When "O" brings a big
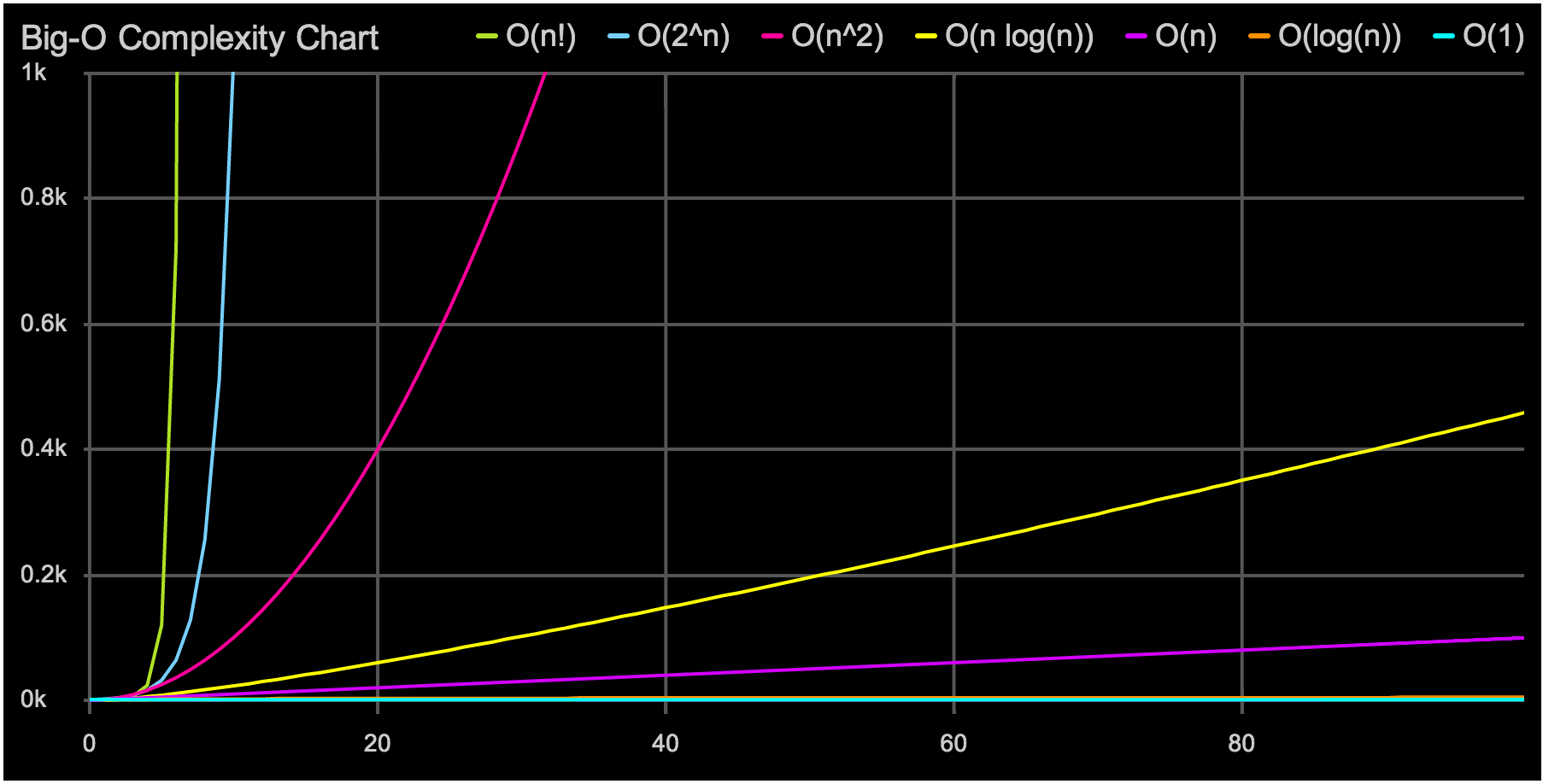
The "O" is a great tool. It allows you to quickly select the appropriate data structure or algorithm. But sometimes a simple analysis of “O” big can fool us, if you don’t think carefully about the influence of constant factors. An example that is often encountered when programming on modern processors is associated with the choice of data structure: an array, a list, or a tree.
Memory, slow-slow memory
In the early 1980s, the time required to obtain data from RAM and the time required to perform calculations with this data were approximately the same. It was possible to use an algorithm that randomly moved through the dynamic memory, collecting and processing data. Since then, processors began to perform calculations many times faster, from 100 to 1000 times, than to receive data from RAM. This means that while the processor is waiting for data from memory, it is idle for hundreds of cycles, doing nothing. Of course, it would be completely stupid, so modern processors contain several levels of embedded cache. Each time you request a single piece of data from memory, additional adjacent pieces of memory will be written to the processor cache. As a result, with a sequential pass through memory, you can access it almost as quickly as the processor can process information, because chunks of memory will be constantly recorded in the L1 cache. If you move to random memory addresses, then often the cache will not work, and performance can suffer greatly. If you want to know more, Mike Acton’s CppCon report is a great starting point (and a great time).
As a result, arrays have become a better data structure when performance is important, even if, according to analysis “O”, a large array should work slower. Where you wanted to use a tree, a sorted binary search array might be better. Where you would like to use a queue, a growing array may come up better, and so on.
Linked list and dynamic array
When you understand the importance of accessing sequential memory, it will not be a surprise to you that if you need to quickly go through the collection, the array will be faster than a coherent list. Environments with smart memory management and garbage collectors will probably keep the linked list nodes more consistent, but they cannot guarantee this. Using a raw array usually requires more complex code, especially when you need to insert or add new elements, as you have to handle the growth of the array, the movement of elements, and so on. Most languages have native libraries containing one or another implementation of dynamic arrays. In C ++, there is a vector , in C # there is a List (in F # it is used under the name ResizeArray) , and in Java there is an ArrayList . Usually these structures provide the same or similar interface as the linked list. In this article I will call such structures dynamic arrays (Array List), but keep in mind that the examples in C # use the List class, and not the older ArrayList.
What if you need a data structure in which you can quickly insert elements and quickly pass through them? Let's imagine, for this example, that we have such a case: we will insert at the beginning of the collection about 5 times more often than go through it. Let's also imagine that both the coherent list and the dynamic array in our environment have equally pleasant interfaces. It remains only to decide what will be a more effective solution. We can refer to the analysis of "O" big to optimize our valuable time. Let us refer to the useful hint about the “O” large , the corresponding difficulties for these data structures are:
| Pass | Insert | |
|---|---|---|
| Dynamic array | O (n) | O (n) |
| Linked list | O (n) | O (1) |
The problem of dynamic arrays is to insert, at a minimum, each element must be copied and moved one point past the insertion point to make room for the new element. Hence, O (n). Sometimes you need to create a new array, larger in size so that there is a place to insert. In our case, insertion occurs 5 times more often than a pass, so it seems that the conclusion is obvious. As long as n is large enough, a coherent list should generally be more efficient.
Experiment
But to make sure, it is better to count. Let's experiment with C # using BenchMarkDotNet . In C #, there is a LinkedList collection, which is a classic linked list, and a List, which is a dynamic array. The interfaces of both are similar, and both can be easily applied in our case. Consider the worst case for a dynamic array — the insert always occurs at the beginning, so you have to copy the entire array with each insert. The configuration of the test environment is as follows:
Host Process Environment Information: BenchmarkDotNet.Core=v0.9.9.0 OS=Microsoft Windows NT 6.2.9200.0 Processor=Intel(R) Core(TM) i7-4712HQ CPU 2.30GHz, ProcessorCount=8 Frequency=2240910 ticks, Resolution=446.2473 ns, Timer=TSC CLR=MS.NET 4.0.30319.42000, Arch=64-bit RELEASE [RyuJIT] GC=Concurrent Workstation JitModules=clrjit-v4.6.1590.0 Type=Bench Mode=Throughput Test Cases:
[Benchmark(Baseline=true)] public int ArrayTest() { //In C#, List<T> is an array backed list. List<int> local = arrayList; int localInserts = inserts; int sum = 0; for (int i = 0; i < localInserts; i++) { local.Insert(0, 1); //Insert the number 1 at the front } // For loops iterate over List<T> much faster than foreach for (int i = 0; i < local.Count; i++) { sum += local[i]; //do some work here so the JIT doesn't elide the loop entirely } return sum; } [Benchmark] public int ListTest() { LinkedList<int> local = linkedList; int localInserts = inserts; int sum = 0; for (int i = 0; i < localInserts; i++) { local.AddFirst(1); //Insert the number 1 at the front } // Again, iterating the fastest possible way over this collection var node = local.First; for (int i = 0; i < local.Count; i++) { sum += node.Value; node = node.Next; } return sum; } Results:
| Method | The size | Inserts | Median |
|---|---|---|---|
| ArrayTest | 100 | five | 38.9983 us |
| Listtest | 100 | five | 51.7538 us |
The dynamic array wins with a good margin. But this is a small list, “O” large describes the performance of only growing to large sizes n , so the test results should eventually turn upside down with increasing n . Let's try:
| Method | The size | Inserts | Median |
|---|---|---|---|
| ArrayTest | 100 | five | 38.9983 us |
| Listtest | 100 | five | 51.7538 us |
| ArrayTest | 1000 | five | 42.1585 us |
| Listtest | 1000 | five | 49.5561 us |
| ArrayTest | 100,000 | five | 208.9662 us |
| Listtest | 100,000 | five | 312.2153 us |
| ArrayTest | 1,000,000 | five | 2,179.2469 us |
| Listtest | 1,000,000 | five | 4,913.3430 us |
| ArrayTest | 10,000,000 | five | 36,103.8456 us |
| Listtest | 10,000,000 | five | 49,395.0839 us |

Unexpected results for many. No matter how large n , the dynamic array is still better. To make the performance worse, the ratio of inserts to aisles must change, not just the size of the collection. Note that this is not an error of the “O” analysis of a big one, it is just a human error - we incorrectly apply the method. If you go deep into mathematics, then “O” will show a lot that both data structures will grow at the same speed as long as the ratio of inserts to the passes does not change.
Where the tipping point lies depends on many factors, but a good approximate rule is suggested by Chandler Carruth from Google: a dynamic array will be more efficient than a coherent list until the inserts are an order of magnitude larger than the passes. In our case, the rule works well, because with a 10: 1 ratio, you can see a shift towards the linked list:
| Method | The size | Inserts | Median |
|---|---|---|---|
| ArrayTest | 100,000 | ten | 328,147.7954 ns |
| Listtest | 100,000 | ten | 324,349.0560 ns |
The devil is in the details
The dynamic array wins because the numbers that pass through are in memory sequentially. Each time a number is requested from memory, a whole set of numbers is added to the L1 cache, so the next 64 bytes of data are ready for processing. When working with a linked list, each node.Next call redirects a pointer to the next node, and there is no guarantee that this node will be in memory immediately after the previous one. Therefore, sometimes we will get past the cache. But we do not always have to work with types that store values directly, especially in object-oriented languages, where the passage often takes place on reference types. In this case, despite the fact that in the dynamic array the pointers themselves are in memory sequentially, the objects to which they point are not. The situation is still better than with a coherent list, where you have to dereference the pointers for each item twice, but how does this affect the overall performance?
Performance deteriorates significantly, depending on the size of objects and the features of hardware and software. If in the example above, the numbers are replaced with small objects (12 bytes), then the “break point” drops to 4 inserts in one pass:
| Method | The size | Inserts | Median |
|---|---|---|---|
| ArrayTestObject | 100,000 | 0 | 674.1864 us |
| ListTestObject | 100,000 | 0 | 1,140.9044 us |
| ArrayTestObject | 100,000 | 2 | 959.0482 us |
| ListTestObject | 100,000 | 2 | 1,121.5423 us |
| ArrayTestObject | 100,000 | four | 1,230.6550 us |
| ListTestObject | 100,000 | four | 1,142.6658 us |
Managed C # code suffers greatly in this case, because going through a dynamic array creates unnecessary checks on the array boundaries. A vector in C ++ is likely to work more efficiently. If we are quite aggressive in solving this problem, then we can write a faster class for the dynamic array using the unsafe C # code to avoid checking the bounds of the array. The relative difference will also depend heavily on how the memory allocator and the garbage collector manage dynamic memory, how large objects are and other factors. Larger objects usually improve the performance of dynamic arrays in my environment. When it comes to whole applications, the relative performance of dynamic arrays can also improve with increased fragmentation of dynamic memory, but to be sure, testing is needed.
One more thing. If objects are quite small (from 16 to 32 bytes or less in different situations), then it is worth considering the option of storing them by value ( struct in .NET), and not in the object. This will not only greatly improve performance due to consistent memory allocation, but also theoretically reduce the additional workload due to garbage collection, depending on the usage scenario for this data:
| Method | The size | Inserts | Median |
|---|---|---|---|
| ArrayTestObject | 100,000 | ten | 2,094.8273 us |
| ListTestObject | 100,000 | ten | 1,154.3014 us |
| ArrayTestStruct | 100,000 | ten | 792.0004 us |
| ListTestStruct | 100,000 | ten | 1,206.0713 us |
Java can show better results here because it automatically makes smart changes to small objects, or you can simply use separate arrays of primitive types. And although this is very tedious to write, it can be faster than an array of structures. It all depends on the specifics of accessing the data in your code. Keep this in mind when performance is especially important.
Make sure the abstraction justifies itself.
Often people do not agree with such conclusions, and their arguments are the purity of the code, correctness and maintainability. Of course, each sphere has its own priorities, but I believe that when abstraction only slightly improves cleanliness when, and performance suffers greatly, you need to make it a rule to choose performance. If you do not regret the time to study the environment, then you can learn about cases where there is a faster and no less clear solution, as is often the case with dynamic arrays instead of lists.
Things to think about: here are seven different ways to find the sum of a list of numbers in C #, with execution time and memory usage. Everywhere overflow checking arithmetic is used, so that the comparison with Linq, where the Sum method uses just such arithmetic, is correct. Notice how much better the method is faster than others Notice how costly the most popular way. Note that the foreach abstraction works well with arrays, but not with dynamic arrays or linked lists. Whatever your language and environment, it is important to understand these details in order to make the right decisions by default.
| Method | Length | Median | Bytes Allocated / Op |
|---|---|---|---|
| LinkedListLinq | 100,000 | 990.7718 us | 23,192.49 |
| RawArrayLinq | 100,000 | 643.8204 us | 11,856.39 |
| LinkedListForEach | 100,000 | 489.7294 us | 11,909.99 |
| LinkedListFor | 100,000 | 299.9746 us | 6,033.70 |
| ArrayListForEach | 100,000 | 270.3873 us | 6,035.88 |
| ArrayListFor | 100,000 | 97.0850 us | 1,574.32 |
| RawArrayForEach | 100,000 | 53.0535 us | 1,574.84 |
| RawArrayFor | 100,000 | 53.1745 us | 1,577.77 |
[Benchmark(Baseline = true)] public int LinkedListLinq() { var local = linkedList; return local.Sum(); } [Benchmark] public int LinkedListForEach() { var local = linkedList; int sum = 0; checked { foreach (var node in local) { sum += node; } } return sum; } [Benchmark] public int LinkedListFor() { var local = linkedList; int sum = 0; var node = local.First; for (int i = 0; i < local.Count; i++) { checked { sum += node.Value; node = node.Next; } } return sum; } [Benchmark] public int ArrayListFor() { //In C#, List<T> is an array backed list List<int> local = arrayList; int sum = 0; for (int i = 0; i < local.Count; i++) { checked { sum += local[i]; } } return sum; } [Benchmark] public int ArrayListForEach() { //In C#, List<T> is an array backed list List<int> local = arrayList; int sum = 0; checked { foreach (var x in local) { sum += x; } } return sum; } [Benchmark] public int RawArrayLinq() { int[] local = rawArray; return local.Sum(); } [Benchmark] public int RawArrayForEach() { int[] local = rawArray; int sum = 0; checked { foreach (var x in local) { sum += x; } } return sum; } [Benchmark] public int RawArrayFor() { int[] local = rawArray; int sum = 0; for (int i = 0; i < local.Length; i++) { checked { sum += local[i]; } } return sum; } ')
Source: https://habr.com/ru/post/308818/
All Articles