Hardware acceleration of corporate computing
“Accelerated Computing” (Accelerated Computing) is a computing model in which highly specialized co-processors (“accelerators”) are used in tandem with traditional CPUs. The main task of the coprocessors is the highly parallel execution of an intensive computational load and the release of CPU resources for other application needs (“offloading”).
Good examples of such “accelerators” can be GPUs from NVIDIA or Xeon Phi coprocessors, without which almost no project in the field of scientific or engineering computing can do. However, in the corporate sector, such technologies were practically not used (except for the use of GPUs in workplace virtualization farms ).
That is why the output of servers on the Oracle SPARC M7 chip, which contains, in addition to general-purpose cores, specialized Data Analytics Accelerators (DAX) coprocessors, can be considered the starting point for the penetration of “accelerated calculations” into the corporate market.
The main objective of DAX is to accelerate in-memory computing by unloading the main cores by performing search operations on the contents of RAM on coprocessors.
')
If it is necessary to transfer the search operation to the DAX, the general purpose kernel forms a request and sends it to execution for the “accelerators”, after which it continues to execute the main code. When this happens, the task is automatically paralleled across all chip accelerators, and then the results are collected (similar to MapReduce) in the chip cache and the kernel is notified of the completion of the operation. Coprocessors are connected to the chip's L3 cache, which allows for fast interaction with general-purpose kernels and the transfer of search results:

It is worth noting that in order to enable data search using DAX, they must be located in memory in a special format (In-Memory Column Store). A characteristic feature of this format is the ability to store data in a compressed form (the compression algorithm is a proprietary Oracle Zip), which allows you to place a larger amount of information in RAM and has a positive effect on the data processing speed of accelerators by saving bandwidth of the bus connecting the chip and RAM. When searching, decompression is performed by hardware, by means of DAX, and does not affect performance. Another feature is the presence of indexes containing the minimum and maximum values for each of the multiple memory segments (In-Memory Compression Units - IMCUs) that make up the In-Memory Column Store. It turns out that the “acceleration” of the sample has its price - a long initial placement of data in memory, during which they are compressed and preliminary analysis (a kind of indexing).
The main consumer of this technology at the moment is the Oracle Database 12c DBMS, which uses DAX to speed up the search for tables located in the In-Memory Column Store. The DBMS automatically transfers part of the operations to DAX, which leads to a significant acceleration of some queries.
However, it was interesting for us in Jet Infosystems to study the DAX technology without an intermediate “black box” in the form of the Oracle Database DBMS, which hides interesting details and creates additional overhead costs that do not allow us to accurately assess the benefits created by using co-processors.
In early March 2016, Oracle opened the DAX API for independent developers (Open DAX API). Now DAX can be used not only in the Oracle Database DBMS, but also in any other applications.
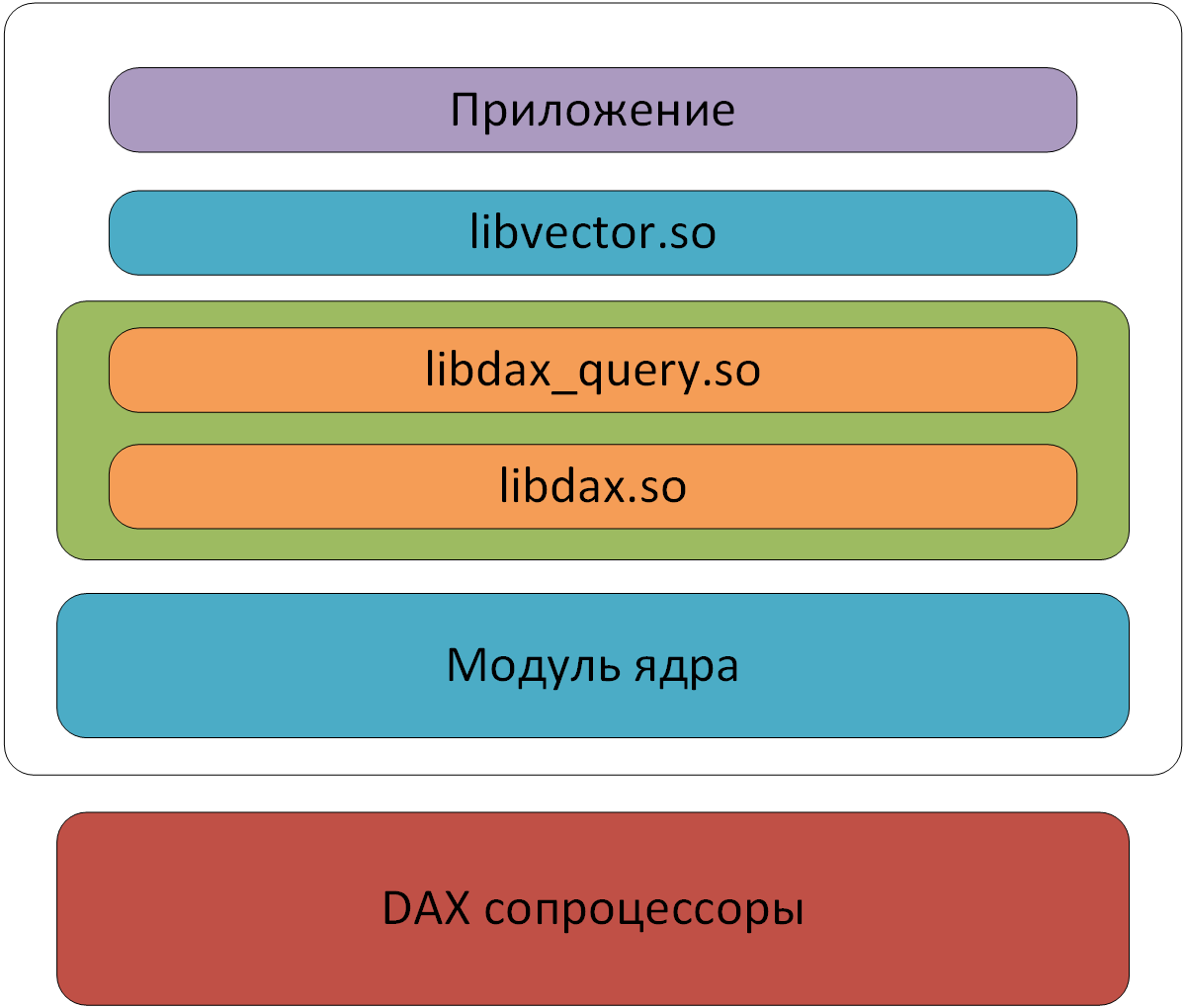
Oracle invited everyone in its cloud to test DAX not only from the DBMS, but also using the SDK for various programming languages (C, Python and Java). Since the low-level API, designed to interact directly with the coprocessor's hardware, is rather complicated, to get acquainted with the new technology, in addition to the SDK, it was proposed to use an additional library that provides high-level tools for working with data (libvector) located in the RAM. It was on its basis that a series of tests were made to test the operation of DAX.
SDK components
A simple analytical task was considered as a test case - searching for values in an integer array located in the memory that satisfies a given condition. In the form of a SQL query, this task could be written as:
The task was planned to be solved in two ways - by classical enumeration of all elements and using DAX co-processors.
In C, the solution to this problem was approximately as follows:
Note that when searching, the results are immediately saved to a new array. Once again, we note that the above code is executed on the core of the main processor.
For DAX, searching and retrieving results are divided into two operations:
In the case of DAX, the search operation for values (the vector_in_range function) satisfying the condition returns a bit vector (bit vector), on the basis of which a new vector with results is formed by another query (vector_extract). The records sought will be retrieved from their IMCUs and recorded in new IMCUs, which you can work with again through DAX.
This approach allows you to work effectively with key / value data sets when you need to find keys whose values satisfy the condition. In this case, two data arrays are formed in the memory - a vector of keys and a vector of values:
Searches for a vector of values using DAX, which results in a bitmap:
To retrieve the desired elements, the resulting bitmap is applied using the DAX to the key vector:
In addition, over the set of bit vectors it is possible to perform operations of the AND and OR types, that is, to transfer to DAX the union of the results of several comparisons, as, for example, in the query:
Our experiments with combining two bit vectors through AND showed the advantage of a call made on a DAX:
Before element-wise (with elements of type long) the union of bitmaps on a processor of the form:
3–6 times in execution speed depending on the number of elements.
But back to the program. The elements of our array will be random integers, and the search will be performed over the range from –109 to 109 (that is, approximately half of the numbers will satisfy the condition).
We launched both variants of our test implementation on the quantities of numbers in the array from 1 million to 500 million and measured the search execution time and the time of copying the results into a new array, which you can work with again. For classical brute force, it makes no sense to separate these two operations, since copy to the new array will have either the element address (8 bytes) or the element itself (4 bytes).
So, below is a graph of the dependence of search time and data retrieval on the number of array elements:
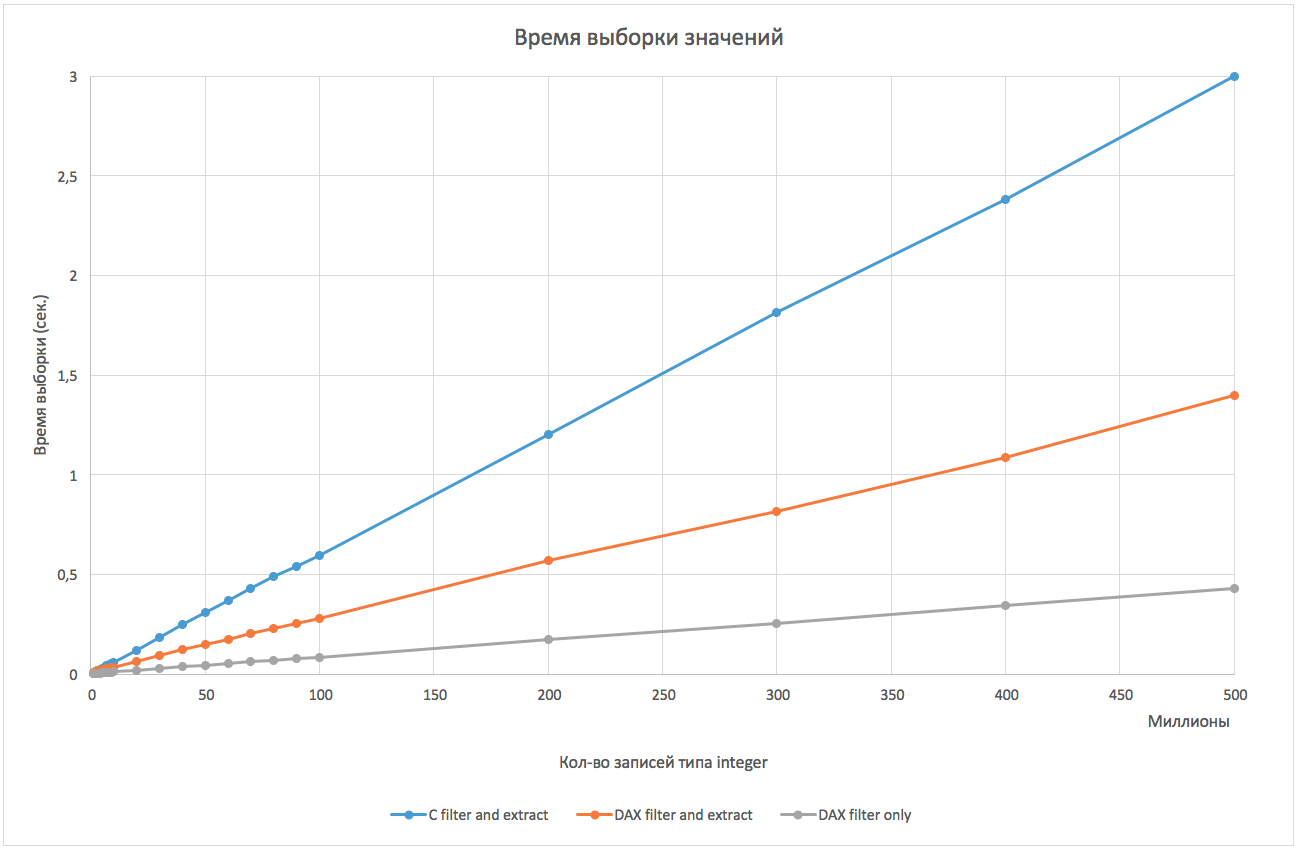
Using DAX showed a 2-fold superiority over a simple brute force. If you compare only the search (without saving the values found, that is, when performing an operation like “SELECT COUNT (*)" or in order to get a bitmap), then the search speed through DAX is more than 5 times higher.
You can monitor the use of coprocessors in the system using the busstat utility, which collects performance metrics from various processor components (busstat -w dax 30 1). During the execution of our tests, we observed parallelization of requests on 8 of 32 DAX co-processors (there are eight of them in each M7 processor). When using multiple user processes in parallel, the load will be visible on all 32 coprocessors.
Of course, you can implement all DAX algorithms programmatically (which was implemented in the Oracle Database In-Memory Option before the appearance of DAX), make additional optimizations and get even more impressive results than with DAX (especially if you manually parallelize the task on all SPARC M7 processor threads ). But the purpose of the DAX is to shift the work of the processor cores to specialized coprocessors. Those. In general, it is not the performance gain itself that is important, namely the possibility of unloading the main CPU.
Among the code examples for DAX, Oracle engineers implemented its support in an application for Apache Spark . According to the manufacturer, when using DAX performance increased by 6 times. The essence of the optimization was the set of operations with bitmaps via DAX, which was much faster than on the processor.
Transferring the execution of software logic from processors to specialized devices has once again proved its usefulness. Especially in such a “hot” area at the moment as In-Memory Computing.
The ability to use DAX through an open API can attract new software products to the world of SPARC.
However, similar functions can be implemented in the future and on the Intel platform on already existing hardware solutions - using the Xeon Phi coprocessor. At a minimum, research in this area is already underway:
Test programs were built using the Solaris Studio 12.4 compiler. The maximum optimization level (-xO5) was used, with the help of which the “classical” calculations were significantly accelerated. Source codes are available on github .
SPARC M7 and DAX - the official release of Oracle .
The article was prepared by Dmitry Glushchenko, system architect of the Jet Systems Infosystems Design Center. We welcome your constructive comments.
Good examples of such “accelerators” can be GPUs from NVIDIA or Xeon Phi coprocessors, without which almost no project in the field of scientific or engineering computing can do. However, in the corporate sector, such technologies were practically not used (except for the use of GPUs in workplace virtualization farms ).
That is why the output of servers on the Oracle SPARC M7 chip, which contains, in addition to general-purpose cores, specialized Data Analytics Accelerators (DAX) coprocessors, can be considered the starting point for the penetration of “accelerated calculations” into the corporate market.
The main objective of DAX is to accelerate in-memory computing by unloading the main cores by performing search operations on the contents of RAM on coprocessors.
')
If it is necessary to transfer the search operation to the DAX, the general purpose kernel forms a request and sends it to execution for the “accelerators”, after which it continues to execute the main code. When this happens, the task is automatically paralleled across all chip accelerators, and then the results are collected (similar to MapReduce) in the chip cache and the kernel is notified of the completion of the operation. Coprocessors are connected to the chip's L3 cache, which allows for fast interaction with general-purpose kernels and the transfer of search results:
It is worth noting that in order to enable data search using DAX, they must be located in memory in a special format (In-Memory Column Store). A characteristic feature of this format is the ability to store data in a compressed form (the compression algorithm is a proprietary Oracle Zip), which allows you to place a larger amount of information in RAM and has a positive effect on the data processing speed of accelerators by saving bandwidth of the bus connecting the chip and RAM. When searching, decompression is performed by hardware, by means of DAX, and does not affect performance. Another feature is the presence of indexes containing the minimum and maximum values for each of the multiple memory segments (In-Memory Compression Units - IMCUs) that make up the In-Memory Column Store. It turns out that the “acceleration” of the sample has its price - a long initial placement of data in memory, during which they are compressed and preliminary analysis (a kind of indexing).
The main consumer of this technology at the moment is the Oracle Database 12c DBMS, which uses DAX to speed up the search for tables located in the In-Memory Column Store. The DBMS automatically transfers part of the operations to DAX, which leads to a significant acceleration of some queries.
However, it was interesting for us in Jet Infosystems to study the DAX technology without an intermediate “black box” in the form of the Oracle Database DBMS, which hides interesting details and creates additional overhead costs that do not allow us to accurately assess the benefits created by using co-processors.
Using DAX co-processors from third-party applications
In early March 2016, Oracle opened the DAX API for independent developers (Open DAX API). Now DAX can be used not only in the Oracle Database DBMS, but also in any other applications.
Oracle invited everyone in its cloud to test DAX not only from the DBMS, but also using the SDK for various programming languages (C, Python and Java). Since the low-level API, designed to interact directly with the coprocessor's hardware, is rather complicated, to get acquainted with the new technology, in addition to the SDK, it was proposed to use an additional library that provides high-level tools for working with data (libvector) located in the RAM. It was on its basis that a series of tests were made to test the operation of DAX.
SDK components
Test script
A simple analytical task was considered as a test case - searching for values in an integer array located in the memory that satisfies a given condition. In the form of a SQL query, this task could be written as:
SELECT value FROM values WHERE value BETWEEN value_low AND value_high; The task was planned to be solved in two ways - by classical enumeration of all elements and using DAX co-processors.
Implementation
In C, the solution to this problem was approximately as follows:
#define RANDOM_SEED 42 int *values, *results; int low = VALUE_LOW, high = VALUE_HIGH; values = generate_random_values_array(NUM_VALUES, RANDOM_SEED); results = malloc(NUM_VALUES * sizeof(int)); for (i=0; i<NUM_VALUES; i++) { if (values[i] >= low && values[i] <= high) { results[n] = values[i]; n++; } } Note that when searching, the results are immediately saved to a new array. Once again, we note that the above code is executed on the core of the main processor.
For DAX, searching and retrieving results are divided into two operations:
#include <vector.h> /* DAX */ #define RANDOM_SEED 42 int low = VALUE_LOW, high = VALUE_HIGH; vector valuesVec, bitVec, resultsVec; valuesVec = generate_random_values_vector(NUM_VALUES, RANDOM_SEED); /* */ bitVec = vector_in_range(valuesVec, &low, &high); /* , */ n = bit_vector_count(bitVec); /* , */ resultsVec = vector_extract(valuesVec, bitVec); In the case of DAX, the search operation for values (the vector_in_range function) satisfying the condition returns a bit vector (bit vector), on the basis of which a new vector with results is formed by another query (vector_extract). The records sought will be retrieved from their IMCUs and recorded in new IMCUs, which you can work with again through DAX.
This approach allows you to work effectively with key / value data sets when you need to find keys whose values satisfy the condition. In this case, two data arrays are formed in the memory - a vector of keys and a vector of values:
vector keysVec, valuesVec; int low = VALUE_LOW, high = VALUE_HIGH; populateKeyValueVectors(&keysVec, &valueVec); Searches for a vector of values using DAX, which results in a bitmap:
bitVec = vector_in_range(valuesVec, &low, &high); To retrieve the desired elements, the resulting bitmap is applied using the DAX to the key vector:
resultsVec = vector_extract(keysVec, bitVec); In addition, over the set of bit vectors it is possible to perform operations of the AND and OR types, that is, to transfer to DAX the union of the results of several comparisons, as, for example, in the query:
SELECT part FROM parts WHERE mass > 100 AND volume < 30; Our experiments with combining two bit vectors through AND showed the advantage of a call made on a DAX:
bit_vector_and2(bitVec1, bitVec2); Before element-wise (with elements of type long) the union of bitmaps on a processor of the form:
for (i=0; i<elemcount; i++) { resultsRegularBitMap[i] = regularBitMap1[i] & regularBitMap2[i]; } 3–6 times in execution speed depending on the number of elements.
But back to the program. The elements of our array will be random integers, and the search will be performed over the range from –109 to 109 (that is, approximately half of the numbers will satisfy the condition).
We launched both variants of our test implementation on the quantities of numbers in the array from 1 million to 500 million and measured the search execution time and the time of copying the results into a new array, which you can work with again. For classical brute force, it makes no sense to separate these two operations, since copy to the new array will have either the element address (8 bytes) or the element itself (4 bytes).
results
So, below is a graph of the dependence of search time and data retrieval on the number of array elements:
Using DAX showed a 2-fold superiority over a simple brute force. If you compare only the search (without saving the values found, that is, when performing an operation like “SELECT COUNT (*)" or in order to get a bitmap), then the search speed through DAX is more than 5 times higher.
You can monitor the use of coprocessors in the system using the busstat utility, which collects performance metrics from various processor components (busstat -w dax 30 1). During the execution of our tests, we observed parallelization of requests on 8 of 32 DAX co-processors (there are eight of them in each M7 processor). When using multiple user processes in parallel, the load will be visible on all 32 coprocessors.
Of course, you can implement all DAX algorithms programmatically (which was implemented in the Oracle Database In-Memory Option before the appearance of DAX), make additional optimizations and get even more impressive results than with DAX (especially if you manually parallelize the task on all SPARC M7 processor threads ). But the purpose of the DAX is to shift the work of the processor cores to specialized coprocessors. Those. In general, it is not the performance gain itself that is important, namely the possibility of unloading the main CPU.
Other interesting moments
Among the code examples for DAX, Oracle engineers implemented its support in an application for Apache Spark . According to the manufacturer, when using DAX performance increased by 6 times. The essence of the optimization was the set of operations with bitmaps via DAX, which was much faster than on the processor.
findings
Transferring the execution of software logic from processors to specialized devices has once again proved its usefulness. Especially in such a “hot” area at the moment as In-Memory Computing.
The ability to use DAX through an open API can attract new software products to the world of SPARC.
However, similar functions can be implemented in the future and on the Intel platform on already existing hardware solutions - using the Xeon Phi coprocessor. At a minimum, research in this area is already underway:
Post Scriptum
Test programs were built using the Solaris Studio 12.4 compiler. The maximum optimization level (-xO5) was used, with the help of which the “classical” calculations were significantly accelerated. Source codes are available on github .
SPARC M7 and DAX - the official release of Oracle .
The article was prepared by Dmitry Glushchenko, system architect of the Jet Systems Infosystems Design Center. We welcome your constructive comments.
Source: https://habr.com/ru/post/307862/
All Articles