64-bit browser arithmetic and WebAssembly
 WebAssembly is being actively developed and has already reached the state when the assembled module can be tried in Chrome Canary and Firefox Nightly by turning on the checkbox in the settings.
WebAssembly is being actively developed and has already reached the state when the assembled module can be tried in Chrome Canary and Firefox Nightly by turning on the checkbox in the settings.
Let's compare the performance of arithmetic calculations with 64-bit numbers in WebAssembly, asm.js, PNaCl and native-code. Let's look at the tools that are available for WebAssembly now, and look into the near future.
Disclaimer
WebAssembly is currently under development, in a month the article may become outdated. The purpose of the article is to tell about the situation for those who are interested.
TL; DR
Algorithm
As a benchmark, we take Argon2, which I recently needed to calculate in the browser.
Argon2 ( github , habr ) is a relatively new cryptographic key generation function (key derivation function, KDF) that won the Password Hashing Competition .
It is based on 64-bit arithmetic, here are the functions that are executed about 60M times in one iteration:
uint64_t fBlaMka(uint64_t x, uint64_t y) { const uint64_t m = UINT64_C(0xFFFFFFFF); const uint64_t xy = (x & m) * (y & m); return x + y + 2 * xy; } uint64_t rotr64(const uint64_t w, const unsigned c) { return (w >> c) | (w << (64 - c)); } Implementation difficulties on asm.js
It would seem that everything is simple: take and multiply two 64-bit numbers, as is done in the native-code argon2, for example, by calling an sse-instruction. But not in the browser.
In V8, as you know, there are no 64-bit integers, so all arithmetic, for lack of a better one, is emulated by 31-bit smi (small integer). Which is very slow. So slow and so ugly that the developers of Unity repeatedly mentioned it, and 64-bit types were included in WebAssembly MVP, although at first they wanted to postpone it for later.
Let's look at the code generated by asm.js for the multiplication function of two int64, this is the function from the compiler-rt:
function ___muldsi3($a, $b) { $a = $a | 0; $b = $b | 0; var $1 = 0, $2 = 0, $3 = 0, $6 = 0, $8 = 0, $11 = 0, $12 = 0; $1 = $a & 65535; $2 = $b & 65535; $3 = Math_imul($2, $1) | 0; $6 = $a >>> 16; $8 = ($3 >>> 16) + (Math_imul($2, $6) | 0) | 0; $11 = $b >>> 16; $12 = Math_imul($11, $1) | 0; return (tempRet0 = (($8 >>> 16) + (Math_imul($11, $6) | 0) | 0) + ((($8 & 65535) + $12 | 0) >>> 16) | 0, 0 | ($8 + $12 << 16 | $3 & 65535)) | 0; } Here it is , and here it is in JavaScript . The implementation is very good by the way, not causing deopts in V8. Check it out just in case:
Compile asm.js, disabling variable renaming so that the function names in the code are readable, and run with flags that allow you to open artifacts in IR Hydra (you can simply install npm i -g node-irhydra):
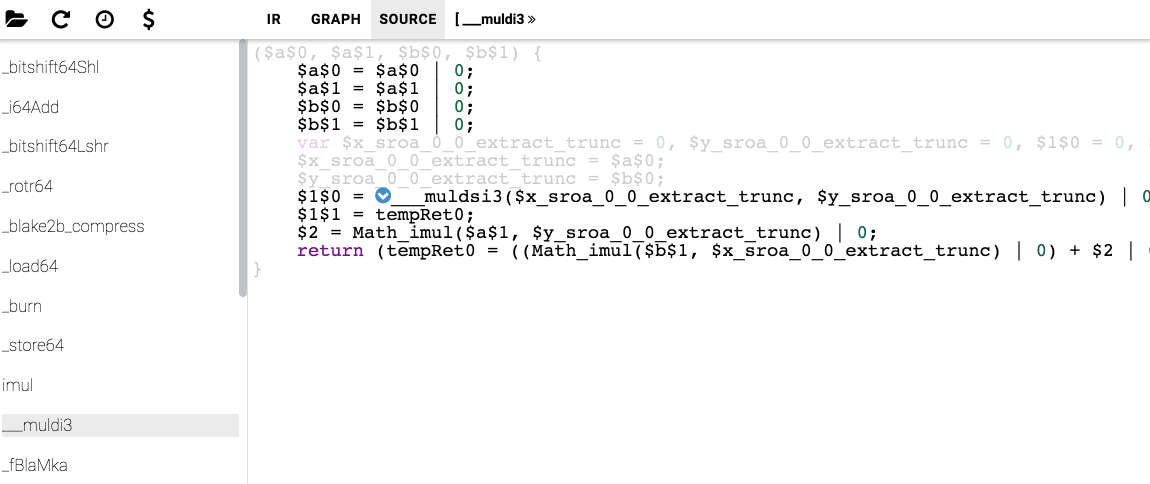
As you can see, V8 even zainlayn __muldsi3 function in __muldi3 . You can also look at the assembler code of this function.
v50 EnterInlined ___muldsi3 Tagged i71 Constant 65535 Smi i72 Bitwise BIT_AND i234 i71 TaggedNumber i76 Bitwise BIT_AND i236 i71 TaggedNumber t79 LoadContextSlot t47[13] Tagged t82 CheckValue t79 0x3d78a90c3b59 <JS Function imul (SharedFunctionInfo 0x3d78a9058f91)> Tagged i83 Mul i76 i72 TaggedNumber i88 Constant 16 Smi i89 Shr i234 i88 TaggedNumber i94 Shr i83 i88 TaggedNumber i100 Mul i76 i89 TaggedNumber i104 Add i94 i100 TaggedNumber i111 Shr i236 i88 TaggedNumber i118 Mul i111 i72 TaggedNumber i125 Shr i104 i88 TaggedNumber i131 Mul i111 i89 TaggedNumber i135 Add i125 i131 TaggedNumber i142 Bitwise BIT_AND i104 i71 TaggedNumber i145 Add i142 i118 TaggedNumber i151 Shr i145 i88 TaggedNumber i153 Add i135 i151 TaggedNumber t238 Change i153 i to t v158 StoreContextSlot t47[12] = t238 changes[ContextSlots] Tagged v159 Simulate id=319 var[3] = t47, var[1] = i234, var[2] = i236, var[6] = i83, var[5] = t6, var[8] = i104, var[4] = t6, var[10] = i118, var[9] = t6, var[7] = t6, push i153 Tagged i163 Add i104 i118 TaggedNumber i166 Shl i163 i88 TaggedNumber i170 Bitwise BIT_AND i83 i71 TaggedNumber i172 Bitwise BIT_OR i166 i170 TaggedNumber v179 LeaveInlined Tagged v180 Simulate id=172 pop 1 / push i172 Tagged v181 Goto B3 Tagged 140 andl r8,0xffff
;; <@ 43, # 72> gap
147 movq r9, rdx
;; <@ 44, # 76> bit-i
150 andl r9,0xffff
;; <@ 48, # 79> load-context-slot
170 movq r11, [r11 + 0x77]
;; <@ 50, # 82> check-value
174 movq r10,0x3d78a90c3b59 ;; object: 0x3d78a90c3b59 <JS Function imul (SharedFunctionInfo 0x3d78a9058f91)>
184 cmpq r11, r10
187 jnz 968
;; <@ 51, # 82> gap
193 movq rdi, r9
;; <@ 52, # 83> mul-i
196 imull rdi, r8
;; <@ 53, # 83> gap
200 movq r11, rax
;; <@ 54, # 89> shift-i
203 shrl r11, 16
;; <@ 55, # 89> gap
207 movq r12, rdi
;; <@ 56, # 94> shift-i
210 shrl r12, 16
;; <@ 58, # 100> mul-i
214 imull r9, r11
;; <@ 60, # 104> add-i
218 addl r9, r12
;; <@ 61, # 104> gap
221 movq r12, rdx
;; <@ 62, # 111> shift-i
224 shrl r12, 16
;; <@ 63, # 111> gap
228 movq r14, r12
;; <@ 64, # 118> mul-i
231 imull r14, r8
;; <@ 65, # 118> gap
235 movq r8, r9
;; <@ 66, # 125> shift-i
238 shrl r8, 16
;; <@ 68, # 131> mul-i
242 imull r12, r11
;; <@ 70, # 135> add-i
246 addl r12, r8
;; <@ 71, # 135> gap
249 movq r8, r9
;; <@ 72, # 142> bit-i
252 andl r8,0xffff
;; <@ 74, # 145> add-i
259 addl r8, r14
;; <@ 76, # 151> shift-i
262 shrl r8, 16
;; <@ 78, # 153> add-i
266 addl r8, r12
;; <@ 80, # 238> smi-tag
269 movl r12, r8
272 shlq r12, 32
;; <@ 84, # 158> store-context-slot
289 movq [r11 + 0x6f], r12
;; <@ 86, # 163> add-i
293 leal r8, [r9 + r14 * 1]
;; <@ 88, # 166> shift-i
297 shll r8, 16
;; <@ 90, # 170> bit-i
301 andl rdi, 0xffff
;; <@ 92, # 172> bit-i
307 orl rdi, r8
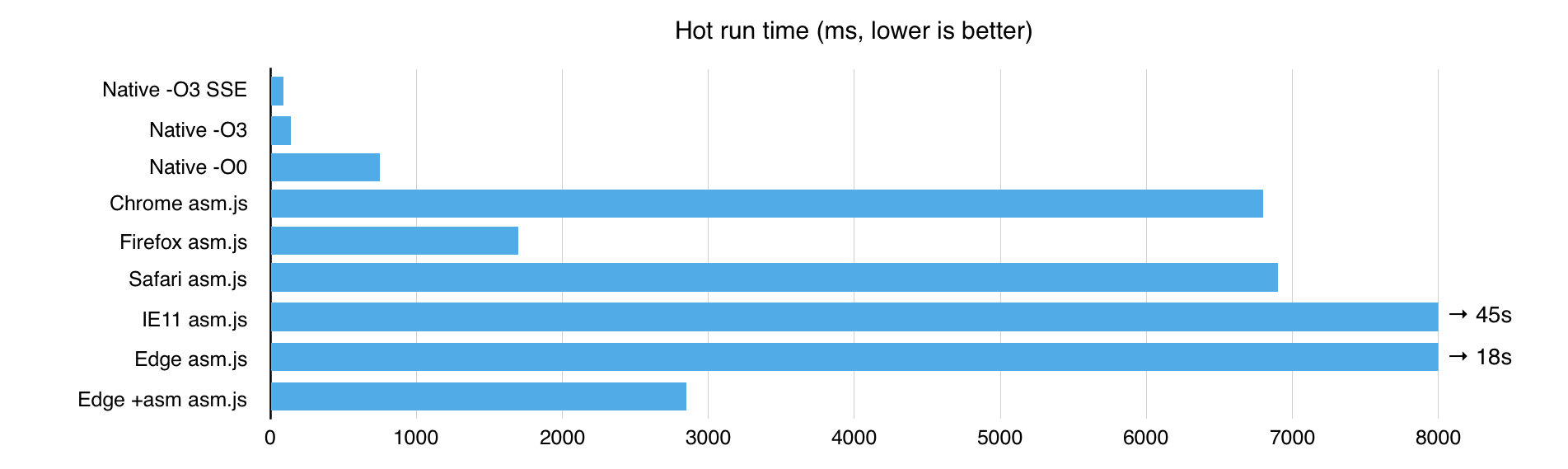
Chrome does not generate the optimal code, as you could do with type annotations, the V8 developers basically do not want to support the asm.js js subset, and in general, that's right. In contrast, Firefox, seeing "use asm", in case the code passes validation, throws out some checks, with the result that the resulting code is faster about 3..4 times faster.
Compared to native code, Chrome and Safari are 50 times slower, Firefox is 12 times slower.
IE11 is quite slow, but Edge with asm.js enabled is somewhere in the middle between Chrome and Firefox:
WebAssembly
Compile this code in WebAssembly. This can be done in several ways, first we will try C / C ++ Source ⇒ asm2wasm ⇒ WebAssembly (some parameters are excluded for brevity):
cmake \ -DCMAKE_TOOLCHAIN_FILE=~/emsdk_portable/emscripten/incoming/cmake/Modules/Platform/Emscripten.cmake \ -DCMAKE_C_FLAGS="-O3" \ -DCMAKE_EXE_LINKER_FLAGS="-O3 -g0 -s 'EXPORTED_FUNCTIONS=[\"_argon2_hash\"]' -s BINARYEN=1" && cmake --build . You can use the same toolchain as for the asm.js assembly, specifying that we want to use binaryen ( -s BINARYEN=1 ).
At the output we get:
- wast file: textual representation of WebAssembly, S-Expressions.
- mappedGlobals: json with functions exported from the module and available in JavaScript, there will be runtime functions and what we have specified in
EXPORTED_FUNCTIONS. - js-wrapper that manages a wasm module or can execute code in other ways if wasm is not supported.
- asm.js code that will be used as a fallback, in case there is no support for wasm.
Convert the wast file to the wasm binary format :
~/binaryen/bin/wasm-as argon2.wast > argon2.wasm We use the module in the browser
What can js-wrapper do except call the wasm-module and how to use it?
- load binary wasm module
- create a
Moduleobject with settings - any way to import the script into the browser
global.Module = { print: log, printErr: log, setStatus: log, wasmBinary: loadedWasmBinaryAsArrayBuffer, wasmJSMethod: 'native-wasm,', asmjsCodeFile: 'dist/argon2.asm.js', wasmBinaryFile: 'dist/argon2.wasm', wasmTextFile: 'dist/argon2.wast' }; var xhr = new XMLHttpRequest(); xhr.open('GET', 'dist/argon2.wasm', true); xhr.responseType = 'arraybuffer'; xhr.onload = function() { global.Module.wasmBinary = xhr.response; // load script }; xhr.send(null); Here we indicate the location of the compiled artifacts, connect our logs and determine the method by which we will execute the code. From the methods you can choose:
native-wasm: use wasm support in the browser;interpret-s-expr: load .wast textual representation and interpret it;interpret-binary: interpret the .wasm binary format;interpret-asm2wasm: load asm.js code, compile it into .wasm and execute;asmjs: execute asm.js code.
You can list several methods separated by commas, then the first successful one will be executed. The default method is native-wasm,interpret-binary , that is, try if there is no wasm, if not, then interpret the binary module.
After successful loading, all exported methods appear in the Module object.
Example of use ( completely ):
var pwd = Module.allocate(Module.intArrayFromString('password'), 'i8', Module.ALLOC_NORMAL); // ... var res = Module._argon2_hash(t_cost, m_cost, parallelism, pwd, pwdlen, salt, saltlen, hash, hashlen, encoded, encodedlen, argon2_type, version); var encodedStr = Module.Pointer_stringify(encoded); Firefox Nightly allows you to look inside the wasm module:
In Chrome, there are no tools to view wasm, the module is not even displayed in the editor. But the release also promised to make view source.
Interpreter from Binaryen
Binaryen generates an interpreter that can execute text .wast and binary .wasm formats. You can try it by setting method in interpret-s-expr or interpret-binary . So far, the interpreter is so slow that I did not wait for the hash calculation, but I appreciated it by a smaller number of iterations. It would have been half an hour, while in Chrome it was 7 seconds and even in IE11 45 seconds.
Quality code
Let's see what kind of code we got. I wrote a simple test so that .wast was extremely small, here it is :
uint64_t fBlaMka(uint64_t x, uint64_t y) { const uint64_t m = UINT64_C(0xFFFFFFFF); const uint64_t xy = (x & m) * (y & m); return x + y + 2 * xy; } int exp_fBlaMka() { for (unsigned i = 0; i < 100000000; i++) { if (fBlaMka(i, i) == i - 1) { return 1; } } return 0; } Let's take a look at .wast and find our function:
(func $_exp_fBlaMka (result i32) (local $0 i32) (set_local $0 (i32.const 0) ) (loop $while-out$0 $while-in$1 (if # , (i32.and (i32.eq (call $___muldi3 # (call $_i64Add (call $_bitshift64Shl (get_local $0) (i32.const 0) (i32.const 1) ) (i32.load (i32.const 168) ) (i32.const 2) (i32.const 0) ) (i32.load (i32.const 168) ) (get_local $0) (i32.const 0) ) (i32.add (get_local $0) (i32.const -1) ) ) # ... I32 again? Why is this so? Recall that we received a wasm code by compiling asm.js, so i64 will not be seen here. It is no wonder that such code is also executed for a long time.
However, now the speed of execution in Chrome is the same as in Firefox, and a little faster than asm.js in Firefox.
LLVM WebAssembly Backend
Now let's try a more complicated way, C / C ++ Source ⇒ WebAssembly LLVM backend ⇒ s2wasm ⇒ WebAssembly.
LLVM learned how to generate WebAssembly, doing this without emscripten. But he does it so far very badly, the resulting module does not always work.
We assemble LLVM with support for WebAssembly:
cmake -G Ninja -DLLVM_EXPERIMENTAL_TARGETS_TO_BUILD=WebAssembly .. && ninja We include it in compilation:
export EMCC_WASM_BACKEND=1 -DCMAKE_EXE_LINKER_FLAGS="-s WASM_BACKEND=1" To try different versions of LLVM in emscripten, specify the path to it in ~ / .emscripten, LLVM_ROOT. And ... we get an error when loading the module into the browser.
You can still collect not the fork of fastcomp used in emcc, but vanilla LLVM from upstream, something like this:
clang -emit-llvm --target=wasm32 -S perf-test.c llc perf-test.ll -march=wasm32 ~/binaryen/bin/s2wasm perf-test.s > perf-test.wast ~/binaryen/bin/wasm-as perf-test.wast > perf-test.wasm Also falling. Perhaps, wasm from wast for V8 should be built sexpr-wasm-prototype , not binaryen, but it still does not help.
However, the simple test works quite well; you can at least evaluate the performance using the example of one function. Let's look at the resulting .wast:
(func $fBlaMka (param $0 i64) (param $1 i64) (result i64) (i64.add (i64.add (get_local $1) (get_local $0) ) (i64.mul (i64.and (i64.shl (get_local $0) (i64.const 1) ) (i64.const 8589934590) ) (i64.and (get_local $1) (i64.const 4294967295) ) ) ) ) Hooray, i64! We will load it into the browser and estimate the time in comparison with the previous option:
console.time('i64'); Module._exp_fBlaMka(); console.timeEnd('i64'); i32: 1851.5ms i64: 414.49ms In the bright future, the speed of 64-bit arithmetic is several times better.
Threading
Pthreads are not included in MVP WebAssembly, they will appear only later . While it is difficult to say what will happen, in general, for the next year - the answer is no. But WebAssembly can be easily used in web workers without any performance degradation, as you can see for yourself on the demo page.
PNaCl
Now compare performance with PNaCl. PNaCl is also a binary code format developed by Google for Chrome and even enabled by default. It was once supposed to support it in other browsers, but Mozilla rejected the proposal , while others did not think about it. Did not take off.
So, PNaCl is .pexe, which is jit-run in runtime, let's make a simple module for it:
class Argon2Instance : public pp::Instance { public: virtual void HandleMessage(const pp::Var& msg) { pp::VarDictionary req(msg); // int t_cost = req.Get(pp::Var("time")).AsInt(); // ... int res = argon2_hash(t_cost, m_cost, parallelism, pwd, pwdlen, salt, saltlen, hash, hashlen, encoded, encodedlen, argon2_type == 1 ? Argon2_i : Argon2_d, version); pp::VarDictionary reply; reply.Set(pp::Var("res"), res); PostMessage(reply); // } }; You can call this by inserting .pexe on the page in <embed> and sending him a message:
// listener.addEventListener('message', e => console.log(e.data)); // moduleEl.postMessage({ pwd: 'password', ... }); Unlike WASM, PNaCl already supports 64-bit types and pthreads, therefore, the operating time is 1.5..2 times longer than native-code in terms of speed. But it is only chrome. Sadly, only the download time, which is a few seconds, and in the case of the first use of PNaCl in general, the user can grow to irresponsible figures in the order of 30 seconds.
Charts
Average code execution time in different environments:

Load time and first run:

Code size
| Code size, KiB | Comment | |
|---|---|---|
| asm.js | 109 | all js nickname |
| WebAssembly | 43 | only .wasm, without wrapper |
| PNaCl | 112 | .pexe |
What about node.js?
In node.js, compiling native code is very simple right now; just add a couple of bindings. When V8 is upgraded to some version, node.js can be run with the --expose-wasm (as long as its support is in the experimental stage) and you can use wasm in the node. Until it boots up, because the V8 is quite old.
findings
It is now sensible to use asm.js in Firefox and PNaCl in Chrome. WASM is already good enough now, by the time of MVP, the compilation in LLVM will most likely be brought to mind, but using it is, of course, early, even in nightly builds it is turned off by default. However, the performance of the wasm is already indicative now and exceeds the speed of asm.js, even without the support of i64.
Links
')
Source: https://habr.com/ru/post/308874/
All Articles