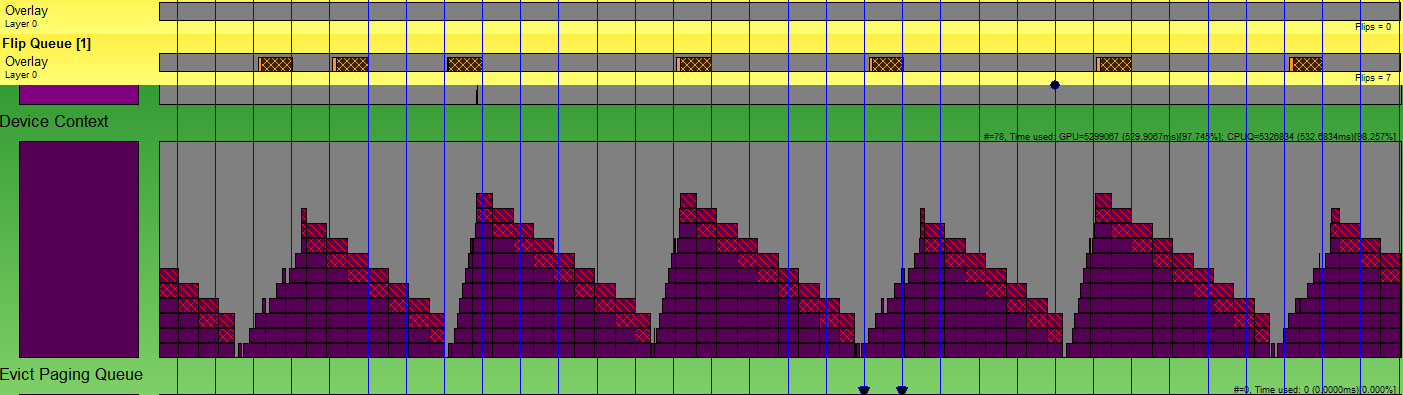
The picture is almost perfect, is not it? I implemented the wait like this:
procedure TfrmMain.SyncQueryWaitEvent; var qDesc: TD3D11_QueryDesc; hRes: HRESULT; qResult: BOOL; begin if FSyncQuery = nil then // - , . begin qDesc.MiscFlags := 0; qDesc.Query := D3D11_QUERY_EVENT; Check3DError(FRawDevice.CreateQuery(qDesc, FSyncQuery)); end else begin repeat hRes := FRawDeviceContext.GetData(FSyncQuery, @qResult, SizeOf(qResult), 0); case hRes of S_OK: ; S_FALSE: qResult := False; else Check3DError(hRes); end; until qResult; // , end; end; The installation of the event is trivial:
procedure TfrmMain.SyncQuerySetEvent; begin if Assigned(FSyncQuery) then FRawDeviceContext._End(FSyncQuery); end; Well, in the render itself, we first add the wait. Then, just before drawing, we collect fresh Input data, and just before the Present we set the event:
if FCtx.Bind then try case WaitMethod of // 1: SyncQueryWaitEvent; 2: SyncTexWaitEvent; end; FCtx.States.DepthTest := True; FFrame.FrameRect := RectI(0, 0, FCtx.WindowSize.x, FCtx.WindowSize.y); FFrame.Select(); FFrame.Clear(0, Vec(0.0,0.2,0.4,0)); FFrame.ClearDS(FCtx.Projection.DepthRange.y); ProcessInputMessages; // Input FShader.Select; FShader.SetAttributes(FBuffer, nil, FInstances); FShader.SetUniform('CycleCount', tbCycle.Position*1.0); for i := 0 to FInstances.Vertices.VerticesCount - 1 do FShader.Draw(ptTriangles, cmBack, False, 1, 0, -1, 0, i); FFrame.BlitToWindow(0); case WaitMethod of // 1: SyncQuerySetEvent; 2: SyncTexSetEvent; end; FRawSwapChain.Present(0,0); finally FCtx.Unbind; end; The lack of a
3. Work around through texture
This is what we do. We have mechanisms to read data from video resources. If we make the video card draw something, and then we try to pick it up, it will automatically synchronize between the GPU-CPU. We will not be able to pick up the data before it is drawn. Therefore, instead of installing an event, I propose to generate MIPs on a video card for a 2 * 2 texture, and instead of waiting for an event, to take data from this texture into the system memory. As a result, the approach looks like this:
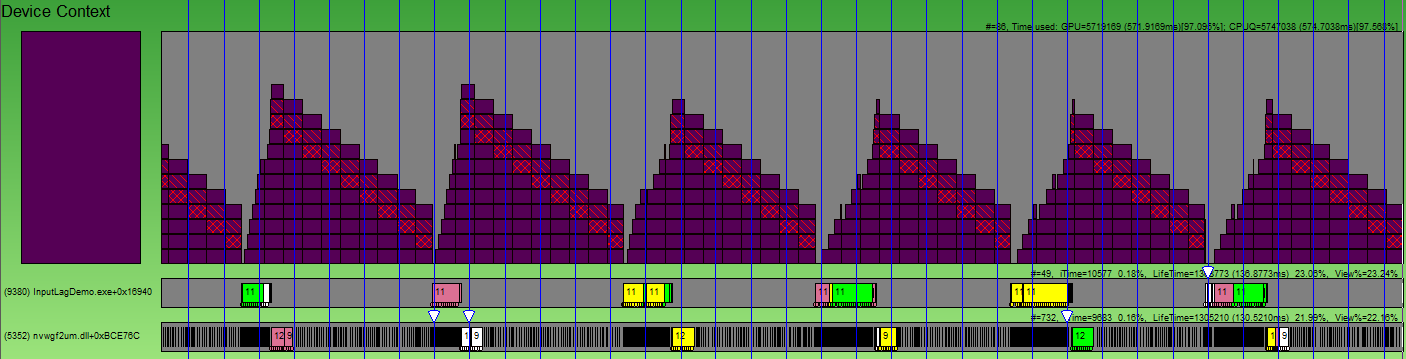
This is how we expect the event:
procedure TfrmMain.SyncTexWaitEvent; var SrcSubRes, DstSubRes: LongWord; TexDesc: TD3D11_Texture2DDesc; ViewDesc: TD3D11_ShaderResourceViewDesc; Mapped: TD3D11_MappedSubresource; begin if FSyncTex = nil then begin TexDesc.Width := 2; TexDesc.Height := 2; TexDesc.MipLevels := 2; TexDesc.ArraySize := 1; TexDesc.Format := TDXGI_Format.DXGI_FORMAT_R8G8B8A8_UNORM; TexDesc.SampleDesc.Count := 1; TexDesc.SampleDesc.Quality := 0; TexDesc.Usage := TD3D11_Usage.D3D11_USAGE_DEFAULT; TexDesc.BindFlags := DWord(D3D11_BIND_SHADER_RESOURCE) or DWord(D3D11_BIND_RENDER_TARGET); TexDesc.CPUAccessFlags := 0; TexDesc.MiscFlags := DWord(D3D11_RESOURCE_MISC_GENERATE_MIPS); Check3DError(FRawDevice.CreateTexture2D(TexDesc, nil, FSyncTex)); TexDesc.Width := 1; TexDesc.Height := 1; TexDesc.MipLevels := 1; TexDesc.ArraySize := 1; TexDesc.Format := TDXGI_Format.DXGI_FORMAT_R8G8B8A8_UNORM; TexDesc.SampleDesc.Count := 1; TexDesc.SampleDesc.Quality := 0; TexDesc.Usage := TD3D11_Usage.D3D11_USAGE_STAGING; TexDesc.BindFlags := 0; TexDesc.CPUAccessFlags := DWord(D3D11_CPU_ACCESS_READ); TexDesc.MiscFlags := 0; Check3DError(FRawDevice.CreateTexture2D(TexDesc, nil, FSyncStaging)); ViewDesc.Format := TDXGI_Format.DXGI_FORMAT_R8G8B8A8_UNORM; ViewDesc.ViewDimension := TD3D11_SRVDimension.D3D10_1_SRV_DIMENSION_TEXTURE2D; ViewDesc.Texture2D.MipLevels := 2; ViewDesc.Texture2D.MostDetailedMip := 0; Check3DError(FRawDevice.CreateShaderResourceView(FSyncTex, @ViewDesc, FSyncView)); end else begin SrcSubRes := D3D11CalcSubresource(1, 0, 1); DstSubRes := D3D11CalcSubresource(0, 0, 1); FRawDeviceContext.CopySubresourceRegion(FSyncStaging, DstSubRes, 0, 0, 0, FSyncTex, SrcSubRes, nil); Check3DError(FRawDeviceContext.Map(FSyncStaging, DstSubRes, TD3D11_Map.D3D11_MAP_READ, 0, Mapped)); FRawDeviceContext.Unmap(FSyncStaging, DstSubRes); end; end; and this is how we install it:
procedure TfrmMain.SyncTexSetEvent; begin if Assigned(FSyncView) then FRawDeviceContext.GenerateMips(FSyncView); end; The rest of the approach is completely similar to the previous one. Advantage: works not only on DirectX but also on OpenGL. The disadvantage is a small overhead projector for texture generation and data transfer back + potentially spent time to “wake up” the flow with the operating system sheduler.
Pro try
Of course, I was spreading on the tree ... but how serious is the problem? How to feel it? I wrote a special demo program (requires DirectX11).
Download * .exe here . For those who are afraid to download builds of an unknown vendor - the source code of the lazarus project is here (I also need my library framework AvalancheProject, which is located here )
The program is such a window:

Here 40 * 40 * 40 = 64000 is drawn (by the way, each cube is a separate draccolll). GPU workload trackbar gives the load on the GPU (using a useless loop in the vertex shader). Simply lower the FPS to a low level with this trackbar, say 10-20, and then try to right-click the cubes and switch the methods of reducing Input lag using radio beats.
You will only appreciate what a huge difference in response speed. With Query Event it is comfortable to turn a cube even at 20 fps.
Finally
I honestly was surprised when I saw that few people struggle with this problem. Even large AAA projects allow such terrible input lags. It also surprises me that the new graphics APIs come out one by one, and the problem, which is clearly more than 10 years old, has to be solved so far with crutches. In general, I hope that this article will help you improve the responsiveness of your application, as well as add you to satisfied users.
Source: https://habr.com/ru/post/308980/
All Articles