Cat-and-mouse game: how anti-spam was created in Mail.Ru Mail and what does Tarantool have to do with it

Hi, Habr! In this article I want to talk about the anti-spam system in Mail.Ru Mail and the experience of working with Tarantool in this project: what tasks we use this DBMS, what difficulties and peculiarities of its integration we encountered, what rakes we attacked, how we bumped cones and eventually learned zen.
First a brief antispam story. Anti-spam Mail began to be introduced more than ten years ago. The first solution used for filtering was Kaspersky Anti-Spam paired with RBL ( Real-time blackhole list - a real -time list containing IP addresses somehow related to spamming). As a result, the number of unwanted emails has decreased, but due to the nature of the system (inertia), this approach did not satisfy the requirements: to suppress spamming messages quickly (in real time). An important condition was the speed of the system - the user should receive verified emails with minimal delay. The integrated solution did not have time for spammers. Spam mailers very dynamically change (modify) the content and model of their behavior when they see that their letters are not delivered to the addressee, so we could not tolerate inertia. And they began to develop their own spam filtering system.
The next stage in Mail.Ru Mail appeared MRASD - Mail.Ru Anti-Spam Daemon. In fact, it was a very simple system. The letter from the client was sent to the Exim mail server, primary filtering was performed using RBL, after which it was sent to MRASD, where all the “magic” was performed. The anti-spam daemon disassembled messages into parts: headers, the body of the letter. Next, the simplest text normalizations were carried out over each of them: reduction to one register, similar in writing characters to a certain type (for example, the Russian letter o and the English letter o turned into one character), etc. After the normalization was performed, the following were extracted called entities, or signatures of a letter. By analyzing various parts of email messages, spam filtering services block based on any content. For example, you can create a signature for the word "Viagra" , and all messages that contain this word will be blocked. Other examples of entities are URLs, images, attachments. Also during the verification of a letter its unique feature (fingerprint) is formed - with the help of a certain algorithm, a set of hash functions for writing is calculated. For each hash and entity, statistics (counters) were kept: how many times they met, how many times they complained about it, the entity flag is SPAM / HAM (ham in antispam terminology is the opposite of the spam term, meaning that the email being checked does not contain spam content). Based on these statistics, a decision was made when filtering letters: when the hash or entity reaches a certain frequency, the server can block a specific mailing.
')
The core of the system was written in C ++, and a significant part of the business logic is carried away in the interpreted language Lua. As I mentioned above, spammers are dynamic people and quickly change their behavior. Each change needs to be able to react immediately, which is why it was decided to use an interpreted language to store business logic (no need to recompile the system each time and put it into servers). Another requirement for the system was speed - Lua has a good indicator of speed, and on top of that, it easily integrates into C ++.
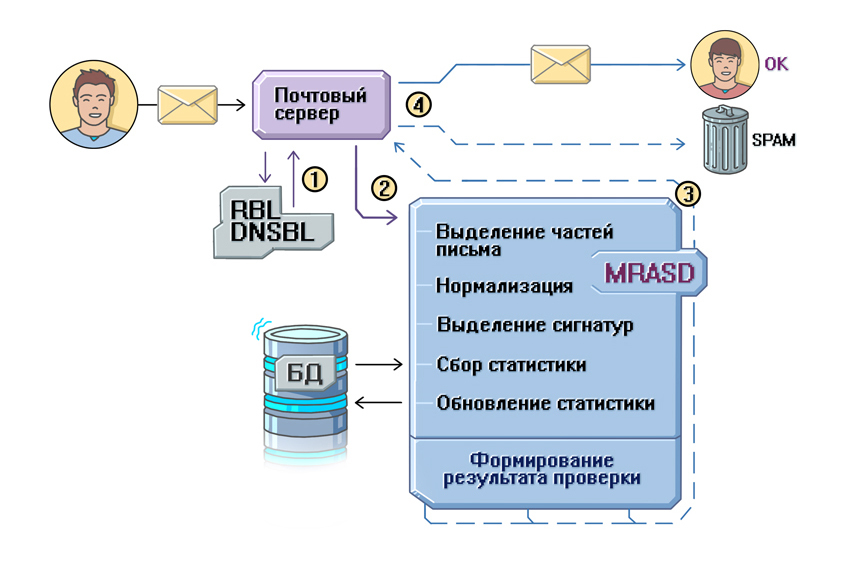
The figure above illustrates a simplified scheme for sending a letter: from the sender it goes to the server, passes the initial checks (1), if successful, it is sent to the MRASD check (2). MRASD returns the result of the check to the server (3), and based on it, the letter is either placed in the Spam folder or sent to the user in the inbox.
The introduction of MRASD reduced the number of spam messages delivered to the user tenfold. Time passed, the system improved, new subsystems, components appeared, new technological tools were introduced. The system expanded and became more complex, the tasks solved by the anti-spam team also became more and more diverse . The changes could not but affect the technological stack, which I will tell you about.
Evolution of the technology stack
At the beginning of the development of postal services, the flow of letters, and indeed their content was much more scarce than at the moment, but the choice of tools and computational abilities were, to put it mildly, different. From the above described “parent” model of MRASD it is clear that for the functioning of the system it was necessary to save various statistical information. At the same time, the percentage of “hot” (that is, frequently used) data was high, which undoubtedly imposed certain requirements on the data warehouse. As a result, MySQL chose the storage of “cold” (rarely updated) data. There was a question: what solution to choose to store hot
As time passed, the load on the mail, and as a result - on the antispam grew. There were new services, it was required to store more and more data (Hadoop, Hypertable). By the way, at the moment, at peak, the number of processed letters per minute reaches 550 thousand (if this figure is averaged over the day, then an average of 350 thousand messages are checked per minute), the volume of logs analyzed is more than 10 TB per day. But back to the past: in spite of growing loads, the requirement for fast data handling (loading, saving) remained relevant. And at some point, Kyoto stopped coping with the volumes we needed. In addition, we wanted to have a more functionally rich tool for storing important hot data. In short, it was necessary to begin to turn our heads to find worthy alternatives that would be flexible and easy to use, productive and fault tolerant. At that time, our company was gaining popularity with NoSQL DB Tarantool, which was developed in its native walls and responded to the Wishlist we set. By the way, recently, while doing the revision of our services, I felt like an archaeologist: I came across one of the earliest versions - Tarantool / Silverbox . We decided to try this database because the stated benchmarks and covered our volumes (there are no exact load data for this period), and also the storage satisfied our requests for fault tolerance. An important factor is that the project was “at hand”, and it was possible to quickly throw up their tasks with the help of JIRA. We were among the newcomers who decided to test in their Tarantool project, and I think that the successful experience of the pioneers also pushed us towards such a choice.
Then began our "era of the Tarantula." It was actively implemented and is still being introduced into the antispam architecture. Currently we can find queues implemented on the basis of Tarantool, high-load services for storing all sorts of statistics: user reputation (user reputation), IP sender reputation (IP reputation), user trust statistics (karma), etc. Work is underway to integrate a modernized storage system and work with entity statistics. Anticipating questions about why we in our project are fixated on one solution and do not switch to other repositories, I would say that this is not quite so. We study and analyze competing systems, but at the moment Tarantool is successfully coping with the tasks and workload assigned to it within our project. The introduction of a new (unfamiliar, not previously used) system is always fraught with complications, requires a lot of time and resources. Tarantool is in our (and not only) project well studied. Programmers and system administrators have already eaten a dog on it and know the subtleties of work and system settings to make it as efficient as possible. The advantage is also that the development team is constantly improving its product and provides support (and also sits close, which is also very convenient :)). So, when introducing a new solution based on data storage in Tarantool, I very quickly received from the guys answers to my questions and necessary help (I’ll tell you about this later).
Then I will conduct a brief overview of several systems based on this DBMS, and share those features that I had to face.
A brief excursion into systems using Tarantool
Karma is a numerical characteristic that reflects the degree of trust in the user. It was conceived primarily as the basis of a common “carrot and stick” system for a user, built without resorting to complex dependent systems. Karma acts as an aggregator of data received from other reputation systems. The idea of the system is simple: each user has his own karma - the higher it is, the more we trust the user, the lower, the more rigidly we make decisions when checking letters. So, if the sender sends a letter with suspicious content and has a high rating, the letter will be delivered to the recipient. Low karma is taken into account when deciding whether a letter is spam as a pessimizing factor. This system reminds me of a school magazine in the exam. An excellent student will be asked two or three additional questions and released on vacation, while the bad student will have to sweat to get a positive assessment.
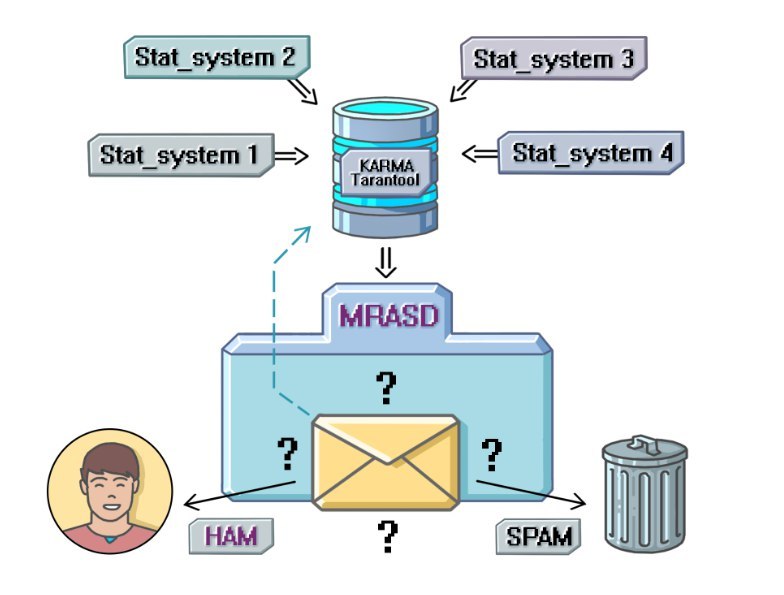
Tarantool, which stores data related to karma, runs on the same machine. Below is a graph of the number of requests executed on a single karma instance per minute.
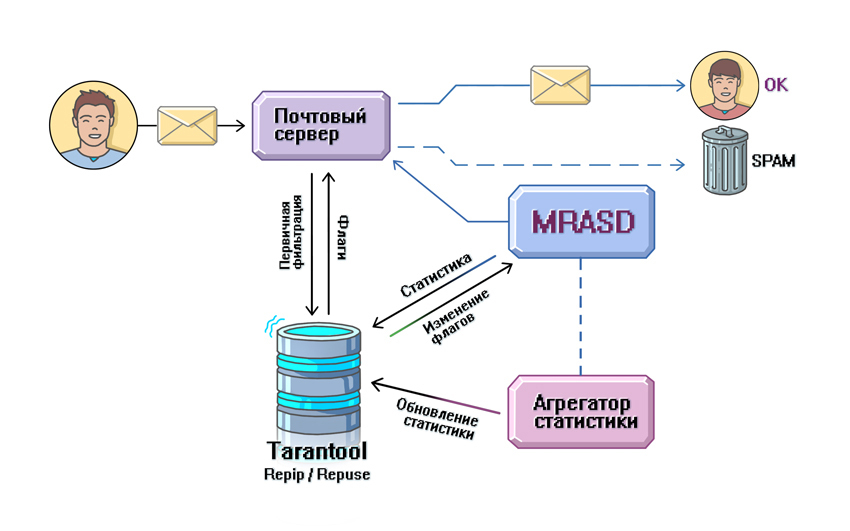
RepIP / RepUser
RepIP and RepUser (reputation IP and reputation user) is a high-load service designed to record statistics on the activity and actions of senders (users) with a specific IP, as well as a user when working with mail for a specific time interval. Using this system, we can tell how many letters the user sent, how many of them were read, and how many were marked as spam. The peculiarity of the system is that in the analysis of behavior we see not an instantaneous (snapshot) of activity, but expanded in the time interval. Why is it important? Imagine that you moved to another country where there is no means of communication, and your friends stayed in their homeland. And now, after a few years, the Internet is being pulled into your hut. You get into a social network and see a photo of your friend - he has changed a lot. How much information can you extract from a snapshot? I think not so much. Now imagine if you were shown a video in which you can see how your friend is changing, getting married, and so on. This is a sort of video biography. I think in the second case you will get a much more complete picture of his life. Similarly with data analysis: the more information we have, the more accurately we can evaluate user behavior. You can see the pattern in the intensity of mailing, understand the "habits" of mailers. Based on such statistics, each user and IP-address is given a measure of confidence in him, and a special flag is set. It is this flag that is used during the initial filtering, which eliminates up to 70% of unwanted messages by the time a letter arrives at the server. This figure shows how important the service is, therefore it requires maximum performance and fault tolerance. And for storing such statistics, we also use Tarantool.
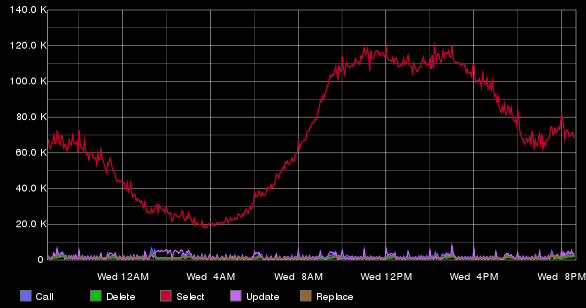
Statistics are stored on two servers with four Tarantool instances on each. Below is a graph with the number of executed requests for RepIP, averaged over one minute.
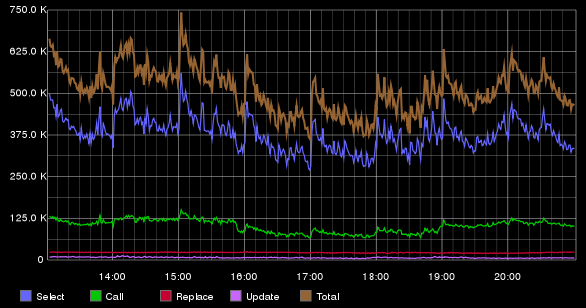
When implementing this service, we had to face a number of tasks that were associated with setting up Tarantool. This system differs from the previously described systems in that the packet size with statistics stored in RepIP / RepUser is much larger: the average packet size is 471.97 bytes (the maximum packet size is 16 KB). A package can be divided into two logical components: a small “basic” part of the package (flags, aggregated statistics) and a large statistical part (detailed statistics on actions). Working with the whole package leads to the fact that the network utilization increases and the load time from saving the record is higher. A series of systems need only the basic part of the package, but how to pull it out of the tackle (tuple - this is the name for the Tarantool entry)? Stored procedures come to the rescue. To do this, you need to add the necessary function to the init.lua file and call it from the client (starting from version 1.6, you can write stored procedures in C).
function get_first_five_fields_from_tuple(space, index, key) local tuple = box.select(space, index, key) -- — if tuple == nil then return end -- tuple local response = {} for i = 0, 4 do -- , 1 table.insert(response, tuple[i]) end return response end Version issues up to 1.5.20
Not without adventure. After the planned restart of Tarantool, the clients (there were 500+ of them) started knocking on the server and could not connect (they fell off due to a timeout). It should be noted that the progressive time-outs did not help either - in the case of an unsuccessful connection attempt, the time of the next attempt is postponed by some increasing value. The problem was that Tarantool did accept one connection for one event-loop event (although hundreds were crammed into it). The problem can be solved in two ways: by installing a new version 1.5.20 or higher or by setting the configuration file (io_collect_interval should be turned off, and then everything will be fine). The development team fixed this problem as soon as possible. In version 1.6, it is missing.
RepEntity - entity reputation
At the moment, a new component is being integrated to store statistics for entities (URL, image, attach etc.) - RepEntity . The idea of RepEntity is similar to the RepIP / RepUser described earlier - it also allows you to have detailed information about the behavior of entities on the basis of which a decision is made when spam is filtered. Thanks to RepEntity statistics, we can catch spam mailings, focusing on the essence of the letter. For example, if the mailing includes a “bad” URL (containing spam content, a link to a phishing site, etc.), we can quickly notice and suppress the mailing of such emails. Why? Because we see the dynamics of the distribution of this URL and can detect changes in its behavior, in contrast to the "flat" counters.
The main difference (feature) of RepEntity from the IP reputation system, in addition to the modified packet format, is a significant increase in the load on the service (the volume of processed and stored data and the number of requests increase). For example, a letter can contain up to hundreds of entities (while there are no more than ten IP addresses), most of which need to download and save a complete package with statistics. I note that a special aggregator is responsible for saving the package, which previously accumulates statistics. Thus, within the framework of this task, the load on the DBMS significantly increases, which requires careful work in the design and implementation of the system. I would like to especially note that the implementation of this component uses Tarantool version 1.5 (this is caused by the project’s features), and then we will talk about this version.
The first thing that was done was an estimate of the required amount of memory to store all of these statistics. Figures may say about the importance of this item: on the expected load, an increase in the packet size by one byte leads to an increase in the total stored information by one gigabyte. Thus, we were faced with the task of storing the data as compactly as possible in a tuple (as I mentioned above, we cannot store the entire package in one cell of the tapl, since there are requests to extract part of the data from the package). When calculating the amount of stored data in Tarantool, remember that there is:
- index storage costs;
- the cost of storing the size of the stored data in the cell of the tapl (1 byte);
- The size limit is 1 MB ( in version 1.6 ).
A large number of various requests (reads, inserts, deletions) led to the fact that Tarantool began to time out. As it turned out in the course of the study, the reason was that with frequent insertion and removal of packages, complex rebalancing of the tree was caused (the tree-like key - TREE) was used as all indexes. In this database, some kind of sly, self-balancing tree. In this case, balancing does not occur immediately, but when a certain “imbalance” condition is reached. Thus, when the tree was “quite unbalanced,” the balancing was started, which slowed down the work. In the logs, you could see messages like Resource temporarily temporarily unavailable (errno: 11) , which disappeared after a few seconds. But during these errors the client could not get the data of interest. Colleagues from Tarantool suggested a solution: use a different type of “wooden” key - AVLTREE, which, with each insertion / deletion / change, produces rebalancing. Yes, the number of rebalances has increased, but their total cost is lower. After the new scheme was filled and the DB was restarted, the error no longer manifested itself.
Another difficulty we faced was the cleaning of obsolete entries. Unfortunately, in Tarantool (as far as I know, in version 1.6 as well) it will not be possible to set the TTL (time to live) for the specified entry and forget about its existence, shifting the concerns about its deletion to the data storage. But at the same time, it is possible to write the scrubbing process yourself on Lua based on box.fiber . On the other hand, such an approach gives greater freedom of action: you can write complex removal conditions (not only in time). But to write the cleaning process correctly, you also need to know and consider some subtleties. The first displacing process (cleaning fiber), which I wrote, fiercely slowed down the system. The fact is that the amount of data that we can delete is significantly less than the total number of records. In order to reduce the number of entries - candidates for deletion, I entered the secondary index on the field of interest to me. After that, he wrote a fayber that went around all the candidates (for which the change time is less than the specified one), checked additional conditions for deletion (for example, that the record flag was not set) and, if both conditions were met, deleted the record. When I tested without load, everything worked fine. With a low load, too, everything went like clockwork. But as soon as I approached half of the expected load - there were problems. I started to time out requests. I realized that somewhere made a blunder. He began to understand and realized that my idea of how fayber works was wrong. In my world, fayber was a separate thread, which in no way (except for context switching) should have influenced the reception and processing of requests from clients. But later I found out that fayber uses the same event-loop as the request processing thread. Thus, iterating in a loop over a large number of records, without a delete operation, I simply “blocked” the event-loop, and requests from users were not processed. Why did I mention the delete operation? Because every time delete was executed, a yield occurred — an operation that “unlocks” the event-loop and allows the next event to be processed. From here I concluded that if n operations (where n is to be looked for empirically - I took 100) were performed without yield, it is necessary to do forced yield (for example, wrap.sleep (0)). Also note that when deleting a record, the index can be rebuilt and, iterating over the records, you can skip part of the data for deletion. Therefore, there is another option for removal. You can select a small number of elements (up to 1000) in a loop and iterate over this 1000 elements, removing unnecessary and remembering the last one unreleased. And after that, at the next iteration, select the next 1000, starting with the last one that was not deleted.
local index = 0 -- , local start_scan_key = nil -- , local select_range = 1000 -- , select_range local total_processd = 0 -- (tuple) local space = 0 -- local yield_threshold = 100 -- , yield local total_records = box.space[space]:len() -- while total_processed < total_records do local no_yield = 0 local tuples = { box.space[space]:select_range(index, select_range, start_scan_key) } for _, tuple in ipairs(tuples) do -- tuples local key = box.unpack('i', tuple[key_index_in_tuple]) if delete_condition then box.delete(space, key) -- delete yield no_yield = 0 else no_yield = no_yield + 1 if no_yield > yield_threshold then box.fiber.sleep(0) -- yield end start_scan_key = key -- end total_processed = total_processed + 1 done Also within the framework of this work there was an attempt to introduce a solution that would help to produce resharding painlessly in the future, but the experience was unsuccessful, the implemented mechanism carried a big overhead, and as a result, it was rejected from the resharing technique. We are waiting for the appearance of resarding in the new version of Tarantool.
Best practice:
You can achieve even more performance if you disable xlog'i. But it is worth considering that from this moment on Tarantool will act as a cache, with all the ensuing consequences (I’m talking about the lack of replication and data warming up after restarting). Do not forget that it is possible to periodically snapshot and, if necessary, restore data from it.
If several Tarantool are running on the same machine, then to increase performance, it is worth “nailing” each of them to the cores. For example, if you have 12 physical cores, then you should not raise 12 instances (you need to remember that each Tarantool, in addition to the performing thread, there is also a VAL thread).
What is missing:
- Sharding
- Cluster approach with the ability to dynamically configure the cluster, for example in the case of adding nodes or node failure, similar to MongoDB (mongos), Redis (redis sentinel).
- Possibilities of TTL task (time to live) for recordings.
Summing up
Tarantool plays an important role in the anti-spam system, it is tied with many key high-load services. Ready-made connectors make it easy to use it in different components written in different languages. Tarantool has proven itself well: during the use of the database, the project did not have any serious problems related to its operation and stability in solving its tasks. Let me remind you that there are a number of subtleties that need to be taken into account when setting up a database (especially for version 1.5) in order to work effectively.
A little about future plans:
- Increasing the number of services in a project working with Tarantool.
- Migration to Tarantool 1.6.
- We also plan to use Sophia , including for the repentity task, since the amount of really hot data is not so large.
PS By the way, in our office on August 25, the third Tarantool meetup will take place, if you want to learn more about our database and personally communicate with the developers, register and come!
Source: https://habr.com/ru/post/307424/
All Articles