NGINX: Interception of 5xx errors using a debug server
Is the answer a mistake 5xx, if no one sees it? [one]

Regardless of how long and thoroughly the software is checked before launching, some of the problems manifest themselves only in the working environment. For example, race condition from concurrent maintenance of a large number of clients or exceptions in validating unexpected data from the user. As a result, these problems can lead to 5xx errors.
HTTP 5xx responses are often returned to users and can damage the company's reputation even in a short period of time. At the same time, debugging a problem on a production server is often very difficult. Even a simple extraction of a problem session from logs can turn into a search for a needle in a haystack. And even if all the necessary logs are collected from all working servers, this may not be enough to understand the causes of the problem.
')
To facilitate the search and debugging process, some useful techniques can be used when NGINX is used for proxying or balancing an application. This article will look at the special use of the
error_page directive applied to typical application infrastructure with proxying through NGINX.Debug server
The debug server (debug server, Debug Server) is a special server to which requests are redirected that cause errors on the production servers. This is achieved by taking advantage of the fact that NGINX can detect 5xx errors returned from upstream and redirect error-causing requests from different upstream groups to the debug server. And since the debug server will only process requests that lead to errors, there will be information in the logs that relates exclusively to errors. Thus, the problem of finding needles in a haystack is reduced to a handful of needles.
Since the debug server does not serve the working client requests, there is no need to sharpen it for performance. Instead, it can enable maximum logging and add diagnostic tools for every taste. For example:
- Run application in debug mode
- Enabling verbose logging on the server
- Adding Application Profiling
- Counting resources used by the server
Debugging tools are usually disabled for production servers, as they often slow down the application. However, for a debug server you can safely enable them. Below is an example of the application infrastructure with a debug server.
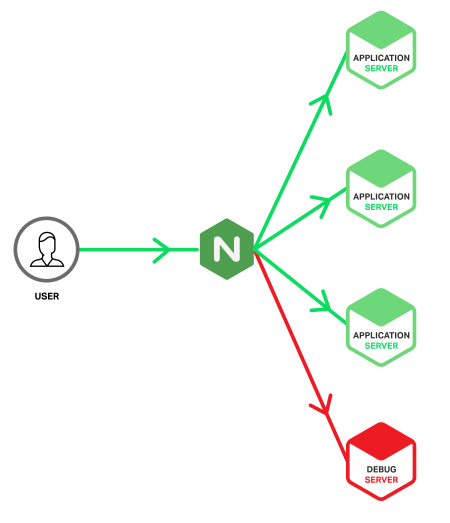
In an ideal world, the process of configuring and allocating resources for a debug server should not be different from the process of setting up a regular production server. But if you make a debugging server in the form of a virtual machine, then this may have its advantages (for example, cloning and copying for offline analytics). However, in this case, there is a risk that the server can be overloaded in case of a serious problem that causes a sudden surge of 5xx errors. In NGINX Plus, this can be avoided by using the max_conns parameter to limit the number of parallel connections (below is an example configuration).
Since the debug server is loaded differently than the working server, not all 5xx errors can be reproduced. In such a situation, it can be assumed that you have reached the limit of scaling the application and exhausted resources, and there is no error in the application itself. Regardless of the root cause, using a debug server will help improve user interaction and warn it against 5xx errors.
Configuration
The following is a simple example of a debugging server configuration for receiving requests that resulted in a 5xx error on one of the main servers.
upstream app_server { server 172.16.0.1; server 172.16.0.2; server 172.16.0.3; } upstream debug_server { server 172.16.0.9 max_conns=20; } server { listen *:80; location / { proxy_pass http://app_server; proxy_intercept_errors on; error_page 500 503 504 @debug; } location @debug { proxy_pass http://debug_server; access_log /var/log/nginx/access_debug_server.log detailed; error_log /var/log/nginx/error_debug_server.log; } } The upstream
app_server block contains the addresses of the working servers. The following is one debug server address in the upstream debug_server .The first location block configures simple proxying using the proxy_pass directive to balance the application servers in
upstream app_server (the example does not specify a balancing algorithm, therefore the standard Round Robin algorithm is used). The included proxy_intercept_errors directive means that any response with an HTTP status of 300 or higher will be processed using the error_page directive. In our example, only 500, 503 and 504 errors are intercepted and sent to the location @debug block for processing. All other responses, such as 404, are sent to the user unchanged.Two actions occur in the
@debug block: first, proxying to the upstream debug_server group, which, of course, contains the debugging server; secondly, write access_log and error_log to separate files. By isolating messages generated by erroneous requests to the working servers, you can easily correlate them with errors that are generated on the debug server itself.Note that the access_log directive refers to a separate logging format - detailed . This format can be determined by specifying the following values at the
http level in the log_format directive: log_format detailed '$remote_addr - $remote_user [$time_local] ' '"$request" $status $body_bytes_sent "$http_referer" ' '"$http_user_agent" $request_length $request_time ' '$upstream_response_length $upstream_response_time ' '$upstream_status'; The detailed format extends the default format combined by adding five variables that provide additional information about the request to the debug server and its response.
$request_length- full size of the request, including headers and body, in bytes$request_time- request processing time, in milliseconds$upstream_response_length- length of the response received from the debug server, in bytes$upstream_response_time- time taken to receive a response from the debug server, in milliseconds$upstream_status- response status code from the debug server
The above additional fields in the log are very useful for detecting invalid queries and queries with a long execution time. The latter may indicate incorrect timeouts in the application or other interprocess communication problems.
Idempotency with requests forwarders
Perhaps, in some cases, I want to avoid redirecting requests to the debug server. For example, if an application encountered an error while trying to change several records in the database, then a new request may repeat the call to the database and make changes again. This can lead to confusion in the database.
Therefore, it is safe to re-send a request only if it is idempotent - that is, a request, for which it is sent again, the result will be the same. HTTP
GET , PUT , and DELETE methods are idempotent, while POST is not. However, it is worth noting that the idempotency of HTTP methods may depend on the implementation of the application and may differ from formally defined ones.There are three options for how to handle idempotency on a debug server:
- Start the debug server in read-only mode for the database. In this case, re-sending requests is safe, as it does not make any changes. Logging requests on the debug server will be unchanged, but less information will be available to diagnose the problem (due to the read-only mode).
- Re-send only idempotent requests to the debug server.
- Deploy the second debug server in read-only mode for the database and re-send nonidempotent requests to it, and the idempotent ones continue to send debugging to the main server. In this case, all requests will be processed, but additional configuration will be required.
For completeness, consider the configuration for the third option:
upstream app_server { server 172.16.0.1; server 172.16.0.2; server 172.16.0.3; } upstream debug_server { server 172.16.0.9 max_conns=20; } upstream readonly_server { server 172.16.0.10 max_conns=20; } map $request_method $debug_location { 'POST' @readonly; 'LOCK' @readonly; 'PATCH' @readonly; default @debug; } server { listen *:80; location / { proxy_pass http://app_server; proxy_intercept_errors on; error_page 500 503 504 $debug_location; } location @debug { proxy_pass http://debug_server; access_log /var/log/nginx/access_debug_server.log detailed; error_log /var/log/nginx/error_debug_server.log; } location @readonly { proxy_pass http://readonly_server; access_log /var/log/nginx/access_readonly_server.log detailed; error_log /var/log/nginx/error_readonly_server.log; } } Using the map directive with the $ request_method variable, depending on the idempotency of the method, the value of the new
$debug_location variable is $debug_location . When the error_page directive is error_page , the $debug_location variable is calculated, and it is determined to which debugging server the request will be forwarded.Often, the proxy_next_upstream directive is used to resend failed requests to other servers in the upstream (before being sent to the debug server). Although, as a rule, it is used for errors at the network level, but an extension for 5xx errors is also possible. Starting with NGINX version 1.9.13, non-idempotent requests that result in 5xx errors are not re-sent by default. To enable this behavior, you need to add the
non_idempotent parameter in the non_idempotent directive. The same behavior is implemented in NGINX Plus starting with version R9 (April 2016). location / { proxy_pass http://app_server; proxy_next_upstream http_500 http_503 http_504 non_idempotent; proxy_intercept_errors on; error_page 500 503 504 @debug; } Conclusion
Do not ignore the error 5xx. If you are using the DevOps model, experimenting with Continuous Delivery, or just want to reduce the risk of upgrades - NGINX provides tools that can help you better respond to problems that arise.
Source: https://habr.com/ru/post/308880/
All Articles