Choosing an html-parser for Apache.JMeter
The average quality of the work of parsers (for seven sites)
I suggest:
- calculate the average quality of completeness of extracting links to embedded resources by Apache.JMeter html parsers;
- check if links extraction in Apache.JMeter 3.0 is true has become more complete;
- try out the CsvLogWriter plugin.
As popular wisdom says: Believe believe, but ...
')
Project Description
When Apache.JMeter 3.0 came out, I was still in development, my colleagues and I tested it and started using it in my work. The first in combat testing was a new version of Artem Zetsigemon for one of the new services, pgu.mos.ru , where using Apache.JMeter 3.0, the quality of parsing of embedded resources was significantly improved compared to the previous version.
And then the question arose, what is the quality, how to measure it for different sites, what it was and how it became?
Materials and research results are reflected in the current article.
Test object
HtmlParser-s for Apache.JMeter 2.13 and Apache.JMeter 3.0 are tested .
Apache.JMeter 2.13 parsers:
- LagartoBasedHtmlParser;
- HtmlParserHTMLParser;
- JTidyHTMLParser;
- RegexpHTMLParser;
- JsoupBasedHtmlParser.
Parses Apache.JMeter 3.0 :
- LagartoBasedHtmlParser;
- JTidyHTMLParser;
- RegexpHTMLParser;
- JsoupBasedHtmlParser.
Parsers parse the start pages of various websites:
- stackoverflow.com;
- habrahabr.ru;
- yandex.ru;
- mos.ru;
- jmeter.apache.org;
- google.ru;
- linkedin.com;
- github.com.
The basis of testing
The basis was the changes in Apache.JMeter 3.0 , see http://jmeter.apache.org/changes.html .
Excerpts from the list of changes:
Core improvements
Dependencies refresh
Deprecated Libraries dropped to date:
- htmllexer, htmlparser removed
- jdom removed
Removed parser htmlparser and more unused library jdom .Protocols and Load Testing improvements
Parallel downloads are much better:
- Parsing of CSS imported files (through import ) or embedded resources (background, images, ...)
A new parser for CSS files has been added, links to other CSS files (via import ) and links to resources specified in CSS files will be extracted: background images, images, ...Incompatible changes
- Since it was a version of the parser for the embedded resources (replaced since 2.10 by the Lagarto based implementation), it has been updated with the htmlparser library (HtmlParserHTMLParser).
- The following jars have been removed:
Removed parser htmlparser and more unused libraries htmllexer and jdom .Improvements
HTTP Samplers and Test Script Recorder
- Bug 59036 - FormCharSetFinder: Use JSoup instead of deprecated HTMLParser
- Bug 59033 - Parallel Download plug-in parser for each mime types
- Bug 59140 - Parallel Download: Add CSS Parsing to extract links from CSS files
To search for theaccept-charsetattribute informtags, JSoup is now used instead of remote HTMLParser [Bug 59036]. Implemented CSS parser [Bug 59140] and this parser is used by default [Bug 59033].
Test objectives
Compare the work of all available parsers. In particular, compare parsers versions 2.13 and 3.0 to each other, make sure that the load of embedded resources has become more realistic and better.
Strategy
Stage 1:
- Download the starting pages of the list of sites using all 5 Apache.JMeter 2.13 parsers and write logs.
- Download the starting pages of the list of sites using all 4 Apache.JMeter 3.0 parsers and write logs.
- Analyze the Apache.JMeter logs and compare them with each other. Evaluate whether the load on embedded resources has become better, whether the list of downloaded embedded resources has expanded.
Stage 2:
- Download the starting pages of the list of popular sites using Google Chrome and webpagetest.org service.
- Analyze the reports from webpagetest.org and compare them with the results of the analysis of Apache.JMeter logs. Rate, realistic loading of embedded resources.
Testing approach
To accurately determine how many requests are sent during the opening of a page from Apache.JMeter, all requests are logged:
- View Results Tree - standard logger, logging to XML format with subquery logging, XML log will be used to find out the details of queries / answers / errors;
- CsvLogWriter - custom logger https://github.com/pflb/Jmeter.Plugin.CsvLogWriter , logging in CSV format with logging subqueries, CSV log will be used for software calculation of statistics on the work of different parsers;
- only quantitative evaluation is performed, the addresses of subqueries are not compared by list.
In order to be able to group requests by Apache.JMeter versions, parsers and sites, additional variables for each request will be logged:
- siteKey - the tested site;
- jmeterVersion - Apache.JMeter version;
- htmlParser is the name of the currently used html parser.
results
Evaluation of the improvement of parsers for version 3.0 compared to version 2.13
There are no dramatic improvements in the completeness of parsing html-pages, there are worsening.
The essential difference is that in the Apache.JMeter 3.0 parsers there is a recursive loading of the Yandex Browser browser promotional materials page. This is manifested when downloading https://yandex.ru/ .
Sites with a small amount of content - a good result
On simple sites such as jmeter.apache.org, all parsers work the same way. By creating the same number of subqueries that the browser creates. The quality of the parsers for jmeter.apache.org is perfect, 100%.
Sites with a lot of content - bad result
But on a site like mos.ru, the parsers will find an average of 22 links to embedded resources, while a full page load with the browser loading all embedded resources - 144 requests. The quality is low.
Similarly, on the site habrahabr.ru , the Lagardo parser from Apache.JMeter 3.0 will find 55 links, while the browser will make 117 subqueries. The quality is 47.01%. Satisfactory quality of completeness of extracting links to embedded resources.
Number of subqueries using different parsers
Table on Google Docs: JMeter.HtmlParser.Compare (top table) .
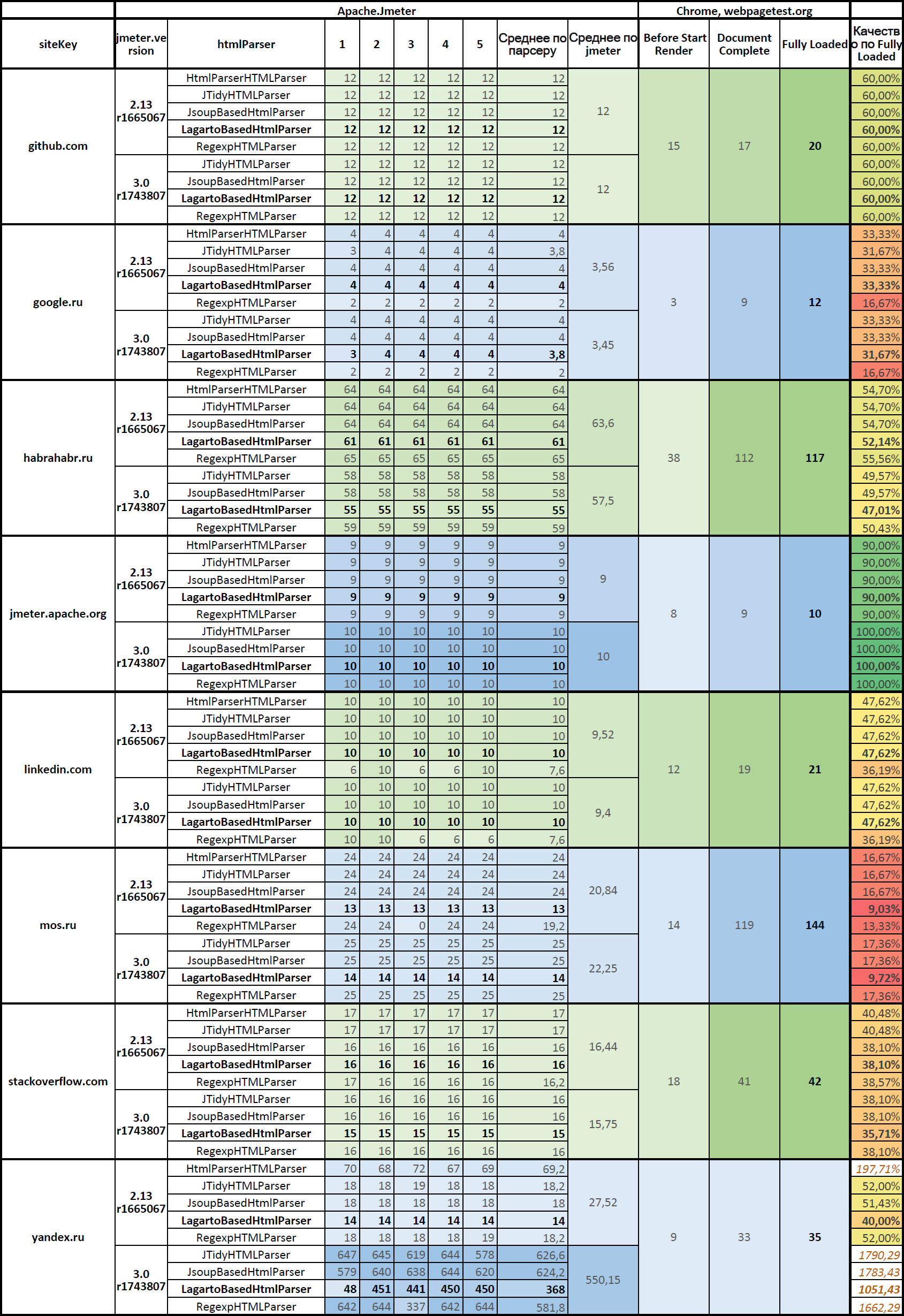
Apache.JMeter statistics on versions and html parsers and its comparison with Google Chrome
Column description:
- Before Start Render - the number of subqueries made by the browser, before the start of displaying the contents of the page. These are html markup, main js and css-files, main images.
- Document Complete - the number of subqueries made by the browser at the time of the complete loading of the document. All page resources have already been loaded here.
- Fully Loaded - the number of subqueries made by the browser at the time when the javascript worked, when everything was loaded.
The good result of the parsers will be if the subqueries are as many as the Google Chrome browser does at the time of Document Complete , and excellent at the time of Fully Loaded . The measure of the realism of Apache.JMeter when using a particular parser is the proximity of the number of subqueries to the number of subqueries executed by the browser at the time of Fully Loaded .
If we exclude the results of testing site yandex.ru, where:
- The parsing goes into recursion by doing requests again and again to yandex.ru until the depth of the recursion reaches the maximum level and ends with an error:
>java.lang.Exception: Maximum frame/iframe nesting depth exceeded.
And as a measure of the quality of the work of parsers to accept the number of subqueries at the time of Fully Loaded , we get such a table of the average quality of work of the parsers.
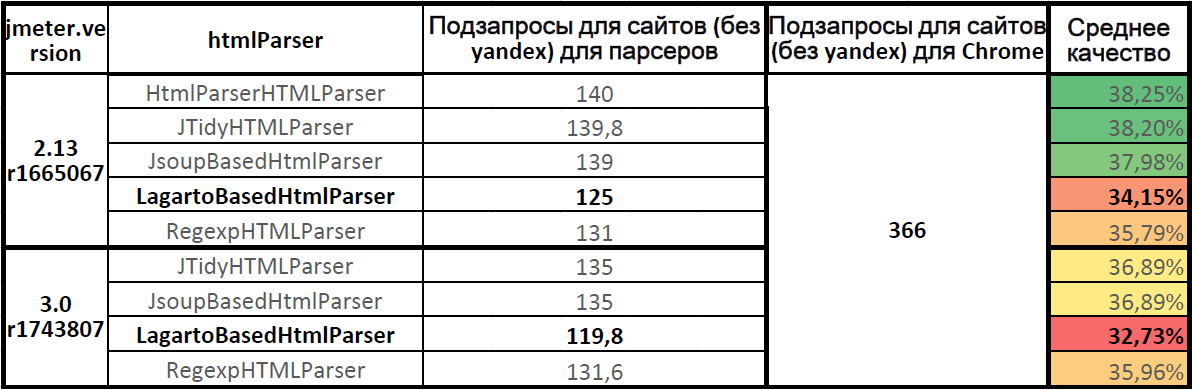
The average quality of the parsers
Table on Google Docs: JMeter.HtmlParser.Compare (lower table) .
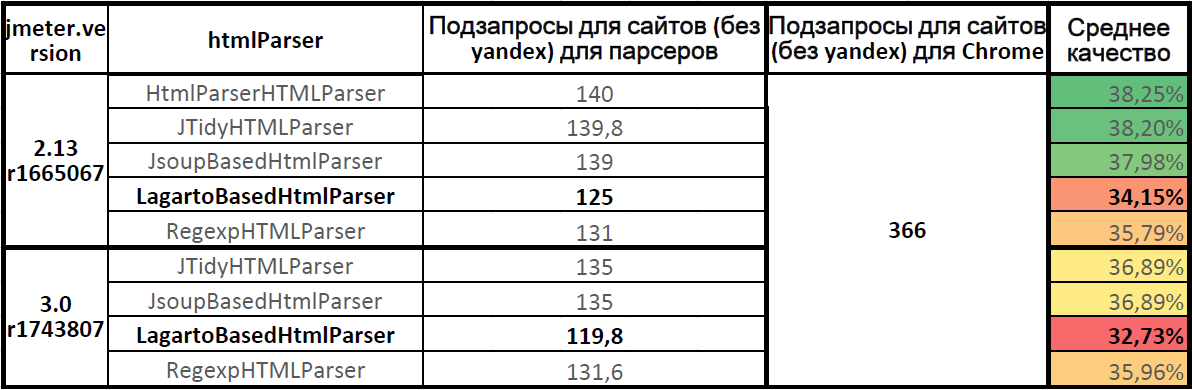
The average quality of the work of parsers (for seven sites, without yandex.ru)
The most accurate HTML Parser parser in Apache.JMeter 2.13. In Apache.JMeter 3.0, the Jsoup and JTidy parsers showed the same quality. Parser Lagarto behind the leaders. The parsing completeness for the Lagarto parser in Apache.JMeter 3.0 has decreased in comparison with Apache.JMeter 2.13.
The quality of the Lagarto parser on the current version of Apache.JMeter 3.0 was 32.73%, only a third of all the subqueries were sent, two thirds of the load on the static was not submitted.
Detailed analysis of missing links when working Apache.JMeter 3.0 site habrahabr.ru
Spreadsheet on Google Docs: Missed default Apache.JMeter 3.0 parser links to habrahabr.ru
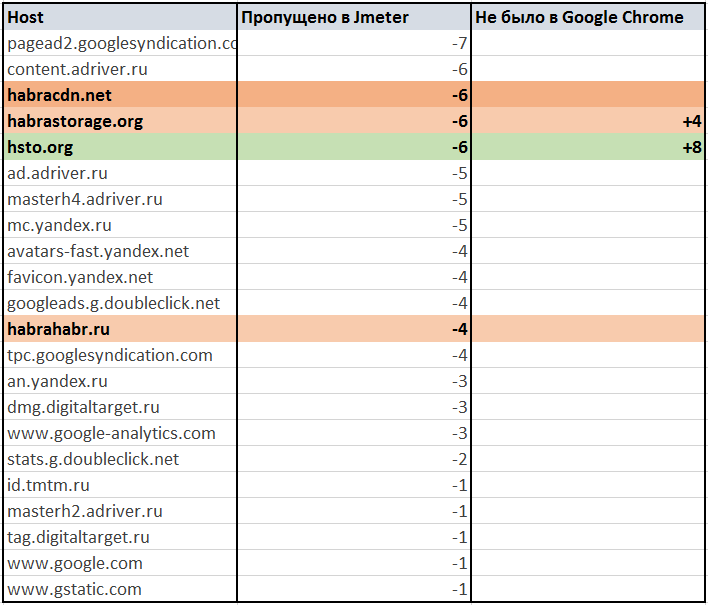
Missed Apache.JMeter 3.0 links when parsing habrahabr.ru
Missing a lot of promotional materials and statistics. And this is good.
Above I have already made a reservation that I will evaluate only quantitative characteristics. By numbers, it turns out that the quality of extracting links to embedded resources is low. Detailed analysis can show exactly what was missing. It may turn out that this is advertising and content from third-party resources, which need not be loaded as part of the load testing of a specific site.
Logs and their processing
Initial data
All logs are available at the link: https://drive.google.com/drive/folders/0B5nKzHDZ1RIiVkN4dDlFWDR1ZGM .
WebPageTest.org reports
| sytekey | webpagetest.org | Raw page data (.csv) | Raw object data (.csv) | HTTP Archive (.har) |
|---|---|---|---|---|
| github.com | 160819_VF_FM8 | github.com.summary.csv | github.com.details.csv | github.com.har |
| google.ru | 160819_C9_FQD | google.com.summary.csv | google.com.details.csv | google.ru.har |
| habrahabr.ru | 160819_8N_FRB | habrahabr.ru.summary.csv | habrahabr.ru.details.csv | habrahabr.ru.har |
| jmeter.apache.org | 160819_CG_FSM | jmeter.apache.org.summary.csv | jmeter.apache.org.details.csv | jmeter.apache.org.har |
| linkedin.com | 160819_K2_FY1 | linkedin.com.summary.csv | linkedin.com.details.csv | linkedin.com.har |
| mos.ru | 160819_91_G0F | mos.ru.summary.csv | mos.ru.details.csv | mos.ru.har |
| stackoverflow.com | 160819_S0_G18 | stackoverflow.com.summary.csv | stackoverflow.com.details.csv | stackoverflow.com.har |
| yandex.ru | 160819_MR_G1R | yandex.ru.summary.csv | yandex.ru.details.csv | yandex.ru.har |
Report Images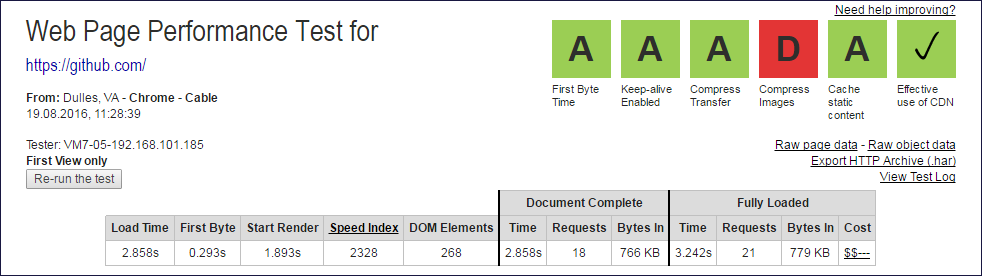
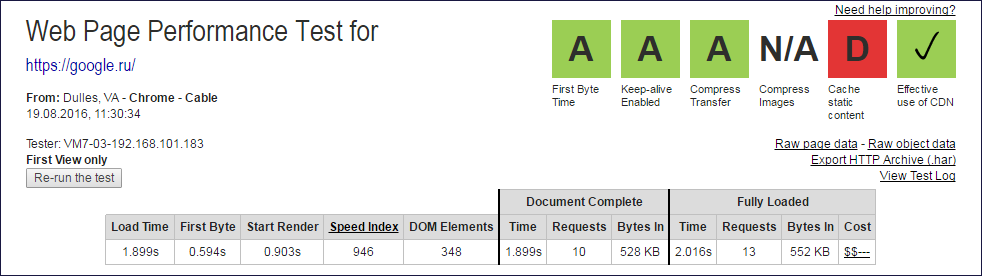
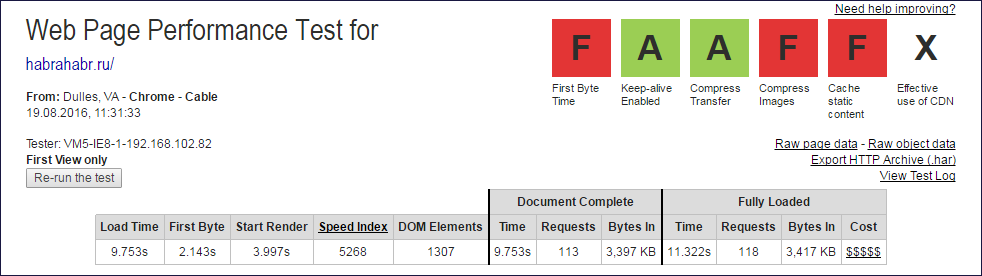
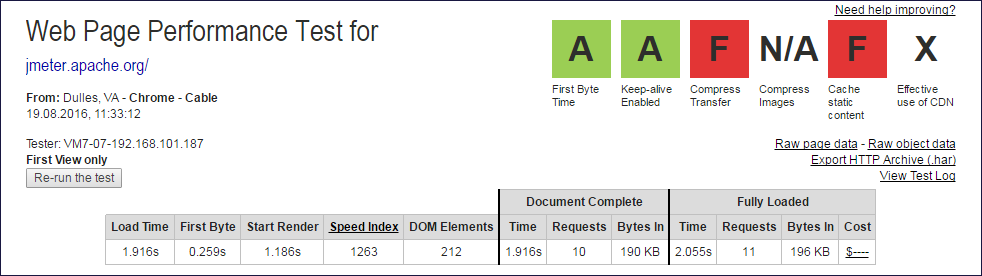

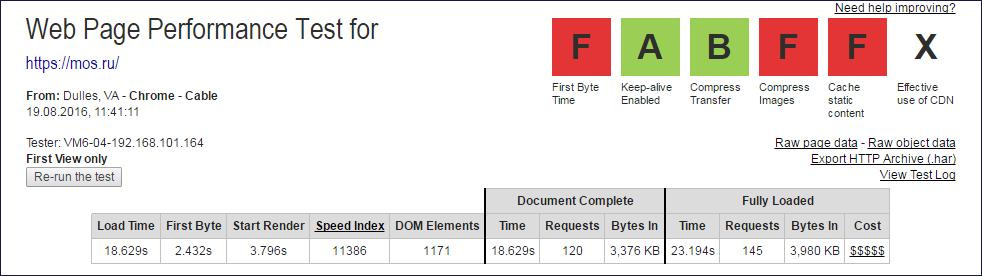

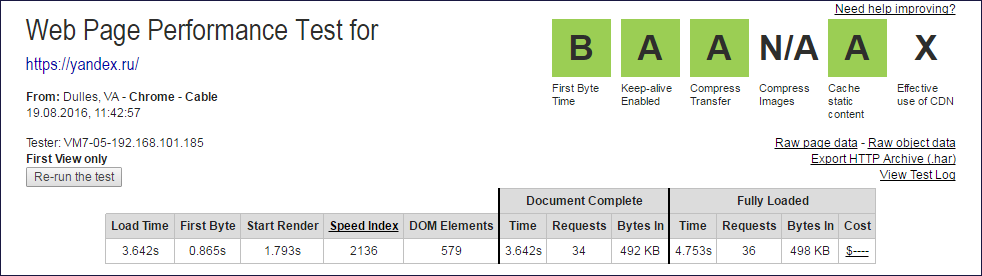
The caps of the webpagetest.org reports from which Document Complete and Fully Loaded data were extracted
The caps of the webpagetest.org reports from which Document Complete and Fully Loaded data were extracted
From the values of the columns Document Complete and Fully Loaded, you need to exclude one query (root) to get the number of subqueries.
Logs Apache.JMeter
For processing, csv-logs are used, formed by the CsvLogWriter plugin:
- project: https://github.com/pflb/Jmeter.Plugin.CsvLogWriter ;
- description on habrahabr.ru: CsvLogWriter plugin for JMeter .
The third-party plugin is used to request requests for embedded resources in the csv-log.
As a result of CsvLogWriter operation, a log is generated, the list of columns of which includes:
- timeStamp - time;
- URL - address of the request;
- elapsed - the duration of the response to the request;
- bytes - the size of the response;
- siteKey - used site;
- htmlParser - the name used;
- jmeterVersion - used version of Apache.JMeter;
- i is the iteration number of testing.
Log Processing Automation
Aggregation of Aps.JMeter csv logs is done using pandas with this python code:
import pandas as pd import codecs from os import listdir import numpy as np # - . dirPath = "D:/project/jmeter.htmlParser.3.0.vs.2.13/logs" read_csv_param = dict( index_col=['timeStamp'], low_memory=False, sep = ";", na_values=[' ','','null']) # csv- . files = filter(lambda a: '.csv' in a, listdir(dirPath)) # csv- DataFrame dfs. csvfile = dirPath + "/" + files[0] print(files[0]) dfs = pd.read_csv(csvfile,**read_csv_param) for csvfile in files[1:]: print(csvfile) tempDfs = pd.read_csv(dirPath + "/" + csvfile, **read_csv_param) dfs = dfs.append(tempDfs) #dfs.to_excel(dirPath + "/total.xlsx") # JSR223, , HTTP Request Sampler. # JSR223 URL , HTTP- URL . dfs = dfs[(pd.isnull(dfs.URL) == False)] # , report.subrequests.html - . # , . # - , . pd.pivot_table(dfs, index=['siteKey', "jmeterVersion", "htmlParser"], values="URL", columns=["i"], aggfunc=lambda url: url.count()-1).to_html(dirPath + "/report.subrequest.count.html") Recursive download on yandex.ru

Recursive loading of embedded resources for the current version of Apache.JMeter 3.0 with default settings (html-parser Lagarto) on the website yandex.ru
As seen:
- Apache.JMeter finds and follows the link
https://yandex.ru/clck/redir/dtype=stred....7004fcb3793e79bb1ac9e&keyno=12 - Then it finds a new unique link
https://yandex.ru/clck/redir/dtype=stred....cd1c46cad58fbfe2f61&keyno=12 - And so on, goes into recursion.
In this case, this is the picture inside the link to download Yandex Browser:
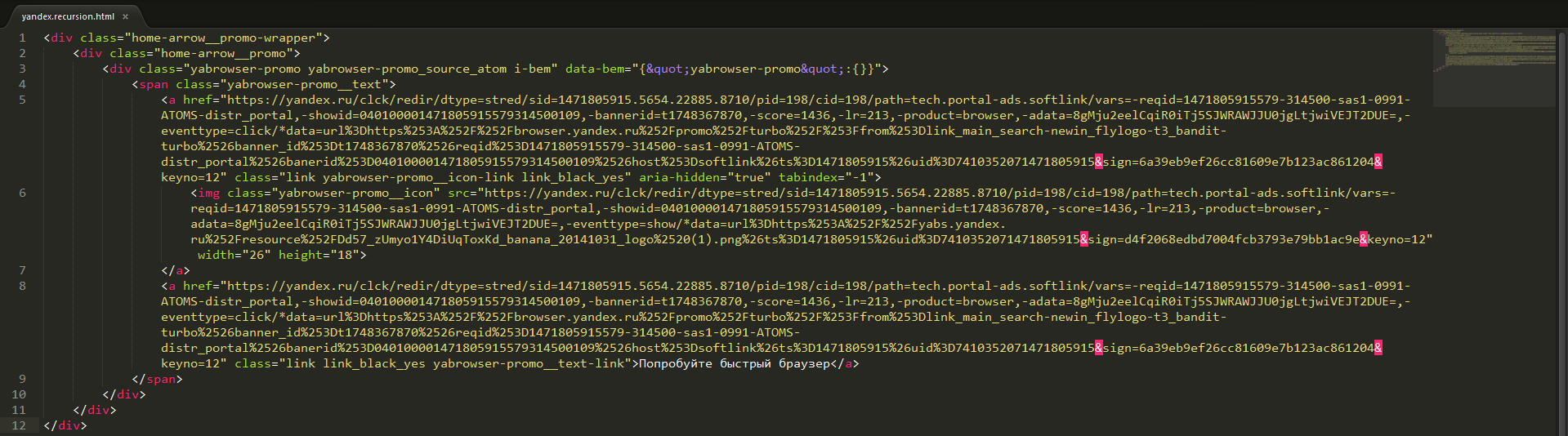
Fragment of the html-code of the site yandex.ru processing of which adds a new recursion step, links and a picture for downloading Yandex Browser
The parser finds the picture. JMeter tries to download it, gets a html page in response, there is again a link to the picture and other links. And everything repeats. Apache.JMeter behavior is correct.
And in Apache.JMeter 2.13, the recursion occurs only on the HtmlParser parser, why does not guess why it happens to others:
- there is a restriction on the length of references, and due to the cutting off of the unique end of the reference, recursion does not occur;
- or in Apache.JMeter 2.13, something is not working properly in parsers;
- or in Apache.JMeter 2.13, something works the other way around correctly - cookies, something else, and the Yandex server itself responds to it so that it does not go into recursion, for example, it responds with a picture to a picture request, and not a new html page.
I will not guess. Seems a hopeless situation. But such situations do not happen. There is always a solution.
For example, you can try to specify Yandex Browser as User-Agent . Then the server probably will not show a picture for downloading the browser, or the picture will respond to the picture request, and there will be no recursion. This is a guess, did not check it.
Now the User-Agent for Google Chrome was specified in the script for synchronization with the work of webpagetest.org, and seeing the server not seeing your browser, apparently, suggests a link to your own.
The composition of the project
- jmeter.testfile.jmx - test script for Apache.JMeter 2.13 and Apache.JMeter 3.0 accepting input parameters:
URL- the address of the tested site, for example, https://yandex.ru/ ;siteKey- the string by which the grouping of records in the logs will be performed, for example, yandex.ru;loopCount- the number of test iterations, several iterations are used due to the fact that the work of websites may be unstable;htmlParser.className- a parser for extracting links to embedded resources;- For the script to work, you need to download and install the additional CsvLogWriter plugin.
- jmeter.3.0.bat is the test command batch file for Apache.JMeter 3.0 , here you specify the path to the folder
/bin/Apache.JMeter 3.0 , the path to the test script jmeter.testfile.jmx , the test launch options, and the htmlParser check list whose work is performed; - jmeter.2.13.bat is the test command command file for Apache.JMeter 2.13 , here you set the path to the folder
/bin/Apache.JMeter 2.13 , the path to the test script jmeter.testfile.jmx , the test launch options, and the htmlParser check list whose work is performed; - test.bat - batch test run file on two versions of Apache.JMeter , 2.13 and 3.0, the file contains the number of test iterations and the addresses of the sites under test. The file calls jmeter.2.13.bat and jmeter.3.0.bat ;
- jmeter.3.0.vs.jmeter.2.13.ipynb - notepad for jupyter for analyzing the Apache.JMeter logs;
- statistics.xlsx - a table with statistics on the work of parsers, the result of the study.
The test is easy to change for yourself, specify your sites and the desired number of iterations. All settings are specified in the test.bat file.
CALL jmeter.2.13.bat http://stackoverflow.com/ 5 stackoverflow.com CALL jmeter.2.13.bat https://habrahabr.ru/ 5 habrahabr.ru CALL jmeter.2.13.bat https://yandex.ru/ 5 yandex.ru CALL jmeter.2.13.bat https://www.mos.ru/ 5 mos.ru CALL jmeter.2.13.bat http://jmeter.apache.org/ 5 jmeter.apache.org CALL jmeter.2.13.bat https://www.google.ru/ 5 google.ru CALL jmeter.2.13.bat https://www.linkedin.com/ 5 linkedin.com CALL jmeter.2.13.bat https://github.com/ 5 github.com CALL jmeter.3.0.bat http://stackoverflow.com/ 5 stackoverflow.com CALL jmeter.3.0.bat https://habrahabr.ru/ 5 habrahabr.ru CALL jmeter.3.0.bat https://yandex.ru/ 5 yandex.ru CALL jmeter.3.0.bat https://www.mos.ru/ 5 mos.ru CALL jmeter.3.0.bat http://jmeter.apache.org/ 5 jmeter.apache.org CALL jmeter.3.0.bat https://www.google.ru/ 5 google.ru CALL jmeter.3.0.bat https://www.linkedin.com/ 5 linkedin.com CALL jmeter.3.0.bat https://github.com/ 5 github.com You can then insert the results from an Excel file with customized formulas and get a descriptive table of results.
You can try to refine the parsers, and follow a similar method to track the improvement in the quality of parsing embedded resources.
findings
There is no special practical value in the article. But some useful conclusions can be made:
- the parser on average retrieves references to only a third of the resources;
- parsers work almost the same, which means you can use any;
- parsers are designed to work with simple sites, such as jmeter.apache.org;
- on sites with a lot of content, the parsers work much worse than the real browser;
- the completeness of the load of embedded resources in the new version of JMeter slightly decreased, and not increased (on selected sites);
- demonstrated the use of the CsvLogWriter plugin, which logs requests for embedded resources in the csv-log, which was done by my colleague Alexander Sanchez92 ;
- using bat-files, transferring JMeter parameters via the command line, logging variables and processing csv-logs with pandas, you can test the testing tool itself, the technique has been worked out, see the project on github:
Source: https://habr.com/ru/post/308254/
All Articles