Project Life in Production: Operational Tips

An important point that is often overlooked by developers is the operation of the project. How to choose a data center? How to predict threats? What can happen at frontend level? How to balance front-end? How to monitor? How to set up logs? What metrics are needed?
And this is only a frontend, and there is also a backend and a database. Everywhere there are different laws and logic. More information about the operation of highload projects in the report by Nikolay Sivko ( okmeter.io ) from the HighLoad ++ Junior conference.
Project Life in Production: Operational Tips
Nikolay Sivko ( okmeter.io )
I want to tell you about the operation. Yes, the HighLoad conference is more about development, how to cope with high loads, etc. etc. - the organizers gave me such an introduction, but I want to talk about fault tolerance, because, in my opinion, this is also important.
It is necessary to begin with the statement of the problem - the definition of what we want.

There will be no rocket science, no particularly top-secret recipes I will give. I will base on the fact that the intended public is novice exploiters. Therefore, it will be just a summary of how to plan for fault tolerance.
At the entrance we have a website, and we will assume that he makes money. Accordingly, if the site is turned off and is not available to users, then it does not earn money, and this is a problem. Here we will solve it. How much money he earns is a question, but we will try to do everything we can for not enormous money, i.e. we have a small budget, and we decided to spend some time on fault tolerance.

')
We must immediately limit ourselves in desires, i.e. make four nines, five nines immediately not worth it. We will rely on everything that data centers offer us - they have a different level of certification, the data center design is certified, i.e. as far as everything is fail-safe there, and we probably will not try to jump further than TIER III, i.e. eight minutes of downtime per month, 99-98% uptime will come down to us. Those. we are not going to reserve a data center yet.

In reality, when the data center is certified slightly lower than TIER III (or rather, I do not remember which order), then in fact the data centers in the modern world work quite well. Those. in Moscow, to find a data center that works steadily from year to year, as they say, without a single gap, is not difficult. You can google, you can ask for feedback. As a result, you got up somewhere and put your iron. But everything that breaks inside the data center is more likely to fail, i.e. Iron breaks, software breaks. The software that was not written by you breaks down a bit less often, because there is a community, sometimes there is a vendor that monitors fault tolerance, but the software that you wrote is likely to break more often.

We need to start somewhere. Let's say there is a dedicated server for 20 thousand rubles a month, from this we will dance. On it, we have a bunch of everything: the frontend, the backend, the base, some ancillary services, memcached, the queue with asynchronous tasks and the handlers that rake them up and make them. Here? We will work with this, and, in order.

Approximate algorithm - we take each subsystem, we approximately estimate how it can break, and we think how it can be repaired.
I must say - to fix everything is unreal. If it were possible to fix everything, there would be 100% uptime, and all this would not be necessary. But let's try everything we can quickly close.
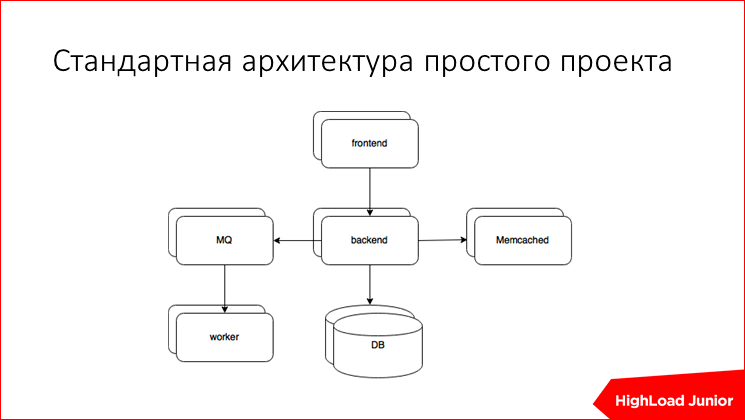
Accordingly, how does the average project work, starting from the year 2000? There is a backend, there is a frontend, memcached often, but it doesn’t matter, the message queue, the handlers and the base. If there is something else that we have not covered, approximately understanding the algorithm, you can do it yourself.

Frontend. What is it for? It accepts all incoming requests, is committed to serving slow clients, somehow optimizing the load on our fatter backend, giving statics on its own from the disk, doing services to Transport Layer Security, in this case, to sites with respect to https, proxies requests for backends, balancing between backends, sometimes there is a built-in cache.

What can happen? The piece of iron on which at you Nginx or other frontendovy server can stupidly break. Nginx itself may die or something on this machine for various reasons. It can blunt everything, for example, you have rested against resources, have rested against a disk, etc. And in the end everything slows down. Let's start to solve it.

The frontend in itself does not carry any condition, as a rule. If this is not the case, then I advise you to fix it urgently. If he is stateless, i.e. it does not store data, the client is not obliged to come with his requests only to him, you can put several pieces of iron and, in fact, organize balancing between them.
What are the difficulties? As a rule, everything that happens above is not our area of responsibility, we cannot twist anything there, there is already a provider who gave us the string that we stuck into our server.

There are ways to do something about this too. The first, most primitive thing you can do without having any skills is the DNS round robin. Just for your domain, you specify several IPs, one IP of one frontend, another - of another, and everything works.
The problem here is that the DNS does not know whether the server you registered there is working or not. If you even teach the DNS to know about it and not give a broken IP in the response, you still have the DNS cache, there are crookedly configured caches for different providers, etc. In general, you should not pledge the fact that you quickly change the DNS. The reality is that even if you have a low TTL registered in the DNS, clients will still break into a non-working IP.
There are technologies that are generally called Shared IP, when one IP address is used between several servers, which you register in the DNS. Implementation of protocols such as VRRP, CARP, etc. Just google how to do it, then it will be clear.
The problem here is what? You need the provider to ensure that both servers are in the same Ethernet segment, so that they can transfer service heartbeats and so on.
And yet - it does not provide you with load balancing, i.e. Your backup server will always be idle. The solution is simple - we take two servers, take two IP, one master for one, another master for another. And they insure each other. And in the DNS we register both, and everything is fine.

If you have in front of these servers some kind of a router or another network piece of hardware that can do routing, you can prescribe such simple hints for Cisco, let's say, equivalent routes and somehow make these routes get rid of the hardware, server is down. For Juniper, this can be done using BFDd. But, in general, these words will be available - google and master it.
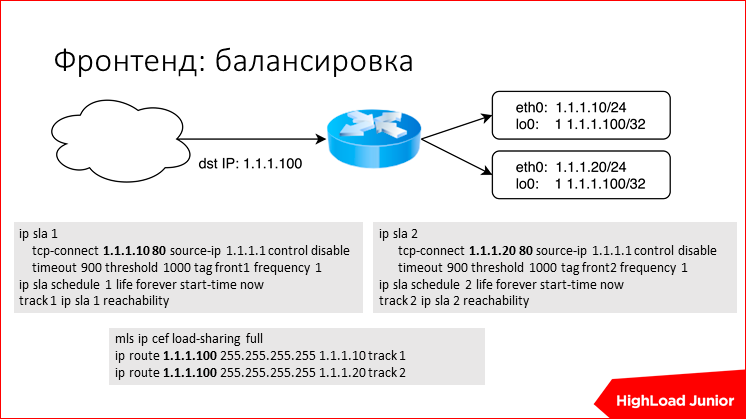
Something like this works through Cisco. These are pieces of a config. You announce one IP-address, and it has two routes - through one server and through the other. Is the target IP hanging on each frontend on a lowback interface? and somehow the check validation logic is provided. Cisco itself is able to check the status of the router, for example, it can check the CB-connection on the Nginx port or something else, or just trite ping. Everything is simple, it is unlikely that someone in a small project has its own router.

Everything we do needs to be monitored at the same time because, despite how it reserves itself, you need to understand what is happening in your system.
In the case of frontends, monitoring by logs works very well, i.e. your monitoring reads logs, builds histograms, you start to see how many errors you give to your users and see how fast your website works.
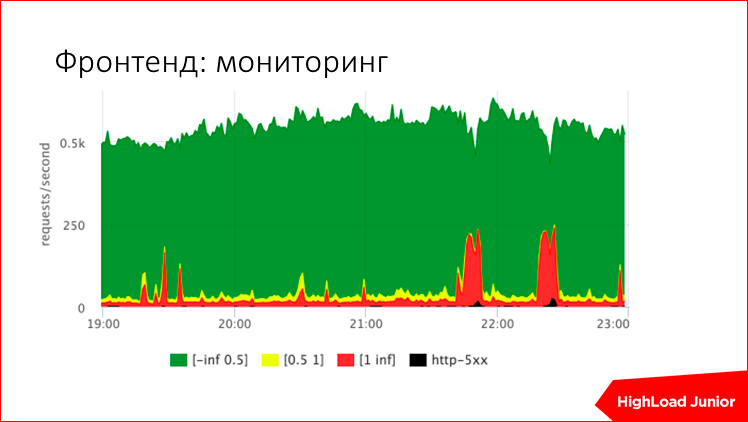
About this picture is very revealing. You see on the Y axis requests per second to your site. In this case, about 500 requests per second. In a normal situation, there are slow requests - they are marked in red - these are requests that are processed longer than a second. Greens are those that are faster than 500 ms, yellows are something in the middle, and black is errors. Those. immediately you see how your site works - just like 5 minutes ago or not. There are two red outliers - this is just a problem. This slowed down the site, somewhere in the eye 30-40% of user requests were stupid.

So, according to these metrics, you can set up alerts that will uniquely tell you how your site works - good or bad. For example, here are the thresholds. Those. if for a site with 200 requests per second errors are more than 10 requests per second, then this is a criticized alert. If the percentage of slow requests that are more than a second, more than five, for example, then this also criticized the alert.
So, we covered the whole site with monitoring. Well, not the whole site, but, in principle, the state of the site and, in general, we can go further.

So, on this layer, we somehow closed two problems by reserving the frontends, we are checking the frontend and service on it on the way. We have closed two problems; we will not solve the third problem, because it is difficult, because we need to rely on metrics in decision making. We simply monitor it, and if we have a problem, we come and sort it out with our hands. This is already 10 times better than nothing.

Go ahead. Backend. What is the backend for? It collects, receives data, as a rule, from some storages, from a database, somehow converts it and gives the answer to the user. Accordingly, there is some part of the requests when we are waiting for someone. There is a part when we calculate something, let's say we render the template and just give the answer to the user.

We write out the risks: the piece of iron has broken, the server itself has died up, there are problems with the services from which the backend takes data, i.e. Tupit database, tupit something else, stupid due to the fact that we ourselves do not have enough resources, stupid from the fact that we received more requests than we can physically serve. I wrote it out, but maybe not everything, I give you an approximate algorithm.

We start to think and close.
Backend is also better to do stateless and store user sessions on disk, etc. Thus, you simplify the task of balancing, i.e. You can not bathe, where to send the next user request. We can put a few pieces of iron and make balancing on the front end.

To protect yourself from a large number of requests for each backend, you need to understand what the limit of backend performance is and configure the limits in it. Suppose there is a limit in apache that you can configure, that is, for example, “I take only 200 parallel requests and no longer take. If more has come, I give “503” - this is an intelligible status that I can no longer serve the request now. ” Thus, we show the balancer or, in our case, the frontend, that the request can be sent to another server. Thus, you do not suffer from overload - if your system is completely overloaded, you give the user "503" - a clear error like "Dude, I can not." This is instead of all requests being blunted and hanging on hold, and customers do not understand what is happening at all.
Also a moment that everyone forgets. In projects that are developing rapidly, they forget to check timeouts for everything, i.e. set timeouts. If the input of your backend goes somewhere outside, let's say in the memcached database, you need to limit how much you will wait for a response. You can not wait forever. Waiting for, say, a postgress response, taking a connection with it, taking some resources, and you need to fall off in time, say: “That's all, I can’t wait any longer” and give the error up. Thus, you exclude situations when everything is dull with you, there is nothing in the logs, because all operations are in progress, and you do not understand what is happening. It is necessary to limit timeouts and treat them very carefully, then you will get a more manageable system.

Balancing. In this case, just. If you have Nginx on the frontend, then you just prescribe a few upstream. Again, about timeouts - for lokalki connection, the timeout should not be seconds, but tens of milliseconds, or even less, you have to look at your situation. Speak, in which cases to repeat requests to a neighboring server. Limit the number of retrae, so as not to cause a storm. The big question is whether to retract requests for data modification, posts, etc. Here, with fresh versions of Nginx, they do not default to such requests as POST, i.e. no idempotent queries. And this, in principle, is good, everyone has been waiting for this pen for a long time and, finally, it has appeared. There you can customize other behavior if you want to retract posts.

About the backend - we are also trying to monitor it at the same time. We want to understand whether the process is alive, whether the socket TCP listen is open, which we expect the service to service, whether it responds to some special handle that checks its status, how much the service consumes, how much CPU it uses, how much it i have allocated memory, how much it sits in the swap, the number of descriptor files that it has opened, the number of I / O operations on the disk, in pieces, in traffic, etc., in order to understand whether it consumes more or as usual. It is very important to understand, and it is important to understand this in time in order to compare with previous periods.
Specific runtime metrics for Java are the heap state, the use of memory pools, garbage collection, how many of them there were in pieces, how many were there in seconds, per second, etc.
For Python, there are their own, for GO'shki - their own, for everything related to runtime, there are separate metrics.

You need to understand what the backend was doing, how many requests it took. This can be shot in the log, it can be shot in statsd, the timings for each request, you need to understand how much time was spent on a particular request, how many errors were there. Some of these metrics, in principle, see the frontend, because it acts as a client for the backend, and he sees if there was a mistake or a normal response. He sees how much he was waiting for an answer. We must surely measure and log how much the backend was waiting for all the services that stand outside of it, i.e. this is the base, memcached, nosql, if it works with the queue, how many took to put the task in the queue. And the time taken by some tangible pieces of the CPU, for example, rendering a template. Those. we write to the log: “I render such a template, it took me 3 ms,” that's all. Those. we see and can compare these metrics.
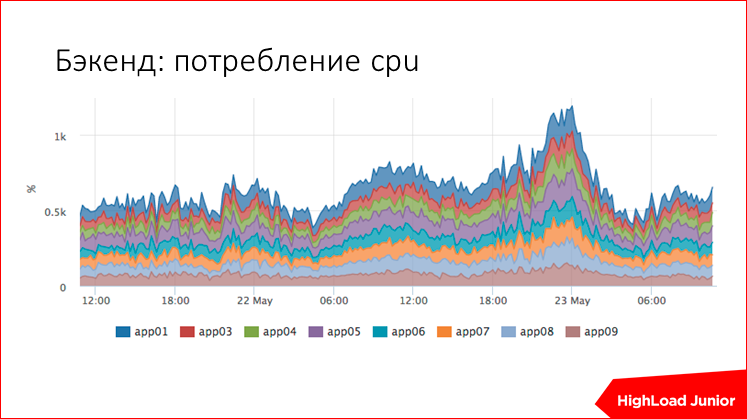
Here is an example of how we measure CPU usage ruby in one of the projects. This is a summary schedule for all hosts; there are nine backends here. We immediately see that we have some abnormal resource consumption here or not.
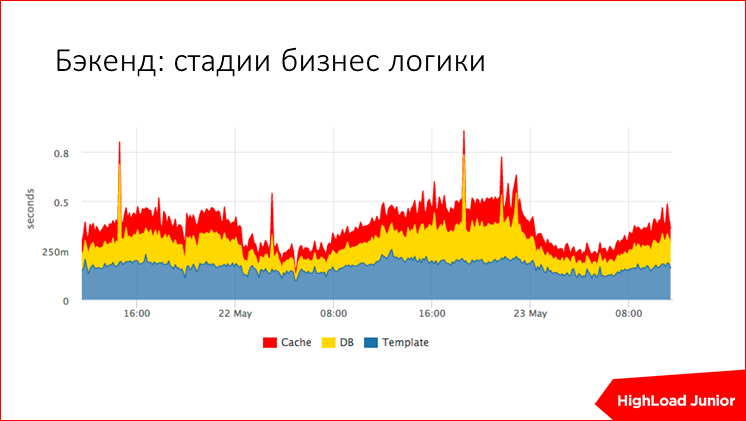
Or, say, the request processing stage. Here a third of the time is taken by standardization, we measured it. And the rest is about a third, this is waiting for the database and waiting for the cache. Immediately in sight, if we have a surge, let's say. Here there is a jolt in the center, when we have dulled the cache, in another surge we have a dull base, for example, it is yellow, i.e. it is immediately clear who is to blame, and it’s not necessary to search for anything for a long time.

Total, we closed the case with the breakage of iron, we closed the case so that the service died, because the balancer ceases to balance on this host, and there are no problems. We monitored the case when the base and other resources are tupit, because we measured, and also measured the number of errors. We measured the consumption of resources and understand that, for example, if we slow down rendering, we look at how much more CPU process there is, ruby or something else. We are also monitoring it. In principle, we have everything under control. Because of the greater number of requests, we closed with restrictions, limits, so here, in principle, everything is also not bad.

According to the database. What is her task? It stores your data, that is, as a rule, the central data storage point is the base. Perhaps, nosql, but we do not take it into account yet. It responds to realtime requests from the user, i.e. from the backend to the pages that the user is waiting for, and she does some analytical processing of requests, i.e. somewhere in your nighttime the cron is triggered, it calculates how much you are doing there, etc.

What can happen to the base? As always - the piece of iron broke, without this, nowhere, the pieces of iron break. By the way, the statistics says that it’s impossible to expect that your piece of iron will work forever, despite all the reserves and so on, you must always allow this risk, and it will be correct and smart.
Loss of data due to the pieces of iron, when we had data in a single copy, and the piece of iron died, we lost everything ... Or the piece of hardware is alive and some delete has come, or the data has somehow somehow been cached - this is a completely separate risk.
The service died, well, postgress was nailed by oom killer or mysql - we also need to somehow understand that this is happening.
The brakes are due to lack of resources, when you send requests to the database so much that, in principle, it cannot cope with the CPU or the disk, etc.
Due to the fact that you sent 10 times more requests than the calculated ones, say, sent some traffic there, etc.
Brakes due to curve queries - if you do not use indexes, or your data is somehow wrong, you also get brakes.

Let's try to do something with it.
Replication Replication is always needed. There are almost no cases when you can do without replication. We just take it and set it up to another server in master-slave mode and nothing more needs to be invented yet.
The main workload of most projects is reading. In principle, if you ensure read only the constant, stable operation of your site, then your superiors or you will be immensely pleased. It is already 100,500 times better than nothing than falling.

You can immediately unload all the SELECTs that are not sensitive to replication lag. What it is? The data on the replica does not go right away, but with a certain delay, depending on various reasons, ranging from the bandwidth of the channels to the replica there. Requests that are requested by anonymous users, state, say, a directory — they are not sensitive to replication lag. If the data is delayed and the user gets irrelevant, nothing bad will happen. And if a user fills in his profile and presses submit on a form, and you show him data that has not changed yet, let's say you took it from the replica, then this is already a problem. In this case, SELECT must be done from the wizard. But most of the load still goes to the replica. And applications need to be taught that there is a replica, that it is lagging behind, at the same time, in addition to fault tolerance, you solve the problem of scaling the load on the read operation.
To access the replica you can put a lot of replicas, and it is easy. You can either unbalance incoming requests to these replicas, or teach the application to know that it has 10 replicas. It is quite difficult and, as I understand it, standard tools and all kinds of frameworks do not know how to do this, you need to program a little. But you get the opportunity to balance, do retracts, i.e. if you make a user request and, say, replicas are behind your balancer, you get an error or timeout, you cannot make an attempt, because there is a chance that you will get to the same dead server. Accordingly, you can teach the backend to know about 10 replicas, and if one of the replicas is lying, try another and, if it is alive, give the user his answer without error, and that is cool. This is cleaning out such small-small problems, i.e. also work on uptime.
You need to understand what to do if the master is dead, and you have a reply. First, you need to decide that you will switch.

Suppose your server is dead, he has a panic there, he dies once every three years. Then it’s just better for you to zarebut it, wait until it rises, and don’t plan all this garbage with switching, because it’s not free, it takes time, and it’s quite risky.
If you do decide to switch, we reconfigure our backends to the replica, i.e. we send the whole record to one of the replicas. If this is a normal database (postgress), then in replica mode it will return errors for all modifying requests, inserts, updates, etc. And it does not matter. Then you, if necessary, wait until everything from the master to the replica reaches the end. If he is alive. If he is still lifeless, then there is nothing to wait for.
You must finish the master if he is alive. Those. it is better to finish it so that such an incident does not happen, that someone writes to the disabled, old master and thus not to lose data. Thus upgrade slave to master. This is done differently in different solutions of database management systems, but there is a streamlined procedure.
If there are still replicas, they need to be switched to the new master and, if you want to attach the old server somewhere, then turn it on as a replica.

In total, we have roughly considered what is happening and, in my opinion, what we have said is quite a swift operation, and I don’t want to do it on the machine, well, personally to me. I would not dare. It is better, nevertheless, to minimize the chance that you will have to switch and buy or rent better hardware or do something else. Those. we stupidly reduce the likelihood that the master is dead.
Be sure to write instructions on how to switch the master in steps. This will have to be done by a half-asleep person at four o'clock in the morning, who is in a stressful situation, he has a business related to the site, and he should not be particularly bothered to think what he is doing. He must, of course, think, we still do not quite hire boots, but turn on the brain to a minimum. Because it is a stressful situation.
Be sure to test this instruction. Untested instructions are not instructions. So, we test the instruction, arrange the exercises, i.e. we wrote instructions, we cut down the master, and we train, we do everything strictly according to the instructions and do not invent anything along the way. If something goes wrong with you, we append the instructions immediately.
Along the way, we measure time. We need to measure the time to ensure that we cope with a similar problem in 30 or 15 minutes, or the total downtime is one and a half minutes, after the person came in, opened the laptop, went off-line and drove.
The next time, if you changed the instructions, you need to hold repeated exercises. If you are not satisfied with the time that ended up as a result of downtime, you can try to do something with it, optimize some steps, provide parallel copying of files somewhere or something else. Just when you look at the steps, measure how much each step takes, and stir up some kind of optimization.

Separately, it is worth noting such a captain thing that replication is not a backup. If you receive a request that kills the data, it will get to the replica too, and you will lose everything. If you need to save data at all, then you need to make a backup.
Backups, again, for different databases are done differently. There are full backups, which are usually not made every second, there is the possibility of a backup, which you can catch up with daily dump or daily copy of data files using write ahead log or bin log or something else ... These bin logs need to be copied to the side neatly .
, , , , — , - , , .
, , , , — . , . Those. , , , , . , , -, , ?

— , , , , , , / , , listen socket, .
, 5 . . - , - , postrgess , CPU, . - , , , , 500 , , , , ? - , , , . , , , , , , CPU, .
— . , — , — , . , -, 1 — . , , .. . , - , .
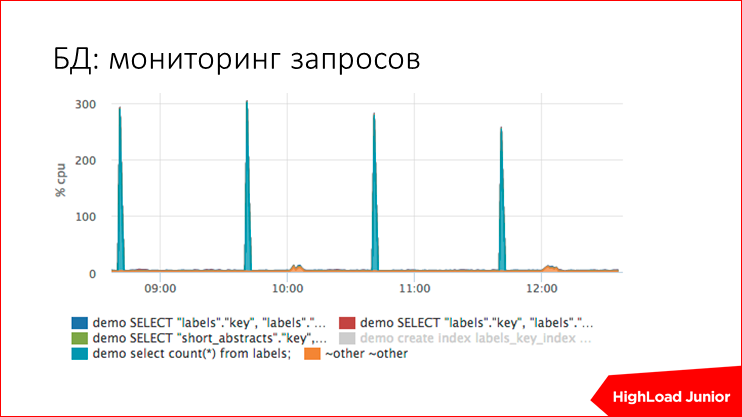
postgress . — - . , , , , ..
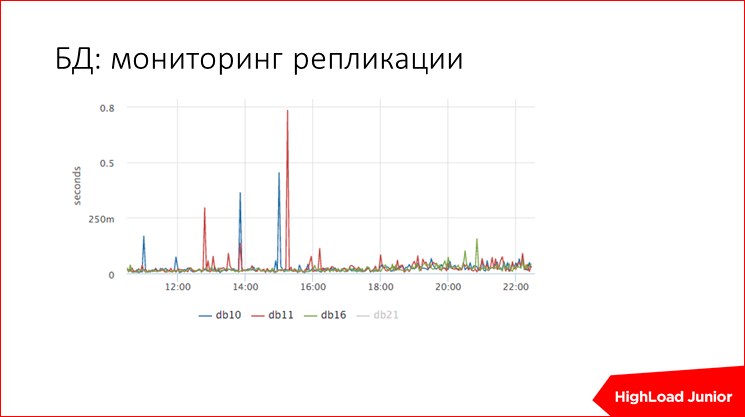
. Those. , , -, - , 800 , 50 .

.
- delete' — , , . , .
, , — , , read only .
- — . - . , . - .
, , 3 , , 5 , 8 . , . , , « 15 » — , , .

memcached, , , . memcached , .
, . Those. , , , 10 , .

, , , , memcached, - - - . .

emcached , , . - , . , -, , , , , . , , memcached , , , .
, , , , , , , , , , , , , , . , . , , , expire, , , - .

, , . , , , memcached , ? , , , , , , n , . , , , memcached? , , , , . , . Those. , , — , , ?
, . Those. - , , , , , , ? , , .
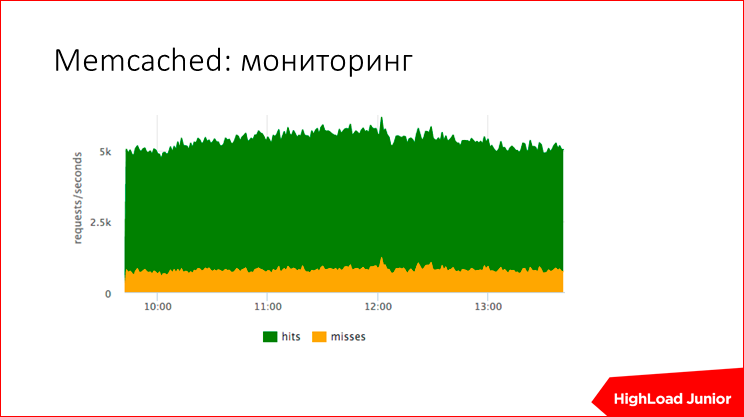
memcached , .. , - , , - . , , 98% , .

. , , memcached, latency … , -, , . , - — , . . . memcached , , , - .
— . , .

. ? - , , - , . , Message Queue. publisher — , , consumer — , - ..

.
. «», , -, .
, , 2 . — , .
— , .
, publisher , , , - , , , , , , .
- .

, , .. — , — . , , , , , . . , . -, , , , , , , , - .
, , , , , 3 , , , -.

, , , . , 10 . . ? . Those. , , , . , , , , , , , . , , , - , , , . , , .
, ?

, , , — , ? , .. , , , , , - , -.
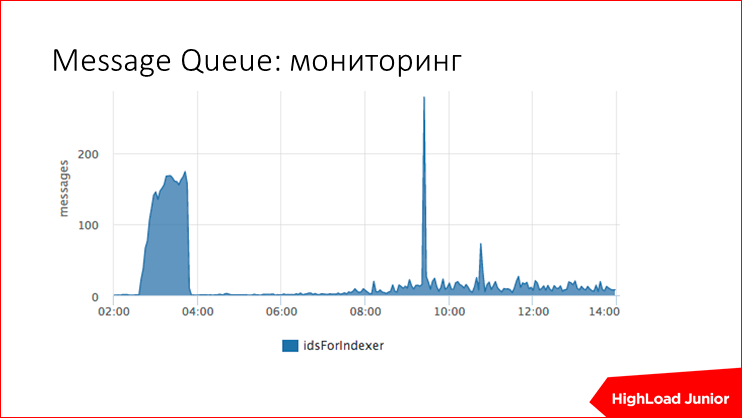
— , .. , , .

— , .. . , , , ..

To summarize , . , , - , - , , , .

20 . . per month. , , , - — , .. uptime . , , , — , , .

. — . , , , , , . Load Balancing, . , — . , 5 , - SLA .
, . , , CPU, , — , . , — , , , , , -, , , , , . , , , , .

Still, if you want to protect against the departure of the data center, then everything is exactly the same - you simply put backup glands in another data center, set up replication there, and you also need to deploy a new code there. If we are talking about backends, you need to fill in static data there, well, just work with servers in several DCs. You can make fault tolerant traffic either by switching the manual DNS, in case your data center is dead, or by using routing, BGP and your address blocks.

We summarize everything that I told you today.
The most important thing is to understand the risks, i.e. you just write out the risks, you can do nothing with them right now, but if you have a list, then this is already very good. If you see that the risk is simple and it is very easy to close it right now, in 5 minutes, do it, your list is reduced, and the possible problems you need to remember, it becomes less. If the scenario is complicated, try to reduce the likelihood of this risk triggering, if you cannot do this, then you can close some part of this problem, if you’re right at all, leave it to manual intervention, if you want to work out manual intervention to automatism, then write instructions, conduct exercises.
Thus, if you have plans, then you are already tired of failover. Everything else is just optimization and reduced downtime.

Contacts
Nikolay Sivko, nsv@okmeter.io . Company blog okmeter.io on Habré.
Additional Information
Not enough information? Or it is not clear at what point to connect these or other tips of Nikolai? All this we will analyze in detail at the master class of Roman Ivliev on September 6.
Source: https://habr.com/ru/post/308756/
All Articles