Search for invalid passports or learn how to prepare binary files
 In the comments to the publication Why Go surpasses mediocrity , one of the habrayers suggested writing an algorithm for searching for a list of invalid passports as an example.
In the comments to the publication Why Go surpasses mediocrity , one of the habrayers suggested writing an algorithm for searching for a list of invalid passports as an example.One of the conditions of the task was not to use DBMS for this purpose. Also, the solution should at a minimum use memory, disk space and CPU.
To my surprise, I found out that most commentators suggested using a DBMS, despite the fact that a solution using standard databases would be quite cumbersome (except that for the data itself you need to use at least 5 bytes per record, so also almost as many places on indexes).
Having experience working on binary databases for Sypex Geo , I decided to try to sketch a binary file format and a search algorithm for it.
')
Data analysis
First of all, in order to create a special file format, you need to analyze the data itself.
The initial data is a CSV file containing a list of invalid passports (series and number, separated by commas), we are only interested in Russian passports (4 digits of the series and 6 digits of the number).
In the bz2 archive this list occupies 359 MB, in unpacked form 1.13 GB. About 102 million records. I loaded the data into MySQL (there is a convenient loading of a CSV file using LOAD DATA), and already in it I analyzed the data. Without indexes, the table with the following structure hung at 680 MB.
CREATE TABLE `pass` ( `seria` SMALLINT(5) UNSIGNED NOT NULL, `num` MEDIUMINT(8) UNSIGNED NOT NULL ) ENGINE=MyISAM ROW_FORMAT=FIXED If you add an index on the num column, it will be 1.5 GB, and if you make an index on two columns, then it will already be 1.7 GB.
It turned out that:
- For one series can be up to 600,000 numbers.
- At the time, as for a single number, a maximum of 200 series.
From here we conclude that searching immediately by number is more profitable, since this will greatly reduce further search. So we make an index by passport number.
Create your own format
Our binary file will consist of two parts, the first part will be an index in which there will be a constant number of elements, namely a million values from 000 000 to 999 999. Each index element occupies 4 bytes and contains an offset in the second part of the file, where series listings for the corresponding number. The series itself is stored in the second part of the file as two-byte values. The number of elements in the series for a particular number is the difference of the offsets (the desired number) and (the desired number + 1).
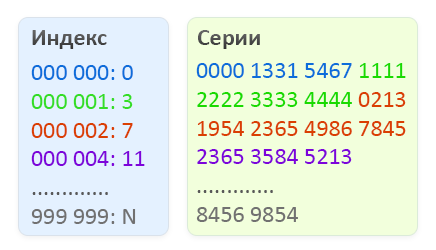
Schematic display of the structure of the binary file to search for invalid passports.
To find out if there is a passport in the list of invalid, you need to perform the following simple steps.
For example, take the number 2365 000002 .
- According to the passport number, we determine the offset in the index, for this we multiply the number by 4 (the size of the index element). 4 * 000002 = 8 bytes (red block in the figure)
- Perform the offset and read 2 index elements (2 * 4 bytes) to know the beginning of the list of series and the end. Convert them to 2 decimal 32-bit numbers. In our case, it turns out 7 and 11 (for clarity, the display shows not the offset in bytes, but 1 unit offset = 1 series)
- We read data on the shift of the beginning of the list of series to the end of the list of series of the desired number, remember that the series are written in 2 bytes.
- Now we are looking for the series we need among two-byte sequences.
- If found, the passport is not valid, otherwise it is not listed as invalid in the database.
Since there are no more than 200 series for each number, you can search for the series by a simple search. To speed up the process, you can use a binary search, pre-sorting the series. But about any additional optimizations, probably, in another publication I will write if it is interesting.
And now testing
For example, I sketched a couple of test scripts in PHP. One for converting a CSV file into our binary format. The second to find the right passport. Archive with scripts can be downloaded here .
Also compare the resulting solution with the option in which the data in MySQL. Data is stored on the SSD (in the case of storage on the HDD, the indicators will be worse), besides, there is enough memory on the server to cache all the tables in memory, i.e. The most optimal option for MySQL.
Testing was conducted on your favorite test site - Vultr. Favorite because you can quickly raise a powerful VPS-ku with hourly pay and storage snapshots free (ie, you can delete, and then, when you need to quickly restore the test environment).
Bonus
Those who want to receive $ 20 to the account can use the ref-link (for new users only) to pay for Vultr services.
For VPS, the selected plan is 6 CPU, 8 GB, 150 GB SSD, MariaDB 10.1.16, PHP 7.0.9.
So, to the numbers
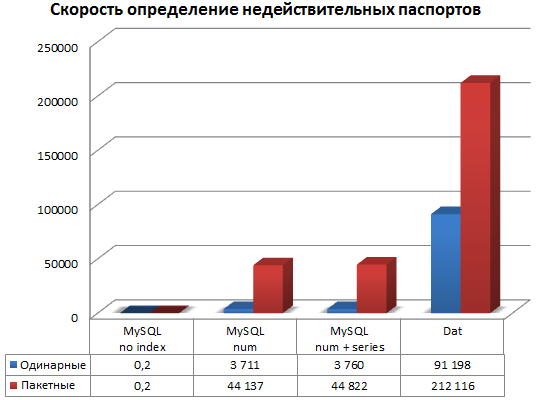
For each type of data storage, we checked two modes: single mode (when opening a file and connecting to the database is done for each number) and batch mode (opening the file and connecting to the database once).
| Dat file | Mysql without indexes | Mysql index by numbers | Mysql index by numbers and series | |
| DB size (including index) | 198 MB | 680 MB | 1.5 GB | 1.7 GB |
| Index size | 4 MB | 0 MB | 893 MB | 1.07 GB |
| Download CSV in DB (mm: ss) | 3: 54 * | 0:31 | 3:38 | 3:42 |
| Single search speed (p / s) | 91 198 | 0.2 ** | 3,711 | 3,760 |
| Search speed batch (p / sec) | 212,116 | 0.2 | 44 137 | 44,822 |
** For all methods, 300,000 passports were run, except for MySQL without an index, since it takes up to 10 seconds to search for one passport.
findings
As we see from the results of testing, the custom solution, sharpened for the desired task, can work much faster than general-purpose DBMS, besides, the format is 7-8 times more compact than the table in MySQL.
And the script itself for searching the file takes less than 10 lines (without comments).
$pass = '0307,000000'; // $fn = fopen('passports.dat', 'rb'); // // 2- , , $seria = pack('n', substr($pass, 0, 4)); $num = substr($pass, 5); // fseek($fn, $num * 4); // 2 4 $seek = unpack('Nbegin/Nend', fread($fn, 8)); // fseek($fn, $seek['begin']); $series = fread($fn, $seek['end'] - $seek['begin']); // echo ($pos = strpos($series, $seria)) !== false && $pos % 2 == 0 ? 'INVALID' : 'VALID'; PS The script is naturally maximally simplified, and is intended for training purposes, and not for production (but this concerns not so much the algorithm, as error handling).
Translations to other programming languages are welcome, it will be possible to measure :)
Source: https://habr.com/ru/post/307568/
All Articles