The intersection of the muzzles of top domains 1,000,000 by N-grams
The task of the study is to visualize the duplication of the main pages of domains using five-word shingles within the framework of a common base.


')

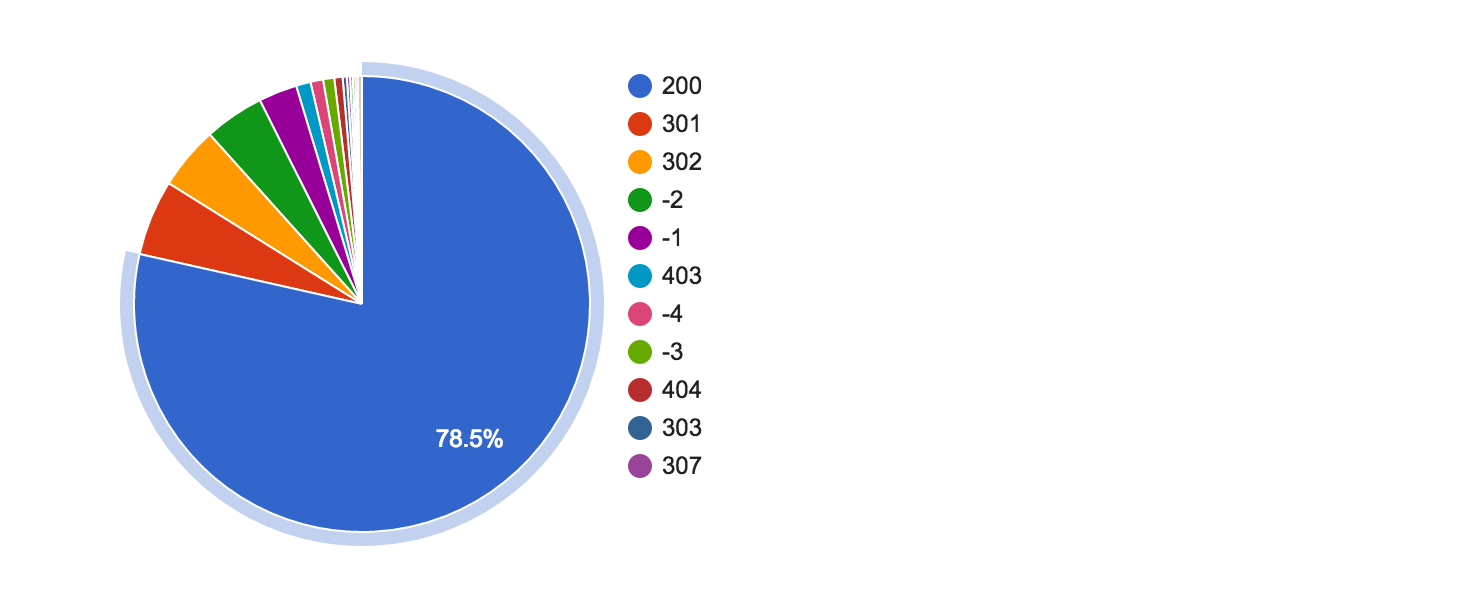
588,086,318 shingle were found on the content pages.
We add each shingle with additional information in top1m_shingles dataset :
shingle , domain , position , count_on_page
At the output, we have a shingle_w table of 476,380,752 unique n-grams with weights.
We add the weight of the shingle within the base to the source dataset:
If the resulting dataset is grouped by documents (domains) and the values of n-grams and positions are compiled, we will get a weighed label for each domain.
We enrich on_page with indicators, averages, calculate UNIQ RATIO for each document (as the ratio of the number of unique shingles within the base to non-unique), display n-grams, generate a page :


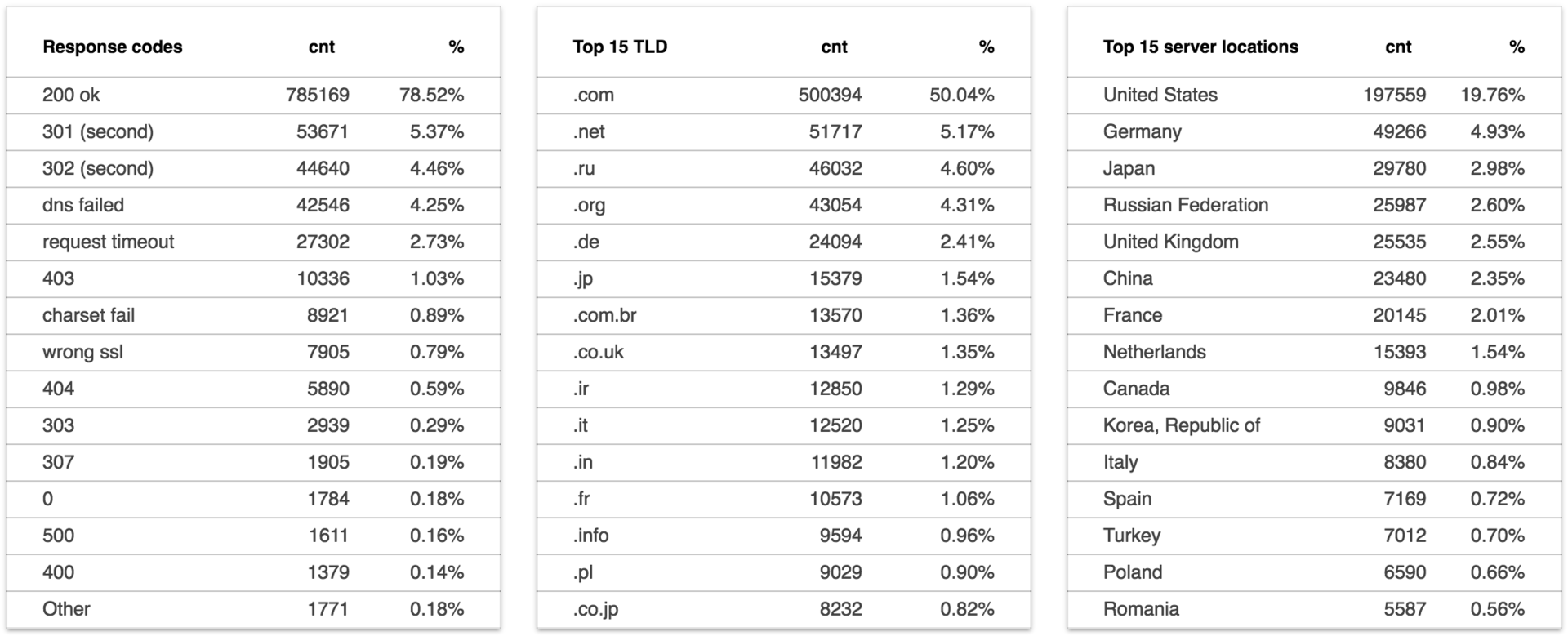
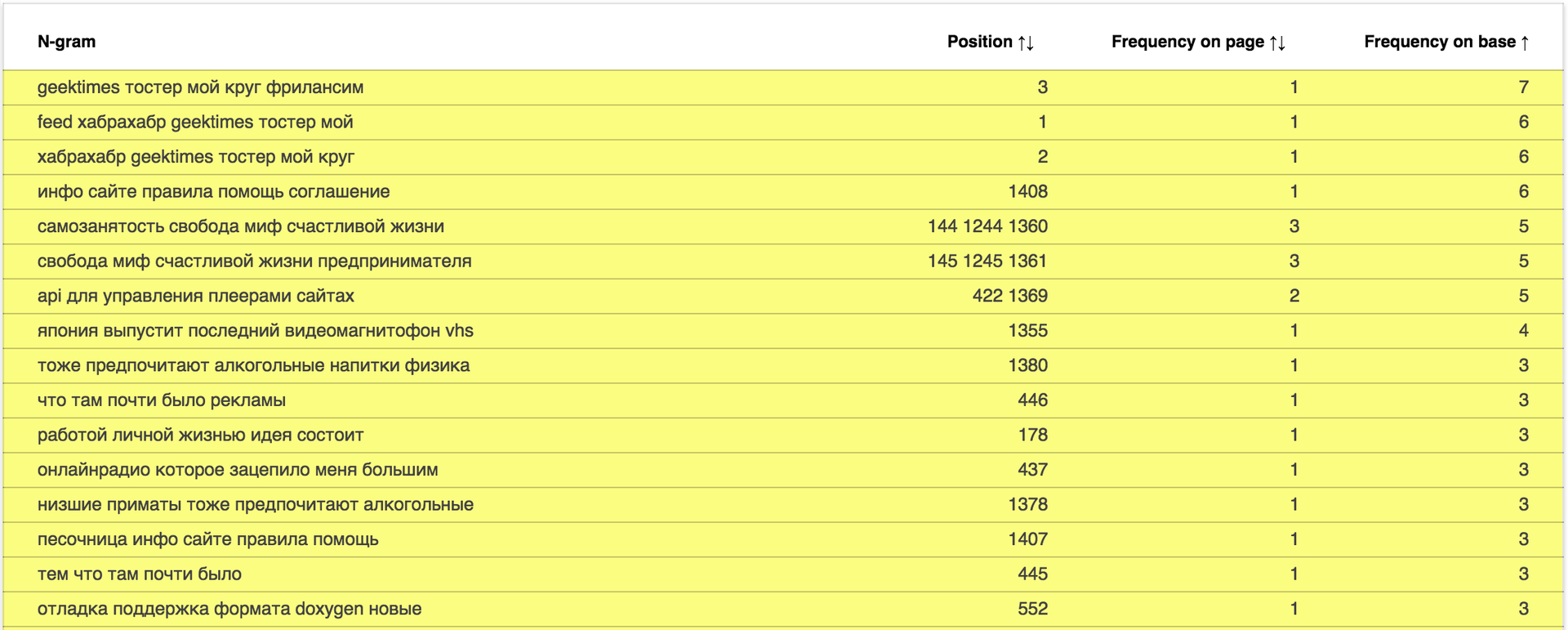
The report is available at: data.statoperator.com/report/habrahabr.ru and contains a complete table with shiglov texts and their values. Shingles are not originally sorted. If you want to view them in the order in which they went in the document - sort the table by position. Or in frequency in the database, as in the image:
We change the domain in urla or enter in the search form and look at the report on any domain from the list of Alexa top 1M.
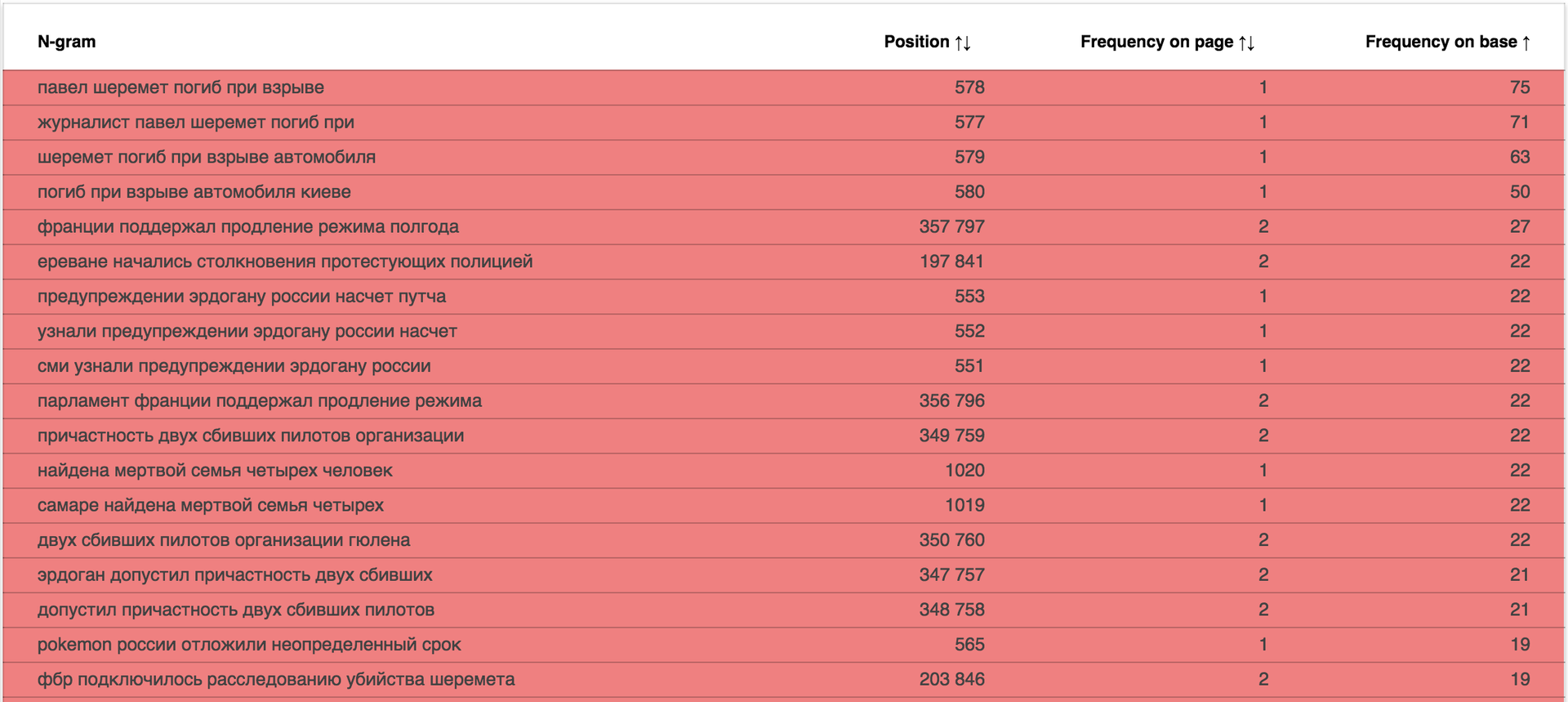
It is interesting to look at news sites: data.statoperator.com/report/lenta.ru
Data Collection: 2016-07-21
Date of report generation: 2016-07-27
Run the crawler
')
We retrieve the text, we delete garbage, we generate five-word shingly
588,086,318 shingle were found on the content pages.
We add each shingle with additional information in top1m_shingles dataset :
shingle , domain , position , count_on_page
Calculate n-grams
SELECT shingle, COUNT(shingle) cnt FROM top1m_shingles GROUP BY shingle At the output, we have a shingle_w table of 476,380,752 unique n-grams with weights.
We add the weight of the shingle within the base to the source dataset:
SELECT shingle, domain, position, count_on_page, b.cnt count_on_base FROM top1m_shingles AS a JOIN shingles_w AS b ON a.shingle = b.shingle If the resulting dataset is grouped by documents (domains) and the values of n-grams and positions are compiled, we will get a weighed label for each domain.
We enrich on_page with indicators, averages, calculate UNIQ RATIO for each document (as the ratio of the number of unique shingles within the base to non-unique), display n-grams, generate a page :
The report is available at: data.statoperator.com/report/habrahabr.ru and contains a complete table with shiglov texts and their values. Shingles are not originally sorted. If you want to view them in the order in which they went in the document - sort the table by position. Or in frequency in the database, as in the image:
We change the domain in urla or enter in the search form and look at the report on any domain from the list of Alexa top 1M.
It is interesting to look at news sites: data.statoperator.com/report/lenta.ru
Average page uniqueness: 82.2%
Data Collection: 2016-07-21
Date of report generation: 2016-07-27
Source: https://habr.com/ru/post/307250/
All Articles