The most important thing about neural networks. Lecture in Yandex
It seems that not a day goes by, so that posts about neural networks do not appear on Habré. They made machine learning accessible not only to large companies, but also to any person who can program. Despite the fact that it seems to everyone that everyone already knows everything about neural networks, we decided to share a review lecture given at the Small ShAD, designed for high school students with a strong mathematical background.
The material told by our colleague Konstantin Lachman summarizes the history of the development of neural networks, their main features and fundamental differences from other models used in machine learning. We will also discuss specific examples of the use of neural network technologies and their immediate prospects. The lecture will be useful to those who want to systematize in their head all the most important modern knowledge of neural networks.
')
Konstantin klakhman Lakhman graduated from the Moscow Engineering and Physics Institute, worked as a researcher in the neuroscience department of the Kurchatov Institute. In Yandex, he deals with neural network technologies used in computer vision.
Under the cut - detailed decoding with slides.
Hello. My name is Kostya Lachman, and the topic of today's lecture is “Neural Networks”. I work at Yandex in a group of neural network technologies, and we develop all sorts of cool things based on machine learning using neural networks. Neural networks are one of the methods of machine learning, which now attracts quite a lot of attention not only from data analysis specialists or mathematicians, but also generally from people who have nothing to do with this profession. And this is due to the fact that solutions based on neural networks show the best results in the most diverse areas of human knowledge, such as speech recognition, text analysis, image analysis, which I will try to talk about in this lecture. I understand that, probably, everyone in this audience and those who listen to us have a slightly different level of training - someone knows a little more, someone a little less - but you can raise your hands for those who read something about neural networks? This is a very solid part of the audience. I will try to make it interesting for those who have not heard anything at all, and for those who still read something, because most of the studies I’m going to talk about are from this year or the previous year, because there are so many everything happens, and literally half a year goes by, and those articles that were published six months ago, they are already a little outdated.

Let's start. I very quickly just tell you what the task of machine learning as a whole is. I am sure that many of you know this, but to move on, I would like everyone to understand. On the example of the task of classification as the most understandable and simple.
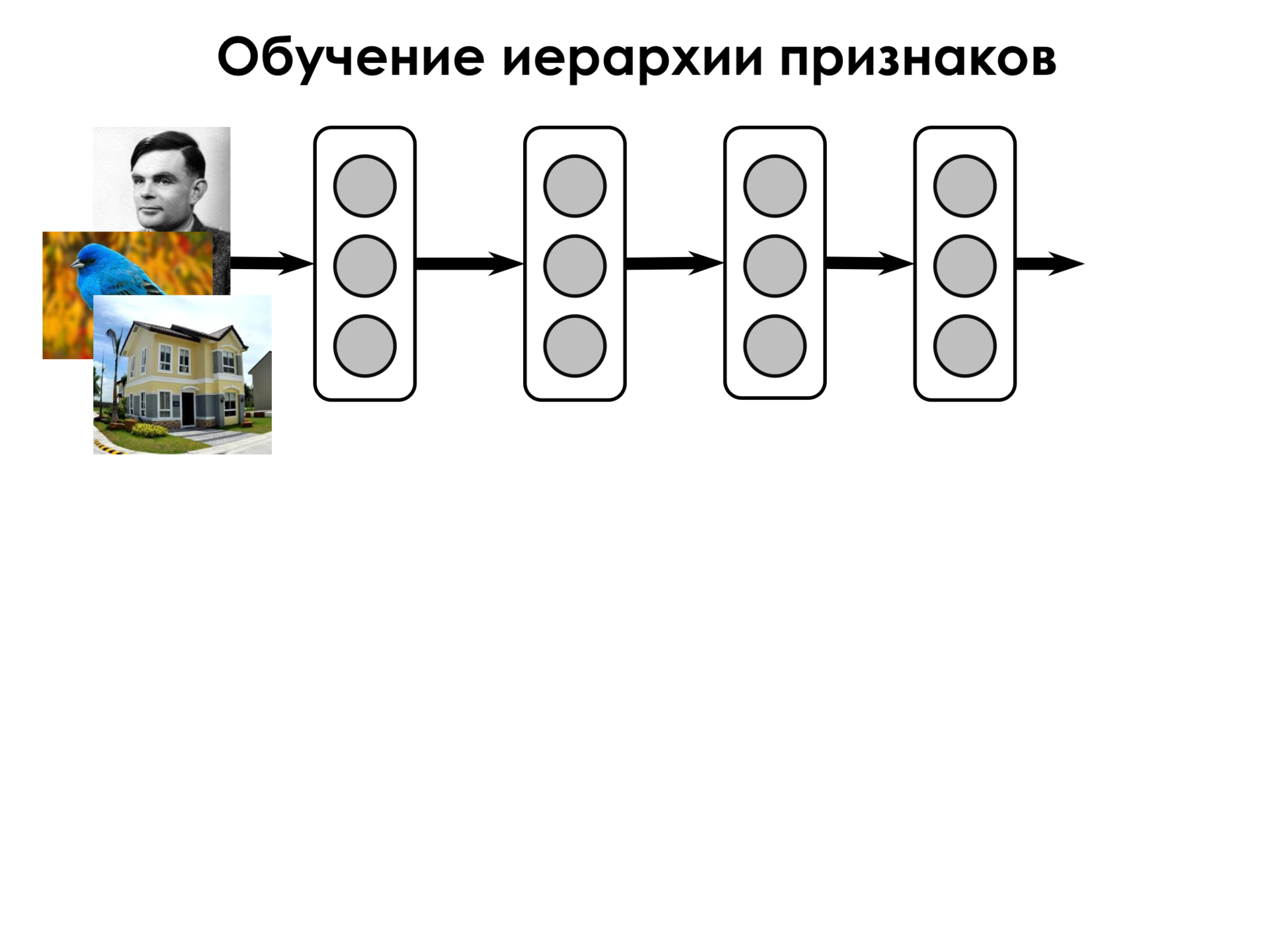
Suppose we have some U - a set of objects of the real world, and for each of these objects we assign some signs of these objects. And also each of these objects has some kind of class that we would like to be able to predict, having attributes of an object. Let's look at this situation on the example of images.

Objects are all images in the world that may interest us.

The simplest attributes of images are pixels. Over the past half century, during which humanity has been engaged in image recognition, much more complex features of images have been invented - but these are the simplest.

And the class that we can relate to each image is, for example, a person (this is a photograph of Alan Turing, for example), a bird, a house, and so on.

The task of machine learning in this case is the construction of a decisive function, which, according to the feature vector of the object, will say to which class it belongs. You had a lecture, as far as I know, Konstantin Vorontsov, who talked about all this much deeper than me, so I am only at the very top.
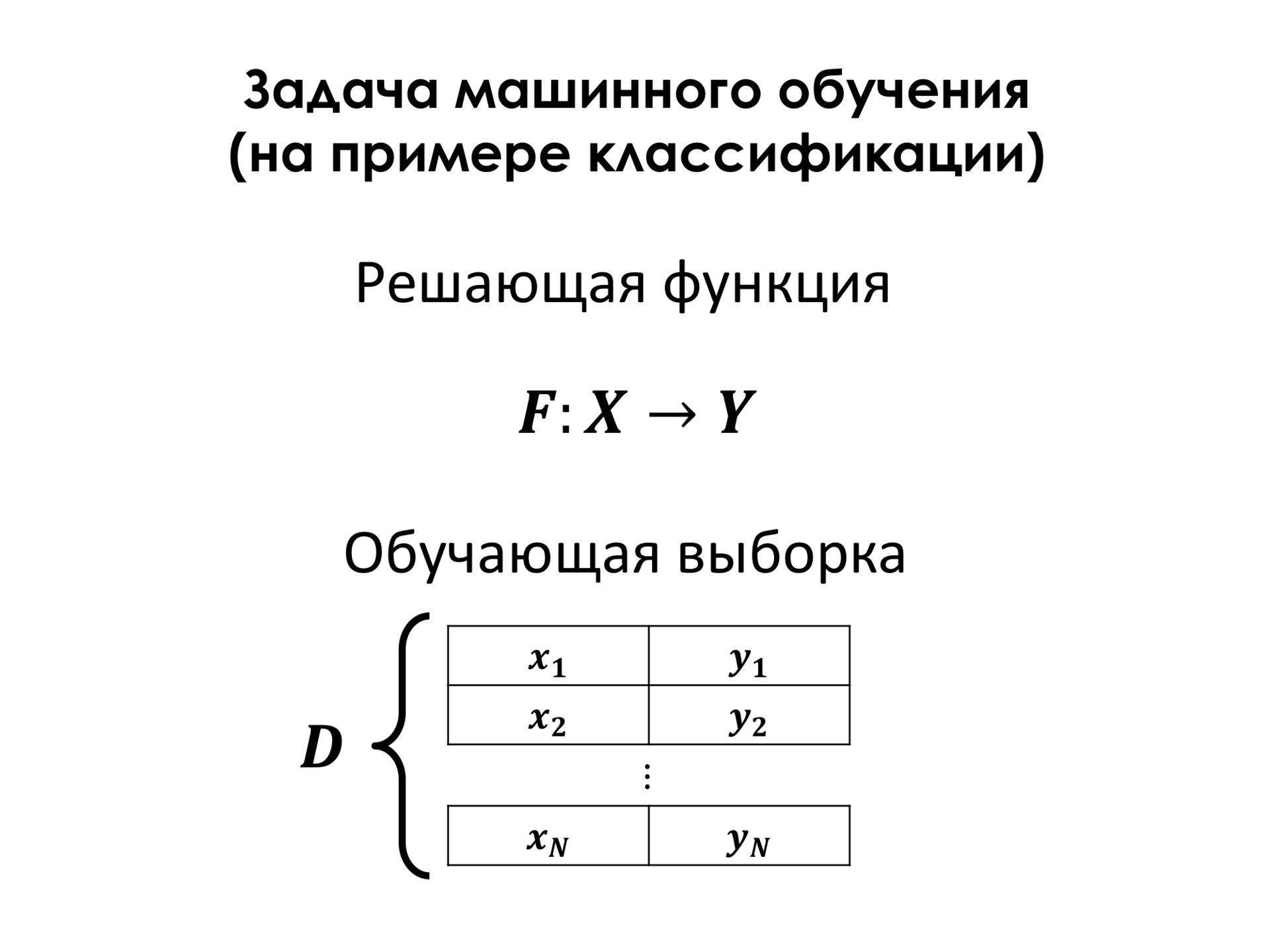
In most cases, the so-called learning sample is needed. This is a set of examples, about which we know for sure that this object has such a class. And on the basis of this training sample, we can build this crucial function, which makes as few mistakes as possible on the objects of the training set and, thus, expects that we will also have good quality classifications on objects that are not part of the training set.

To do this, we need to introduce some error function. Here D is a learning set, F is a crucial function. And in the simplest case, the error function is just the number of examples in which we are mistaken. And, in order to find the optimal crucial function, we need to understand. Usually we choose a function from some parametric set, that is, it is just some kind of, for example, polynomial equation, which has some coefficients, and we need to somehow pick them up. And the parameters of this function, which minimize this error function, loss function, are our goal, that is, we want to find these parameters.
There are many methods for finding these parameters. I will not go into it now. One of the methods is when we take one example of this function, look, whether we have classified it correctly or incorrectly, and take the derivative with respect to the parameters of our function. As you know, if we go in the direction of the inverse of this derivative, we will thus reduce the error in this example. And, thus, passing all the examples, we will reduce the error by adjusting the parameters of the function.
What I just talked about applies to all machine learning algorithms and to the same extent applies to neural networks, although neural networks have always stood a little apart from all other algorithms.

Now there is a surge of interest in neural networks, but this is one of the oldest machine learning algorithms that you can think of. The first formal neuron, the neural network cell, was proposed, its first version, in 1943 by Warren McCulloch and Walter Pitts . Already in 1958, Frank Rosenblatt proposed the first simplest neural network that could already separate, for example, objects in two-dimensional space. And neural networks went through all this more than half a century history of ups and downs. Interest in neural networks was very large in the 1950s and 1960s, when the first impressive results were obtained. Then neural networks gave way to other machine learning algorithms, which turned out to be stronger at that moment. Again interest resumed in the 1990s, then again went into decline.

And now in the last 5–7 years, it has turned out that in many tasks related to the analysis of natural information, and everything that surrounds us is natural information, this is language, this is speech, this is an image, video, many other very different information, neural networks are better than other algorithms. At least for the moment. Perhaps again the Renaissance will end and something will come to replace them, but now they show the best results in most cases.
What led to this? The fact that neural networks as an algorithm for machine learning, they need to be trained. But unlike most algorithms, neural networks are very critical to the volume of data, to the volume of that training sample, which is necessary in order to train them. And on a small amount of data, the networks simply do not work well. They do not generalize well, they work poorly with examples that they have not seen in the learning process. But in the past 15 years, the growth of data in the world may become exponential, and now this is no longer such a big problem. We have a lot of data.
The second such cornerstone, why now the renaissance of networks is computing resources. Neural networks are one of the most ponderous machine learning algorithms. Huge computational resources are needed to train a neural network and even to use it. And now we have such resources. And, of course, new algorithms were invented. Science does not stand still, engineering does not stand still, and now we understand more about how to train this kind of structure.
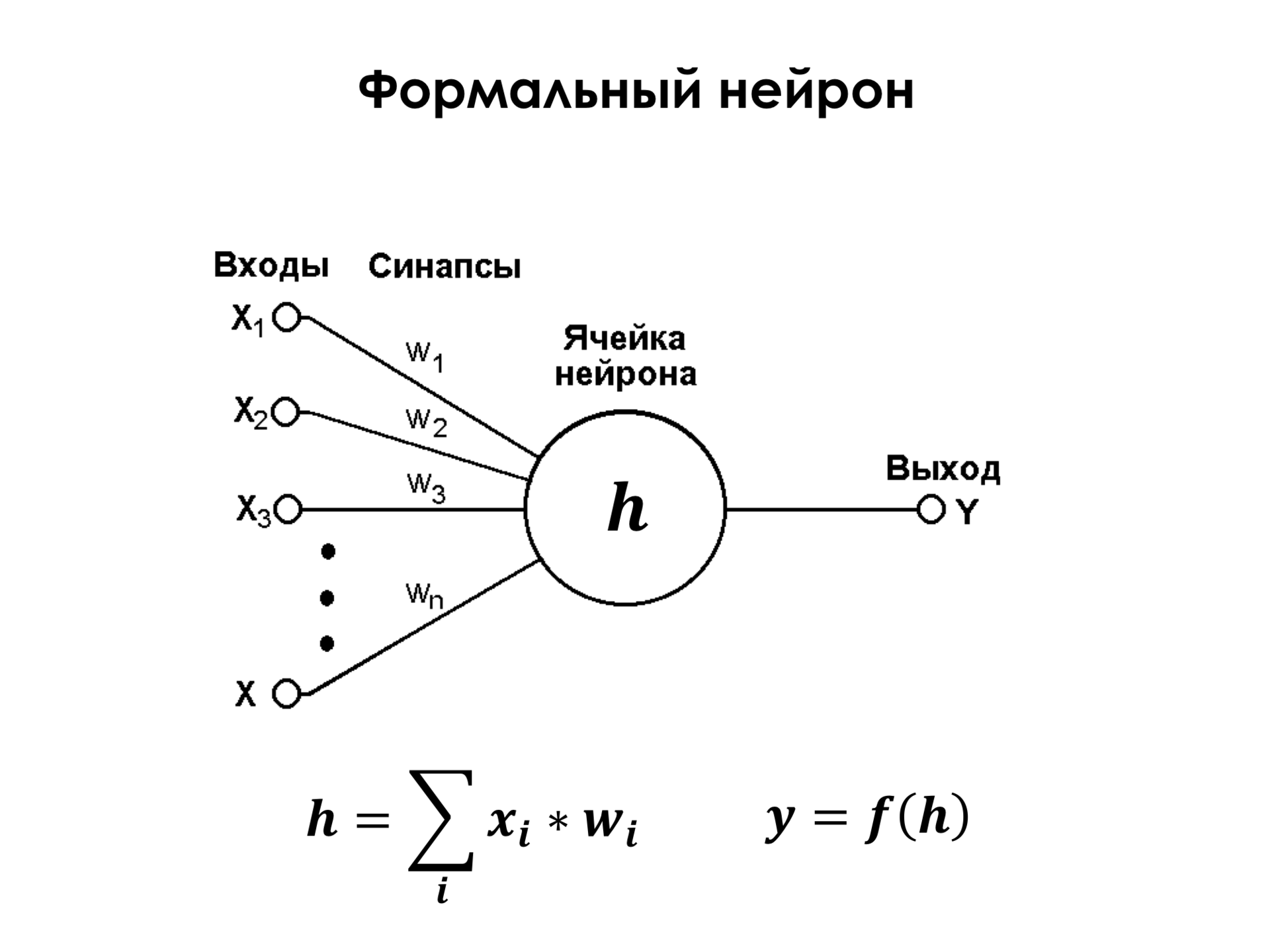
What is a formal neuron? This is a very simple element that has some limited number of inputs, a certain weight is attached to each of these inputs, and the neuron simply takes and performs a weighted summation of its inputs. At the entrance may be, for example, the same pixels of the image, about which I told before. Imagine that X 1 and up to X n are just all the pixels of the image. And to each pixel some weight is attached. He summarizes them and performs some non-linear transformation on them. But even if you do not touch the linear transformation, then already one such neuron is a powerful enough classifier. You can replace this neuron and say that it’s just a linear classifier, and the formal neuron is, it’s just a linear classifier. If, say, in a two-dimensional space we have a certain set of points of two classes, and these are their signs of X 1 and X 2 , that is, by selecting these weights V 1 and V 2 , we can build a dividing surface in this space. And thus, if we have this amount, for example, greater than zero, then the object belongs to the first class. If this sum is less than zero, then the object belongs to the second class.
And everything is good, but the only thing is that this picture is very optimistic, there are only two signs, classes, as they say, linearly separable. This means that we can simply draw a line that correctly classifies all the objects in the training set. In fact, this is not always the case, and it is almost never the case. And so one neuron is not enough to solve the vast majority of practical problems.

This is a non-linear transformation that each neuron performs over this sum, it is critically important, because, as we know, if we, for example, perform such a simple summation and say that it is, for example, some new feature Y 1 (W 1 x 1 + W 2 x 2 = y 1 ) , and then we have, for example, a second neuron, which also summarizes the same signs, only this will be, for example, W 1 'x 1 + W 2 ' x 2 = y 2 . If we then want to apply again a linear classification in the space of these features, then it will not make any sense, because two applied linear classifications are easily replaced by one, it is simply a property of linearity of operations. And if we carry out some non-linear transformations on these features, for example, the simplest ... Previously, we used more complex non-linear transformations, such as this logistic function, it is limited to zero and one, and we see that there are sections of linearity. That is, it is about 0 in x behaves quite linearly, like a normal straight line, and then it behaves nonlinearly. But, as it turned out, in order to effectively train classifiers of this kind, the simplest nonlinearity in the world is enough - just a truncated straight line, when in the positive segment it is straight, and in the negative segment it is always 0. This is the simplest nonlinearity, and it turns out that even enough to effectively train the classification.
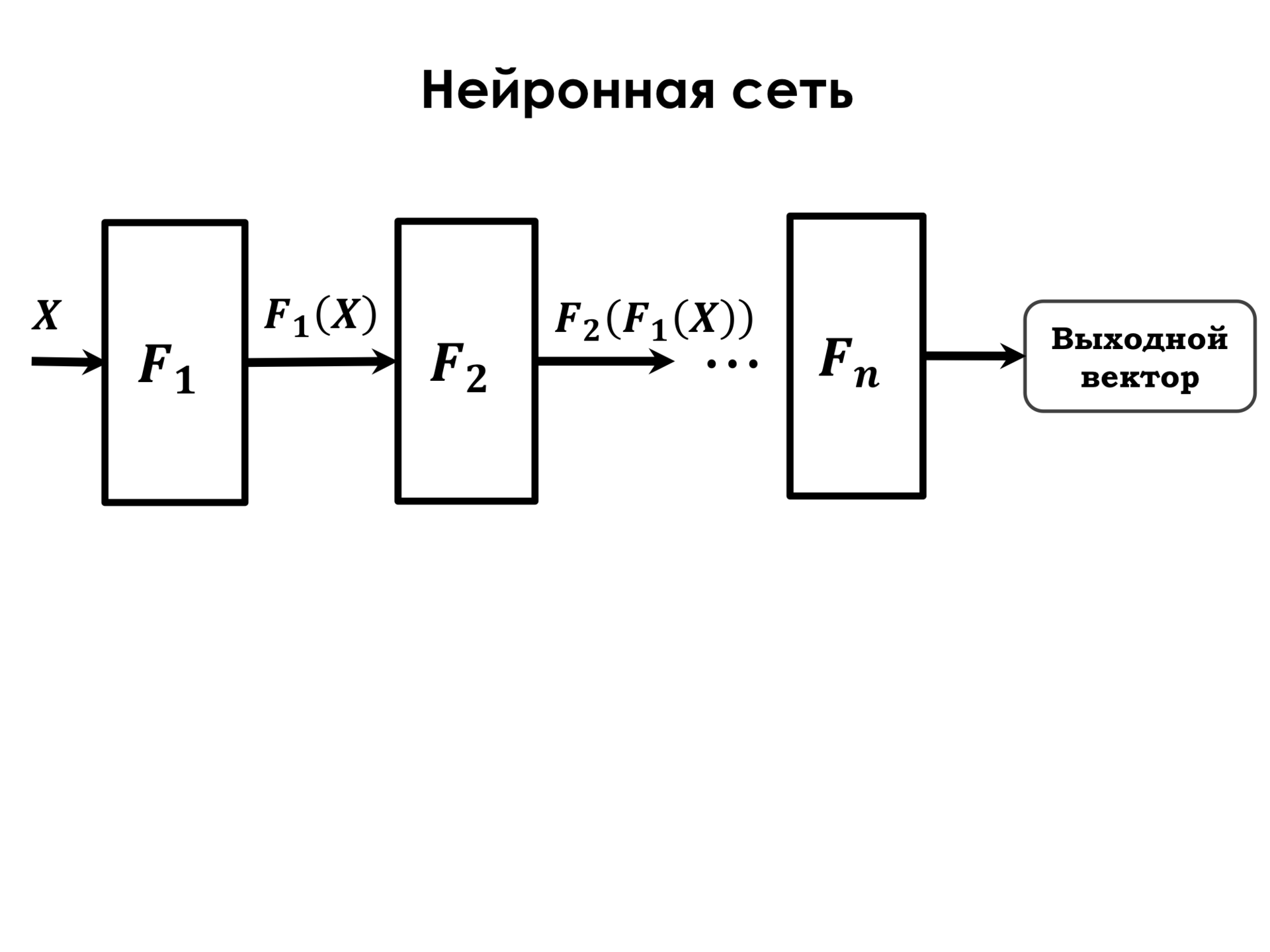
What is a neural network? The neural network is a sequence of such transformations. F1 is the so-called neural network layer. The layer of a neural network is simply a collection of neurons that work on the same signs. Imagine that we have the initial signs x 1 , x 2 , x 3 , and we have three neurons, each of which is associated with all these signs. But each of the neurons has its own weights, on which it weighs such signs, and the task of training the network in selecting such weights for each of the neurons, which optimizes our error function. And the function F 1 is one layer of such neurons, and after applying the function we get some new feature space. Then we apply another such layer to this feature space. There may be a different number of neurons, some other non-linearity as a transforming function, but these are the same neurons, but with such weights. Thus, consistently applying these transformations, we get the common function F - the transformation function of the neural network, which consists of the sequential application of several functions.

How are neural networks trained? In principle, like any other learning algorithm. We have some output vector, which is obtained at the output of the network, for example, a class, some sort of class label. There is some reference output that we know that these signs should have, for example, such an object, or what number we should attach to it.

And we have some delta, that is, the difference between the output vector and the reference vector, and further on the basis of this delta there is a big formula, but its essence is that if we understand that this delta depends on F n , that is from the output of the last layer of the network, if we take the derivative of this delta by weights, that is, by those elements that we want to train, and the so-called chain rule also applies, that is, when we have derivatives of a complex function, this is the product of the derivative with respect to the function of the function of the parameter it turns out that in such a simple way we can find derivatives for all of our scales and adjust them depending on the error that we observe. That is, if we do not have an error on any particular training example, then, accordingly, the derivatives will be zero, and this means that we classify it correctly and we do not need to do anything. If the error in the training example is very large, then we must do something about it, somehow change the weights to reduce the error.
Now there was a little mathematics, very superficial. Further, most of the report will be devoted to cool things that can be done with the help of neural networks and that many people in the world, including in Yandex, are doing now.

One of the methods that first showed practical benefits is the so-called convolutional neural networks. What are convolutional neural networks? Suppose we have an image of Albert Einstein. This picture, probably, many of you also saw. And these circles are neurons. We can connect a neuron to all pixels of the input image. But here there is a big problem that if you connect each neuron to all pixels, then, firstly, we will have a lot of weights, and this will be a very computationally capacious operation, it will take a very long time to calculate such a sum for each neuron. second, there will be so many weights that this method will be very unstable to retraining, that is, to effect, when we all predict well on the training set, and we work very poorly on many examples that are not included in the training, simply because we converted to an educational set stiffness We have too many scales, too much freedom, we can very well explain any variations in the training set. Therefore, they invented a different architecture in which each of the neurons is connected only to a small neighborhood in the image. Among other things, all these neurons have the same weights, and this design is called image convolution.
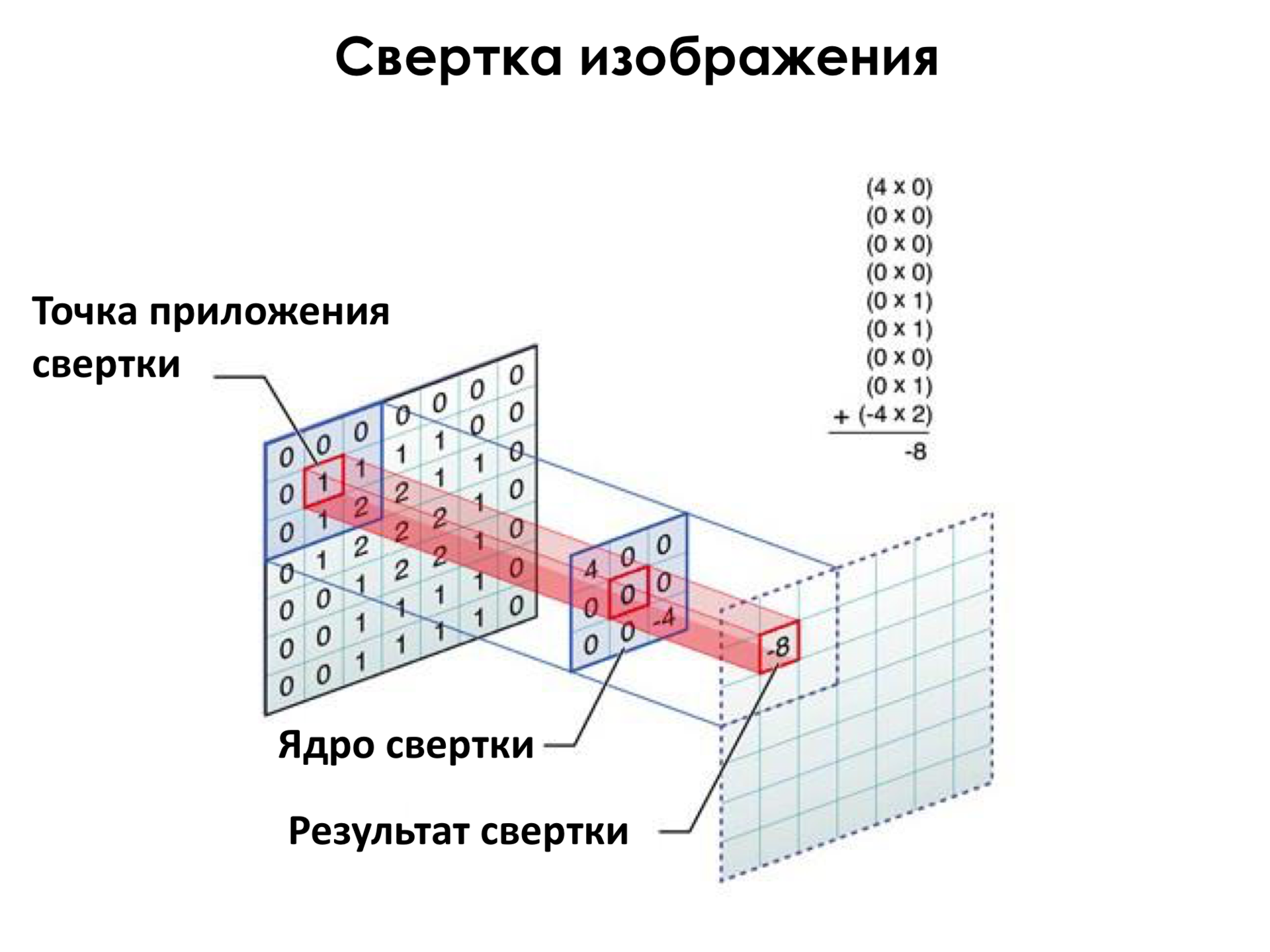
How is it done? Here we have the so-called convolution kernel in the center - this is the set of weights of this neuron. And we apply this convolution kernel in all pixels of the image sequentially. Apply - this means that we simply weigh the pixels in this square on the weights, and get some new value. We can say that we converted the image, walked through it with a filter. As in Photoshop, for example, there are some filters. That is, the simplest filter is how to make black and white from a color picture. And so we went through this filter and got some transformed image.
What is the plus here? The first plus is that less scales, faster to count, less prone to retraining. On the other hand, each of these neurons is produced by some detector, as I will show next. Suppose if somewhere in the image we have an eye, then we are using the same set of weights, traversing the picture, we will determine where the eyes are in the image.

There must be a video here.
And one of the first things to which this architecture was applied is the recognition of numbers as the simplest objects.
Applied it somewhere in 1993, Yang Lekun in Paris, and now there will be almost an archive recording. The quality is so-so. Here they now provide handwritten numbers, press a button, and the network recognizes these handwritten numbers. Basically, she recognizes unmistakably. Well, these numbers are naturally simpler because they are printed. But, for example, in this image the numbers are much more complicated. And these figures, to be honest, even I can not quite discern. There, it seems, the four left, but the network guesses. Even this kind of numbers she recognizes. This was the first success of convolutional neural networks, which showed that they are really applicable in practice.
What are the specific features of these convolutional neural networks? This convolution operation is elementary, and we build the layers of these bundles above the image, transforming further and further the image. Thus, we actually get new signs. Our primary features were the pixels, and then we transform the image and get new signs in the new space, which may allow us to more effectively classify this image. If you imagine the image of dogs, they can be in a variety of poses, in a variety of lighting, on a different background, and it is very difficult to classify them, directly relying only on pixels. And by consistently obtaining a hierarchy of signs of new spaces, we can do this.
This is the main difference between neural networks and other machine learning algorithms. For example, in the field of computer vision, in recognition of images up to neural networks, the following approach was adopted.
When you take a subject area, for example, we need to define between ten classes which object the house, bird, person belongs to, people sat for a very long time and thought what signs could be found to distinguish these images. For example, an image of a house is easy to distinguish if we have a lot of geometric lines that intersect somehow. In birds, for example, there is a very bright color, so if we have a combination of green, red, other signs, then probably it looks more like a bird. The whole approach was to come up with as many such signs as possible, and then submit them to some fairly simple linear classifier, something like this, which actually consists of a single layer. There are also more difficult methods, but, nevertheless, they worked on these signs, which were invented by man. And with neural networks, it turned out that you can just make a training sample, not select any signs, just submit images to it, and she will learn, she will select those signs that are critical for classifying these images due to this hierarchy.
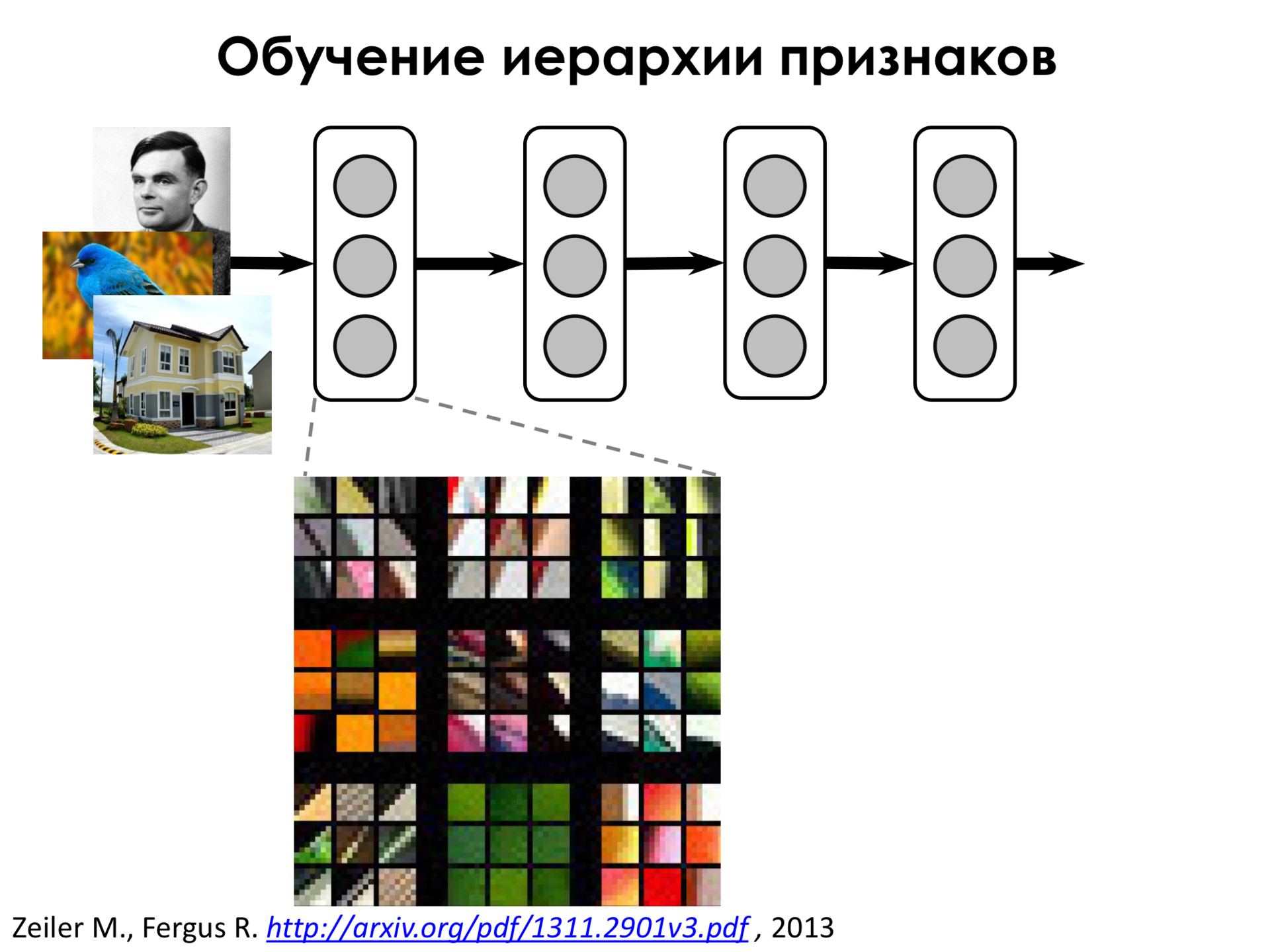
Let's look at what signs a neural network highlights. On the first layers of such a network, it turns out that the network highlights very simple features. For example, gradient transitions or some lines at different angles. That is, it highlights the signs - this means that the neuron reacts if it sees approximately such a piece of the image in the window of its convolution kernel, in the field of view. These signs are not very interesting, we could have come up with them ourselves.
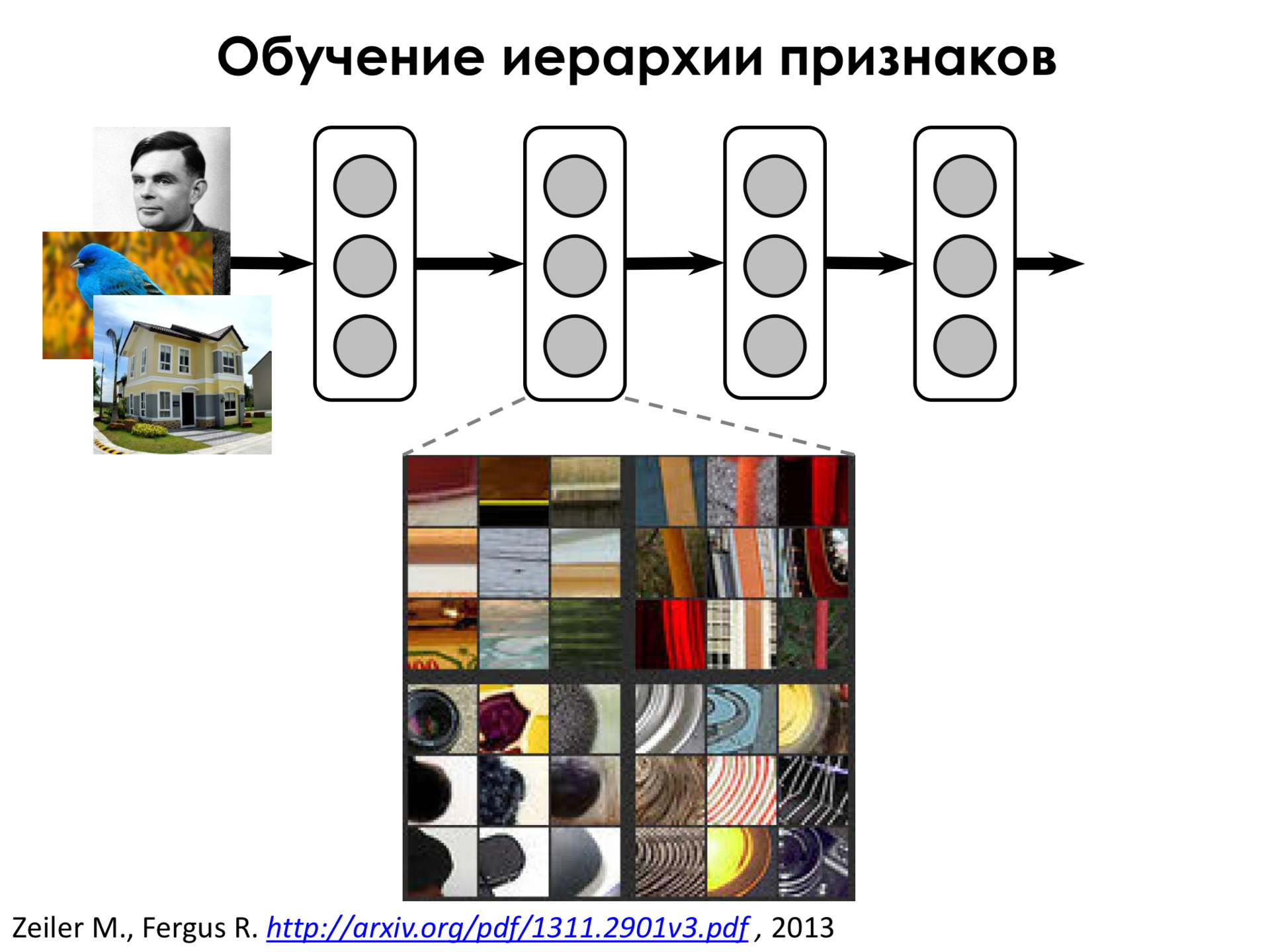
Moving deeper, we see that the network begins to select more complex features, such as circular elements and even circular elements, along with some stripes.
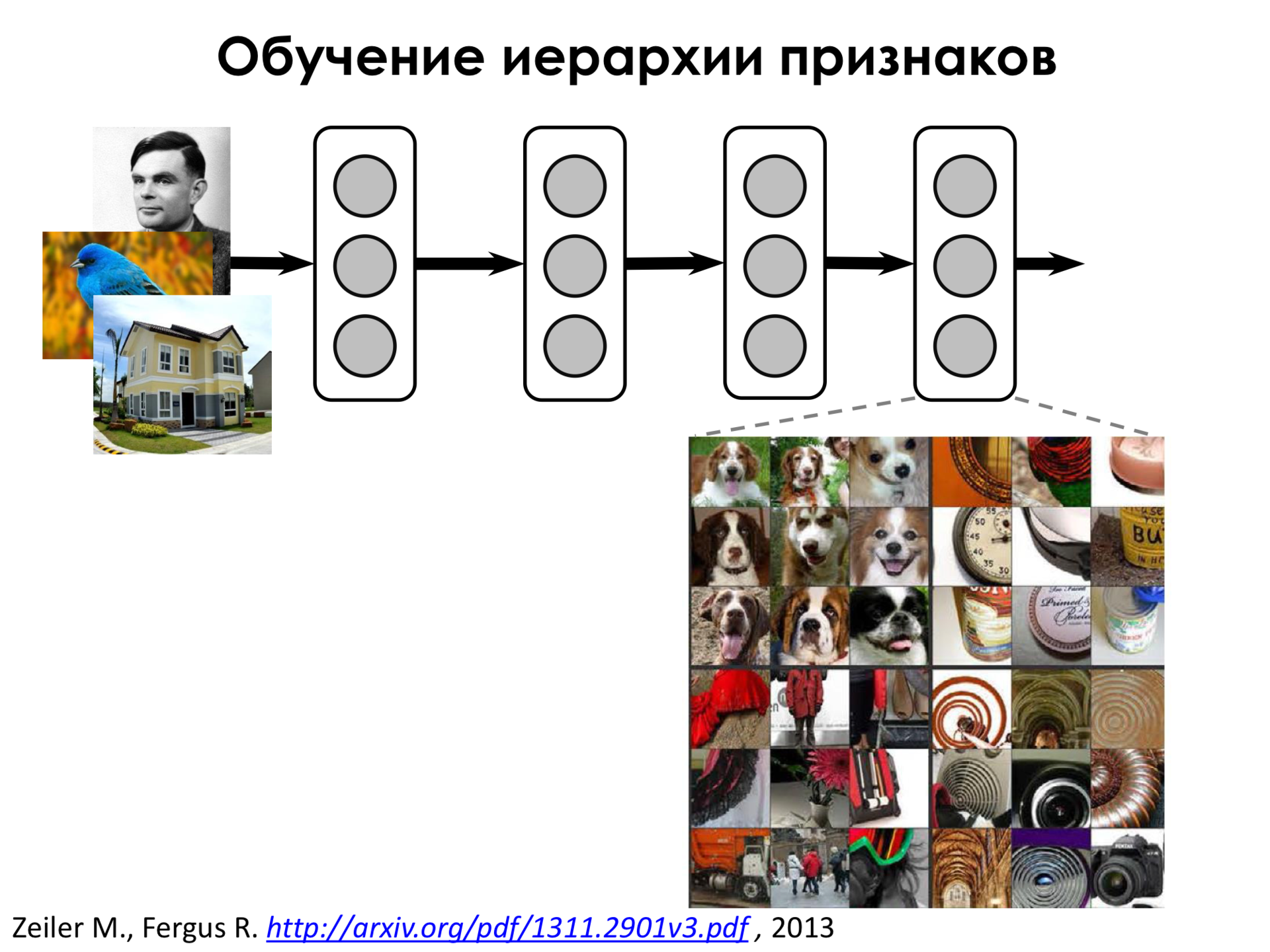
, , . , , , , , , , - .

What is all this for? , Image.net. , . .

. , , , – . , , , , . , -, 300 . , , - , .

, , . , , , . , , . , , , . , – , . , , , - - . , . , , , , . , , , . , , , – . , , , - , – . , .
, , . , . , . . , . , - . , . , - , .
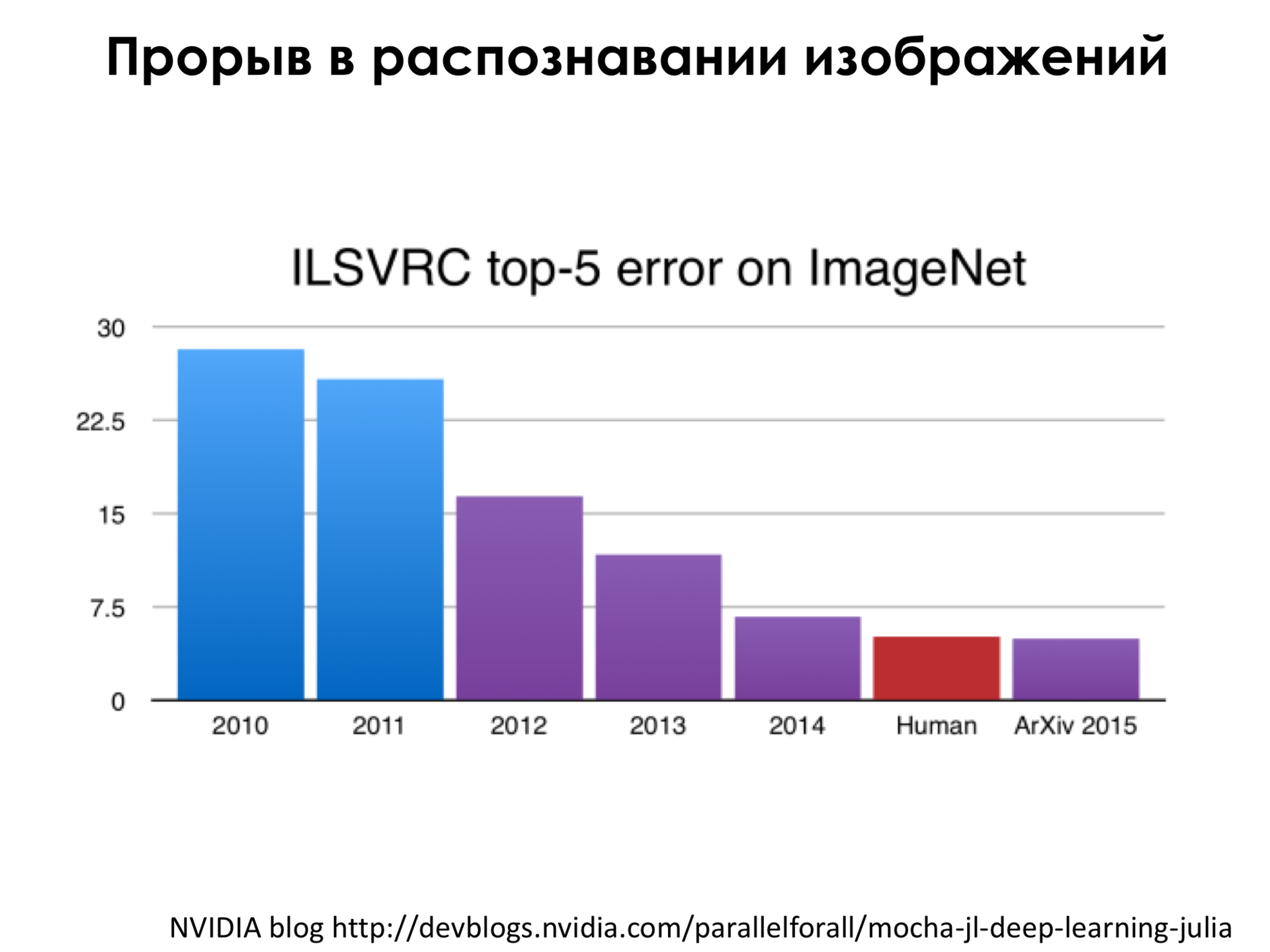
-5 . -5 , , , , , . – . ( 2010-2011 , ) , , , , 30%, 2011 , , , 2012 , , , , , , , – – , . , , , , - 4,5% , 2015 , , , .

, , , , , . , 2013 , , -, 8 9 . , , 2014 , , , , , , .

? , ? , , , - -, , , , , , , . , , , NBA, , .
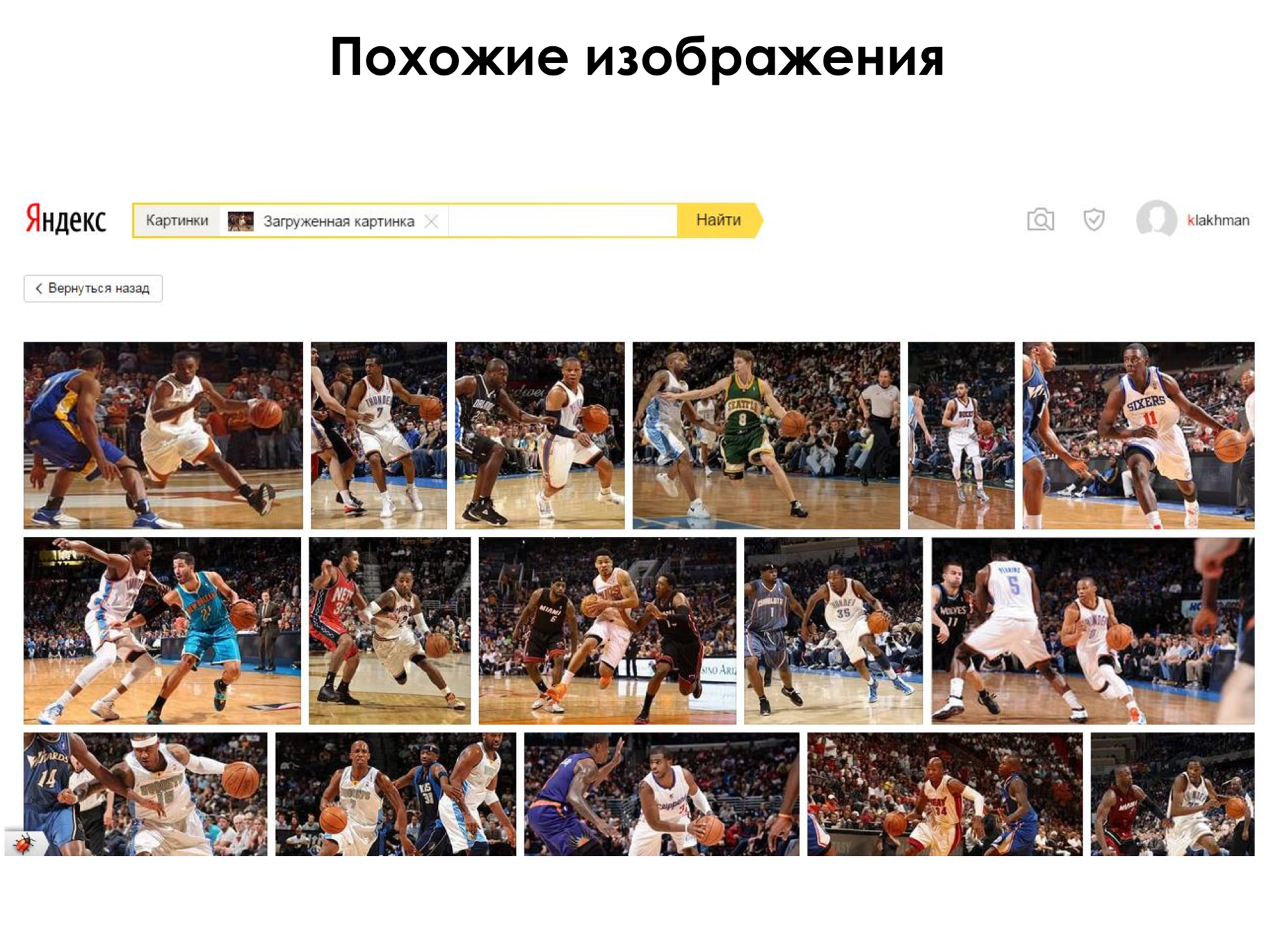
, , . , . , , .

, , – – , , , , . . , , , , , , , . , « , , , , ». , , . , , , . , , , – - 2014-2015 , .
: , , . What it is?
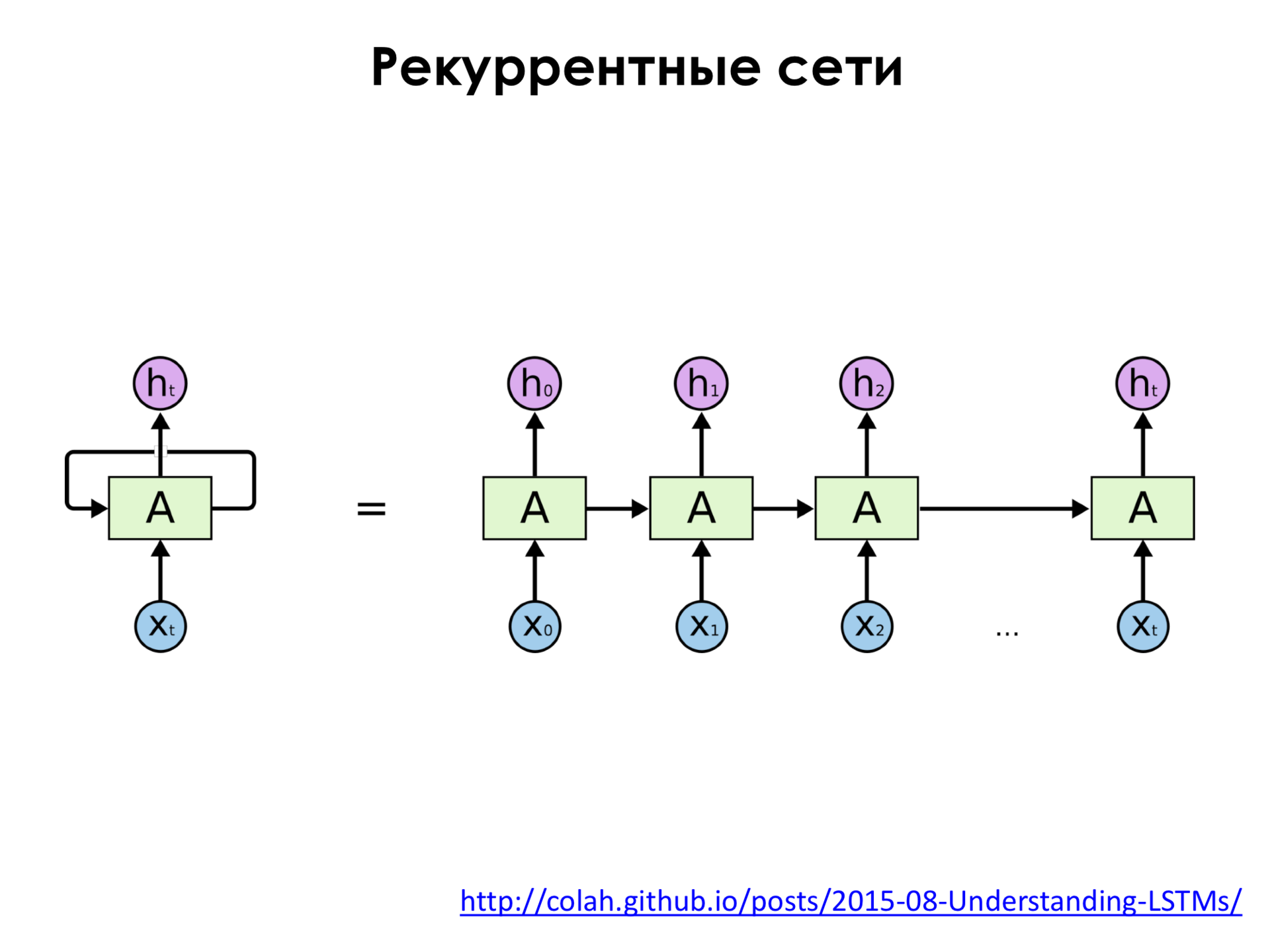
– – . , , , - , , . . , , , - , , , - , , . , , , , , , , , , . . , , , , , . .
– . x 0 , x 1 , x 2 . . , , , .

? – , . , , , , , , . LaTeX, , . , , , . . , . , , , , , . , . , . , , - . LaTeX , , - .

, , . Linux, , , , , , . , , , , . , . , , , , , , .

, , , . , , . , , . , « », , . , , , . , , , . . , , . . , , , , . , , , . . : , , .
— , ?
— – , - , . .
– , . . . , - , , - , , , 100 – . , , . , 100 – , , , . . - . 50 ., , .
, , , , . .
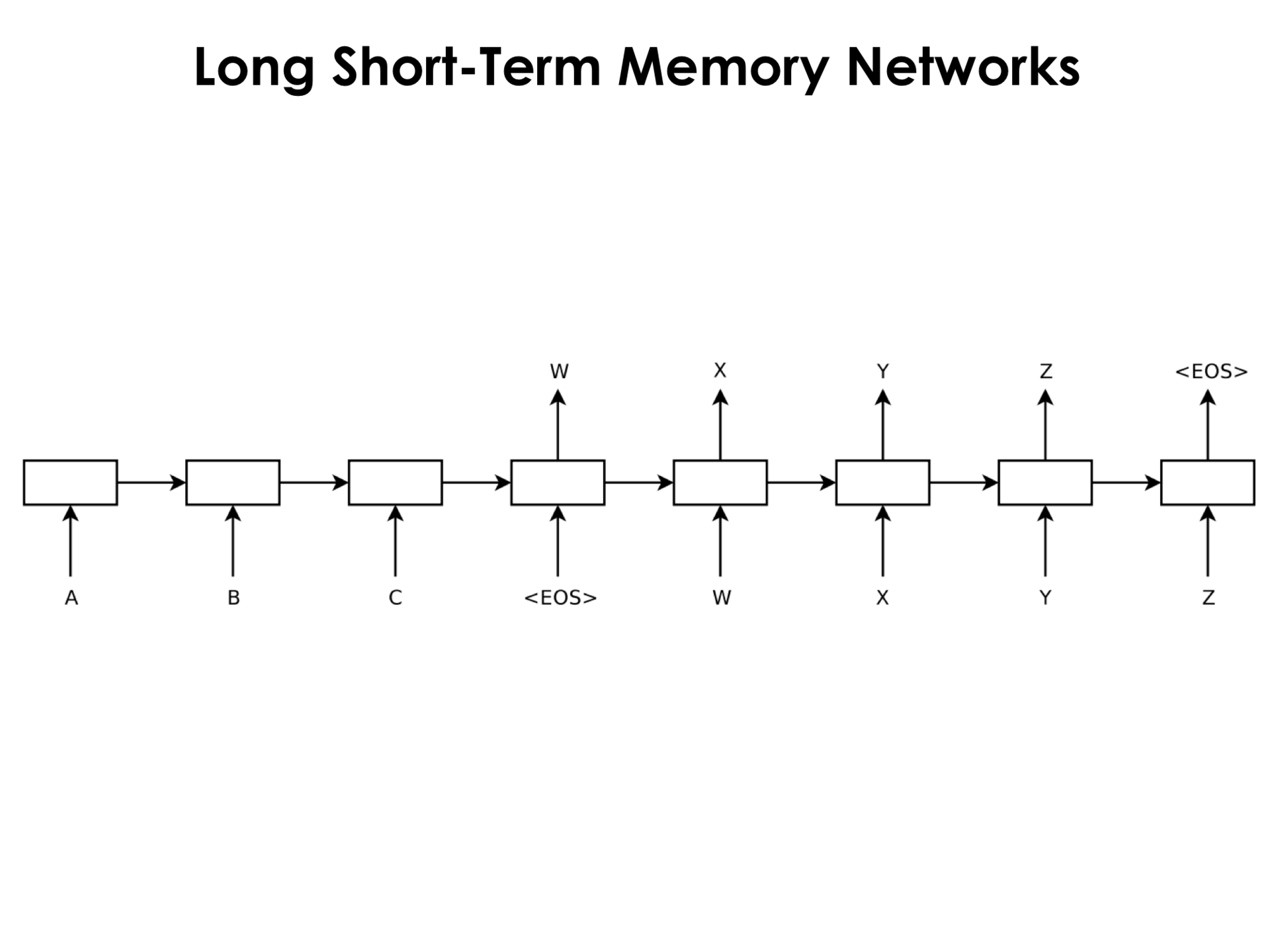
, , , . .
What is it for? , . , , – , , . , , , , , . – , - , , abstract. , .

, , , . , , , , IT, . , , , , , . , , , - . , , . , - , « -, , , , ?». , , .

, . , , -, , .
. , , .

, « ». , , , , . , . , , , , . , , .
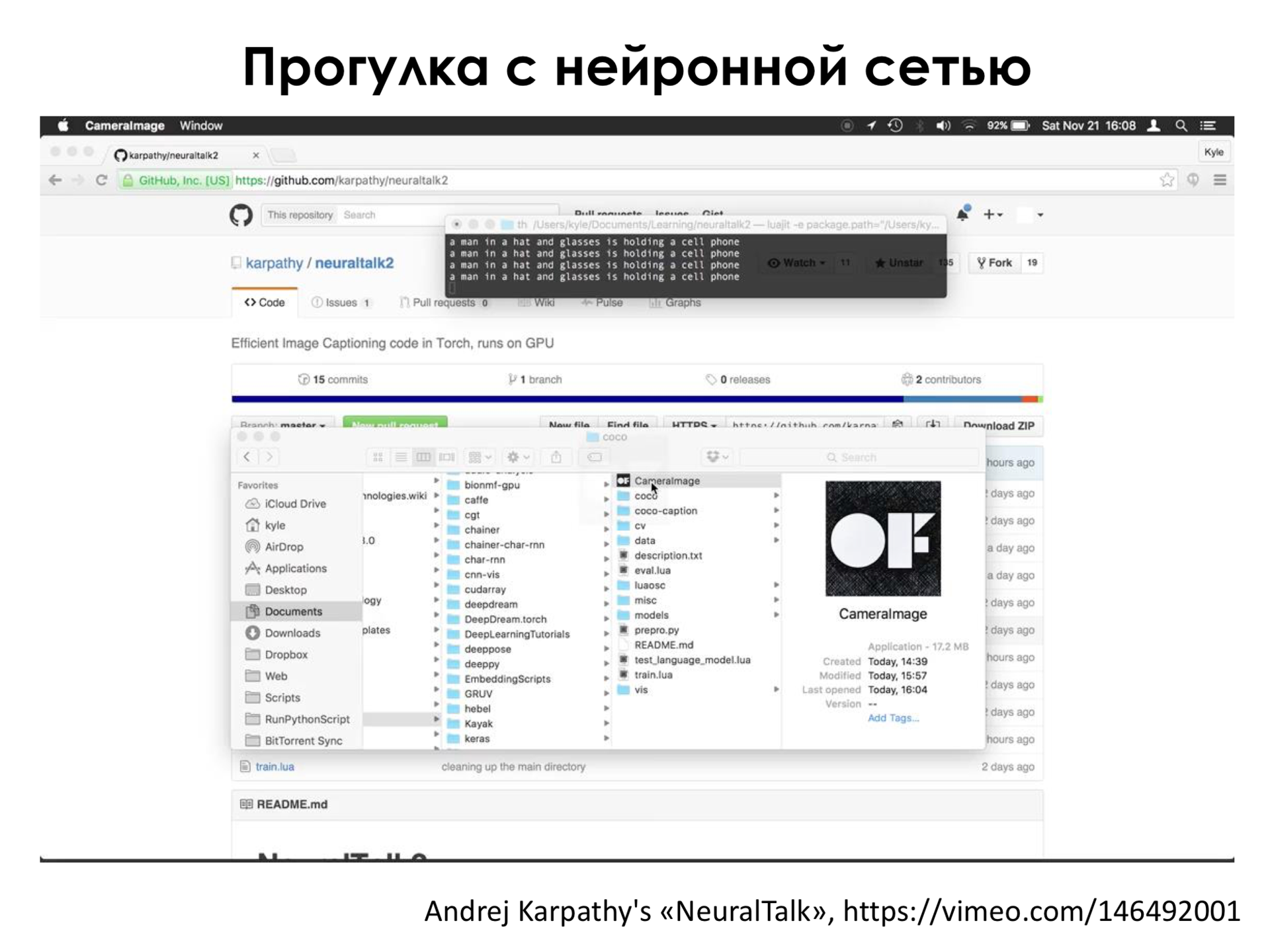
. « ». - . , , « », - , , . , , , , , . , , .
Here, on the left above, the network’s response to what it sees. She says “some person in a sweater”. Generates some phrases. Here she says that this is a sign, she does not understand what is written on it, but she understands that it is a sign. She says that this person walks down the street, some buildings around, a window or a door, an alley, says that there are a lot of bicycles (but this is Amsterdam, there are a lot of bicycles, so she often says that there are bicycles everywhere). He says a white boat is parked. And so on. I would not say that this is a specially prepared image, a person just walks and shoots, and in real time it turns out that the neural network copes with recognizing what a person is shooting.
“And how fast does she recognize it?” And if a person runs, but does not walk, how quickly does she understand?
- It seems to me that just the frame rate is set.
- Yes. In fact, I deceived you a little, because, as far as I remember, this video was shot with post-processing, that is, he took it off, and then drove it locally on the computer through the recognition of this network. But now in many mobile phones there are graphic video cards that are in the computer, only they are smaller, less powerful, but more powerful than processors. And in general, it is possible to recognize something with a small network in real time with some kind of frame sampling, even when you are running, that is, trying to do it. In general, this is possible, and I think that this issue will be less relevant in a few more years, because, as we know, computing capabilities are growing, and, probably, it will someday be possible in real time with the largest networks that to recognize anything.
- In fact, the meaning of this recognition technology on the picture? That is, I myself see.
- Here they tell me - for people with disabilities it makes a lot of sense. Secondly, imagine how the search for images on the Internet. How?
- You told, on these most.
- This is a search for similar images. And, for example, if you go to any server of the type “Yandex. Pictures” ...
- By key words.
- Yes. And at this moment, if we can generate these keywords from a picture, the search will simply be of higher quality. That is, we can find pictures ... Now the search for pictures is mostly based on the textual text. That is, there is some text around the picture. When we put a picture in our index, we say that we have a picture of such a text. When a user enters a query, we try to match words and queries with words in the text. But the text with a little text is a very complicated thing, it is not always relevant to the picture next to it. Many people try to optimize their earnings on the Internet, for example, or something else, and therefore this is not always reliable information.
And if we can safely say that in the picture, it will be very useful.

In this video there were quite dry and short descriptions, that is, we said that “Here the boat is parked somewhere” or “Here is a pile of bicycles lying on the asphalt,” but we can train the network for a slightly different sample, for example, on a sample of adventure novels, and then it will generate very lively descriptions for any pictures. They will not be entirely relevant to these pictures, that is, not to the end, but at least they will be very funny. For example, here a person just goes skiing, and the network says that there was such a person who lived on his own, and he did not know how far he could go, and he was chasing, did not show any signs of weakness. That is such an adventure novel for one picture. This was also done by a group of researchers in response to what they said, "You have some very dry predictions in the picture, somehow the network does not burn." But made the network generate interesting descriptions.

Here, too, if you read, the whole drama about how a person got on a bus, tried to get somewhere and then changed routes, got on a car, found himself in London, and so on.

In fact, we can change these two blocks in our architecture and say that “First, let's put the recurrent network in the first place, which will perceive words, and then some semblance of a convolutional network, which will not compress our image, but rather unclench it. " That is, there is a vector of signs in some space, and we want to generate an image using this vector of signs. And one of my colleagues at Yandex said that “The future is here, only a little blurred so far.” And the future is really here, but slightly blurred. Here you can see that we generate an image by description. For example, on the left above a yellow bus is parked in a parking space. Here, colors are hardly perceived, unfortunately, but, nevertheless, if we replace, for example, the word “yellow” with the word “red” in the same sentence, the color of this spot, which is a bus, will change, that is, it will turn red. And the same thing, if we ask that this is a green bus, then this spot will turn green. He really looks like a bus.
Here is the same thing, that if we change not only the color, but the objects themselves, for example, “a chocolate is lying on the table” or “a banana is on the table”, then we do not directly specify the color of the object, but it’s understandable that chocolate usually brown, and banana usually yellow, and therefore, even without directly specifying the color of the object, our network changes some color of the image.

This is about the same as I said before. For example, a herd of elephants walks through a burned field, across a field with dry grass. And dry grass is usually orange, and green grass is usually green. And here it is clear that some creatures, not very distinguishable, are walking on something green, and here on something orange. Usually these creatures are more than one. If we meet with you in a year or half a year, we will make great progress in this area.
What I would like to say in conclusion is a very interesting topic “A linking of neural networks with reinforcement learning”. Have any of you read what reinforcement training is?
- There is such a thing in psychology.
- In fact, it is connected with psychology. The field “a bundle of neural networks with reinforcement learning” is the most related to biology and psychology area of the study of neural networks.

Imagine that we have a mouse and there is a maze. And we know that at the ends of this labyrinth lies cheese, water, a carrot, and nothing at one end of the labyrinth. And we know that each of these items has some utility for our mouse. For example, a mouse loves cheese, but less like carrots and water, but loves them the same, but she does not like anything at all. That is, if she comes to the end of the maze and sees nothing, she will be very upset.
Imagine that in this simple labyrinth we have only three states in which a mouse can be found - this is S 1 . In the state of S 1 she can make a choice - go left or go right. And in the state of S 2 and S 3, she can also make a choice to go left or go right.
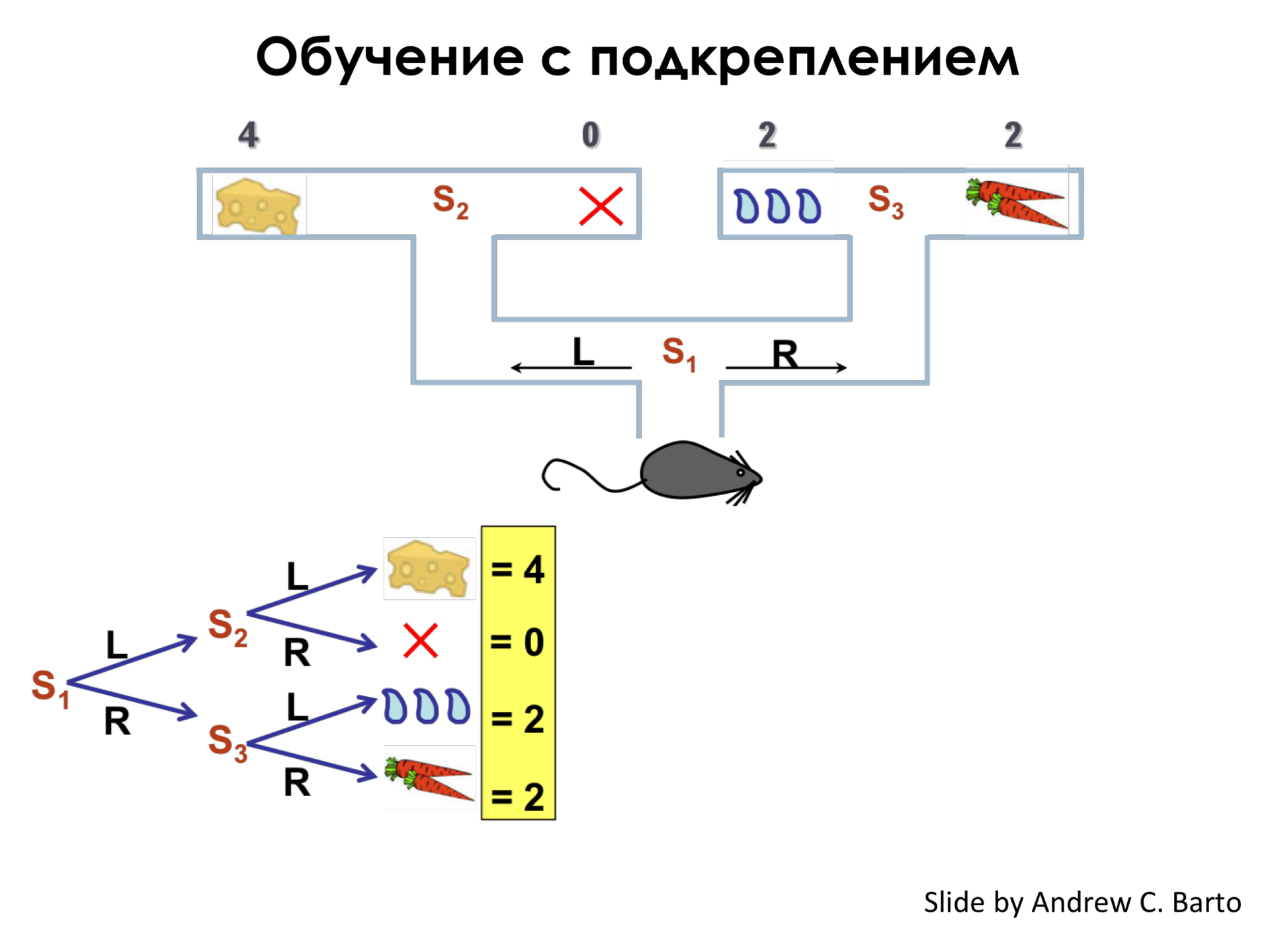
We can set such a wonderful tree, which tells us that if the mouse goes to the left two times, then it will receive some value equal to four conventional units. If she goes to the right, and then it does not matter, to the left or to the right, after the first time she went to the right, and gets the value of two.

And the task of learning with reinforcement in this simplest case is to construct such a function Q, which for each state S in our labyrinth or in some of our environment will say: “If you perform this action, for example, go to the left, then you you can get such a reward. ” It is important for us to be in state S 1 , when we still do not know what will be ahead, for this function to say that "If you go left in this state, you will be able to get a reward 4". Although, if we move from S 1 to S 2 , then we can receive a reward of 0. But the maximum reward that we can receive with the right behavior strategy is 4.

In this formula, it is displayed. Let us imagine that for some of the states we know for all the following states, which can be reached from this, the optimal reward, that is, we know the optimal behavior policy. Then for the current state we can very easily tell what action we need to take. We can simply view all of the following states, say which of the following states we acquire the greatest reward - imagine that we know it, although this is not so in fact - and say that we need to go to the state in which the expected reward more.

There is an algorithm for this function, because for the following states we do not know the optimal policy of behavior.

And this algorithm is quite simple, it is iterative. Imagine that we have this function Q (s, a) .

We have its old value, and we want to update it in some way so that it can more correctly assess the current real world.

What should we do? For all the following states, we must estimate where we can earn the highest maximum, in which of the following states. You see that here it is not the optimal estimate, it is just some approximation of this estimate. And this is the difference between the evaluation of awards in the current state and in the following. What does this mean?
Let us imagine that we have in some state of our environment, for example, we simply take that it is some kind of labyrinth, moreover, with such cells, that is, we are here in this state and we want to find this function Q (S, up ) , that is, to find how much we can get this utility, if we go up.
And, let's say, at the current time, this function is equal to three in our country. And in this state S, which we go to after we’ve left S , let us imagine that if we take max a ' Q (S', a ') , that is, we take the maximum, how much we can get from this state S , it is 5, for example. We obviously have some inconsistencies. That is, we know that from this state we can get a reward of 5, but in this state for some reason we still don’t know it, although if we go up, we can get this reward 5. And in that case we are trying this discrepancy eliminate, that is, take the difference between Q (S, up) = 3 and max (a ') Q (S', a ') = 5 and, thus, at the next iteration we increase the value of this action in that state. And so iteratively we learn.
What is all this for? In this task, to which neural networks had nothing to do initially, it was training with reinforcements, where classical teaching methods were also used, you can also apply them.

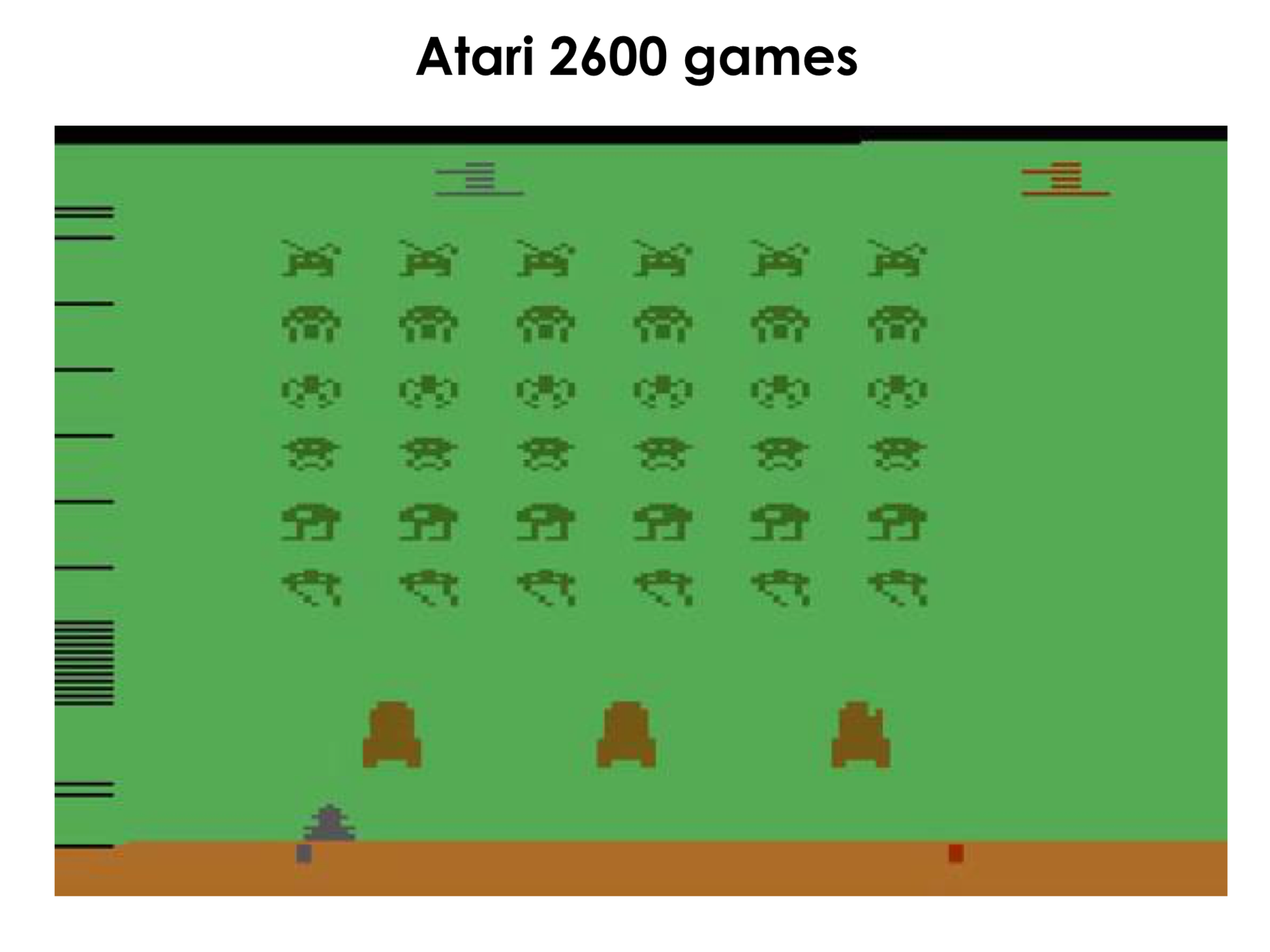
We have Atari games. I'm not sure that any of you played in them, because even I did not play in them. I played them, but already in adulthood. They are very different. The most famous of them, which is located at the bottom left, is called Space Invaders , this is when we have some shuttle, a group of yellow alien invaders approaches us, and we are such a lonely green gun, and we are trying to shoot all these yellow invaders .
There are very simple games like “Ping-pong”, when we have to try not to miss the ball in our own half and make the opponent lose the ball in his own half.
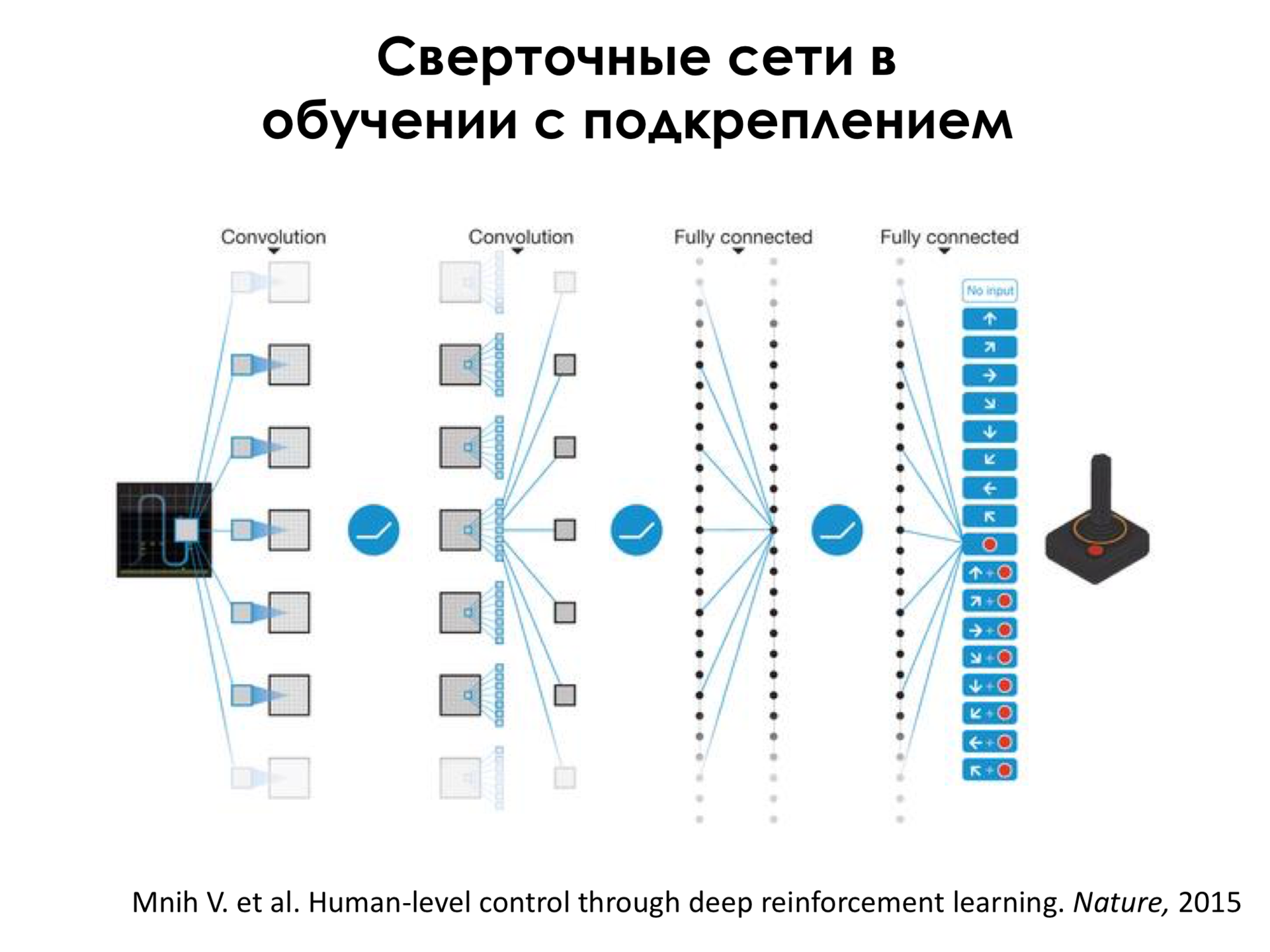
What we can do? We can again take convolutional neural networks, submit the image of the game to the input of these convolutional neural networks and try to get not the class of this image at the output, but what we should do in this game situation, that is, what we should do: leave to the left, shoot, nothing do not and so on.
And if we make such a fairly standard network, that is, there are convolutional layers, layers just with neurons, and we will train it, we will launch it in this environment - and in this environment we must correctly understand that we have an account, and this account is is a reward - if we run in this game and let it learn a little, then we will get a system that can, as I show next, even beat the person.
That is, they are now at a level far above the top man who plays this game. And we see that this game is not very simple, here you need to hide behind these little red things. They protect us. And when we see a blaster flying into us, it’s better to dodge, hide behind them, then crawl back and keep shooting those yellow pixels at the top. It doesn't look very impressive, I feel. But, in fact, to achieve such a breakthrough, it took a lot of work. And I will try to tell you why this is really impressive.
Even before the use of neural networks in this problem, there were many methods that were created specifically for each of these games, and they worked very well. They, too, sometimes beat the person and so on. But, as with the field of image recognition, people had to work very hard to come up with certain winning strategies in this game.
They took every game, for example, Space Invaders or Ping-pong, thought for a long time how to move, thought out some signs, said that if the ball flies at such an angle and at that speed, then we must develop that speed to take it on the opposite side and so that it still bounced uncomfortable for the opponent. And so on. And for each game it had to come up separately. And now they took the same neural network architecture in general, launched it into different games, and in all these games this one architecture, but with different weights - each game had different weights, but the same architecture - she managed to beat almost all of these methods that have been invented for 10–20 years.
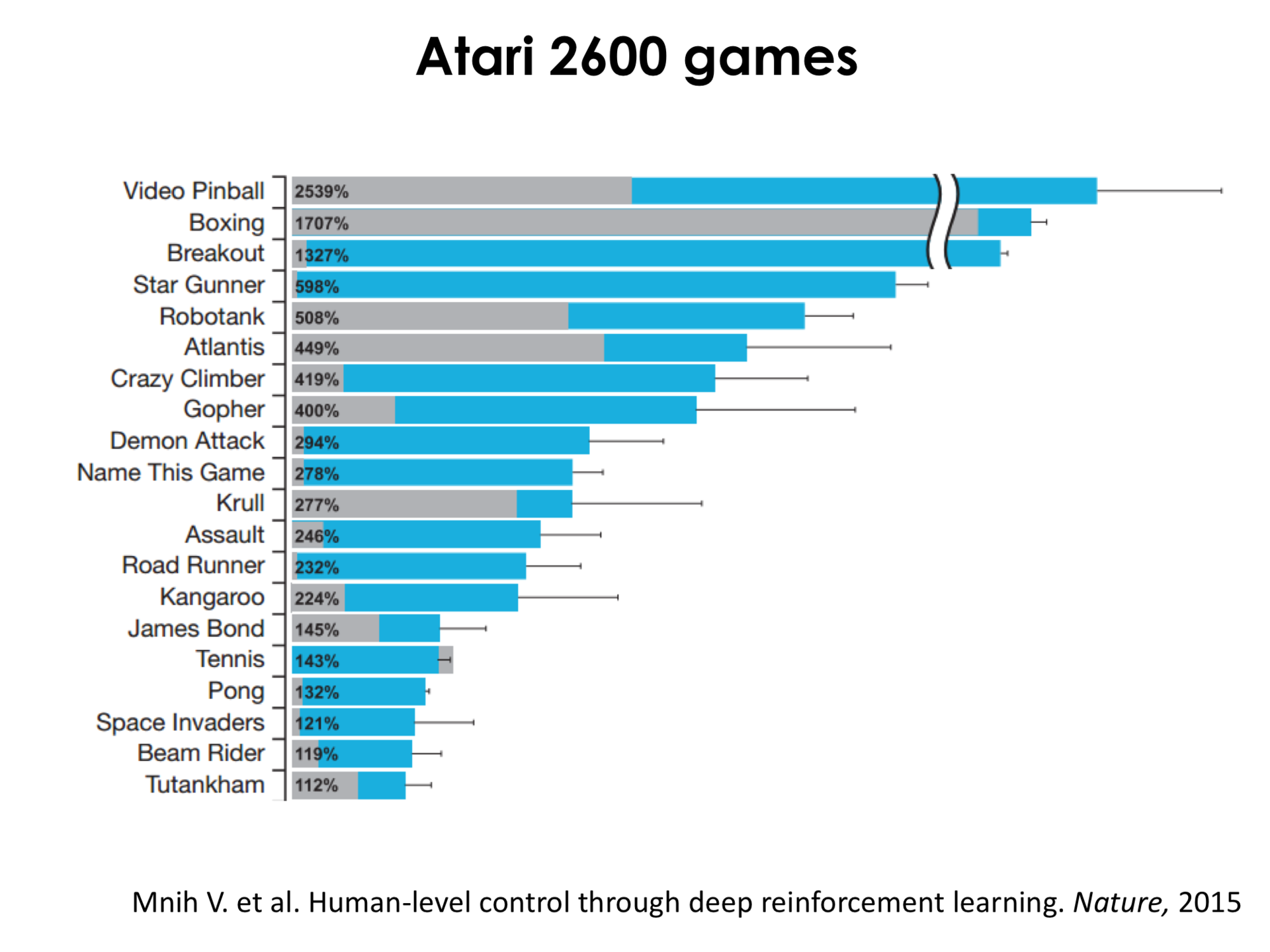
Here, blue is, roughly speaking, how much a point is gained by a neural network, grayishness is a state of the art can up to neural networks, and percentile in bars is how many percent a neural network plays better than a person. That is, we can see, for example, that a pinball neural network plays 2500% better than a person. In boxing, in a variety of games, races, tennis, ping-pong, even in Space Invaders, the neural network plays better than humans. Moreover, we must understand that Space Invaders is a very difficult game. If we look here, then it is here, and this gray one is the state of the art that was before, roughly speaking. Let's just say that he was very bad. This means that this game is very difficult, and with the help of neural networks you can not only bypass it, but also bypass a person.
Actually, I show only the upper part of this diagram, there is still some part of this diagram below, where the neural network success is declining, but now with most new Atari games, the network wins over the human.
Of course, there are very complex games for the network, where you need to have memory, about which I spoke, and there you can also apply recurrent networks, and then the results will significantly improve.
Thanks for attention. I hope you have any questions.
The only thing I wanted to say is that on the Internet there are an insane amount of various materials about neural networks, a lot of materials in the form of scientific articles, which, probably, will be hard to perceive from scratch. But, nevertheless, there are very good tutorials. They are in most cases in English. There is a very good course of Victor Lempitsky in an adult SAD. There is, for example, the second link - the so-called Hackers guide to Neural Networks . This is such a tutorial without mathematics, only with programming. That is, there, for example, in Python, it is shown how to make the simplest networks, how to train them, how to collect samples, and so on. There are so many software tools in which neural networks are implemented, and it is very easy to use them. That is, you, roughly speaking, simply create neurons, create layers, collect a neural network from the bricks and then use it. And I assure you, every one of you can do it - try experimenting. It is very interesting, fun and useful. Thanks for attention.
The material told by our colleague Konstantin Lachman summarizes the history of the development of neural networks, their main features and fundamental differences from other models used in machine learning. We will also discuss specific examples of the use of neural network technologies and their immediate prospects. The lecture will be useful to those who want to systematize in their head all the most important modern knowledge of neural networks.
')
Konstantin klakhman Lakhman graduated from the Moscow Engineering and Physics Institute, worked as a researcher in the neuroscience department of the Kurchatov Institute. In Yandex, he deals with neural network technologies used in computer vision.
Under the cut - detailed decoding with slides.
Neural networks
Hello. My name is Kostya Lachman, and the topic of today's lecture is “Neural Networks”. I work at Yandex in a group of neural network technologies, and we develop all sorts of cool things based on machine learning using neural networks. Neural networks are one of the methods of machine learning, which now attracts quite a lot of attention not only from data analysis specialists or mathematicians, but also generally from people who have nothing to do with this profession. And this is due to the fact that solutions based on neural networks show the best results in the most diverse areas of human knowledge, such as speech recognition, text analysis, image analysis, which I will try to talk about in this lecture. I understand that, probably, everyone in this audience and those who listen to us have a slightly different level of training - someone knows a little more, someone a little less - but you can raise your hands for those who read something about neural networks? This is a very solid part of the audience. I will try to make it interesting for those who have not heard anything at all, and for those who still read something, because most of the studies I’m going to talk about are from this year or the previous year, because there are so many everything happens, and literally half a year goes by, and those articles that were published six months ago, they are already a little outdated.
Let's start. I very quickly just tell you what the task of machine learning as a whole is. I am sure that many of you know this, but to move on, I would like everyone to understand. On the example of the task of classification as the most understandable and simple.
Suppose we have some U - a set of objects of the real world, and for each of these objects we assign some signs of these objects. And also each of these objects has some kind of class that we would like to be able to predict, having attributes of an object. Let's look at this situation on the example of images.
Objects are all images in the world that may interest us.
The simplest attributes of images are pixels. Over the past half century, during which humanity has been engaged in image recognition, much more complex features of images have been invented - but these are the simplest.
And the class that we can relate to each image is, for example, a person (this is a photograph of Alan Turing, for example), a bird, a house, and so on.
The task of machine learning in this case is the construction of a decisive function, which, according to the feature vector of the object, will say to which class it belongs. You had a lecture, as far as I know, Konstantin Vorontsov, who talked about all this much deeper than me, so I am only at the very top.
In most cases, the so-called learning sample is needed. This is a set of examples, about which we know for sure that this object has such a class. And on the basis of this training sample, we can build this crucial function, which makes as few mistakes as possible on the objects of the training set and, thus, expects that we will also have good quality classifications on objects that are not part of the training set.
To do this, we need to introduce some error function. Here D is a learning set, F is a crucial function. And in the simplest case, the error function is just the number of examples in which we are mistaken. And, in order to find the optimal crucial function, we need to understand. Usually we choose a function from some parametric set, that is, it is just some kind of, for example, polynomial equation, which has some coefficients, and we need to somehow pick them up. And the parameters of this function, which minimize this error function, loss function, are our goal, that is, we want to find these parameters.
There are many methods for finding these parameters. I will not go into it now. One of the methods is when we take one example of this function, look, whether we have classified it correctly or incorrectly, and take the derivative with respect to the parameters of our function. As you know, if we go in the direction of the inverse of this derivative, we will thus reduce the error in this example. And, thus, passing all the examples, we will reduce the error by adjusting the parameters of the function.
What I just talked about applies to all machine learning algorithms and to the same extent applies to neural networks, although neural networks have always stood a little apart from all other algorithms.
Now there is a surge of interest in neural networks, but this is one of the oldest machine learning algorithms that you can think of. The first formal neuron, the neural network cell, was proposed, its first version, in 1943 by Warren McCulloch and Walter Pitts . Already in 1958, Frank Rosenblatt proposed the first simplest neural network that could already separate, for example, objects in two-dimensional space. And neural networks went through all this more than half a century history of ups and downs. Interest in neural networks was very large in the 1950s and 1960s, when the first impressive results were obtained. Then neural networks gave way to other machine learning algorithms, which turned out to be stronger at that moment. Again interest resumed in the 1990s, then again went into decline.
And now in the last 5–7 years, it has turned out that in many tasks related to the analysis of natural information, and everything that surrounds us is natural information, this is language, this is speech, this is an image, video, many other very different information, neural networks are better than other algorithms. At least for the moment. Perhaps again the Renaissance will end and something will come to replace them, but now they show the best results in most cases.
What led to this? The fact that neural networks as an algorithm for machine learning, they need to be trained. But unlike most algorithms, neural networks are very critical to the volume of data, to the volume of that training sample, which is necessary in order to train them. And on a small amount of data, the networks simply do not work well. They do not generalize well, they work poorly with examples that they have not seen in the learning process. But in the past 15 years, the growth of data in the world may become exponential, and now this is no longer such a big problem. We have a lot of data.
The second such cornerstone, why now the renaissance of networks is computing resources. Neural networks are one of the most ponderous machine learning algorithms. Huge computational resources are needed to train a neural network and even to use it. And now we have such resources. And, of course, new algorithms were invented. Science does not stand still, engineering does not stand still, and now we understand more about how to train this kind of structure.
What is a formal neuron? This is a very simple element that has some limited number of inputs, a certain weight is attached to each of these inputs, and the neuron simply takes and performs a weighted summation of its inputs. At the entrance may be, for example, the same pixels of the image, about which I told before. Imagine that X 1 and up to X n are just all the pixels of the image. And to each pixel some weight is attached. He summarizes them and performs some non-linear transformation on them. But even if you do not touch the linear transformation, then already one such neuron is a powerful enough classifier. You can replace this neuron and say that it’s just a linear classifier, and the formal neuron is, it’s just a linear classifier. If, say, in a two-dimensional space we have a certain set of points of two classes, and these are their signs of X 1 and X 2 , that is, by selecting these weights V 1 and V 2 , we can build a dividing surface in this space. And thus, if we have this amount, for example, greater than zero, then the object belongs to the first class. If this sum is less than zero, then the object belongs to the second class.
And everything is good, but the only thing is that this picture is very optimistic, there are only two signs, classes, as they say, linearly separable. This means that we can simply draw a line that correctly classifies all the objects in the training set. In fact, this is not always the case, and it is almost never the case. And so one neuron is not enough to solve the vast majority of practical problems.
This is a non-linear transformation that each neuron performs over this sum, it is critically important, because, as we know, if we, for example, perform such a simple summation and say that it is, for example, some new feature Y 1 (W 1 x 1 + W 2 x 2 = y 1 ) , and then we have, for example, a second neuron, which also summarizes the same signs, only this will be, for example, W 1 'x 1 + W 2 ' x 2 = y 2 . If we then want to apply again a linear classification in the space of these features, then it will not make any sense, because two applied linear classifications are easily replaced by one, it is simply a property of linearity of operations. And if we carry out some non-linear transformations on these features, for example, the simplest ... Previously, we used more complex non-linear transformations, such as this logistic function, it is limited to zero and one, and we see that there are sections of linearity. That is, it is about 0 in x behaves quite linearly, like a normal straight line, and then it behaves nonlinearly. But, as it turned out, in order to effectively train classifiers of this kind, the simplest nonlinearity in the world is enough - just a truncated straight line, when in the positive segment it is straight, and in the negative segment it is always 0. This is the simplest nonlinearity, and it turns out that even enough to effectively train the classification.
What is a neural network? The neural network is a sequence of such transformations. F1 is the so-called neural network layer. The layer of a neural network is simply a collection of neurons that work on the same signs. Imagine that we have the initial signs x 1 , x 2 , x 3 , and we have three neurons, each of which is associated with all these signs. But each of the neurons has its own weights, on which it weighs such signs, and the task of training the network in selecting such weights for each of the neurons, which optimizes our error function. And the function F 1 is one layer of such neurons, and after applying the function we get some new feature space. Then we apply another such layer to this feature space. There may be a different number of neurons, some other non-linearity as a transforming function, but these are the same neurons, but with such weights. Thus, consistently applying these transformations, we get the common function F - the transformation function of the neural network, which consists of the sequential application of several functions.
How are neural networks trained? In principle, like any other learning algorithm. We have some output vector, which is obtained at the output of the network, for example, a class, some sort of class label. There is some reference output that we know that these signs should have, for example, such an object, or what number we should attach to it.
And we have some delta, that is, the difference between the output vector and the reference vector, and further on the basis of this delta there is a big formula, but its essence is that if we understand that this delta depends on F n , that is from the output of the last layer of the network, if we take the derivative of this delta by weights, that is, by those elements that we want to train, and the so-called chain rule also applies, that is, when we have derivatives of a complex function, this is the product of the derivative with respect to the function of the function of the parameter it turns out that in such a simple way we can find derivatives for all of our scales and adjust them depending on the error that we observe. That is, if we do not have an error on any particular training example, then, accordingly, the derivatives will be zero, and this means that we classify it correctly and we do not need to do anything. If the error in the training example is very large, then we must do something about it, somehow change the weights to reduce the error.
Convolution networks
Now there was a little mathematics, very superficial. Further, most of the report will be devoted to cool things that can be done with the help of neural networks and that many people in the world, including in Yandex, are doing now.
One of the methods that first showed practical benefits is the so-called convolutional neural networks. What are convolutional neural networks? Suppose we have an image of Albert Einstein. This picture, probably, many of you also saw. And these circles are neurons. We can connect a neuron to all pixels of the input image. But here there is a big problem that if you connect each neuron to all pixels, then, firstly, we will have a lot of weights, and this will be a very computationally capacious operation, it will take a very long time to calculate such a sum for each neuron. second, there will be so many weights that this method will be very unstable to retraining, that is, to effect, when we all predict well on the training set, and we work very poorly on many examples that are not included in the training, simply because we converted to an educational set stiffness We have too many scales, too much freedom, we can very well explain any variations in the training set. Therefore, they invented a different architecture in which each of the neurons is connected only to a small neighborhood in the image. Among other things, all these neurons have the same weights, and this design is called image convolution.
How is it done? Here we have the so-called convolution kernel in the center - this is the set of weights of this neuron. And we apply this convolution kernel in all pixels of the image sequentially. Apply - this means that we simply weigh the pixels in this square on the weights, and get some new value. We can say that we converted the image, walked through it with a filter. As in Photoshop, for example, there are some filters. That is, the simplest filter is how to make black and white from a color picture. And so we went through this filter and got some transformed image.
What is the plus here? The first plus is that less scales, faster to count, less prone to retraining. On the other hand, each of these neurons is produced by some detector, as I will show next. Suppose if somewhere in the image we have an eye, then we are using the same set of weights, traversing the picture, we will determine where the eyes are in the image.
There must be a video here.
And one of the first things to which this architecture was applied is the recognition of numbers as the simplest objects.
Applied it somewhere in 1993, Yang Lekun in Paris, and now there will be almost an archive recording. The quality is so-so. Here they now provide handwritten numbers, press a button, and the network recognizes these handwritten numbers. Basically, she recognizes unmistakably. Well, these numbers are naturally simpler because they are printed. But, for example, in this image the numbers are much more complicated. And these figures, to be honest, even I can not quite discern. There, it seems, the four left, but the network guesses. Even this kind of numbers she recognizes. This was the first success of convolutional neural networks, which showed that they are really applicable in practice.
What are the specific features of these convolutional neural networks? This convolution operation is elementary, and we build the layers of these bundles above the image, transforming further and further the image. Thus, we actually get new signs. Our primary features were the pixels, and then we transform the image and get new signs in the new space, which may allow us to more effectively classify this image. If you imagine the image of dogs, they can be in a variety of poses, in a variety of lighting, on a different background, and it is very difficult to classify them, directly relying only on pixels. And by consistently obtaining a hierarchy of signs of new spaces, we can do this.
This is the main difference between neural networks and other machine learning algorithms. For example, in the field of computer vision, in recognition of images up to neural networks, the following approach was adopted.
When you take a subject area, for example, we need to define between ten classes which object the house, bird, person belongs to, people sat for a very long time and thought what signs could be found to distinguish these images. For example, an image of a house is easy to distinguish if we have a lot of geometric lines that intersect somehow. In birds, for example, there is a very bright color, so if we have a combination of green, red, other signs, then probably it looks more like a bird. The whole approach was to come up with as many such signs as possible, and then submit them to some fairly simple linear classifier, something like this, which actually consists of a single layer. There are also more difficult methods, but, nevertheless, they worked on these signs, which were invented by man. And with neural networks, it turned out that you can just make a training sample, not select any signs, just submit images to it, and she will learn, she will select those signs that are critical for classifying these images due to this hierarchy.
Let's look at what signs a neural network highlights. On the first layers of such a network, it turns out that the network highlights very simple features. For example, gradient transitions or some lines at different angles. That is, it highlights the signs - this means that the neuron reacts if it sees approximately such a piece of the image in the window of its convolution kernel, in the field of view. These signs are not very interesting, we could have come up with them ourselves.
Moving deeper, we see that the network begins to select more complex features, such as circular elements and even circular elements, along with some stripes.
, , . , , , , , , , - .
What is all this for? , Image.net. , . .
. , , , – . , , , , . , -, 300 . , , - , .
, , . , , , . , , . , , , . , – , . , , , - - . , . , , , , . , , , . , , , – . , , , - , – . , .
, , . , . , . . , . , - . , . , - , .
-5 . -5 , , , , , . – . ( 2010-2011 , ) , , , , 30%, 2011 , , , 2012 , , , , , , , – – , . , , , , - 4,5% , 2015 , , , .
, , , , , . , 2013 , , -, 8 9 . , , 2014 , , , , , , .
? , ? , , , - -, , , , , , , . , , , NBA, , .
, , . , . , , .
, , – – , , , , . . , , , , , , , . , « , , , , ». , , . , , , . , , , – - 2014-2015 , .
: , , . What it is?
– – . , , , - , , . . , , , - , , , - , , . , , , , , , , , , . . , , , , , . .
– . x 0 , x 1 , x 2 . . , , , .
? – , . , , , , , , . LaTeX, , . , , , . . , . , , , , , . , . , . , , - . LaTeX , , - .
, , . Linux, , , , , , . , , , , . , . , , , , , , .
, , , . , , . , , . , « », , . , , , . , , , . . , , . . , , , , . , , , . . : , , .
— , ?
— – , - , . .
– , . . . , - , , - , , , 100 – . , , . , 100 – , , , . . - . 50 ., , .
, , , , . .
, , , . .
What is it for? , . , , – , , . , , , , , . – , - , , abstract. , .
, , , . , , , , IT, . , , , , , . , , , - . , , . , - , « -, , , , ?». , , .
, . , , -, , .
+
. , , .
, « ». , , , , . , . , , , , . , , .
. « ». - . , , « », - , , . , , , , , . , , .
Here, on the left above, the network’s response to what it sees. She says “some person in a sweater”. Generates some phrases. Here she says that this is a sign, she does not understand what is written on it, but she understands that it is a sign. She says that this person walks down the street, some buildings around, a window or a door, an alley, says that there are a lot of bicycles (but this is Amsterdam, there are a lot of bicycles, so she often says that there are bicycles everywhere). He says a white boat is parked. And so on. I would not say that this is a specially prepared image, a person just walks and shoots, and in real time it turns out that the neural network copes with recognizing what a person is shooting.
“And how fast does she recognize it?” And if a person runs, but does not walk, how quickly does she understand?
- It seems to me that just the frame rate is set.
- Yes. In fact, I deceived you a little, because, as far as I remember, this video was shot with post-processing, that is, he took it off, and then drove it locally on the computer through the recognition of this network. But now in many mobile phones there are graphic video cards that are in the computer, only they are smaller, less powerful, but more powerful than processors. And in general, it is possible to recognize something with a small network in real time with some kind of frame sampling, even when you are running, that is, trying to do it. In general, this is possible, and I think that this issue will be less relevant in a few more years, because, as we know, computing capabilities are growing, and, probably, it will someday be possible in real time with the largest networks that to recognize anything.
- In fact, the meaning of this recognition technology on the picture? That is, I myself see.
- Here they tell me - for people with disabilities it makes a lot of sense. Secondly, imagine how the search for images on the Internet. How?
- You told, on these most.
- This is a search for similar images. And, for example, if you go to any server of the type “Yandex. Pictures” ...
- By key words.
- Yes. And at this moment, if we can generate these keywords from a picture, the search will simply be of higher quality. That is, we can find pictures ... Now the search for pictures is mostly based on the textual text. That is, there is some text around the picture. When we put a picture in our index, we say that we have a picture of such a text. When a user enters a query, we try to match words and queries with words in the text. But the text with a little text is a very complicated thing, it is not always relevant to the picture next to it. Many people try to optimize their earnings on the Internet, for example, or something else, and therefore this is not always reliable information.
And if we can safely say that in the picture, it will be very useful.
In this video there were quite dry and short descriptions, that is, we said that “Here the boat is parked somewhere” or “Here is a pile of bicycles lying on the asphalt,” but we can train the network for a slightly different sample, for example, on a sample of adventure novels, and then it will generate very lively descriptions for any pictures. They will not be entirely relevant to these pictures, that is, not to the end, but at least they will be very funny. For example, here a person just goes skiing, and the network says that there was such a person who lived on his own, and he did not know how far he could go, and he was chasing, did not show any signs of weakness. That is such an adventure novel for one picture. This was also done by a group of researchers in response to what they said, "You have some very dry predictions in the picture, somehow the network does not burn." But made the network generate interesting descriptions.
Here, too, if you read, the whole drama about how a person got on a bus, tried to get somewhere and then changed routes, got on a car, found himself in London, and so on.
In fact, we can change these two blocks in our architecture and say that “First, let's put the recurrent network in the first place, which will perceive words, and then some semblance of a convolutional network, which will not compress our image, but rather unclench it. " That is, there is a vector of signs in some space, and we want to generate an image using this vector of signs. And one of my colleagues at Yandex said that “The future is here, only a little blurred so far.” And the future is really here, but slightly blurred. Here you can see that we generate an image by description. For example, on the left above a yellow bus is parked in a parking space. Here, colors are hardly perceived, unfortunately, but, nevertheless, if we replace, for example, the word “yellow” with the word “red” in the same sentence, the color of this spot, which is a bus, will change, that is, it will turn red. And the same thing, if we ask that this is a green bus, then this spot will turn green. He really looks like a bus.
Here is the same thing, that if we change not only the color, but the objects themselves, for example, “a chocolate is lying on the table” or “a banana is on the table”, then we do not directly specify the color of the object, but it’s understandable that chocolate usually brown, and banana usually yellow, and therefore, even without directly specifying the color of the object, our network changes some color of the image.
This is about the same as I said before. For example, a herd of elephants walks through a burned field, across a field with dry grass. And dry grass is usually orange, and green grass is usually green. And here it is clear that some creatures, not very distinguishable, are walking on something green, and here on something orange. Usually these creatures are more than one. If we meet with you in a year or half a year, we will make great progress in this area.
Neural networks + reinforcement learning
What I would like to say in conclusion is a very interesting topic “A linking of neural networks with reinforcement learning”. Have any of you read what reinforcement training is?
- There is such a thing in psychology.
- In fact, it is connected with psychology. The field “a bundle of neural networks with reinforcement learning” is the most related to biology and psychology area of the study of neural networks.
Imagine that we have a mouse and there is a maze. And we know that at the ends of this labyrinth lies cheese, water, a carrot, and nothing at one end of the labyrinth. And we know that each of these items has some utility for our mouse. For example, a mouse loves cheese, but less like carrots and water, but loves them the same, but she does not like anything at all. That is, if she comes to the end of the maze and sees nothing, she will be very upset.
Imagine that in this simple labyrinth we have only three states in which a mouse can be found - this is S 1 . In the state of S 1 she can make a choice - go left or go right. And in the state of S 2 and S 3, she can also make a choice to go left or go right.
We can set such a wonderful tree, which tells us that if the mouse goes to the left two times, then it will receive some value equal to four conventional units. If she goes to the right, and then it does not matter, to the left or to the right, after the first time she went to the right, and gets the value of two.
And the task of learning with reinforcement in this simplest case is to construct such a function Q, which for each state S in our labyrinth or in some of our environment will say: “If you perform this action, for example, go to the left, then you you can get such a reward. ” It is important for us to be in state S 1 , when we still do not know what will be ahead, for this function to say that "If you go left in this state, you will be able to get a reward 4". Although, if we move from S 1 to S 2 , then we can receive a reward of 0. But the maximum reward that we can receive with the right behavior strategy is 4.
In this formula, it is displayed. Let us imagine that for some of the states we know for all the following states, which can be reached from this, the optimal reward, that is, we know the optimal behavior policy. Then for the current state we can very easily tell what action we need to take. We can simply view all of the following states, say which of the following states we acquire the greatest reward - imagine that we know it, although this is not so in fact - and say that we need to go to the state in which the expected reward more.
There is an algorithm for this function, because for the following states we do not know the optimal policy of behavior.
And this algorithm is quite simple, it is iterative. Imagine that we have this function Q (s, a) .
We have its old value, and we want to update it in some way so that it can more correctly assess the current real world.
What should we do? For all the following states, we must estimate where we can earn the highest maximum, in which of the following states. You see that here it is not the optimal estimate, it is just some approximation of this estimate. And this is the difference between the evaluation of awards in the current state and in the following. What does this mean?
Let us imagine that we have in some state of our environment, for example, we simply take that it is some kind of labyrinth, moreover, with such cells, that is, we are here in this state and we want to find this function Q (S, up ) , that is, to find how much we can get this utility, if we go up.
And, let's say, at the current time, this function is equal to three in our country. And in this state S, which we go to after we’ve left S , let us imagine that if we take max a ' Q (S', a ') , that is, we take the maximum, how much we can get from this state S , it is 5, for example. We obviously have some inconsistencies. That is, we know that from this state we can get a reward of 5, but in this state for some reason we still don’t know it, although if we go up, we can get this reward 5. And in that case we are trying this discrepancy eliminate, that is, take the difference between Q (S, up) = 3 and max (a ') Q (S', a ') = 5 and, thus, at the next iteration we increase the value of this action in that state. And so iteratively we learn.
What is all this for? In this task, to which neural networks had nothing to do initially, it was training with reinforcements, where classical teaching methods were also used, you can also apply them.
We have Atari games. I'm not sure that any of you played in them, because even I did not play in them. I played them, but already in adulthood. They are very different. The most famous of them, which is located at the bottom left, is called Space Invaders , this is when we have some shuttle, a group of yellow alien invaders approaches us, and we are such a lonely green gun, and we are trying to shoot all these yellow invaders .
There are very simple games like “Ping-pong”, when we have to try not to miss the ball in our own half and make the opponent lose the ball in his own half.
What we can do? We can again take convolutional neural networks, submit the image of the game to the input of these convolutional neural networks and try to get not the class of this image at the output, but what we should do in this game situation, that is, what we should do: leave to the left, shoot, nothing do not and so on.
And if we make such a fairly standard network, that is, there are convolutional layers, layers just with neurons, and we will train it, we will launch it in this environment - and in this environment we must correctly understand that we have an account, and this account is is a reward - if we run in this game and let it learn a little, then we will get a system that can, as I show next, even beat the person.
That is, they are now at a level far above the top man who plays this game. And we see that this game is not very simple, here you need to hide behind these little red things. They protect us. And when we see a blaster flying into us, it’s better to dodge, hide behind them, then crawl back and keep shooting those yellow pixels at the top. It doesn't look very impressive, I feel. But, in fact, to achieve such a breakthrough, it took a lot of work. And I will try to tell you why this is really impressive.
Even before the use of neural networks in this problem, there were many methods that were created specifically for each of these games, and they worked very well. They, too, sometimes beat the person and so on. But, as with the field of image recognition, people had to work very hard to come up with certain winning strategies in this game.
They took every game, for example, Space Invaders or Ping-pong, thought for a long time how to move, thought out some signs, said that if the ball flies at such an angle and at that speed, then we must develop that speed to take it on the opposite side and so that it still bounced uncomfortable for the opponent. And so on. And for each game it had to come up separately. And now they took the same neural network architecture in general, launched it into different games, and in all these games this one architecture, but with different weights - each game had different weights, but the same architecture - she managed to beat almost all of these methods that have been invented for 10–20 years.
Here, blue is, roughly speaking, how much a point is gained by a neural network, grayishness is a state of the art can up to neural networks, and percentile in bars is how many percent a neural network plays better than a person. That is, we can see, for example, that a pinball neural network plays 2500% better than a person. In boxing, in a variety of games, races, tennis, ping-pong, even in Space Invaders, the neural network plays better than humans. Moreover, we must understand that Space Invaders is a very difficult game. If we look here, then it is here, and this gray one is the state of the art that was before, roughly speaking. Let's just say that he was very bad. This means that this game is very difficult, and with the help of neural networks you can not only bypass it, but also bypass a person.
Actually, I show only the upper part of this diagram, there is still some part of this diagram below, where the neural network success is declining, but now with most new Atari games, the network wins over the human.
Of course, there are very complex games for the network, where you need to have memory, about which I spoke, and there you can also apply recurrent networks, and then the results will significantly improve.
Thanks for attention. I hope you have any questions.
The only thing I wanted to say is that on the Internet there are an insane amount of various materials about neural networks, a lot of materials in the form of scientific articles, which, probably, will be hard to perceive from scratch. But, nevertheless, there are very good tutorials. They are in most cases in English. There is a very good course of Victor Lempitsky in an adult SAD. There is, for example, the second link - the so-called Hackers guide to Neural Networks . This is such a tutorial without mathematics, only with programming. That is, there, for example, in Python, it is shown how to make the simplest networks, how to train them, how to collect samples, and so on. There are so many software tools in which neural networks are implemented, and it is very easy to use them. That is, you, roughly speaking, simply create neurons, create layers, collect a neural network from the bricks and then use it. And I assure you, every one of you can do it - try experimenting. It is very interesting, fun and useful. Thanks for attention.
Source: https://habr.com/ru/post/307260/
All Articles