The tale of virtualization-clustering and storage Fujitsu
Here is how it was.
One small state-scale organization decided to upgrade its server equipment in its local ownership. And her men turned to our valiant managers, they say, we want servers with disks for our important services. And they learned from managers about virtualization overseas, fault tolerant, and clustering.
Actually, the fairy tale has a long effect, but it's done quickly.
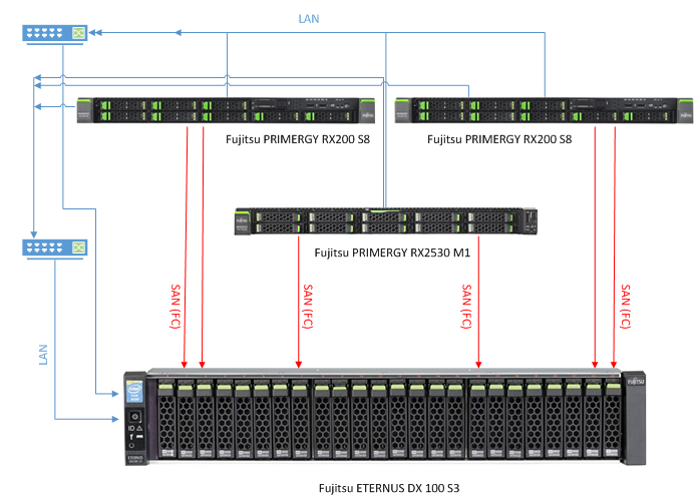
This is how a bundle of two Fujitsu PRIMERGY RX 200 S8 servers and the ETERNUS DX 100 S3 storage system appeared in the organization. And no one at that time thought that very soon those server resources would not be enough. On the contrary, they considered and were sure that it was enough for a long time. But quickly the virtual machines became fertile and voracious, they were fat. And then the disk space was expanded, and their two young Fujitsu PRIMERGY RX2530 M1 got hooked to the two RX 200.
We will tell you about sharing the new server in the cluster, as well as adding new expansion cards with additional FC interfaces to the controller blocks. Or rather, about the simplicity, security and convenience of all these and other engineering manipulations that are possible (in our case) with VMware virtualization and Fujitsu hardware. Those who already have storage and one or another implementation of server virtualization (or just a thread) will not be surprised and, probably, will not learn anything new from this text. But there are still many organizations where any actions with the equipment, its rebooting and stopping cause horror and force meticulously plan and minimize the upcoming downtime.
About the storage system
As is known, in order to add or remove a component (not supporting hot swap) in an already running device that provides services and constantly exchanging data, this device needs to be turned off. In the case of the server, such a stop is inevitable, in the case of modern storage systems that have two controllers, everything is done without stopping or pauses. Indeed, in addition to fault tolerance through multipath I / O (MultiPathing - each of the hosts (servers) has several data channels from its I / O ports to the ports of each of the storage controllers), modern data storage systems (in particular, this is Fujitsu ETERNUS DX 100 S3) are able to distribute / parallelize the transfer of data on these channels, reducing the load on the channel and increasing bandwidth. Idle time in case of failure of one of the channels is reduced to zero (active / active mode) or minimized when automatically switching from the active (but "lost") channel to the passive - "waiting" (active / passive mode). Actually, these features, as well as features of the operating system, allow us to make changes to the controller units (or replace them completely) without downtime and reboot.
With the DX 100 S3, this is easily and simply performed as follows, reflecting all the safety and reasonableness of the manipulations:
Having entered the GUI under the service engineer account (f.ce), we transfer the whole system to the maintenance mode
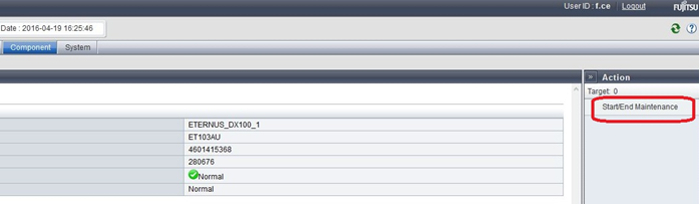
- Next, choosing the controller module we need, we transfer it to the maintenance mode

The system before performing the required unit in maintenance mod performs a series of security tests and implements the request only if the second controller and dependent components are working properly and the data integrity is not compromised. All logical drives for which the disabled controller was the “owner” will go into the service of the second controller almost instantly and seamlessly after synchronizing the cache and changing the data transfer paths.
- The graphical interface will show that the controller is no longer available and can be removed. At the end of the manipulations, also in online mode, we return it to its place; the system automatically, without rebooting the controller blocks themselves, recognizes and returns the previous work pattern. New devices that appear (we have FC adapters) need to be activated by adding to the system. That's all, truly ETERNUS DX has a real-time operating system.
In the IBM (Lenovo) Storwize line, for example, these manipulations also go online, but the controllers themselves perform a cycle of several alternate reloads after indicating that this is not an error at all and that we have added one or another component. And the reboot can last, according to the testimony of the system, up to 30 (!!!) minutes each.

I would like to add a few more words about the security algorithm implemented here, it can be said, protection against rash actions. And its essence is simple and elegant: you can not remove anything by accidental pressing is not where it should be. For example, we cannot remove a RAID or a logical disk until we analyze the whole chain of interconnections from the very end, namely, we first need to remove the LUN groups from the Host Affinity communication settings, then remove the logical disks themselves from the LUN -groups, remove logical drives and only then destroy the RAID. Agree, to do this by accident and inadvertently almost impossible.


The "Delete" tabs of the LUN Group and the RAID Group are not active until the "connections" are broken.
It is worth mentioning that from the command line (SSH), if necessary, the forced removal of any elements is available immediately.
About servers and virtualization
As mentioned earlier, the server part of the cluster initially consisted of 2 Fujitsu PRIMERGY RX200 S8 servers, to which they later added a Fujitsu PRIMERGY RX 2530 M1 device of similar class and performance. In fact, the architecture of the device is very similar, but the new line of Intel processors (as a result, new functions, instructions, protocols) in the RX 2530 M1 promised us problems at the VMware cluster level, namely, problems with the migration of machines between hosts. What appeared after the implementation: some of the existing machines during the migration produced an error related to the CPU of the target server.
Of course, VMware has provided a solution for this kind of problems, its EVC (Enhanced vMotion Compatibility) function is designed to “mask” the differences in processors of different generations. Alas, initially the cluster was raised on the fifth version of the VMware virtual realm (VMware vSphere 5.5), which at that time still had no idea about the new Intel processors. However, the point is that for our situation this trouble is not a problem at all. Having a failover cluster, upgrading to VMware vSphere 6.0 (the EVC of which has the ability to work with all versions of processors) takes only a few hours. With proper use and planning of the cluster, any of the servers available in it can be freely maintained by distributing its machines on the remaining hosts using live migration.
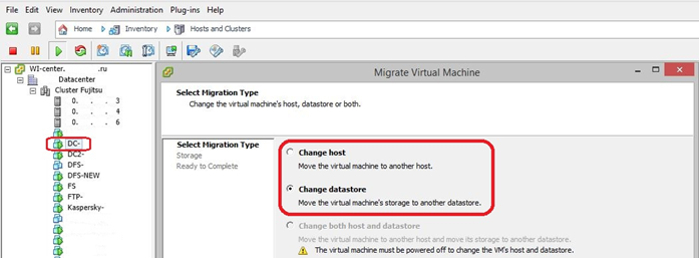
The machine was migrated with a change not only of the host, but also of the data storage, since the storage space was reorganized. This process proceeds by complete cloning of the machine, the original of which is automatically deleted after synchronization. Simultaneous migration (server and disk) is possible only when the virtual machine is turned off.
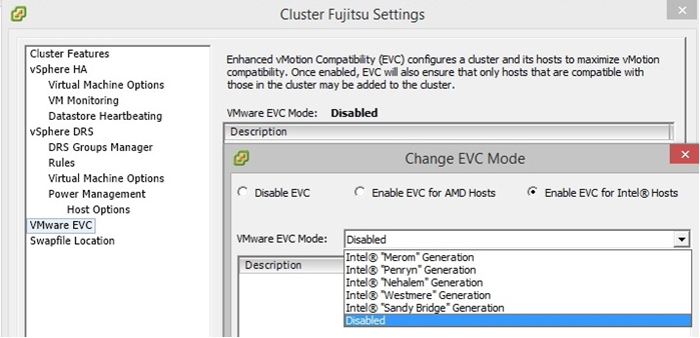
In VMware vSphere 5.5, processor support ends with the generation of "Sandy Bridge"

In VMware vSphere 6.0, we can observe "Ivy Bridge" and "Haswell"
Summing up this small story about cluster virtualization, I want to quote a line from the song - “It was difficult for me to fly with you, but without you I can't breathe!”. For it is difficult to decide this, and it is expensive. But then it’s scary to imagine how people used to do without all this, remembering the spent weekends, dinners and nights, nerves, worries and hopes to have time to complete their plans before the end of the break or the beginning of the working day.
Prepared on the material of Tretyakov Vyacheslav, an engineer of the company "Paradigma". See the full article here .
')
Source: https://habr.com/ru/post/307768/
All Articles