Machine Learning for Tennis Prediction: Part 2
In the first part of the review, I reviewed the basic terms and concepts in tennis betting and made an overview of statistical models for predicting tennis matches.
The second part is devoted to machine learning itself: algorithms, problems and cases.

')
Content
Part 2
Machine learning in tennis
Machine learning models
Machine learning problems
Cases MO to predict tennis
Machine learning is the section of artificial intelligence that studies algorithms that can learn or adapt their structure based on a processed data sample. Machine learning with a teacher solves the problem of constructing a function from a set of labeled learning examples, where the labeled example is a pair consisting of an input vector and the desired output value.
In the context of tennis, historical match statistics can be used to select a sample of training examples. For a single match, the input vector may contain various match and player attributes, and the output value will be the outcome of the match. The selection of relevant features is one of the main problems in constructing an effective machine learning algorithm.
From the point of view of existing algorithms, prediction of tennis can be considered from two sides:
Despite its name, logistic regression is essentially a classification algorithm. The main features of the algorithm are the logistic function properties. The logistic function σ (t) is defined as:
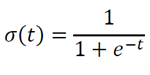
As can be seen in the figure below, the logistic function displays real input values in the range from –∞ to + ∞ and from 0 to 1, allowing you to interpret outputs as probabilities.
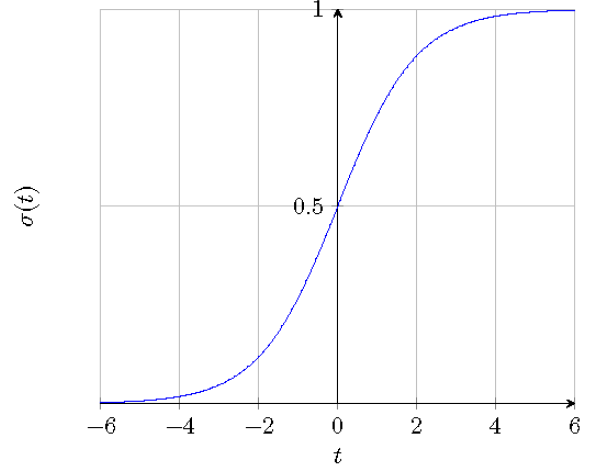
Logistic function σ (t)
The logistic regression model for match prediction consists of the vector n of match signs x = (x 1 , x 2 , ..., x n ) and the vector n + 1 real parameters of the model β = (β 0 , β 1 , ..., β n ) . To predict using the model, we first project the point in our n -dimensional feature space onto the real number:

You can now convert z to a value in an acceptable range of probabilities (from 0 to 1) using the logistic function defined above:

Model training consists of optimization of the parameters β , so that the model gives the best reproduction of the outcomes of matches for the training sample. This is done by minimizing the logistic loss function (equation below), which gives a measure of the model’s error in predicting the outcomes of the matches used for training.

where N is the number of matches in the sample
p i - the probability of predicting victory for match i
y i - real match outcome i (0 - defeat, 1 - win)
The figure below shows the logistic losses arising from one match for different predicted probabilities, provided that the match ended in victory for the predicted player. Any deviation from the most accurate prediction p = 1.0 is penalized.

Logistic losses with correct match prediction
Depending on the size of the sample, one of two training methods is chosen (ie, minimizing logistic losses):
1. Stochastic gradient decay - slow iterative method, suitable for large samples;
2. Maximum likelihood - faster numerical approximation, not suitable for large samples.
Most published machine learning models use logistic regression. Clarke and Dyte [8] apply a logistic regression model to the points difference between the two players in the ATP rating to predict the outcome of the set. In other words, they use the one-dimensional feature space x = (rankdiff) and optimize β 1 so that the function σ (β 1 * rankdiff) gives the best prediction for the training sample. Parameter β 0 is omitted in the model, since rankdiff 0 will give the probability of winning the match 0.5. Instead of directly predicting the outcome of the match, Clark and Data predict the probability of winning the set and simulate the probability of winning the match, thus increasing the sample size. The model was used to predict the results of several men's tournaments in 1998 and 1999, but the authors do not provide data on the prediction accuracy, mentioning only that the results are satisfactory.
Ma, Liu and Tan [9] used a larger feature space of 16 variables belonging to three categories: player skills and performance, player's physical parameters, match parameters. The model was trained at matches from 1991 to 2008. and was used to make recommendations to the players: for example, “to train receiving delivery more”.
Logistic regression is an attractive algorithm for predicting tennis because of the speed of training, resistance to retraining and the output of the probability of winning the match. However, without additional modifications, this algorithm cannot model the complex relationship between the input features.
An artificial neural network is a system of interconnected neurons, created according to the model of biological neurons. Each neuron calculates a value from the input signals, which can then be transmitted to the input to other neurons.
A forward propagation neural network (i.e., a network with an event prediction mechanism, feed-forward network) is a directed acyclic graph. As a rule, neural networks have several layers, with each neuron in the non-input layer associated with all neurons in the previous layer. The figure below shows a three-layer neural network.

Three-layer neural network of direct distribution
Each connection in the network are assigned weights. The neuron uses the input signal and its weight to calculate the output value. A typical network layout method is a non-linear weighted sum:

where w i is the input data weight x i .
The nonlinear K activation function allows the network to calculate non-trivial tasks using a small number of neurons. Usually, sigmoidal functions are used for this purpose, for example, the logistic function defined above.
Tennis matches can be predicted by giving the player and match signs to the input neuron layer and passing values through the network. If you use the logistic activation function, the value at the exit of the network may represent the probability of winning the match. There are many different learning algorithms, the purpose of which is to optimize the weights of the network to obtain the best output values for the training sample. For example, the back-propagation algorithm uses a gradient descent to reduce the mean square error between target values and values at the output of a neural network.
Neural networks can find connections between various features of a match, but by their nature they still remain a “black box,” that is, a trained network does not provide an additional understanding of the system, since it is too difficult to interpret. Neural networks are prone to retraining and therefore a lot of data is needed for their training. In addition, the development of a neural network model requires an empirical approach, and the selection of model hyperparameters is often carried out by trial and error. However, given the success of neural network models for predicting tennis, this approach must be considered promising.
Somboonphokkaphan [10] trained a three-layer neural network to predict tennis matches using a back-propagation algorithm. The author investigated and compared several different networks with different sets of input parameters. The best neural network consists of 27 input nodes representing such match and player attributes as the court surface, the winning percentage on the first serve, the second serve, the return serve, break points, etc. The author claims about 75% accuracy when predicting the outcome of matches of Grand Slam tournaments in 2007 and 2008.
Sipko [11] uses logistic regression and neural networks, testing models on a sample of 6135 matches of ATP tournaments 2013-2014, the ROI of the most accurate model was 4.35%, which according to the author is 75% better than modern stochastic models.
After the publication of the first part of the article, SpanishBoy found the implementation of the Sipko models on GitHub : their result was 65%, but the ROI was negative.
Support vector machines (SVM), like the other machine learning algorithms described here, are a learning algorithm with a teacher. It was proposed by Vladimir Vapnik and Alexey Chervonenkis in 1963 and is one of the most popular modern teaching methods for precedents.
The task solved by SVM is to find the optimal hyperplane that correctly classifies points (examples) by dividing the points of the two classes into categories that are their labels (as in other algorithms, these categories can be “victory” and “defeat”). A new example, for example, the upcoming match, can then be projected into the same space of points and classified on the basis of which side of the hyperplane it comes from.
SVM has a number of advantages over neural networks: first, learning never leads to a local minimum, which often happens with neural networks. Secondly, SVM often outstrips neural networks in prediction accuracy, especially when there is a high ratio of features to training examples. However, much more time is spent on SVM training, and models are hard to customize.
Graduates of MIT Wagner and Narayanan [12] published a term paper where they used SVM to predict the winners in the interactive game ATP World Tour Draw Challenge, which was held by the Association of Tennis Professionals until 2014. tried to predict the tournament table winners in all upcoming matches until the winner of the tournament. The authors used 15 signs, mainly visitor statistics of players. The training sample was 40000 examples, for testing the model used cross-validation on 6000 examples. The maximum accuracy of the model was 65%.
The work of Panjan et al. [13] does not directly concern the prediction of match outcomes. They used SVM, along with other classification algorithms, to predict the success of young Slovenian tennis players in comparison with their peers and senior tennis players.
Support vector machines undoubtedly deserve closer attention as models for predicting tennis. It is important to note that SVM requires stepwise calibration to produce good probabilities, while such a step is not necessary for logistic regression and neural networks. In addition, Bayesian networks that simulate the interdependence between different variables can be used to predict tennis matches.
Each model has a different efficiency in different conditions. Machine learning can also be used to build a hybrid model that combines output from other models. So, forecasts of different models can become separate signs, and the model can be trained to analyze the strengths and weaknesses of each of them. For example, a neural network prediction can be combined with a common rival model, using match parameters to weightedly evaluate the relative impact of two predictions.
As already mentioned, a lot of historical data is available for teaching the described models. However, it is important to note that the game of tennis players in the upcoming match should be evaluated on the basis of their past matches: only recent matches on the same court coverage with similar opponents can accurately reflect the player’s expected result. It is clear that such data is extremely small for modeling, and this may lead to retraining of the model. This means that the model will describe a random error or noise in the data instead of the relevant pattern. Neural networks are especially susceptible to retraining, primarily when the number of hidden layers / neurons is too large compared to the number of examples.
To avoid retraining, only the most relevant signs of a match need to be selected. Separate algorithms also exist for the feature selection process itself. Eliminating irrelevant features will also reduce learning time.
Model training optimizes model parameters, such as weights in a neural network. However, in the model, as a rule, there are hyperparameters that are not taught and which need to be configured manually. For example, for neural networks, one of the configurable hyperparameters is the number of hidden layers and the number of neurons in each layer. Obtaining optimal hyperparameters for each model is an empirical process. The traditional algorithmic approach — grid search — implies an exhaustive search over a predetermined feature space. For these reasons, a successful model for predicting tennis requires careful selection of hyperparameters.
Tennis expert Peter Webb claims that more than 80% of all tennis bets are placed directly during a match. Stochastic models can predict the probability of the outcome of a match from any initial account, which means that they can be used for live bets. Machine learning models are usually not rebuilt during the current match. And although the current score could be used as a sign of a match, the resource intensity of such a model would increase significantly, and the impact on accuracy or ROI could be minimal.
Often, studies only cover ATP men's matches, and the games of the Women's Tennis Association (WTA) are not counted. This is partly due to better availability of historical data and coefficients for ATP players, partly because additional features may be relevant for women, which will require re-checking and re-calibration of the model. In any case, the prediction of women's tennis with all its features is a direct field of activity for machine learning, and perhaps we will see such research in the future.
Research interest in prognostic models for tennis has led to the emergence of services that offer users the results of such predictions. It is important to note that due to the specifics of the sports betting market, a great number of forecasters (cappers, tipsters, etc.) are active on the Internet of varying degrees of decency, claiming that they give forecasts based on their own algorithms. For obvious reasons, in most cases they turn out to be fraudsters, which is easy to track by the number of details and the correctness of the technical information that they disclose (or do not disclose).
After screening people, forecasters, there are only a few resources that appear to use real mathematical models. Despite the fact that they, as a rule, do not reveal the algorithms and methods used, they can be traced by indirect signs.
One group of services provides the probabilities of winning both players in a match, leaving match statistics and player history for independent user analysis. Thus, they use prediction results based on stochastic hierarchical methods. Most of these resources: toptennistips.com, robobet.info, etc.
Services based on machine learning analyze not only the probabilities of winning, but also apply self-learning algorithms to historical statistics on players and match parameters. Such systems have created IBM, Microsoft and the Russian service OhMyBet!

The IBM Keys to the Match system for predicting tennis has been promoted by the company since 2013 as a predictive analytical tool for four Grand Slam tournaments: Wimbledon and the Australian Open, France and the United States. For each player, the system analyzes its unique playing style and gives recommendations on three key indicators (keys) that a tennis player must achieve in order to increase their chances of winning in the current match. "Keys" is published on the official sites of tournaments.
The system takes statistics from Grand Slam tournaments since 2005, which is almost 12,000 matches. IBM has been an official partner of Grand Slam tournaments for many years: the company collects and processes all the statistics of these matches. IBM claims that for each match, Keys to the Match analyzes up to 41 million data points, including points, score, duration, feed rate, percentage of innings, number of hits, types of hits, etc.
Based on the analysis, the system determines 45 key dynamic indicators of the game and identifies three of them that are most important for each player in this match: 19 keys for attack, 9 for defense, 9 for endurance, and 8 keys describing the overall style of play. During the tournament, the system creates a total of 5500 predictive models.
To select three key features, the system also analyzes the difference in player statistics for each of the four Grand Slam tournaments, the history of personal encounters of opponents, and the history of games with similar opponents. A profile with all relevant statistics is created for each player, after which the clustering algorithm separates the players according to the degree of similarity of profiles and playing style.
IBM does not disclose exactly which predictive algorithms are used in the system. Moreover, despite the phrase “predictive analytics” that is constantly found in Keys to the Match marketing materials, IBM spokesman Kenneth Jensen stresses : “The system is not designed to predict the winner of a match or set. The goal of Keys to the Match is to identify three player performance indicators and track the current game of a tennis player in comparison with his previous results and those of comparable players. ”
The artificial intelligence system Cortana Intelligence Suite from Microsoft has not yet been used to predict tennis, but it is being actively tested on predicting football matches, so the story about it is included in this review (you can read more here ).
Cortana was first tried to predict sports in 2014, when she predicted the results of World Cup matches. Then 15 of 16 predictions of game outcomes turned out to be correct. After that, Microsoft made predictions for the Women's World Cup, the English Premier League, the UEFA Champions League, the Brazilian Championship, the French Championship, the Spanish Championship, the German Championship, and the Italian Championship.
To predict results, the system uses a comprehensive analysis of two factors: statistics (the ratio of victories and defeats of the team, the number of goals scored, the location of the match, weather conditions) and data of web search and social networks (the phenomenon of "collective intelligence"). The chance of winning each team is determined as a percentage, the probability of a draw in the matches for each game of the qualifying round is calculated.
In general, the phenomenon of "collective knowledge" is underestimated, according to Microsoft. The results of the events, which, it would seem, cannot influence public opinion (football championships are just this case), in fact, can be predicted by analyzing the behavior of people on the Internet. So Cortana Intelligence Suite predicts the results of TV shows, elections, awards ceremonies and a variety of competitions based on voting. The system reveals exactly which public actions of users correlate with the distribution of votes. Predictive algorithms are compiled on these correlations. It is proved that in cases where individual experts may be wrong, public opinion analysis adds 5% to the accuracy of the forecast.
However, a football match is not a vote, but its structure is more complicated than tennis, and the results of Cortana’s predictions are still far from ideal. So, for Euro 2016, the system predicted that with a probability of 66% the champion would be Germany, and in the match with England on June 11, Russia will not score a single goal, perform less than four attacks, and the number of successful passes will not exceed 221.
The result is known to us.
Service OhMyBet! created by graduates of the Physics and Technology Institute and Moscow State University. In early July, a note on the service appeared on vc.ru , where the creators briefly described the system. The study of predictive algorithms in graduation and dissertation projects led the authors to work out their models at tennis matches.
From the data on 825,000 matches played in ITF and ATF tournaments from 2000 to 2014, we identified such signs as match result, coverage, tournament, number of aces, number of double faults, winning percentage on the first and second serve, average serving speed of each player, age of players , estimated winning motivation, previous player meetings, injuries, rest time between matches, etc. The machine learning algorithms were applied to this data.
The model was validated at the 2015 matches. Result: 12% ROI for 2015, while the accuracy of the system was 75-77%. The maximum accuracy in 2015 is 85%, however, the ROI decreases.
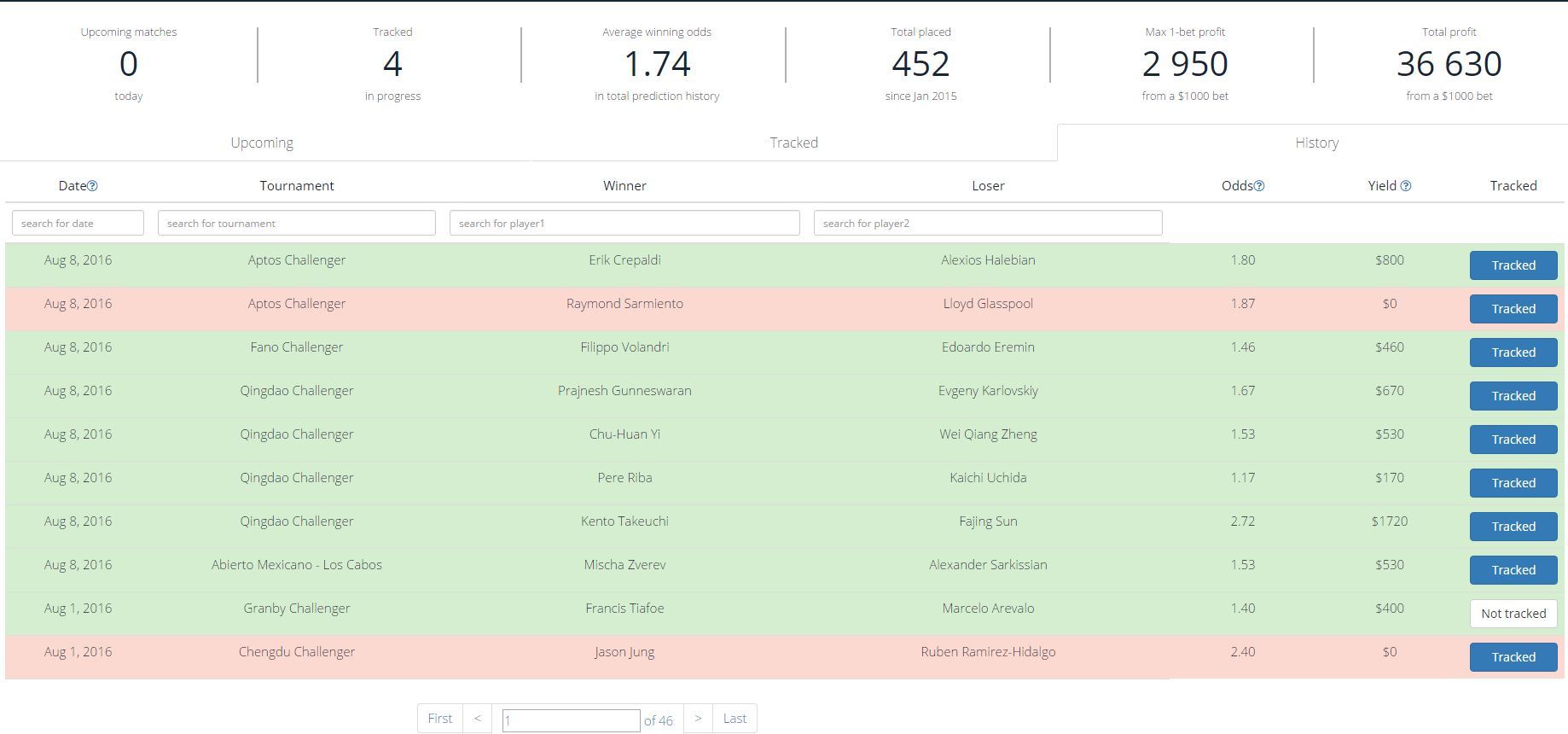
High ROI is provided due to the fact that the algorithm itself cuts forecasts with low coefficients. The average winning coefficient is 1.74. In total from the beginning of 2015 to the present, the algorithm gave 452 forecasts, 350 for 2015.
The creators do not disclose the algorithm used in the system, however, from the analysis of published works and observation of the behavior of the system itself, it can be assumed that this is a neural network. For example, the creators said that when setting up the model, they faced retraining and were forced to adjust the training signs.
The last major update of the algorithm was conducted in early July 2016, after which full access to the site was opened for users. The forecast statistics from the beginning of 2015 to the current match is available on the website in the History section. From the moment of launch, the authors conduct open monitoring of forecasts on the Blogabet platform in order to avoid allegations of fraud on statistics.
8. SR Clarke and D. Dyte. Using official ratings to simulate major tennis tournaments. International Transactions in Operational Research, 7 (6): 585–594, 2000.
9. S. Ma, C. Liu, and Y. Tan. An analysis of the player of the world of science and sports statistics. Journal of sports sciences, 31 (11): 1147–55, 2013.
10. A. Somboonphokkaphan, S. Phimoltares, and C. Lursinsap. Tennis Winner Prediction based on Time-Series History with Neural Modeling. IMECS 2009: International Multi-Conference of Engineers and Computer Scientists, Vols I and II, I:127–132, 2009.
11. M. Sipko. Machine Learning for the Prediction of Professional Tennis Matches. Technical report, Imperial College London, London, 2015.
12. A. Wagner, D. Narayanan. Using Machine Learning to predict tennis match outcomes. MIT 6.867 Final Project.
13. A. Panjan et al.: Prediction of the successfulness of tennis players with machine learning methods. Kinesiology 42(2010) 1:98-106
The second part is devoted to machine learning itself: algorithms, problems and cases.
')
Content
Part 2
Machine learning in tennis
Machine learning models
Machine learning problems
Cases MO to predict tennis
Machine learning in tennis
Machine learning is the section of artificial intelligence that studies algorithms that can learn or adapt their structure based on a processed data sample. Machine learning with a teacher solves the problem of constructing a function from a set of labeled learning examples, where the labeled example is a pair consisting of an input vector and the desired output value.
In the context of tennis, historical match statistics can be used to select a sample of training examples. For a single match, the input vector may contain various match and player attributes, and the output value will be the outcome of the match. The selection of relevant features is one of the main problems in constructing an effective machine learning algorithm.
From the point of view of existing algorithms, prediction of tennis can be considered from two sides:
- As a regression problem, in which the output value is a real value. The exit may represent the probability of winning the match directly, however, the true probabilities of winning the previous matches are unknown, which forces us to use discrete values for the marks of the training examples (for example, 1 for victory, 0 for defeat). Otherwise, it is possible to predict the probabilities of scoring when submitting and insert them into the hierarchical expressions of Barnet and O'Miley to find the probability of winning the match, but this returns us to Markov chains.
- As a task of a binary classification , in which you can try to classify matches into categories of "victory" or "defeat." Some classification algorithms also give a certain degree of accuracy of an event belonging to a class, which can be used as the probability of winning a match.
Machine learning models
Logistic regression
Despite its name, logistic regression is essentially a classification algorithm. The main features of the algorithm are the logistic function properties. The logistic function σ (t) is defined as:
As can be seen in the figure below, the logistic function displays real input values in the range from –∞ to + ∞ and from 0 to 1, allowing you to interpret outputs as probabilities.
Logistic function σ (t)
The logistic regression model for match prediction consists of the vector n of match signs x = (x 1 , x 2 , ..., x n ) and the vector n + 1 real parameters of the model β = (β 0 , β 1 , ..., β n ) . To predict using the model, we first project the point in our n -dimensional feature space onto the real number:
You can now convert z to a value in an acceptable range of probabilities (from 0 to 1) using the logistic function defined above:
Model training consists of optimization of the parameters β , so that the model gives the best reproduction of the outcomes of matches for the training sample. This is done by minimizing the logistic loss function (equation below), which gives a measure of the model’s error in predicting the outcomes of the matches used for training.
where N is the number of matches in the sample
p i - the probability of predicting victory for match i
y i - real match outcome i (0 - defeat, 1 - win)
The figure below shows the logistic losses arising from one match for different predicted probabilities, provided that the match ended in victory for the predicted player. Any deviation from the most accurate prediction p = 1.0 is penalized.
Logistic losses with correct match prediction
Depending on the size of the sample, one of two training methods is chosen (ie, minimizing logistic losses):
1. Stochastic gradient decay - slow iterative method, suitable for large samples;
2. Maximum likelihood - faster numerical approximation, not suitable for large samples.
Most published machine learning models use logistic regression. Clarke and Dyte [8] apply a logistic regression model to the points difference between the two players in the ATP rating to predict the outcome of the set. In other words, they use the one-dimensional feature space x = (rankdiff) and optimize β 1 so that the function σ (β 1 * rankdiff) gives the best prediction for the training sample. Parameter β 0 is omitted in the model, since rankdiff 0 will give the probability of winning the match 0.5. Instead of directly predicting the outcome of the match, Clark and Data predict the probability of winning the set and simulate the probability of winning the match, thus increasing the sample size. The model was used to predict the results of several men's tournaments in 1998 and 1999, but the authors do not provide data on the prediction accuracy, mentioning only that the results are satisfactory.
Ma, Liu and Tan [9] used a larger feature space of 16 variables belonging to three categories: player skills and performance, player's physical parameters, match parameters. The model was trained at matches from 1991 to 2008. and was used to make recommendations to the players: for example, “to train receiving delivery more”.
Logistic regression is an attractive algorithm for predicting tennis because of the speed of training, resistance to retraining and the output of the probability of winning the match. However, without additional modifications, this algorithm cannot model the complex relationship between the input features.
Neural networks
An artificial neural network is a system of interconnected neurons, created according to the model of biological neurons. Each neuron calculates a value from the input signals, which can then be transmitted to the input to other neurons.
A forward propagation neural network (i.e., a network with an event prediction mechanism, feed-forward network) is a directed acyclic graph. As a rule, neural networks have several layers, with each neuron in the non-input layer associated with all neurons in the previous layer. The figure below shows a three-layer neural network.
Three-layer neural network of direct distribution
Each connection in the network are assigned weights. The neuron uses the input signal and its weight to calculate the output value. A typical network layout method is a non-linear weighted sum:
where w i is the input data weight x i .
The nonlinear K activation function allows the network to calculate non-trivial tasks using a small number of neurons. Usually, sigmoidal functions are used for this purpose, for example, the logistic function defined above.
Tennis matches can be predicted by giving the player and match signs to the input neuron layer and passing values through the network. If you use the logistic activation function, the value at the exit of the network may represent the probability of winning the match. There are many different learning algorithms, the purpose of which is to optimize the weights of the network to obtain the best output values for the training sample. For example, the back-propagation algorithm uses a gradient descent to reduce the mean square error between target values and values at the output of a neural network.
Neural networks can find connections between various features of a match, but by their nature they still remain a “black box,” that is, a trained network does not provide an additional understanding of the system, since it is too difficult to interpret. Neural networks are prone to retraining and therefore a lot of data is needed for their training. In addition, the development of a neural network model requires an empirical approach, and the selection of model hyperparameters is often carried out by trial and error. However, given the success of neural network models for predicting tennis, this approach must be considered promising.
Somboonphokkaphan [10] trained a three-layer neural network to predict tennis matches using a back-propagation algorithm. The author investigated and compared several different networks with different sets of input parameters. The best neural network consists of 27 input nodes representing such match and player attributes as the court surface, the winning percentage on the first serve, the second serve, the return serve, break points, etc. The author claims about 75% accuracy when predicting the outcome of matches of Grand Slam tournaments in 2007 and 2008.
Sipko [11] uses logistic regression and neural networks, testing models on a sample of 6135 matches of ATP tournaments 2013-2014, the ROI of the most accurate model was 4.35%, which according to the author is 75% better than modern stochastic models.
After the publication of the first part of the article, SpanishBoy found the implementation of the Sipko models on GitHub : their result was 65%, but the ROI was negative.
Support Vector Machine
Support vector machines (SVM), like the other machine learning algorithms described here, are a learning algorithm with a teacher. It was proposed by Vladimir Vapnik and Alexey Chervonenkis in 1963 and is one of the most popular modern teaching methods for precedents.
The task solved by SVM is to find the optimal hyperplane that correctly classifies points (examples) by dividing the points of the two classes into categories that are their labels (as in other algorithms, these categories can be “victory” and “defeat”). A new example, for example, the upcoming match, can then be projected into the same space of points and classified on the basis of which side of the hyperplane it comes from.
SVM has a number of advantages over neural networks: first, learning never leads to a local minimum, which often happens with neural networks. Secondly, SVM often outstrips neural networks in prediction accuracy, especially when there is a high ratio of features to training examples. However, much more time is spent on SVM training, and models are hard to customize.
Graduates of MIT Wagner and Narayanan [12] published a term paper where they used SVM to predict the winners in the interactive game ATP World Tour Draw Challenge, which was held by the Association of Tennis Professionals until 2014. tried to predict the tournament table winners in all upcoming matches until the winner of the tournament. The authors used 15 signs, mainly visitor statistics of players. The training sample was 40000 examples, for testing the model used cross-validation on 6000 examples. The maximum accuracy of the model was 65%.
The work of Panjan et al. [13] does not directly concern the prediction of match outcomes. They used SVM, along with other classification algorithms, to predict the success of young Slovenian tennis players in comparison with their peers and senior tennis players.
Other MO algorithms
Support vector machines undoubtedly deserve closer attention as models for predicting tennis. It is important to note that SVM requires stepwise calibration to produce good probabilities, while such a step is not necessary for logistic regression and neural networks. In addition, Bayesian networks that simulate the interdependence between different variables can be used to predict tennis matches.
Each model has a different efficiency in different conditions. Machine learning can also be used to build a hybrid model that combines output from other models. So, forecasts of different models can become separate signs, and the model can be trained to analyze the strengths and weaknesses of each of them. For example, a neural network prediction can be combined with a common rival model, using match parameters to weightedly evaluate the relative impact of two predictions.
Machine learning problems
Retraining
As already mentioned, a lot of historical data is available for teaching the described models. However, it is important to note that the game of tennis players in the upcoming match should be evaluated on the basis of their past matches: only recent matches on the same court coverage with similar opponents can accurately reflect the player’s expected result. It is clear that such data is extremely small for modeling, and this may lead to retraining of the model. This means that the model will describe a random error or noise in the data instead of the relevant pattern. Neural networks are especially susceptible to retraining, primarily when the number of hidden layers / neurons is too large compared to the number of examples.
To avoid retraining, only the most relevant signs of a match need to be selected. Separate algorithms also exist for the feature selection process itself. Eliminating irrelevant features will also reduce learning time.
Hyperparameter Optimization
Model training optimizes model parameters, such as weights in a neural network. However, in the model, as a rule, there are hyperparameters that are not taught and which need to be configured manually. For example, for neural networks, one of the configurable hyperparameters is the number of hidden layers and the number of neurons in each layer. Obtaining optimal hyperparameters for each model is an empirical process. The traditional algorithmic approach — grid search — implies an exhaustive search over a predetermined feature space. For these reasons, a successful model for predicting tennis requires careful selection of hyperparameters.
Live forecasting
Tennis expert Peter Webb claims that more than 80% of all tennis bets are placed directly during a match. Stochastic models can predict the probability of the outcome of a match from any initial account, which means that they can be used for live bets. Machine learning models are usually not rebuilt during the current match. And although the current score could be used as a sign of a match, the resource intensity of such a model would increase significantly, and the impact on accuracy or ROI could be minimal.
Female tennis
Often, studies only cover ATP men's matches, and the games of the Women's Tennis Association (WTA) are not counted. This is partly due to better availability of historical data and coefficients for ATP players, partly because additional features may be relevant for women, which will require re-checking and re-calibration of the model. In any case, the prediction of women's tennis with all its features is a direct field of activity for machine learning, and perhaps we will see such research in the future.
Cases MO to predict tennis
Research interest in prognostic models for tennis has led to the emergence of services that offer users the results of such predictions. It is important to note that due to the specifics of the sports betting market, a great number of forecasters (cappers, tipsters, etc.) are active on the Internet of varying degrees of decency, claiming that they give forecasts based on their own algorithms. For obvious reasons, in most cases they turn out to be fraudsters, which is easy to track by the number of details and the correctness of the technical information that they disclose (or do not disclose).
After screening people, forecasters, there are only a few resources that appear to use real mathematical models. Despite the fact that they, as a rule, do not reveal the algorithms and methods used, they can be traced by indirect signs.
One group of services provides the probabilities of winning both players in a match, leaving match statistics and player history for independent user analysis. Thus, they use prediction results based on stochastic hierarchical methods. Most of these resources: toptennistips.com, robobet.info, etc.
Services based on machine learning analyze not only the probabilities of winning, but also apply self-learning algorithms to historical statistics on players and match parameters. Such systems have created IBM, Microsoft and the Russian service OhMyBet!
Ibm
The IBM Keys to the Match system for predicting tennis has been promoted by the company since 2013 as a predictive analytical tool for four Grand Slam tournaments: Wimbledon and the Australian Open, France and the United States. For each player, the system analyzes its unique playing style and gives recommendations on three key indicators (keys) that a tennis player must achieve in order to increase their chances of winning in the current match. "Keys" is published on the official sites of tournaments.
The system takes statistics from Grand Slam tournaments since 2005, which is almost 12,000 matches. IBM has been an official partner of Grand Slam tournaments for many years: the company collects and processes all the statistics of these matches. IBM claims that for each match, Keys to the Match analyzes up to 41 million data points, including points, score, duration, feed rate, percentage of innings, number of hits, types of hits, etc.
Based on the analysis, the system determines 45 key dynamic indicators of the game and identifies three of them that are most important for each player in this match: 19 keys for attack, 9 for defense, 9 for endurance, and 8 keys describing the overall style of play. During the tournament, the system creates a total of 5500 predictive models.
To select three key features, the system also analyzes the difference in player statistics for each of the four Grand Slam tournaments, the history of personal encounters of opponents, and the history of games with similar opponents. A profile with all relevant statistics is created for each player, after which the clustering algorithm separates the players according to the degree of similarity of profiles and playing style.
IBM does not disclose exactly which predictive algorithms are used in the system. Moreover, despite the phrase “predictive analytics” that is constantly found in Keys to the Match marketing materials, IBM spokesman Kenneth Jensen stresses : “The system is not designed to predict the winner of a match or set. The goal of Keys to the Match is to identify three player performance indicators and track the current game of a tennis player in comparison with his previous results and those of comparable players. ”
Microsoft
The artificial intelligence system Cortana Intelligence Suite from Microsoft has not yet been used to predict tennis, but it is being actively tested on predicting football matches, so the story about it is included in this review (you can read more here ).
Cortana was first tried to predict sports in 2014, when she predicted the results of World Cup matches. Then 15 of 16 predictions of game outcomes turned out to be correct. After that, Microsoft made predictions for the Women's World Cup, the English Premier League, the UEFA Champions League, the Brazilian Championship, the French Championship, the Spanish Championship, the German Championship, and the Italian Championship.
To predict results, the system uses a comprehensive analysis of two factors: statistics (the ratio of victories and defeats of the team, the number of goals scored, the location of the match, weather conditions) and data of web search and social networks (the phenomenon of "collective intelligence"). The chance of winning each team is determined as a percentage, the probability of a draw in the matches for each game of the qualifying round is calculated.
In general, the phenomenon of "collective knowledge" is underestimated, according to Microsoft. The results of the events, which, it would seem, cannot influence public opinion (football championships are just this case), in fact, can be predicted by analyzing the behavior of people on the Internet. So Cortana Intelligence Suite predicts the results of TV shows, elections, awards ceremonies and a variety of competitions based on voting. The system reveals exactly which public actions of users correlate with the distribution of votes. Predictive algorithms are compiled on these correlations. It is proved that in cases where individual experts may be wrong, public opinion analysis adds 5% to the accuracy of the forecast.
However, a football match is not a vote, but its structure is more complicated than tennis, and the results of Cortana’s predictions are still far from ideal. So, for Euro 2016, the system predicted that with a probability of 66% the champion would be Germany, and in the match with England on June 11, Russia will not score a single goal, perform less than four attacks, and the number of successful passes will not exceed 221.
The result is known to us.
OhMyBet!
Service OhMyBet! created by graduates of the Physics and Technology Institute and Moscow State University. In early July, a note on the service appeared on vc.ru , where the creators briefly described the system. The study of predictive algorithms in graduation and dissertation projects led the authors to work out their models at tennis matches.
From the data on 825,000 matches played in ITF and ATF tournaments from 2000 to 2014, we identified such signs as match result, coverage, tournament, number of aces, number of double faults, winning percentage on the first and second serve, average serving speed of each player, age of players , estimated winning motivation, previous player meetings, injuries, rest time between matches, etc. The machine learning algorithms were applied to this data.
The model was validated at the 2015 matches. Result: 12% ROI for 2015, while the accuracy of the system was 75-77%. The maximum accuracy in 2015 is 85%, however, the ROI decreases.
High ROI is provided due to the fact that the algorithm itself cuts forecasts with low coefficients. The average winning coefficient is 1.74. In total from the beginning of 2015 to the present, the algorithm gave 452 forecasts, 350 for 2015.
The creators do not disclose the algorithm used in the system, however, from the analysis of published works and observation of the behavior of the system itself, it can be assumed that this is a neural network. For example, the creators said that when setting up the model, they faced retraining and were forced to adjust the training signs.
The last major update of the algorithm was conducted in early July 2016, after which full access to the site was opened for users. The forecast statistics from the beginning of 2015 to the current match is available on the website in the History section. From the moment of launch, the authors conduct open monitoring of forecasts on the Blogabet platform in order to avoid allegations of fraud on statistics.
Bibliography
8. SR Clarke and D. Dyte. Using official ratings to simulate major tennis tournaments. International Transactions in Operational Research, 7 (6): 585–594, 2000.
9. S. Ma, C. Liu, and Y. Tan. An analysis of the player of the world of science and sports statistics. Journal of sports sciences, 31 (11): 1147–55, 2013.
10. A. Somboonphokkaphan, S. Phimoltares, and C. Lursinsap. Tennis Winner Prediction based on Time-Series History with Neural Modeling. IMECS 2009: International Multi-Conference of Engineers and Computer Scientists, Vols I and II, I:127–132, 2009.
11. M. Sipko. Machine Learning for the Prediction of Professional Tennis Matches. Technical report, Imperial College London, London, 2015.
12. A. Wagner, D. Narayanan. Using Machine Learning to predict tennis match outcomes. MIT 6.867 Final Project.
13. A. Panjan et al.: Prediction of the successfulness of tennis players with machine learning methods. Kinesiology 42(2010) 1:98-106
Source: https://habr.com/ru/post/307422/
All Articles