Arrays in PHP 7: Hash Tables
Hash tables are used everywhere, in every serious C program. In fact, they allow the programmer to store values in an “array”, indexing it with strings, while in C, only integer keys of the array are allowed. In a hash table, the lower case keys are first hashed and then reduced to the size of the table. There may be collisions, so we need an algorithm for their resolution. There are several such algorithms, and the linked list strategy (linked list) is used in PHP.
There are a lot of great articles on the Web detailing the structure of hash tables and their implementation. You can start with http://preshing.com/ . But keep in mind, options for the structure of hash tables are myriad, and none of them are perfect, each has compromises, despite the optimization of processor cycles, memory usage, or good scaling of the environment. Some options are better when adding data, others when searching, etc. Choose the implementation depending on what is more important to you.
Hash tables in PHP 5 are discussed in detail in the phpinternalsbook material, which I wrote with Nikic , the author of a good article on hash tables in PHP 7 . Perhaps you will find it interesting too. True, it was written before the release, so some things in it are slightly different.
')
Here we take a closer look at how the hash tables in PHP 7 are arranged, how to work with them from the point of view of the C language and how to manage them using PHP tools (using structures called arrays). The source code is mainly available in zend_hash.c . Do not forget that we use hash tables everywhere (usually in the role of dictionaries), therefore, we need to design them so that they are quickly processed by the processor and consume little memory. These structures have a decisive impact on the overall performance of PHP, since local arrays are not the only place where hash tables are used.
There are a number of provisions that we will examine in detail below:
Consider the
Some fields are rarely used, and therefore we will not talk about them.
The size of this structure is 56 bytes (according to model LP64).
The most interesting data field is
As you can see,
Let's look at the picture, how is the placement in memory:

As you can see, the data placed in the hash table is stored in the adjacent memory section:
PHP must preserve the order of the elements when they are added to the array. If you apply the
This is an important point that imposes a number of restrictions on the implementation of hash tables. All data is stored in memory next to each other. In

Thanks to this approach, you can easily iterate the hash table: you just need to
The data is sorted and transferred to the next cell
A simplified view of adding elements to a hash table using string keys:
When a value is deleted, the

Consequently, the iteration code needs to be slightly rebuilt so that it can process such “empty” cells:
Below we will look at what happens when the hash table is resized and how the
Keys must be hashed and compressed, then converted from a compressed hashed value and indexed in
It must be remembered that we cannot index compressed values as they are directly in
For example: if you add first by key foo, and then by key bar, then the first will be hashed / compressed to key 5, and the second to key 3. If the data foo is stored in

So, we hash and then compress the key so that it fits in the designated
There is one caveat: the conversion table memory is prudently located behind the

Now our foo key is hashed into DJB33X and compressed to the required size (
Access to these cells occurs through a negative offset from the starting position of
Below you can clearly see how the buffer is divided into two parts:
When the macros are executed, we get:
Wonderful.
Now we will understand how collisions are resolved. As you remember, in a hash table, multiple keys for hashing and compression can correspond to the same conversion index. So, having received a transformation index, we use it to extract data back from
Note that the linked list is not memory scattered like traditional linked lists. Instead of walking through several pointers placed in memory, received from a heap - and probably scattered in the address space - we read from memory the full vector
In PHP 7, hash tables have very high data locality. In most cases, access occurs in 1 nanosecond, since the data is usually located in the first level processor cache.
Let's see how you can add elements to the hash, as well as resolve conflicts:
The same with deletion:
Two-stage initialization gives certain advantages, allowing you to minimize the impact of an empty, just-created hash table (a frequent case in PHP). When creating a table, we simultaneously create bucket cells in
Please note that you can not use a bunch. Quite enough static constant memory area (static const memory zone), so it turns out much easier (
After adding the first element, we completely initialize the hash table. In other words, we create the last required transformation cells depending on the requested size (by default, it starts with 8 cells). Placement in memory comes from a heap.
The
An example of a lazy initialized (lazy-initialized) hash table: it was created, but so far no hash has been placed in it.
If the hash table is full and you need to add new elements, you have to increase its size. This is a big advantage of hash tables compared to classic hard-limited arrays in C. With each increase, the size of the hash table doubles. I remind you that when increasing the size of the table, we pre-allocate the
All this memory consists of UNDEF cells and waits for data to be placed into it.
For example, you have 1024 cells in a hash table, and you add a new item. The table grows to 2048 cells, of which 1023 are empty. 1023 * 32 bytes = approximately 32 KB. This is one of the drawbacks of implementing hash tables in PHP.
It must be remembered that a hash table may consist entirely of UNDEF cells alone. If you add and delete many items, the table will be fragmented. But in order to preserve the order of the elements, we add everything new only at the end of
An example of a highly fragmented 8-cell hash table:
As you remember, new values cannot be stored in UNDEF cells. In the above scheme, when iterating a hash table, we go from
By increasing the size, you can reduce the
This illustration shows the previous fragmented hash table after compression:
The algorithm scans
Well, now we know the main points of the implementation of the hash table in PHP 7. Let's now consider its public API.
There’s really nothing to talk about (well, in PHP 5, the API is made much better). Just when using the API function, do not forget about three things:
Whatever your key, lowercase or integer, the main thing: the API should be aware that the lowercase keys get hashes from
Sometimes a key can be a simple pair (char * / int). In this case, you need to use another API, for example
Now about the data that you are going to store in a hash table. Again, this can be anything, the hash table will still put the data in the
The situation can be somewhat simplified if you have a pointer to the storage or memory area (the data referenced by the pointer). Then the API places this pointer or memory area in zval, and then zval itself uses the pointer as data.
Examples will help to understand the idea:
When retrieving data, you get either zval * or NULL. If a pointer is used as a value, the API may return as is:
As for the _new API like
: 5, API
, : , zval…
, :
: .
« -» (packed hashtable):

, .
: , , ( /), - . bucket'.
-
: - , .
(, 42 60), - «». ( — ) . - API:
,
, - .
(packed array):
, :
130 ( 25 000 ).
:
Results:
, ( , modulo noise).
- .
?
— , UNDEF-. : , , , . , , , .
:
See the difference? 32 768 65 538 , . 32 767 .
-, . , , , . «» , (
:
. 2,5 .
, , . , , . 42 idx 0, . The end of the story.
, - , . ? , (, ?) / , . . , . «» 20 32 , .
— OPCache. OPCache, , . . . OPCache , . , AST-. , — AST-. For example:
, OPCache , IS_ARRAY_IMMUTABLE IS_TYPE_IMMUTABLE . IS_IMMUTABLE , . , . .
:
400 OPCache, — 35 . OPCache , 8-
, , ,
- , . , PHP- — - Zend. PHP, . - . , / . -. OPArray ( ) ( ). PHP , OPArray: . OPCache IMMUTABLE , . , .
OPCache , . , ( , ). , - OPCache , PHP- . PHP.
. , :
. , ( interned strings ), , . — , ( , , ), runtime' PHP. ( ). , OPCache.
There are a lot of great articles on the Web detailing the structure of hash tables and their implementation. You can start with http://preshing.com/ . But keep in mind, options for the structure of hash tables are myriad, and none of them are perfect, each has compromises, despite the optimization of processor cycles, memory usage, or good scaling of the environment. Some options are better when adding data, others when searching, etc. Choose the implementation depending on what is more important to you.
Hash tables in PHP 5 are discussed in detail in the phpinternalsbook material, which I wrote with Nikic , the author of a good article on hash tables in PHP 7 . Perhaps you will find it interesting too. True, it was written before the release, so some things in it are slightly different.
')
Here we take a closer look at how the hash tables in PHP 7 are arranged, how to work with them from the point of view of the C language and how to manage them using PHP tools (using structures called arrays). The source code is mainly available in zend_hash.c . Do not forget that we use hash tables everywhere (usually in the role of dictionaries), therefore, we need to design them so that they are quickly processed by the processor and consume little memory. These structures have a decisive impact on the overall performance of PHP, since local arrays are not the only place where hash tables are used.
Hash Table Design
There are a number of provisions that we will examine in detail below:
- The key can be a string or an integer. In the first case, the structure is
zend_string, in the second -zend_ulong. - A hash table must always remember the order in which its elements are added.
- The size of the hash table changes automatically. Depending on the circumstances, it independently decreases or increases.
- From the point of view of internal implementation, the size of the table is always equal to two in degree. This is done to improve performance and align the placement of data in memory.
- All values in the hash table are stored in a
zvalstructure, nowhere else.Zval's can contain data of any type.
Consider the
HashTable structure: struct _zend_array { zend_refcounted_h gc; union { struct { ZEND_ENDIAN_LOHI_4( zend_uchar flags, zend_uchar nApplyCount, zend_uchar nIteratorsCount, zend_uchar reserve) } v; uint32_t flags; /* 32 */ } u; uint32_t nTableMask; /* — nTableSize */ Bucket *arData; /* */ uint32_t nNumUsed; /* arData */ uint32_t nNumOfElements; /* arData */ uint32_t nTableSize; /* , */ uint32_t nInternalPointer; /* */ zend_long nNextFreeElement; /* */ dtor_func_t pDestructor; /* */ }; Some fields are rarely used, and therefore we will not talk about them.
The size of this structure is 56 bytes (according to model LP64).
The most interesting data field is
arData , which is a kind of pointer to the memory area of the Bucket chain. Bucket itself is a single cell in the array: typedef struct _Bucket { zval val; /* */ zend_ulong h; /* ( ) */ zend_string *key; /* NULL */ } Bucket; As you can see,
zval will be stored in the Bucket structure. Note that it does not use a pointer to zval , but the structure itself. This is done because in PHP 7, zval 's are no longer placed on the heap (unlike PHP 5), but the target value stored in zval in the form of a pointer (for example, a PHP string) can be placed in PHP 7.Let's look at the picture, how is the placement in memory:
As you can see, the data placed in the hash table is stored in the adjacent memory section:
arData .Adding items while maintaining order
PHP must preserve the order of the elements when they are added to the array. If you apply the
foreach instruction to the array, you will receive the data exactly in the order in which they were placed in the array, regardless of their keys: $a = [9=>"foo", 2 => 42, []]; var_dump($a); array(3) { [9]=> string(3) "foo" [2]=> int(42) [10]=> array(0) { } } This is an important point that imposes a number of restrictions on the implementation of hash tables. All data is stored in memory next to each other. In
zval 'ah, they are stored packed in a Bucket ' s, which are located in the fields of the arData C-array. Like that: $a = [3=> 'foo', 8 => 'bar', 'baz' => []]; Thanks to this approach, you can easily iterate the hash table: you just need to
arData array. In fact, this is a fast sequential memory scan, consuming very few processor cache resources. All data from arData can be placed in one line, and access to each cell takes about 1 nanosecond. Note: in order to increase the efficiency of using the processor cache, arData aligned in accordance with the 64-bit model (the optimizing alignment of 64-bit full instructions is also used). The hash table iteration code might look like this: size_t i; Bucket p; zval val; for (i=0; i < ht->nTableSize; i++) { p = ht->arData[i]; val = p.val; /* - val */ } The data is sorted and transferred to the next cell
arData . To perform this procedure, it is enough just to remember the next available cell in this array, which is stored in the nNumUsed field. Each time we add a new value, we put it ht->nNumUsed++ . When the number of elements in nNumUsed reaches the number of elements in the hash table ( nNumOfElements ), we run the compact or resize algorithm, which we will discuss below.A simplified view of adding elements to a hash table using string keys:
idx = ht->nNumUsed++; /* */ ht->nNumOfElements++; /* */ /* ... */ p = ht->arData + idx; /* bucket arData */ p->key = key; /* , */ /* ... */ p->h = h = ZSTR_H(key); /* bucket */ ZVAL_COPY_VALUE(&p->val, pData); /* bucket': */ Erase values
When a value is deleted, the
arData array arData not decrease or regroup. Otherwise, performance would be disastrous, since we would have to move data in memory. Therefore, when deleting data from a hash table, the corresponding cell in arData simply marked in a special way: zval UNDEF.Consequently, the iteration code needs to be slightly rebuilt so that it can process such “empty” cells:
size_t i; Bucket p; zval val; for (i=0; i < ht->nTableSize; i++) { p = ht->arData[i]; val = p.val; if (Z_TYPE(val) == IS_UNDEF) { continue; } /* - val */ } Below we will look at what happens when the hash table is resized and how the
arData array needs to be reorganized so that the “empty” cells disappear (compaction).Key Hashing
Keys must be hashed and compressed, then converted from a compressed hashed value and indexed in
arData . The key will be compressed, even if it is integer. This is necessary in order to fit into the array boundaries.It must be remembered that we cannot index compressed values as they are directly in
arData . After all, this will mean that the keys used for the array index directly correspond to the keys obtained from the hash, which violates one of the properties of the hash tables in PHP: preserving the order of the elements.For example: if you add first by key foo, and then by key bar, then the first will be hashed / compressed to key 5, and the second to key 3. If the data foo is stored in
arData[5] , and the data bar is in arData[3] , it turns out that the data bar go to the data foo. And when iterating arData elements will not be transferred in the order in which they were added.So, we hash and then compress the key so that it fits in the designated
arData boundaries. But we do not use it as it is, unlike PHP 5. You must first convert the key using the translation table. It simply matches one integer value resulting from hashing / compression, and another integer value used for addressing within the arData array.There is one caveat: the conversion table memory is prudently located behind the
arData vector. This does not allow the table to use another area of memory, because it is already located next to arData and, therefore, remains in the same address space. This helps improve data locality. This is what the described scheme looks like in the case of an 8-element hash table (the minimum possible size):Now our foo key is hashed into DJB33X and compressed to the required size (
nTableMask ). The resulting value is an index that can be used to access the arData transformation arData (and not straight cells!).Access to these cells occurs through a negative offset from the starting position of
arData . Two memory areas were merged, so we can store data in memory sequentially. nTableMask corresponds to a negative value of the table size, so, taking it as a module, we get a value from 0 to –7. Now you can access the memory. When placing the whole arData buffer in it, we calculate its size using the formula:* bucket' + * (uint32) .Below you can clearly see how the buffer is divided into two parts:
#define HT_HASH_SIZE(nTableMask) (((size_t)(uint32_t)-(int32_t)(nTableMask)) * sizeof(uint32_t)) #define HT_DATA_SIZE(nTableSize) ((size_t)(nTableSize) * sizeof(Bucket)) #define HT_SIZE_EX(nTableSize, nTableMask) (HT_DATA_SIZE((nTableSize)) + HT_HASH_SIZE((nTableMask))) #define HT_SIZE(ht) HT_SIZE_EX((ht)->nTableSize, (ht)->nTableMask) Bucket *arData; arData = emalloc(HT_SIZE(ht)); /* */ When the macros are executed, we get:
(((size_t)(((ht)->nTableSize)) * sizeof(Bucket)) + (((size_t)(uint32_t)-(int32_t)(((ht)->nTableMask))) * sizeof(uint32_t))) Wonderful.
Collision resolution
Now we will understand how collisions are resolved. As you remember, in a hash table, multiple keys for hashing and compression can correspond to the same conversion index. So, having received a transformation index, we use it to extract data back from
arData and compare hashes and keys, checking whether this is necessary. If the data is incorrect, we go through the linked list using the field zval.u2.next , which reflects the next cell for entering data.Note that the linked list is not memory scattered like traditional linked lists. Instead of walking through several pointers placed in memory, received from a heap - and probably scattered in the address space - we read from memory the full vector
arData . And this is one of the main reasons for increasing the performance of hash tables in PHP 7, as well as the entire language.In PHP 7, hash tables have very high data locality. In most cases, access occurs in 1 nanosecond, since the data is usually located in the first level processor cache.
Let's see how you can add elements to the hash, as well as resolve conflicts:
idx = ht->nNumUsed++; /* */ ht->nNumOfElements++; /* */ /* ... */ p = ht->arData + idx; /* arData bucket */ p->key = key; /* */ /* ... */ p->h = h = ZSTR_H(key); /* bucket */ ZVAL_COPY_VALUE(&p->val, pData); /* bucket': */ nIndex = h | ht->nTableMask; /* */ Z_NEXT(p->val) = HT_HASH(ht, nIndex); /* */ HT_HASH(ht, nIndex) = HT_IDX_TO_HASH(idx); /* */ The same with deletion:
h = zend_string_hash_val(key); /* */ nIndex = h | ht->nTableMask; /* */ idx = HT_HASH(ht, nIndex); /* , */ while (idx != HT_INVALID_IDX) { /* */ p = HT_HASH_TO_BUCKET(ht, idx); /* bucket */ if ((p->key == key) || /* ? ? */ (p->h == h && /* ... */ p->key && /* ( ) */ ZSTR_LEN(p->key) == ZSTR_LEN(key) && /* */ memcmp(ZSTR_VAL(p->key), ZSTR_VAL(key), ZSTR_LEN(key)) == 0)) { /* ? */ _zend_hash_del_el_ex(ht, idx, p, prev); /* ! */ return SUCCESS; } prev = p; idx = Z_NEXT(p->val); /* */ } return FAILURE; Hash Conversion and Initialization Cells
HT_INVALID_IDX is a special flag that we put in the conversion table. It means "this transformation leads nowhere, no need to continue."Two-stage initialization gives certain advantages, allowing you to minimize the impact of an empty, just-created hash table (a frequent case in PHP). When creating a table, we simultaneously create bucket cells in
arData and two transformation cells, in which we place the HT_INVALID_IDX flag. Then we apply a mask that directs the transformation to the first cell ( HT_INVALID_IDX , there is no data here). #define HT_MIN_MASK ((uint32_t) -2) #define HT_HASH_SIZE(nTableMask) (((size_t)(uint32_t)-(int32_t)(nTableMask)) * sizeof(uint32_t)) #define HT_SET_DATA_ADDR(ht, ptr) do { (ht)->arData = (Bucket*)(((char*)(ptr)) + HT_HASH_SIZE((ht)->nTableMask)); } while (0) static const uint32_t uninitialized_bucket[-HT_MIN_MASK] = {HT_INVALID_IDX, HT_INVALID_IDX}; /* hash lazy init */ ZEND_API void ZEND_FASTCALL _zend_hash_init(HashTable *ht, uint32_t nSize, dtor_func_t pDestructor, zend_bool persistent ZEND_FILE_LINE_DC) { /* ... */ ht->nTableSize = zend_hash_check_size(nSize); ht->nTableMask = HT_MIN_MASK; HT_SET_DATA_ADDR(ht, &uninitialized_bucket); ht->nNumUsed = 0; ht->nNumOfElements = 0; } Please note that you can not use a bunch. Quite enough static constant memory area (static const memory zone), so it turns out much easier (
uninitialized_bucket ).After adding the first element, we completely initialize the hash table. In other words, we create the last required transformation cells depending on the requested size (by default, it starts with 8 cells). Placement in memory comes from a heap.
(ht)->nTableMask = -(ht)->nTableSize; HT_SET_DATA_ADDR(ht, pemalloc(HT_SIZE(ht), (ht)->u.flags & HASH_FLAG_PERSISTENT)); memset(&HT_HASH(ht, (ht)->nTableMask), HT_INVALID_IDX, HT_HASH_SIZE((ht)->nTableMask)) The
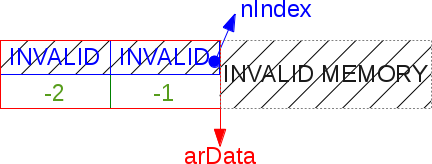
HT_HASH macro allows HT_HASH to access the transformation cells in the part of the memory-allocated buffer for which a negative offset is used. The table mask is always negative because the cells of the translation table are indexed to the minus from the beginning of the arData buffer. Here C programming is revealed in all its glory: billions of cells are available to you, swim in this infinity, just don't drown.An example of a lazy initialized (lazy-initialized) hash table: it was created, but so far no hash has been placed in it.
Hash Fragmentation, Magnification and Compaction
If the hash table is full and you need to add new elements, you have to increase its size. This is a big advantage of hash tables compared to classic hard-limited arrays in C. With each increase, the size of the hash table doubles. I remind you that when increasing the size of the table, we pre-allocate the
arBucket C-array in memory, and put special UNDEF values in the empty cells. As a result, we cheerfully lose memory. Losses are calculated by the formula:( – ) * BucketAll this memory consists of UNDEF cells and waits for data to be placed into it.
For example, you have 1024 cells in a hash table, and you add a new item. The table grows to 2048 cells, of which 1023 are empty. 1023 * 32 bytes = approximately 32 KB. This is one of the drawbacks of implementing hash tables in PHP.
It must be remembered that a hash table may consist entirely of UNDEF cells alone. If you add and delete many items, the table will be fragmented. But in order to preserve the order of the elements, we add everything new only at the end of
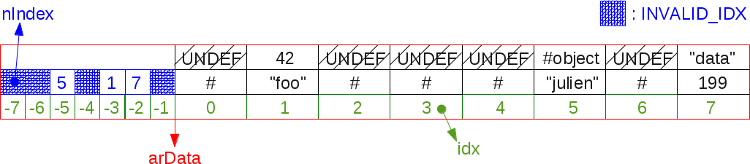
arData , rather than inserting spaces into the resulting spaces. Therefore, a situation may arise when we reach the end of arData , although UNDEF cells are still present in it.An example of a highly fragmented 8-cell hash table:
As you remember, new values cannot be stored in UNDEF cells. In the above scheme, when iterating a hash table, we go from
arData[0] to arData[7] .By increasing the size, you can reduce the
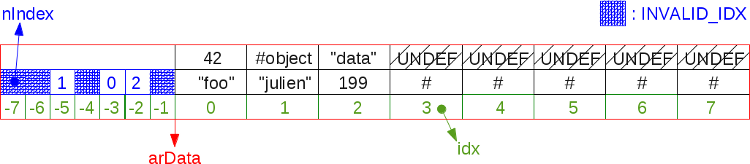
arData vector and eventually fill the empty cells by simply redistributing the data. When a table is given a command to resize, it first of all tries to compact itself. It then calculates whether it will have to increase again after compaction. And if it turns out that yes, then the table is doubled. After that, the vector arData begins to occupy twice as much memory (realloc()) . If it is not necessary to increase, then the data is simply redistributed into cells already allocated in memory. It uses an algorithm that we cannot use every time we remove items, because it spends too many CPU resources, and the exhaust is not so great. You remember the famous programmer compromise between the processor and memory?This illustration shows the previous fragmented hash table after compression:
The algorithm scans
arData and fills each UNDEF cell with data from the next non-UUNDEF cell. Simplified it looks like this: Bucket *p; uint32_t nIndex, i; HT_HASH_RESET(ht); i = 0; p = ht->arData; do { if (UNEXPECTED(Z_TYPE(p->val) == IS_UNDEF)) { uint32_t j = i; Bucket *q = p; while (++i < ht->nNumUsed) { p++; if (EXPECTED(Z_TYPE_INFO(p->val) != IS_UNDEF)) { ZVAL_COPY_VALUE(&q->val, &p->val); q->h = p->h; nIndex = q->h | ht->nTableMask; q->key = p->key; Z_NEXT(q->val) = HT_HASH(ht, nIndex); HT_HASH(ht, nIndex) = HT_IDX_TO_HASH(j); if (UNEXPECTED(ht->nInternalPointer == i)) { ht->nInternalPointer = j; } q++; j++; } } ht->nNumUsed = j; break; } nIndex = p->h | ht->nTableMask; Z_NEXT(p->val) = HT_HASH(ht, nIndex); HT_HASH(ht, nIndex) = HT_IDX_TO_HASH(i); p++; } while (++i < ht->nNumUsed); Hash table API
Well, now we know the main points of the implementation of the hash table in PHP 7. Let's now consider its public API.
There’s really nothing to talk about (well, in PHP 5, the API is made much better). Just when using the API function, do not forget about three things:
- About your operation (add, delete, clear, destroy, etc.).
- About the type of your key (integer or lowercase).
- About the type of data you want to store.
Whatever your key, lowercase or integer, the main thing: the API should be aware that the lowercase keys get hashes from
zend_string , and the integer keys are immediately used as a hash. Therefore, you can meet zend_hash_add(ht, zend_string, data) or zend_hash_index_add(ht, long, data) .Sometimes a key can be a simple pair (char * / int). In this case, you need to use another API, for example
zend_hash_str_add(ht, char *, int, data) . Remember that, be that as it may, the hash table will turn to zend_string , turn your string key into it and calculate its hash, spending some amount of processor resources. If you can use zend_string , use. Surely they have already calculated their hashes, so the API will simply take them. For example, the PHP compiler computes the hash of each part of the string that is used, like zend_string . OPCache stores a similar hash in shared memory. As the author of extensions, I recommend to initialize all your zend_string literals in zend_string .Now about the data that you are going to store in a hash table. Again, this can be anything, the hash table will still put the data in the
zval present in each Bucket . In PHP 7, zvals can store any kind of data. In general, the hash table API expects you to package the data in zval , which the API perceives as a value.The situation can be somewhat simplified if you have a pointer to the storage or memory area (the data referenced by the pointer). Then the API places this pointer or memory area in zval, and then zval itself uses the pointer as data.
Examples will help to understand the idea:
zend_hash_str_add_mem(hashtable *, char *, size_t, void *) zend_hash_index_del(hashtable *, zend_ulong) zend_hash_update_ptr(hashtable *, zend_string *, void *) zend_hash_index_add_empty_element(hashtable *, zend_ulong) When retrieving data, you get either zval * or NULL. If a pointer is used as a value, the API may return as is:
zend_hash_index_find(hashtable *, zend_string *) : zval * zend_hash_find_ptr(hashtable *, zend_string *) : void * zend_hash_index_find(hashtable *, zend_ulong) : zval * As for the _new API like
zend_hash_add_new() , it is better not to use it. It uses the engine for internal needs. This API causes the hash table to store data, even if it is already available in the hash (the same key). As a result, you will have duplicates, which may not have the best effect on your work. So you can use this API only if you are completely sure that there is no data in the hash that you are going to add. This will avoid having to search for them.: 5, API
zend_symtable_api() : static zend_always_inline zval *zend_symtable_update(HashTable *ht, zend_string *key, zval *pData) { zend_ulong idx; if (ZEND_HANDLE_NUMERIC(key, idx)) { /* handle numeric key */ return zend_hash_index_update(ht, idx, pData); } else { return zend_hash_update(ht, key, pData); } } , : , zval…
ZEND_HASH_FOREACH : #define ZEND_HASH_FOREACH(_ht, indirect) do { \ Bucket *_p = (_ht)->arData; \ Bucket *_end = _p + (_ht)->nNumUsed; \ for (; _p != _end; _p++) { \ zval *_z = &_p->val; \ if (indirect && Z_TYPE_P(_z) == IS_INDIRECT) { \ _z = Z_INDIRECT_P(_z); \ } \ if (UNEXPECTED(Z_TYPE_P(_z) == IS_UNDEF)) continue; #define ZEND_HASH_FOREACH_END() \ } \ } while (0) « -»
, :
arData , , arData . -: - arData . - , .: .
arData , . , .« -» (packed hashtable):
, .
arData[0] . , 2 * uint32 = 8 . . , , .: , , ( /), - . bucket'.
ZEND_API void ZEND_FASTCALL zend_hash_packed_to_hash(HashTable *ht) { void *new_data, *old_data = HT_GET_DATA_ADDR(ht); Bucket *old_buckets = ht->arData; ht->u.flags &= ~HASH_FLAG_PACKED; new_data = pemalloc(HT_SIZE_EX(ht->nTableSize, -ht->nTableSize), (ht)->u.flags & HASH_FLAG_PERSISTENT); ht->nTableMask = -ht->nTableSize; HT_SET_DATA_ADDR(ht, new_data); memcpy(ht->arData, old_buckets, sizeof(Bucket) * ht->nNumUsed); pefree(old_data, (ht)->u.flags & HASH_FLAG_PERSISTENT); zend_hash_rehash(ht); } -
u.flags , , -. , -, . , . For example: static zend_always_inline zval *_zend_hash_index_add_or_update_i(HashTable *ht, zend_ulong h, zval *pData, uint32_t flag ZEND_FILE_LINE_DC) { uint32_t nIndex; uint32_t idx; Bucket *p; /* ... */ if (UNEXPECTED(!(ht->u.flags & HASH_FLAG_INITIALIZED))) { CHECK_INIT(ht, h < ht->nTableSize); if (h < ht->nTableSize) { p = ht->arData + h; goto add_to_packed; } goto add_to_hash; } else if (ht->u.flags & HASH_FLAG_PACKED) { /* ... */ } else if (EXPECTED(h < ht->nTableSize)) { p = ht->arData + h; } else if ((h >> 1) < ht->nTableSize && (ht->nTableSize >> 1) < ht->nNumOfElements) { zend_hash_packed_grow(ht); p = ht->arData + h; } else { goto convert_to_hash; } /* ... */ : - , .
- : :
(_ - 2) * (uint32). , . - : . , .
(, 42 60), - «». ( — ) . - API:
void ZEND_FASTCALL zend_hash_real_init(HashTable *ht, zend_bool packed) ,
zend_hash_real_init() — , «» ( zend_hash_init() ). , «», - . , ., - .
-
(packed array):
function m() { printf("%d\n", memory_get_usage()); } $a = range(1,20000); /* range() */ m(); for($i=0; $i<5000; $i++) { /* , * : * «» */ $a[] = $i; } m(); /* * - «», * */ $a['foo'] = 'bar'; m(); , :
1406744 1406776 1533752 130 ( 25 000 ).
:
function m() { printf("%d\n", memory_get_usage()); } /* - . * 32 768 (2^15). */ for ($i=0; $i<32768; $i++) { $a[$i] = $i; } m(); /* */ for ($i=0; $i<32768; $i++) { unset($a[$i]); } m(); /* . - , * */ $a[] = 42; m(); Results:
1406864 1406896 1533872 , ( , modulo noise).
unset() arData 32 768 , UNDEF-zval'.- .
nNumUsed , arData ? , , .?
— , UNDEF-. : , , , . , , , .
/* , , : */ /* (idx). * , */ $a[3] = 42; m(); :
1406864 1406896 1406896 See the difference? 32 768 65 538 , . 32 767 .
Bucket , zval , long ( 42), . zval long. :) , 32 768 , , , . , , . ., , UNDEF-zval' «» .-, . , , , . «» , (
idx 0 ), — UNDEF-zval. function m() { printf("%d\n", memory_get_usage()); } /* - . * 32 768 (2^15). */ for ($i=0; $i<32768; $i++) { /* , */ $a[' ' . $i] = $i; } m(); /* */ for ($i=0; $i<32768; $i++) { unset($a[' ' . $i]); } m(); /* . * , */ $a[] = 42; m(); :
2582480 1533936 1533936 . 2,5 .
unset() , . 32 768 zend_string , 1,5 ., , . , , . 42 idx 0, . The end of the story.
, - , . ? , (, ?) / , . . , . «» 20 32 , .
(Immutable arrays)
— OPCache. OPCache, , . . . OPCache , . , AST-. , — AST-. For example:
$a = ['foo', 1, 'bar']; $a — AST-. , , . OPCache AST-, ( ) , . OPCache ., OPCache , IS_ARRAY_IMMUTABLE IS_TYPE_IMMUTABLE . IS_IMMUTABLE , . , . .
:
$ar = []; for ($i = 0; $i < 1000000; ++$i) { $ar[] = [1, 2, 3, 4, 5, 6, 7, 8]; } 400 OPCache, — 35 . OPCache , 8-
$ar . 8- . OPCache, 8- IS_IMMUTABLE $ar , ., , ,
$ar[42][3] = 'foo'; , 8- $ar[42] .- , . , PHP- — - Zend. PHP, . - . , / . -. OPArray ( ) ( ). PHP , OPArray: . OPCache IMMUTABLE , . , .
OPCache , . , ( , ). , - OPCache , PHP- . PHP.
. , :
$a = [1]; $b = [1]; . , ( interned strings ), , . — , ( , , ), runtime' PHP. ( ). , OPCache.
Source: https://habr.com/ru/post/308240/
All Articles