What is big data, part 2

In the first part of this series, you learned about data and how computers can be used to derive meaning from large blocks of such data. You’ve even seen something like Amazon.com’s big data from the mid-nineties, when the company launched a technology to monitor and record in real time everything that thousands of customers did at the same time on their website. Quite impressively, but you can call it big data with a stretch, puffy data - more suitable. Organizations such as the US National Security Agency (NSA) and the UK Government Communications Center (GCHQ) have already collected big data as part of spyware operations by recording digital messages, although they did not have a simple way to decipher them and find meaning in them. Libraries of government records were replete with inconsistent data sets.
What Amazon.com did was easier. The level of customer satisfaction could be easily determined, even if it covered all tens of thousands of products and millions of consumers. There are not so many actions that a customer can perform in a store, real or virtual. The client can see what is available, request additional information, compare products, put something in the basket, buy or leave. All this was within the capabilities of relational databases, where the relationship between all types of actions can be set in advance. And they must be set in advance, with which relational databases have a problem - they are not so extensible.
Know in advance the structure of such a database - how to make a list of all potential friends of your unborn child ... for life. It should list all unborn friends, because as soon as the list is completed, any addition of a new position will require serious surgical intervention.
Finding relationships and patterns in data requires more flexible technologies.
The first major technological challenge of the Internet of the 90s is to cope with unstructured data. In simple words - with the data that surrounds us every day and before were not considered as something that can be stored as a database. The second task is very cheap processing of such data, since their volume was high and the information exhaust low.
If you need to listen to a million phone conversations in the hope of detecting at least one al-Qaida mention, you will need either a substantial budget or a new, very cheap way to process all this data.
The commercial Internet then had two very similar tasks: searching for all sorts of things on the World Wide Web and paying advertising for the opportunity to find something.
 Search task By 1998, the total number of websites reached 30 million (today there are more than two billion). 30 million sites , each of which contains many web pages. Pbs.org, for example, is a website containing over 30,000 pages. Each page contains hundreds or thousands of words, images and information blocks. To find something on the web, it was necessary to index the entire Internet. This is already big data!
Search task By 1998, the total number of websites reached 30 million (today there are more than two billion). 30 million sites , each of which contains many web pages. Pbs.org, for example, is a website containing over 30,000 pages. Each page contains hundreds or thousands of words, images and information blocks. To find something on the web, it was necessary to index the entire Internet. This is already big data!
For indexing, you first needed to read the entire web, all 30 million hosts in 1998, or 2 billion today. This was done using so-called spiders (spiders) or search robots - computer programs that systematically search the Internet for new web pages, read them, and then copy and drag them back into the index of their contents. All search engines use search robots, and they must work continuously: update the index, keep it up to date with the appearance of new web pages, their change or disappearance. Most search engines maintain an index not only of the current web, but, as a rule, of all older versions, so that if you search for earlier modifications, you can go back in time.
Indexing means recording all metadata — data about data — words, images, links, and other types of data, such as video or audio, embedded in a page. Now multiply that by hundred millions. We do this because the index takes up about one percent of the server it represents - the equivalent of 300 thousand data pages out of 30 million in 1998. But indexing is not a search for information, but only a record of metadata. Finding useful information from the index is even more difficult.
In the first decade of the Internet, there were dozens of search engines, but four were the most important, and each had its own technical approach to obtaining the meaning of all of these pages. Alta Vista was the first real search engine. She appeared in the laboratory of Digital Equipment Corporation, in Palo Alto. Digital Equipment Corporation was actually an informatics lab at XEROX PARC, which was almost fully transported two miles away by Bob Taylor, who built both of them and hired most of the old employees.
 Alta Vista used the linguistic tool to search its web index. And she indexed all the words in the document, for example, in a web page. If you gave him the search for gold doubloons, Alta Vista scanned its index for documents containing the words search, gold and doubloons, and displayed a list of pages ordered by the number of mentions of the requested words.
Alta Vista used the linguistic tool to search its web index. And she indexed all the words in the document, for example, in a web page. If you gave him the search for gold doubloons, Alta Vista scanned its index for documents containing the words search, gold and doubloons, and displayed a list of pages ordered by the number of mentions of the requested words.
But even then there was a lot of shit on the Internet, which means Alta Vista indexed all this shit and did not know how to distinguish good from bad. These were just words, after all. Naturally, bad documents often went upstairs, and the system was easy to inflate, inserting hidden words to distort the search. Alta Vista could not distinguish real words from hidden ones.
 While the advantage of Alta Vista was the use of powerful computers DEC (which was an important point, since DEC were the leading manufacturers of computer equipment), the advantage of Yahoo! was the use of people. The company hired workers so that they could literally browse the web pages all day, index them manually (and not very carefully), and then mark the most interesting ones on each topic. If you have a thousand man-indexers and anyone can index 100 pages per day, then Yahoo could index 100,000 pages per day, or about 30 million per year — the entire universe of the Internet in 1998. It worked great on the World Wide Web until the web has grown to intergalactic scale and has become beyond the control of Yahoo. The early Yahoo system with their human resources did not scale.
While the advantage of Alta Vista was the use of powerful computers DEC (which was an important point, since DEC were the leading manufacturers of computer equipment), the advantage of Yahoo! was the use of people. The company hired workers so that they could literally browse the web pages all day, index them manually (and not very carefully), and then mark the most interesting ones on each topic. If you have a thousand man-indexers and anyone can index 100 pages per day, then Yahoo could index 100,000 pages per day, or about 30 million per year — the entire universe of the Internet in 1998. It worked great on the World Wide Web until the web has grown to intergalactic scale and has become beyond the control of Yahoo. The early Yahoo system with their human resources did not scale.
 Excite soon appeared, it was based on a linguistic stunt. The trick is that the system was looking not for what the person wrote, but for what he really needed, because not everyone could precisely formulate the request. Again, this task was formed in the conditions of a shortage of computing capabilities (this is the main point).
Excite soon appeared, it was based on a linguistic stunt. The trick is that the system was looking not for what the person wrote, but for what he really needed, because not everyone could precisely formulate the request. Again, this task was formed in the conditions of a shortage of computing capabilities (this is the main point).
Excite used the same index as Alta Vista, but instead of counting how often the words "golden" or "duplon" are found, six Excite employees used an approach based on the geometry of vectors, where each query was defined as a vector consisting of query conditions and their frequencies. A vector is just an arrow in space, with a starting point, a direction and a length. In the Excite universe, the starting point was the complete absence of the required words (zero "search," zero "gold" and zero "duplon"). The search vector itself began from point zero-zero-zero with these three search conditions, and then expanded to, say, two search units, because so many times the word search found in the target document, thirteen units of gold and be five - "doubloons." It was a new way of indexing the index and the best way to describe the stored data, because from time to time it led to results that did not directly use any of the required words — something that Alta Vista could not do.
Excite web index was not just a list of words and the frequency of their use, it was a multidimensional vector space in which the search was considered as a direction. Each search was one thorn in the data hedgehog and Excite's ingenious strategy (by the genius of Graham Spencer) was to capture not one, but all the thorns next door. Covering not only fully compliant documents (like Alta Vista), but all of the similarly formulated conditions in a multidimensional vector space, Excite was a more useful search tool. He worked on the index, used the mathematics of vectors for processing and, more importantly, almost did not require calculations to get the result, because the calculations were already made during the indexing process. Excite gave better and faster results using primitive iron.
But google was even better.
 Google made two improvements to the search - PageRank and cheap iron.
Google made two improvements to the search - PageRank and cheap iron.
The advanced vector approach Excite helped to display the desired desired results, but even its results were often useless. Larry Page of Google came up with a way to evaluate utility with an idea based on trust, which led to greater accuracy. A Google search at the beginning used linguistic methods like Alta Vista, but then added an additional PageRank filter (named after Larry Page, noticed?), Which accessed the first results and ranked them according to the number of pages with which they were associated. 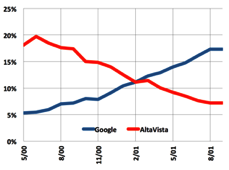 The idea was that the more page authors bothered to give a link to this page, the more useful (or, at least, interesting, even if in a bad sense) was the page. And they were right. Other approaches began to die off, and Google quickly entered the trend with its PageRank patent.
The idea was that the more page authors bothered to give a link to this page, the more useful (or, at least, interesting, even if in a bad sense) was the page. And they were right. Other approaches began to die off, and Google quickly entered the trend with its PageRank patent.
 But there was another detail that Google implemented differently. Alta Vista came from Digital Equipment and worked on a huge cluster of minicomputers VAX from DEC. Excite used the power of UNIX hardware from Sun Microsystems. And Google was launched only with the help of free software, open source, on computers a little more powerful than personal ones. In general, they were smaller than PCs, because Google’s self-made computers didn’t have any cases or power sources (they were literally powered by car batteries and charged by car chargers). The first modifications were bolted to the walls, and later they were stuffed with racks, like baking sheets with fresh pastries in industrial ovens.
But there was another detail that Google implemented differently. Alta Vista came from Digital Equipment and worked on a huge cluster of minicomputers VAX from DEC. Excite used the power of UNIX hardware from Sun Microsystems. And Google was launched only with the help of free software, open source, on computers a little more powerful than personal ones. In general, they were smaller than PCs, because Google’s self-made computers didn’t have any cases or power sources (they were literally powered by car batteries and charged by car chargers). The first modifications were bolted to the walls, and later they were stuffed with racks, like baking sheets with fresh pastries in industrial ovens.
Amazon created a business case for big data and developed an awkward way to implement it on hardware and software, not yet adapted for big data. Search companies have greatly expanded the size of practical data sets, while mastering the indexing. But the real big data could not work with the index, they needed actual data, and this required either very large and expensive computers, like at Amazon, or a way to use cheap PCs that look like a giant computer at Google.
Bubble dotcom. Let's imagine the euphoria and childishness of the Internet in the late 1990s, during the period of the so-called dot-com bubble. It was clear to everyone, starting from Bill Gates, that the future of personal computers and, possibly, business was the Internet. Therefore, venture capitalists have invested billions of dollars in Internet startups, not thinking too much about how these companies will actually make money.
The Internet was viewed as a giant territory, where it was important to create as large companies as possible, as quickly as possible, and to capture and retain a stake in the business, regardless of whether the company has a profit or not. For the first time in the history of the company began to enter the stock market, not earning a penny of profit for the time of their existence. But it was perceived as the norm - the profit will appear in the process.
The result of all this irrational exuberance was the revival of ideas, most of which would not have been realized at other times. Broadcast.com, for example, thought of broadcasting television via dial-up to a huge audience. The idea didn't work, but Yahoo! still bought it for $ 5.7 billion in 1999, which made Mark Kuban the billionaire he still remains today. 
We believe that Silicon Valley was built according to Moore's law, thanks to which computers constantly became cheaper and more powerful, but the dot-com era only pretended to use this law. In fact, it was built on the hype .
The hype and the law of Moore. In order for many of these Internet frauds of the 1990s to succeed, the cost of data processing had to fall dramatically below what was possible in reality, according to Moore's law. This is because the business model of most dotcom startups was based on advertising, and the amount that advertisers were willing to pay had a strict limit.
For a time, it didn’t matter, because venture capitalists and then Wall Street investors were willing to make up the difference, but in the end it became obvious that Alta Vista, with its huge data centers, would not be able to profit only from search . Like Excite, and any other search engine of the time.
The dotcoms in 2001 collapsed due to the fact that startups ran out of money from unsuspecting investors who supported their advertising campaigns in the Super Bowl. When the last dollar of the last fool was spent on the last office chair from Herman Miller, almost all investors had already sold their shares and left. Thousands of companies collapsed, some of them overnight. Amazon, Google and a few others survived because they understood how to make money online.
Amazon.com was different in that Jeff Bezos's business was e-commerce . And it was a new kind of trade, which was supposed to replace bricks with electrons. For Amazon, savings in real estate and wages have played a big role, as the company's profit is measured in dollars per transaction. And for the search engine — the first use of big data and a real Internet tool — the advertising market paid for less than a cent per transaction. The only way to do this was to understand how to break Moore's law and reduce the cost of data processing more strongly, and at the same time link the search engine with advertising and increase sales. Google handled both tasks.
The time has come for the Second Wonderful Advent of big data, which fully explains why Google today is worth $ 479 billion, and most of the rest of the search companies are long dead.

GFS, Map Reduce and BigTable. Since Page and Brin were the first to realize that creating their own super-cheap servers was the key to the company's survival, Google had to build a new data processing infrastructure to make thousands of cheap PCs look and work like one supercomputer.
When other companies seem to have lost money in the hope that Moore's law will work at some point and turn them into profitable, Google has found a way to make its search engine profitable by the end of the 90s. This included the invention of new machine, software and advertising technologies. Google’s activities in these areas directly led us to the world of big data, the formation of which can be observed today.
Let's first look at the scope of today's Google. When you search for something through their search engine, you first interact with three million web servers in hundreds of data centers around the world. All that these servers do is send images of pages to your computer screen, on average, 12 billion pages per day. The web index is stored additionally on two million servers, and another three million servers contain actual documents integrated into the system. All together - eight million servers, excluding YouTube.
The three key components in Google's penny architecture are their file system or GFS, which allows all these millions of servers to access what they consider to be ordinary memory. Of course, this is not just a memory, but its crushed copies, called fragments, but the whole trick in their commonality. If you change the file, it must be changed on all servers at the same time, even to those that are thousands of kilometers apart.
So, a huge problem for Google is the speed of light.
MapReduce distributes a large task across hundreds or thousands of servers. He gives the task to several servers, and then collects many of their answers into one.
BigTable is Google’s database of all data. It is not relational, because the relational cannot work on such a scale. This is an old-fashioned flat database, which, like GFS, must be coherent.
Before these technologies were developed, computers functioned like people, working on one task with a limited amount of information at one point in time. The ability to force thousands of computers to work together on a huge amount of data has become a powerful breakthrough.
But Google was not enough to achieve its financial goals.
 Big Brother started as an advertiser. Google was just enough to make data processing cheaper to get closer to Amazon.com profit margins. The remaining difference between the cent and the dollar per transaction could be covered, if you find a more profitable way to sell online advertising. Google did this through effective user indexing, as it had previously done with the Internet.
Big Brother started as an advertiser. Google was just enough to make data processing cheaper to get closer to Amazon.com profit margins. The remaining difference between the cent and the dollar per transaction could be covered, if you find a more profitable way to sell online advertising. Google did this through effective user indexing, as it had previously done with the Internet.
Studying our behavior and anticipating our consumer needs, Google offered us advertisements that we would click with a probability of 10 or 100 times more, which increased Google’s likely revenue from such a click 10 or 100 times.
Now we are finally talking on the scale of big data.
Whether Google’s tools worked with the inner or outer world — it doesn’t matter, everything worked the same. And unlike the SABER system, for example, these were general-purpose tools — they could be used for almost any kind of task, applied to almost any kind of data.
GFS and MapReduce first did not impose any restrictions on database size or search scalability. All that was needed was more average iron, which would gradually lead to millions of cheap servers sharing the task. Google constantly adds servers to its network, but it does it wisely, because unless the data center turns off completely, the servers will not be replaced after a breakdown. It is too complicated. They will simply be left dead in the racks, and MapReduce will process the data, avoiding non-working servers and using operating nearby.
Google published an article about GFS in 2003 and about MapReduce in 2004. One of the magic moments of this business: they didn’t even try to keep their methods secret, although it’s likely that others would have come to such decisions themselves.
Yahoo !, Facebook and others quickly reproduced the open version of Map Reduce, called Hadoop (after a toy elephant - elephants do not forget anything). This allowed the appearance of what we call cloud computing today. It’s just a paid service: distributing your task between dozens or hundreds of rented computers, sometimes rented for a few seconds, and then combining several answers into one logically related solution.
Big data has turned cloud computing into a necessity. Today it is difficult to separate these two concepts.
Not only big data, but also social networks were made possible by MapReduce and Hadoop, because they made it economically viable for a billion Facebook users to create their dynamic web pages for free, and companies only make money from advertising.
Even Amazon switched to Hadoop, and today there are almost no restrictions on the growth of their network.
Amazon, Facebook, Google and NSA cannot function today without MapReduce or Hadoop, which, by the way, have forever destroyed the need for an index. The search today is not done by index, but by raw data, which varies from minute to minute. More precisely, the index is updated from minute to minute. It does not matter.
Thanks to these tools, Amazon and other companies provide cloud computing services. Armed with a credit card only, smart programmers can use the power of one, thousands or ten thousand computers within a few minutes and apply them to solve any problem. That is why Internet startups no longer buy servers. If you want to briefly acquire computing resources that are larger than those of all of Russia, you only need a payment card.
If Russia wants to get more computing resources than Russia does, it can also use its plastic card.
The big unanswered question: why did Google share its secrets with competitors and make its research public? Was this stupid arrogance on the part of the founders of Google, who at that time still defended doctoral dissertations at Stanford? Not. Google shared its secrets to create an industry. He needed not to look like a monopoly in the eyes of competitors. But more importantly, by allowing thousands of other flowers to bloom, Google has contributed to the growth of the Internet industry, which has increased its revenue by 30-40 percent.
By sharing their secrets, Google got a smaller piece of a larger pie.
So, in a nutshell, Big Data appeared. Google tracks your every mouse click, and a billion or more other people's clicks. Similarly, Facebook and Amazon when you are on their site or using Amazon Web Services on any other site. And they cover a third of the data processing of the entire Internet.
Consider for a minute how important this is for society. If in the past businesses used marketing research and thought about how to sell goods to consumers, now they can use big data to know about your desires and how to sell it. That is why I have long seen ads on the Internet about expensive espresso machines. And when I finally bought it, advertising almost instantly stopped, because the system learned about my purchase. She turned to trying to sell me coffee beans and, for some reason, adult diapers.
Google will once have a server for every Internet user. They and other companies will collect more types of data about us and better predict our behavior. What this will lead to depends on who will use this data. This can turn us into ideal consumers or caught terrorists (or more successful terrorists - this is another argument).
There is no task that would be irresistibly large.
And for the first time, thanks to Google, NSA and GCHQ, finally, have search tools for stored intelligence data, and they can find all the bad guys. Or maybe forever enslave us.
(Translation by Natalia Bass )
')
Source: https://habr.com/ru/post/308586/
All Articles