From Slides Defined to Software Defined Networking. Part 1

Each of us has heard about the concept of software-defined networks (Software Defined Networking, SDN). However, despite the continuous development and a number of significant changes, this concept has not been embodied in the form of commercially held products for a long time, in fact, remaining at the “Slides Defined” level, that is, as speculative constructions in vendor presentations and integrators. In light of this, it is not surprising that overly active discussion of the SDN topic in recent years, coupled with the lack of fully working solutions in the market, has led, if not to the rejection, then to a critical attitude to this technology from the part of the IT community. In this article, we would like to dispel this skepticism and talk about a network factory that meets the classic SDN criteria and at the same time is a complete, “boxed” solution.
The article aims to tell about the architecture of the solution, its features, as well as personal impressions of testing. In the process of preparing the material, we wanted to show how simple and convenient SDN can be for building a data center, so we will deliberately avoid deep immersion in technology and focus more on the possibilities that this solution can bring. Due to the large amount of material we have divided it into 3 parts: a general description and architecture, functionality and integration capabilities.
Instead of intro
Unlike the established technologies for building distributed corporate and campus networks, approaches to the organization of the data center network are constantly evolving. This is partly due to a significant increase in requirements from applications and adjacent systems. Thus, for applications to work, an ever-greater bandwidth is required, requirements for predictability of delay, as well as various parameters for traffic transfer, are being tightened, which leads to a revision of the mechanisms and topologies used. Adjacent systems (in particular, virtualization and orchestration systems), in turn, require greater integration and automation capabilities to influence the processes occurring in the network.
')
The concept of Software Defined Networking is designed to solve most problems with integration and automation through the use of a single point of control and monitoring of the network. The same principles should help to significantly reduce the user’s dependence on the vendor - still in the networked world, the manufacturer is usually the only supplier of software to its equipment, despite the fact that the equipment is created on the basis of typical elements produced by third-party companies.
In turn, the development of the market for special microcircuits (ASIC) and hardware manufacturers led to the appearance on the market of switches without proprietary software (so-called BM switches ), for which the operating system providing the basic functionality is developed by other companies. The cost of such switches is much lower than that of their branded counterparts, and the client has the opportunity to choose an operating system. But, unfortunately, the overwhelming majority of such SDN products are some kind of designer who offers to assemble a solution from available parts (switches, controllers, software). Perhaps the use of such kits is acceptable for companies with a significant staff of technical specialists, but for most organizations this approach is inconvenient.
Meanwhile, our company recently managed to test a solution for building the data center network Big Cloud Fabric (BCF) from Big Switch Networks, which is much more user friendly. Big Cloud Fabric is a classic SDN solution: it uses BM switches as the hardware infrastructure of the network fabric and the centralized Control Plane , placed on a separate controller. The controller is assigned the functions of calculating the topology, processing routing information, studying connected hosts, as well as configuring and controlling all functions of the system. The results of the controller are synchronized between the switches and directly recorded in the ASIC hardware tables. And at the same time, BCF is a complete, “boxed” solution that does not require the user to take long and difficult processes of integrating the components with each other.
About Big Switch Networks Big Switch Networks was founded in 2010 by the SDN concept development team from Stanford University. As a recognized industry pioneer, since 2013, the company has been developing SDN solutions using BM switches. The product portfolio is represented by two systems: Big Cloud Fabric (network data center factory) and Big Fabric Monitoring (package broker). The company has received numerous awards in the field of virtualization, as well as cloud and SDN technologies.
Big Switch Networks was founded in 2010 by the SDN concept development team from Stanford University. As a recognized industry pioneer, since 2013, the company has been developing SDN solutions using BM switches. The product portfolio is represented by two systems: Big Cloud Fabric (network data center factory) and Big Fabric Monitoring (package broker). The company has received numerous awards in the field of virtualization, as well as cloud and SDN technologies.
Big Switch Networks was founded in 2010 by the SDN concept development team from Stanford University. As a recognized industry pioneer, since 2013, the company has been developing SDN solutions using BM switches. The product portfolio is represented by two systems: Big Cloud Fabric (network data center factory) and Big Fabric Monitoring (package broker). The company has received numerous awards in the field of virtualization, as well as cloud and SDN technologies.Let's take a closer look at how the solution works based on such an atypical approach and what opportunities it can offer to users.
Big Cloud Fabric Architecture
What is Big Cloud Fabric? If you try to briefly formulate a definition, the following would be most appropriate: BCF is a data center data center with the ability to use BM switches that are under single control and have a single interface for control, analytics and integration.
BCF is based on the Ethernet switch network, built on the Spine and Leaf topology, which is currently the most popular for building data center networks. Additionally, any two leaf switches can be combined into an MC-LAG pair (Leaf Group in BCF terminology).
Why Spine and Leaf?
The topology of Spine and Leaf is becoming very popular in data center networks, as it is optimized for the transmission of east-west traffic, provides a low level of re-subscription and a predictable, constant delay. For example, in the classical two-tier topology, where a certain number of ToR switches are connected to two EoR switches , when one of the EoRs fails, the re-subscription immediately increases by 2 times, and the failure of the second one completely disables the network. In the case of the spine and leaf topology, for example, with 4 spine switches, the failure of one of them increases the oversubscription only by 33%, while the number of intermediate nodes for any 2 network hosts is always the same.
However, unlike other solutions, BCF can use switches from different manufacturers that support the installation of network operating systems. From a technical point of view, these switches are no different from the usual, branded models. They use the same hardware components — the central processor, the memory, and the commercially available ASIC. However, instead of the operating system, BM switch manufacturers install the ONIE bootloader, a small system utility that downloads and installs any compatible network operating system. Such an approach gives considerable flexibility in building a network, since it provides the possibility of choosing a hardware platform regardless of the software used.
Bare-metal switch, white-box switch ...
Until recently, a very conservative model operated in the networked world — the OS supplier of network equipment was invariably also a supplier of the hardware platform. However, due to the development of commercially available ASIC, switches without an operating system (Bare-metal) or with a pre-installed OS, but with the possibility of its replacement (White Box) began to appear on the market. The development of network operating systems that support various hardware platforms (Cumulus Linux, Pica8, SwitchLight OS) has also accelerated. This was made possible thanks to the vendor’s provision of an ASIC API for interoperability, as well as the introduction of the ONIE standardized loader.
The factory can support any switches built on ASIC Broadcom Trident II / II + and Tomahawk, which is the majority of the data center switches currently manufactured (both classic and Bare-metal / White Box). The official list of supported models includes various switches from Dell Networks and Accton / Edge-Core. This is due to the fact that Big Cloud Fabric is not a set of switches, independently working with each other, but a single factory with centralized management and control. That is why the tested compatibility of all components is extremely important for the uptime of the entire network. At the same time, Big Switch Networks regularly updates the list of supported switches.
The switches themselves are useless without an operating system that could manage them. In the case of BCF, all controls, controls and integration with third-party systems are placed on a special device - the factory controller. Its tasks include all management and control functions — providing a factory access interface, collecting information about connected hosts, calculating topologies, synchronizing information for programming hardware tables between switches, and much more. Lightweight operating system Switch Light OS is installed on the switches, which is designed to receive instructions from the controller and directly program them in the switch ASIC, as well as collect raw statistics data and send them to the controller for analysis. At the same time, the network administrator does not need to manually install the OS on the switch - BCF supports the Zero Touch Provisioning mechanism, thanks to which the switch, once connected to the control network, is automatically detected by the controller, the OS and configuration templates are installed on it. Information between the switches and the controller is transmitted via a highly modified OpenFlow protocol.
Switch Light OS & Open Network Linux
The lightweight Switch Light OS operating system used in BCF is based on the well-known Open Network Linux project (part of the Open Compute Project). ONL is an optimized Debian distribution with a large number of drivers for peripheral devices (SFP, FAN, GPIO, ASIC), and a minimal set of utilities. As a standalone product, ONL is rarely used, but is used as a basis for the development and construction of more powerful projects. In fact, Switch Light OS is the own OpenFlow agent of Big Switch Networks running on Open Network Linux.
If we make an obvious analogy with a modular switch, then switches are line cards (leaf) and switching modules (spine), and the controller is the supervisor of a large geographically distributed switch. To ensure fault tolerance, the factory is managed by a cluster of at least 2 nodes, and the network of interaction between the controller and switches is implemented as a separate, out of band infrastructure.
Big Cloud Fabric is available in two versions: fully physical factory (P Fabric) and hybrid (P + V Fabric). The latter option offers the ability to install the Switch Light VX software agent (in fact, the same Switch Light OS) for Open vSwitch software switches in a virtual KVM environment. Switch Light VX works in the user's environment and has no effect on the core of the hypervisor. Its task is to synchronize traffic forwarding policies with the factory controller and implement them in Open vSwitch. In fact, in BM switches, Swith Light OS relies on the “muscles” of the ASIC, and in a virtual environment, on the CPU and Open vSwitch. Thus, due to the presence of the agent in a virtual environment, not only is traffic forwarding optimized (switching and routing between virtual machines is performed on a physical host, without transferring to an external device), but it also becomes possible to apply policies and collect analytics in a virtual environment.
At the moment, the implementation of P + V Fabric is possible only in the architecture of OpenStack / KVM, since it is open. For other hypervisors, P Fabric is available. However, the ability to integrate with VMware vCenter / vSphere (about which below) fully compensates for these inconveniences.
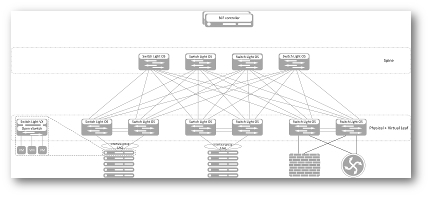
Structural scheme of the Big Cloud Fabric (clickable image)
It should be noted again that, unlike similar products from other manufacturers, the controller is an element that fully controls the switches of the factory, makes calculations of the topology, neighborhood relations of the routing protocols with external devices and synchronizes the state of the hardware tables. This is not a management system that only collects configuration data and adjusts switches based on them. This is not a monitoring system that periodically (or on request) polls devices and collects only the information that they can provide using standard protocols. This is a real factory control plane - the controller has a complete picture of the network, since it creates it. Through the OS on the switches, it has access directly to the ASIC, and that is why the reaction rate of BCF is higher, and the analyst is much more detailed than of competing products.
In connection with such a significant controller role in the infrastructure of the factory, a reasonable question arises: what happens if all the cluster members fail and the factory is left without a Control Plane? As it turns out, nothing terrible will happen. Left without a controller (headless mode), the factory will continue to work as usual and will correctly handle the traffic of already studied hosts, and even some types of failures (for example, link failure within one rack (MC-LAG pair)). Of course, this mode imposes restrictions on new settings, the study of newly connected hosts and changes in the factory topology - that is, they will not be processed. This may seem a disadvantage to some, but let's imagine what happens if all supervisors in a modular switch fail? Most likely it will just stop.
Source: https://habr.com/ru/post/307544/
All Articles