How many neurons do you need to find out if the Alexander Nevsky Bridge is divorced?

Introduction
That week darkk described his approach to the problem of recognizing the state of a bridge (reduced / divorced).
The algorithm described in the article used computer vision techniques to extract features from pictures and fed them logistic regression to estimate the likelihood that the bridge is collapsed.
In the comments, I asked to post pictures so that you can play yourself. darkk responded to the request, for which he thanks a lot.
In the past few years, neural networks have gained a strong popularity, as an algorithm that manages to automatically extract features from data and process them, and this is done so simply from the point of view of who writes the code and such high accuracy is achieved that in many tasks ( ~ 5% of all tasks in machine learning) they tear competitors into the British flag with such a margin that other algorithms are not even considered. One of these successful areas for neural networks is image manipulation. After convincing victory of convolutional neural networks at the ImageNet competition in 2012, the public in academic and not-so-rounder circles got so excited that scientific results, as well as software products in this direction, appear almost every day. And, as a result, in many cases it became very simple to use neural networks and they turned from “fashionable and youth” into an ordinary tool used by machine learning experts, and simply everyone.
Formulation of the problem.
darkk posted images of the Alexander Nevsky Bridge in St. Petersburg. 30k + in raised position, 30k + in lowered position, 9k + in intermediate position.
The task we are trying to solve: using images from a static camera, which is aimed at the Alexander Nevsky Bridge at different times of day, night, and season, determine the probability that the bridge belongs to the classes (raised / lowered / process). I will work with the classes raised / lowered for reasons that this is important from a practical point of view.
Neural networks can solve quite complex tasks with images, noisy data, in conditions when there is very little data for training and other exotics (For example, this is a problem about distracted drivers or this one about nerve segmentation . But! The task of classification is on balanced data, there is enough data and the object of classification practically does not change - for neural networks, and indeed for machine learning tasks - this is somewhere between simple and very simple, which darkk demonstrated using rather simple and inactive A conceptualized combination of computer vision and machine learning.
The task that I will try to solve is to evaluate what neural networks can offer on this issue.
Data preparation.
Despite the fact that the neural networks are sufficiently resistant to noise, nevertheless, slightly clean the data - it never hurts. In this case, it is to crop the picture so that there is at the maximum of the bridge and at the minimum of everything else.
It was in this way:

And it became like this:

You also need to divide the data into three parts:
- train
- validation
- test
train - May 19 - July 17
validation - July 18, 19, 20
test - July 21, 22, 23
Actually, on this the preparation of images is over. Trying to isolate the lines, angles, some other signs are not necessary.
Training model
We define a simple convolutional network in which the convolutional layers extract features, and the last layer tries to answer our question.
(I’ll use Keras with Theano as a backend simply because it's cheap and good-tempered .)
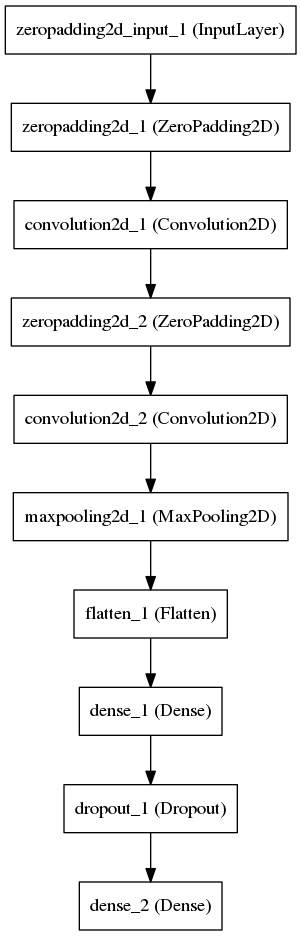
We have a fairly simple task, a simple network structure with a small number of free parameters, so the network converges remarkably. All pictures can be shoved into memory, but I don’t want to, so we will train to read pictures from a disk in batches.
The training process looks something like this:
Using Theano backend. Using gpu device 0: GeForce GTX 980 Ti (CNMeM is disabled, cuDNN 5103) Found 59834 images belonging to 2 classes. Found 6339 images belonging to 2 classes. [2016-08-06 14:26:48.878313] Creating model Epoch 1/10 59834/59834 [==============================] - 54s - loss: 0.1785 - acc: 0.9528 - val_loss: 0.0623 - val_acc: 0.9882 Epoch 2/10 59834/59834 [==============================] - 53s - loss: 0.0400 - acc: 0.9869 - val_loss: 0.0375 - val_acc: 0.9880 Epoch 3/10 59834/59834 [==============================] - 53s - loss: 0.0320 - acc: 0.9870 - val_loss: 0.0281 - val_acc: 0.9883 Epoch 4/10 59834/59834 [==============================] - 53s - loss: 0.0273 - acc: 0.9875 - val_loss: 0.0225 - val_acc: 0.9886 Epoch 5/10 59834/59834 [==============================] - 53s - loss: 0.0228 - acc: 0.9896 - val_loss: 0.0182 - val_acc: 0.9915 Epoch 6/10 59834/59834 [==============================] - 53s - loss: 0.0189 - acc: 0.9921 - val_loss: 0.0142 - val_acc: 0.9961 Epoch 7/10 59834/59834 [==============================] - 53s - loss: 0.0158 - acc: 0.9941 - val_loss: 0.0129 - val_acc: 0.9940 Epoch 8/10 59834/59834 [==============================] - 53s - loss: 0.0137 - acc: 0.9953 - val_loss: 0.0108 - val_acc: 0.9964 Epoch 9/10 59834/59834 [==============================] - 53s - loss: 0.0118 - acc: 0.9963 - val_loss: 0.0094 - val_acc: 0.9979 Epoch 10/10 59834/59834 [==============================] - 53s - loss: 0.0111 - acc: 0.9964 - val_loss: 0.0083 - val_acc: 0.9975 [2016-08-06 14:35:46.666799] Saving model [2016-08-06 14:35:46.809798] Saving history [2016-08-06 14:35:46.810558] Evaluating on test set Found 6393 images belonging to 2 classes. [0.014433901176242065, 0.99405599874863126] ... Or in the pictures:

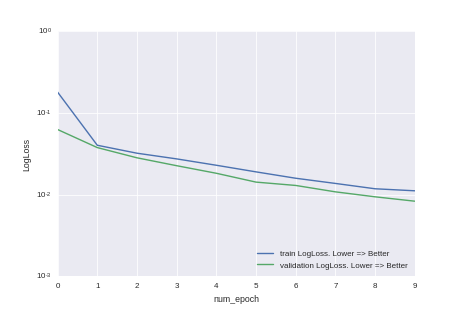
It can be seen that we have not tested and the accuracy of the model can be improved simply by increasing the training time. But, as careless teachers like to say in universities, this is a homework for those who wish.
Estimation of prediction accuracy
Numerical
Accuracy assessment will be made on July 21-23.
accuracy_score = 0.994
roc_auc_score = 0.985
log_loss_score = 0.014
Visual

The green line is what is marked in the pictures.
The blue line is the running average of the previous 20 predictions.
What is behind the scenes.
Why when training a model, the accuracy on val is better than on train. Answer: => because on train - this precision is with a dropout, but on val - not
Why was chosen such a model architecture. Answer => I would like to say: “But this is obvious!”, But the correct answer is probably all the same - we read the lecture notes at http://cs231n.imtqy.com/ , we watch a series of lectures at https://www.youtube .com / watch? v = PlhFWT7vAEw and chasing competitions on kaggle.com until the insight comes as an answer: "This architecture was chosen because it works on very similar MNIST tasks"
On which pictures the model gives an error. Answer: => I looked with one eye - these are the pictures where a person cannot be distinguished simply because the camera did not work. Perhaps there are adequate images in which the model gives an error, but it requires a more thoughtful analysis.
Where to get the code from all of the above? Answer => https://github.com/ternaus/spb_bridges
Will the model work on other bridges? Answer => it is possible, but who knows, you have to try.
And if the task was this: According to the images of the Alexander Nevsky Bridge to create a model to predict the dilution of the Foundry Bridge, would you act the same way? Answer => No. They have a different lifting system, so there they had to look at the data, try and think. The question of correct cross validation would be very acute. In general, this would be an interesting task.
And if you do not crop the image, so that only the bridge remains, then the task would become much more difficult? Answer => Would, but not much.
And what if the classification is not done in two classes (reduced / divorced), but in three (reduced / divorced / in motion)? Answer => If we classify into three classes, we get an estimate of belonging to one of the three classes. But you need to change a few lines in the file that divides the data into parts, and one in the definition of the model. => Homework for enthusiasts.
An example of a complex task, on which it is necessary to break the brain, to make the model work well => Answer: Right now I’ll finish the text, brush my github c code. and start thinking about segmentation of the nerves in the images.
Where can I get pictures of bridges? Answer: => This is to darkk
- How many neurons do you need to find out if the Alexander Nevsky Bridge is divorced? Answer: => And one neuron, that is, the logistic regression will produce a remarkable result.
Afterword.
This is indeed a very simple task for neural networks at this stage of development of this direction in machine learning. And here even non-neural networks, but also simpler algorithms will work with a bang. The advantage of neural networks is that they work in the mode of automatic extraction of signs, in the presence of a large amount of noise, and on some types of data, for example, when working with images, they give accuracy at the level of State Of The Art. And with this text with the attached code I tried to dispel the opinion that working with neural networks is very difficult. No, it is not. Working with neural networks so that they show good accuracy on complex tasks is difficult, but many tasks do not fall into this category and the threshold for entering this area is not as high as it may seem after reading news on popular resources.
')
Source: https://habr.com/ru/post/307218/
All Articles