How do Fault Tolerant servers differ from “consumer” consumer goods in a specific example?

"Mirror" cluster with synchronous computing processes, front view
So far, the entire Internet is screaming about our domestic hard drive for as many as 50 megabytes weighing 25 kilograms, not really understanding that this thing can survive two nuclear wars at the bottom of the pool, I will tell you about serious fault-tolerant servers and their differences from the usual iron. Fortunately, we just received such tests for testing, and there was an opportunity to make fun of them.
These solutions are especially interesting for admins. The fact is that they are protected not physically - by covers, fault-tolerant interfaces or something else, but at the level of the computing architecture.
')
We got into the hands of the flagship ftServer 6800 from Stratus. This is a case with two identical computing nodes united in one cluster, and both its halves work synchronously and make the same “mirror”. This is a good old "space" architecture, when the computational process goes through two independent hardware paths at once. If there is a bug somewhere (not related to the curvature of the code), then one of the results will definitely reach the goal. This is important for critical systems in various areas from banking to medicine, and this is very important where there is “silent data loss”. That is, where processors bugs rise up to their full height, due to the fact that the crystals are still unique and there are no two identical machines in nature. Usually this does not manifest itself, but on responsible tasks it is necessary to protect against the accidental influence of interference and possible more obvious problems. Therefore, that's how it is done.
The most important:
- Computational processes are duplicated. Components look for the OS, as one device. Failover takes place at the driver level. There is no CPU synchronization loss, but there is overhead related to HDD replication.
- Declared availability of 99,999 on Linux, Win and VMware. From the nines dazzled in his eyes, and therefore we undertook to check this statement (as far as possible).
How it works
One of the cluster nodes will always be the master (Primary), and the other slave (Secondary). This approach to building due to the high requirements for resiliency (99,999), the technology is proudly called DMR (Dual Modular Redundancy). Both nodes of the cluster synchronously perform operations and if one of the nodes is lost, they will instantly failover to the rest of the work.
Each of the nodes is divided into two more modules (Enclosure):
- CPU Enclosure - a module that includes a CPU and RAM;
- IO Enclosure is a module dedicated to PCIe, a RAID controller (with disks) and embedded NICs.
The Stratus engineers came to the division into two modules because of the different approaches to synchronizing the devices they contain:
- For CPU Enclosure, Lockstep technology is used (step by step). It guarantees that the components of these two modules will work synchronously and are in the same condition, which means that failover will always be successful.
- Lockstep cannot be used for IO Enclosure due to the presence of a large number of heterogeneous devices. RAID controllers from both halves of the cluster are replicated by combining disks located in the same slots (in pairs). NICs when using Windows (Intel PROset driver) work in one of the following modes: AFT, ALB, SFT, etc., thus the Primary node of the Secondary node is accessible to the node - a total of 8 pieces. If Linux or ESXi is deployed, the NICs are assembled in bonding, that is, the ports are paired with the common MAC address (by analogy with the disks). For third-party HBAs, if the Primary device fails, it will switch to a healthy one. USB, located on the halves themselves, are not subject to synchronization. This problem is solved by common ports VGA, USB and COM, soldered on a passive backplane. They automatically switch to the active half in case of a crash, which means you do not have to switch your usual monitor with the mouse and keyboard to the ports of the new Primary node.
To manage the clustering, a separate ASIC is used - Stratus Albireo, named after the binary system of the star (romance). This controller is located in each of the compute nodes. He is responsible for synchronizing both nodes through a passive backplane, as well as for detecting faults.
The connection between the compute node modules is organized according to the full mesh scheme. Thus, we get a very flexible and fault-tolerant system: this layout allows the Primary node to see backup devices and in which case, for example, put the node's Secondary into the IO enclosure operation.

The topology of relationships between components of cluster nodes.
Stratus Albireo also ensures that the data streams received from both nodes are identical. If there are discrepancies, the system will identify the cause and try to fix the failure. If the error has been resolved (the error type is correctable), the MTBF (Mean Time Between Failures) counter will increase by 1, and if not, this element will be disabled (the error type is uncorrectable). Error counting is carried out for the main components of each of the cluster nodes: CPU, RAM, HDD, IO devices. Due to the accumulation of statistics, the controller can proactively signal the imminent breakdown of one or another component.
- To operate the OS on this non-standard solution, Stratus uses special drivers divided into two classes:
- "Enhanced" drivers, developed in conjunction with the vendor. They are called “enhanced” because they are subjected to a series of tests for stability and compatibility.
- An additional virtual driver that forces the OS to see a pair of devices spaced across two compute nodes as one device, which ensures transparent failover.
To manage the cluster and initialize the OS, the Stratus Automated Uptime Layer software package is used (it has its own for each OS), and it is directly connected to Stratus Albireo (without it, the cluster will not work correctly). On the types of this software and its capabilities, we describe below.
Specifications
FtServer 6800 is positioned as a solution for databases and high-load applications. For those who need something simpler, there are two more models: ftServer 2800 and ftServer 4800.
Characteristic | ftServer 2800 | ftServer 4800 | ftServer 6800 |
Logical processor (per cluster node) | 1 socket | 1 socket | 2 sockets |
Processor type | Intel Xeon processor E5-2630v3, 2.4 GHz | Intel Xeon processor E5-2670v3, 2.3 GHz | Intel Xeon processor E5-2670v3, 2.3 GHz |
Supported amount of RAM | From 8 GB to 64 GB DDR4 | 16 GB to 256 GB DDR4 | From 32 GB to 512 GB DDR4 Up to 1 TB for VMware |
Type of supported drives | 12 Gb / s SAS 2.5 " | 12 Gb / s SAS 2.5 " | 12 Gb / s SAS 2.5 " |
10/100/1000 Ethernet ports (per cluster node) | 2 | 2 | 2 |
10 Gb Ethernet ports (per cluster node) | Not | 2 | 2 |
Integrated PCIe G3 buses (per cluster node) | 2x4 PCIe | 2x4 PCIe | 2x4 PCIe 2x8 PCIe |
Additional PCIe bus (per cluster node) | Not | 2 x 8 PCIe | Not |
In our cluster installed: Intel Xeon processor E5-2670v3, 2.3 GHz (2 pcs.), DDR4 32 GB, 2133 MHz, 512 GB, 400 GB SSD (1 pc.), 300 GB 15k HDD (2 pcs.), 1.2 TB 10k HDD (1 pc.), FC 16 Gb 1 port.
The configuration meets the current performance requirements, and a special version is available for VMware, which is distinguished by a doubled RAM size - 1 TB. Someone will say that now the standard for rack-servers is 2-3 TB of RAM, but you need to understand that the FT cluster is a solution, sharpened primarily under the protection of a certain system, the mechanism of which imposes its limitations.
Here is a rear view:

Separately, about the display, it is quite simple and understandable even without instructions:
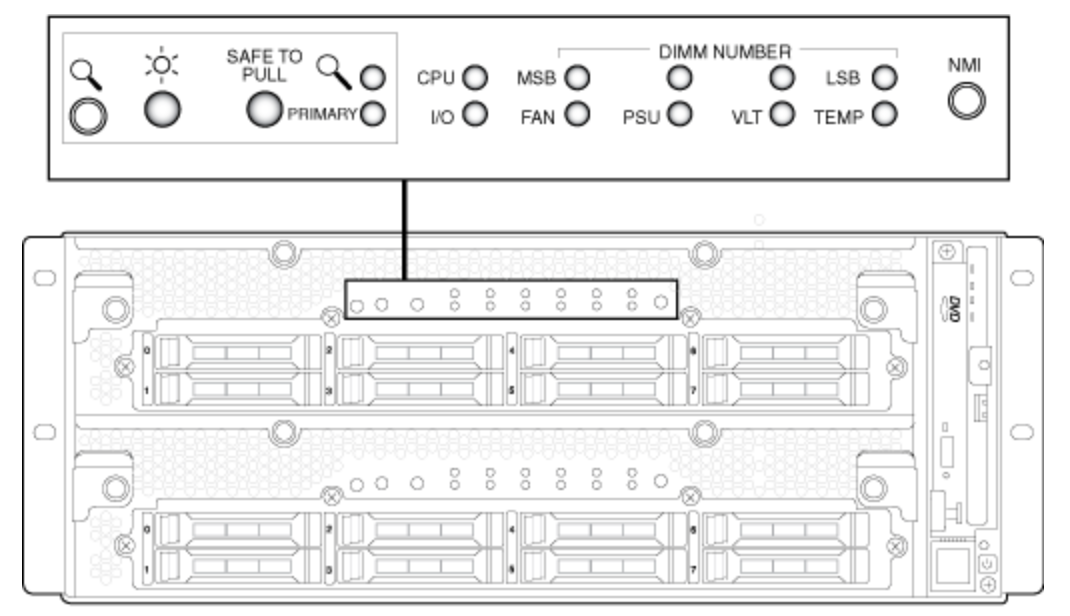
On the front panel are the main indicators responsible for the key elements of the nodes.
But we should care about all three:
- “Sunny” - power is connected, this node is working;
- Primary - indicates which of the given cluster nodes is the leading one;
- Safe to Pull - if it is flashing, you cannot remove the cluster node, and if it is just burning, you can safely pull it out.
The display is fully visible only when the decorative panel is removed. If it is returned in place, then we receive information only about the general state of the system, as well as whether the cluster nodes are synchronized or not.
The chassis is a 4U box, which is divided into two main sections (allocated for cluster nodes) 2U each and one additional vertical section 4U high, in which the management module expander is connected to the QPI bus (clearly visible on the right in Figure 1 ). With it, we get the usual set: DVD drive, USB port (three more are located at the back), VGA, COM port and even a modem, also it has a button for turning the server on and off under the cap, protecting it from being accidentally pressed.
Initially, we were confident that the management module itself was in the expander, but this theory was debunked by an empirical method: despite extracting the expander from the chassis, we were able to successfully access the BMC (Baseboard management controller). Later, when studying the cluster, it turned out that the BMC modules are located in the cluster nodes themselves.
Extract one of the nodes and look at it closer. To do this just will not work, for this you need to unplug the power cord, which holds the crossbar-lever (the first line of defense from accidental disconnection-extraction) and unscrew the two bolts in front. It is noteworthy that because of this crossbar, the power supply unit “for hot” cannot be changed, you need to pull out the cluster node completely.

Removing a cluster node. Step 1.

Removing a cluster node. Step 2.
After these manipulations, the chassis will allow you to push the cluster node only half, for a complete extraction, we will need to press the lever.

Removing a cluster node. Step 3.
After we got hold of the server, let's proceed to inspect what is inside.

Cluster node
There are no complaints about the assembly of the node itself. Everything was done qualitatively and without obvious flaws.
The placement of elements and cabling of the HDD and two USB 3.0 (hi PC) backplanes are laconic and do not cause any negative. It is also worth paying attention to the thickness of the metal case: here it is thick, as in those Compaq servers. The main elements of the body are attracted by screws with a washer-grower, which means that they are unlikely to spin out due to vibration. Stratus engineers obviously wanted to show that the cluster is designed for high computational and physical loads.
We can not fail to note an interesting find, namely, a significant amount of NEC company logos inside a non-NEC server. And indeed, they are there for a reason. As we managed to find out, Stratus has a contract with NEC for the production of servers, and NEC buys software (OEM) from Stratus. Therefore, if you go to the NEC site, you can catch a sickly deja vu. According to Stratus himself, only with the purchase of server hardware from them do you get the latest software, which is quite logical.
Failover Cluster Management
Let us turn to the software, namely, to the management interface of the BMC (for Stratus, it is proudly called the Virtual Technician Module). It looks rustic:


VTM interface
On the other hand, all the main functionality is present: we can get access to KVM, and ISO to mount, and even to know the status of main components.
The lower part of the management console is interesting, it displays the status of both cluster nodes, BIOS codes (at boot time), the number of users logged into each of the VTMs, the role of nodes in the cluster, as well as the Safe to Pull status.

It's funny that if you go to the Secondary cluster node, then the graphical console disappears from the functional, and you can turn off the cluster, but you can’t see what's going on on the monitor.
It is worth adding that it is not possible to disable one of the cluster nodes separately or to decommission some of its elements using VTM. To do this, in the case of vSphere, deploy an appliance on the cluster itself (ftSys virtual machine), and install a software package using Windows or Linux. Moreover, for Windows, a software module is a GUI application (ftSMC), and for Linux it works only in command line mode and almost completely duplicates the appliance functionality for vSphere. It is important to note that the installation of these software packages (OS module, appliance) is mandatory, since they are also responsible for the initial configuration of the OS or hypervisor to work on the cluster hardware, as well as working out a failover. That is, if you do not install and configure these modules, at the right time the cluster simply does not work out the emergency switching.
We were interested in a bunch of Stratus FT and vSphere, so the discussion below will deal specifically with appliance. FtSys itself consists of two parts: a web interface from which you can monitor the status of the entire cluster and any of its components, as well as the command line that allows you to manage the cluster.
FtSys home page:

The ftSys Web Console provides access to view settings and status of remote monitoring (Stratus ActiveService Network, ASN), VTM, virtual switches, disk subsystem status and System Management logs (they contain failover logs and further synchronization).
Check the status of the cluster components:

Open CPU Enclosure 0:

Cluster components can be in one of the states:
- ONLINE - the component is synchronized and is in operation (refers to the CPU and RAM).
- DUPLEX - the component is synchronized and is in fault tolerant mode.
- SIMPLEX - cluster component is not synchronized, or is being diagnosed.
- BROKEN - the component is faulty and did not pass the diagnostics. It is important to note that in the case of network cards BROKEN says that the network cable is not connected.
- SHOT - node component diagnosed as faulty and electrically isolated by the system.
Since we started talking about CPU Enclosure 0, we’ll explain why it’s 0, and not some other number. In the Stratus naming system, each component has a path, and for those that are in the first node, there will always be 0 at the beginning of the path, and for those in the second - 1. This is done for the convenience of working with the cluster. For example, to view information about the component itself through the console:

To distinguish between CPU and IO Enclosure, the latter has a number 1 added at the beginning, so the IO of the module from the first node will have 10 path, and for the same module from the second node - 11.
Connecting via SSH to ftSys allows you to diagnose the server, including collecting logs, viewing detailed reports on components, as well as disabling components and modules as a whole.
Support and warranty
Consider cluster support with a description of the replaced components. Elements are divided into CRU (Customer Replaceable Unit) groups:
CRU | |
Decorative panel | Expander module management |
Compute node | PCIe adapter |
Memory | PCIe riser |
DVD drive | PDU |
HDD | Backplein |
This means that if your CPU or cooling module fails, the cluster node will come to you as an assembly, and you will need to rearrange all the other elements (DIMM, HBA and PCIe riser) from the list above.
The cluster itself is covered by one of four support programs (FtService): Total Assurance, System Assurance, Extended Platform Support and Platform Support. The table with the main indicators:
Ftservice | Total assurance | System assurance | Extended Platform Support | Platform Support |
Sending parts to the customer | NBD (Next Business Day) | NBD (Next Business Day) | NBD (Next Business Day) | NBD (Next Business Day) |
Critical response time | <30 minutes 24/7/365 | <60 minutes 24/7/365 | <2 hours 24/7/365 | <2 hours 9/5/365 |
First Response Time | 24/7/365 | 24/7/365 | 24/7/365 | 24/7/365 |
Proactive Monitoring (ASN) | 24/7/365 | 24/7/365 | 24/7/365 | 24/7/365 |
Access to Accessibility Engineer | 24/7/365 | 24/7/365 | Not | Not |
Search for the cause of the problem at the software level | Yes | Yes | Not | Not |
Identifying the root cause of the problem | Yes | Yes | Not | Not |
Check out | Yes | Yes | Not | Not |
Awarding high priority application | Yes | Yes | Not | Not |
Full OS support, including patches and updates | Yes | Not | Not | Not |
Collaboration with vendor | Yes | Not | Not | Not |
Guaranteed work without downtime | Yes | Not | Not | Not |
The standard warranty for the cluster is 1 year Platform Support, which involves only sending parts with analysis of the cause of the problem solely from the logs of the cluster itself. This means that if the reason lies somewhere in the OS, then they will not help you. You will have to either increase the level of support, or agree to paid assistance.
Certain difficulties may arise and if you want to update or reinstall the software for the cluster, it is not freely available. You need to ask the vendor or be content with what came along with the hardware itself on the disk.
The situation with the documentation is quite different - it is detailed and well written. It is freely available both in the form of an electronic journal and in the form of a pdf.
Although Stratus is not widely known in Russia, it is quite common in certain areas, for example, in oil and gas. The company has its own spare parts warehouse located in Moscow, where CRUs prepared for shipment are waiting in the wings. Of course, in the case of our vast country, it will take some time to deliver parts (especially if you live in Vladivostok), but this is still better than if parts came from Europe.
Hurray, tests!
Stratus cluster was connected via SAN (FC 8 Gb) to storage system (Hitachi AMS 2300). After that, on the cluster, we deployed a virtual machine on VMware ESXi 6 Update 1b running under Windows 2012 R2 and installed the Oracle DB 12c database.

Test stand
Testing was conducted in two stages:
- Assessment of failover and failback with high utilization of computing resources. Characteristics of the used virtual machine: 40 vCPU, 500 GB vRAM.
- Compare Stratus FT with VMware FT. Characteristics of the used virtual machine: 4 vCPU, 16 GB vRAM.
The differences in the characteristics of the VM for the 1st and 2nd stages are associated with the limitation of VMware FT in 4 vCPU.
For testing, we used a set of benchmarks Swingbench. Sales History was selected from the list of available tests. This test creates its own database (the selected size is 8 GB) and allows you to generate queries (known to be specified) to it with a certain frequency.
Requests are different types of uploads, such as sales reports for a month, week, etc. Benchmark settings (changes made to the finished model are described):
- Number of Users: 450 (instead of the standard 16). The number of users has been increased for a full (close to 95% peak) load on the VM.
- Test duration: 1.5 hours. Enough time to check the reliability of the platform as a whole, as well as to reach a normal average value of performance indicators.
For the study we have chosen the following method:
1. Run tests. Evaluation of cluster performance, determination of average values (after 15 minutes of operation):
- Transactions-per-Minute (TPM, number of transactions per minute);
- Transactions-per-Second (TPS, the number of transactions per second);
- Response Time (RT, db query processing time).
2. Disable Primary Cluster Node;
3. Putting the cluster node into operation (30 minutes after disconnection);
4. Waiting for full synchronization of both nodes and getting the DUPLEX status for all components.
Stage I. Assessment of failover and synchronization with high utilization of computing resources.
1. Average performance:
- Transactions-per-Minute, TPM: 542;
- Transactions-per-Second, TPS: 9;
- Response Time (db query processing time): 29335 ms.
2. Disable Primary Cluster Node:
06/06-07: 57: 10.101 INF t25 CpuBoard [0] DUPLEX / SECONDARY -> SIMPLEX / PRIMARY
This line in ftSys logs is a node extraction marker. After that, one ICMP Echo Request (Figure 17) was lost to the virtual machine, and then the cluster continued to work in normal mode.

Primary cluster extraction results. There was no effect on the disk subsystem, the average read latency remained within the reference


Primary Cluster Node Extraction Results
3. Putting the cluster node into operation:
Excerpt from ftSys logs:
06/06-08: 25: 32.061 INF t102 CIM Indication received for: ftmod 16 41
06/06-08: 25: 32.065 INF t102 Ftmod - indicationArrived. Index = 125, OSM index = 124
06/06-08: 25: 32.142 INF t102 Fosil event on bmc [10/120]
06/06-08: 25: 32.145 INF t25 Bmc [10/120] SIMPLEX / PRIMARY -> DUPLEX / PRIMARY
Note that the new cluster node (for replacement) comes without firmware, and during initialization, microcodes and configuration with the remaining in operation are poured into the chassis.
4. Waiting for full synchronization of both nodes and getting the DUPLEX status for all components:
Within 20 minutes after the cluster node is put into operation, the equipment is diagnosed and synchronized in the following order (with layering, that is, a number of parallel operations can occur):
i. BMC (VTM);
ii. IO Slots (PCIe);
iii. HDD and SSD;
iv. RAM and CPU.
i. BMC (VTM). BMC synchronization in our case was a little faster, since the firmware and configuration were already on the extracted node.
Excerpt from ftSys logs:
06/06-08: 25: 32.145 INF t25 Bmc [10/120] SIMPLEX / PRIMARY -> DUPLEX / PRIMARY
06 / 06-08: 26: 44.107 INF t25 Bmc [11/120] EMPTY / NONE -> DUPLEX / SECONDAR
06 / 06-08: 26: 44.259 INF t25 BMC flags, Needed = 00, Changed = 00
06 / 06-08: 26: 44.259 INF t25 Check if it’s possible to save for CFG conflict, saveRestoreCompleted: true
From the logs, it is clear that first VTM, which after failover, became PRIMARY, and only after a minute did SECONDARY VTM receive the same status in DUPLEX.
ii. IO Slots (PCIe). During PCIe synchronization, first determine the type of riser (Make) and only then alternately read each of the IO slots.
Excerpt from ftSys logs:
06/06-08: 27: 47.119 INF t25 Make Riser for IoBoard [11]: 2x PCI-E2 (x8)
06/06-08: 27: 47.122 INF t25 Make IoSlots for IoBoard [11]
06/06-08: 27: 47.238 INF t25 IoSlot [11/1] UNKNOWN / NONE -> EMPTY / NONE
06/06-08: 27: 47.239 INF t25 IoSlot [11/1] removing PCI, was 0000: 43: 00
06/06-08: 27: 47.245 INF t25 IoSlot [11/2] UNKNOWN / NONE -> EMPTY / NONE
06/06-08: 27: 47.245 INF t25 IoSlot [11/2] removing PCI, was 0000: 55: 00
06/06-08: 27: 47.252 INF t25 IoSlot [11/3] UNKNOWN / NONE -> INITIALIZING / NONE
06/06-08: 27: 47.256 INF t25 IoSlot [11/4] UNKNOWN / NONE -> EMPTY / NONE
06/06-08: 27: 47.256 INF t25 IoSlot [11/4] removing PCI, was 0000: c7: 00
06/06-08: 27: 47.262 INF t25 IoSlot [11/5] UNKNOWN / NONE -> INITIALIZING / NONE
And the first NICs are raised and they are added to ESXi:
06/06-08: 27: 48.705 INF t191 NetworkIfc (vmnic_110601) UNKNOWN / NONE -> ONLINE / NONE
06/06-08: 27: 48.709 INF t191 NetworkIfc (vmnic_110600) UNKNOWN / NONE -> ONLINE / NONE
06/06-08: 27: 48.712 INF t191 BondedIfc (vSwitch0) connecting slave vmnic_110600
06/06-08: 27: 48.716 INF t191 BondedIfc (vSwitch0.Management_Network) connecting slave vmnic_110600
At this point, the response time for the ICMP Echo request increases slightly:

Synchronize nodes. Add NIC.
iii. HDD and SSD. After the NICs are up, the reading of the data on the disks and their subsequent synchronization begins:
06 / 06-08: 28: 31.432 NOT t12 Storage Plugin: INFORMATION - 11/40/1 is now STATE_ONLINE / REASON_NONE
06/06-08: 28: 31.433 INF t12 Auto bringup Disk [11/40/1] based on MTBF
06 / 06-08: 28: 31.963 NOT t12 Storage Plugin: non-blank disk 11/40/1 discovered (safe mode)
06/06-08: 28: 31.964 INF t13 Storage: query superblock: vmhba1: C0: T1: L0
06 / 06-08: 28: 31.964 NOT t12 Storage Plugin: INFORMATION - 11/40/2 is now STATE_ONLINE / REASON_NONE
06 / 06-08: 28: 31.965 INF t12 Auto bringup Disk [11/40/2] based on MTBF
06 / 06-08: 28: 32.488 NOT t12 Storage Plugin: non-blank disk 11/40/2 discovered (safe mode)
06/06-08: 28: 32.488 NOT t12 Storage Plugin: INFORMATION - 11/40/3 is now STATE_ONLINE / REASON_NONE
06/06-08: 28: 32.489 INF t12 Auto bringup Disk [11/40/3] based on MTBF
06 / 06-08: 28: 32.964 NOT t12 Storage Plugin: non-blank disk 11/40/3 discovered (safe mode)
06/06-08: 28: 32.964 NOT t12 Storage Plugin: INFORMATION - 11/40/4 is now STATE_ONLINE / REASON_NONE
06/06-08: 28: 32.965 INF t12 Auto bringup Disk [11/40/4] based on MTBF
Next, ftSys determines the boot disk and proceeds to synchronize it:
06/06-08: 28: 40.360 INF t102 == 11/40/1 is a boot disk
06/06-08: 28: 40.360 INF t102 CIM Indication received for: FTSYS_Storage
06/06-08: 28: 40.367 NOT t12 Storage Plugin: INFORMATION - 11/40/1 is now STATE_SYNCING / REASON_NONE
The RAID controller (10/5, 11/5) and FC HBA (10/3, 11/3) for both nodes are raised last:
06/06-08: 30: 47.421 INF t25 IoSlot [11/3] ONLINE / NONE -> DUPLEX / NONE
06/06-08: 30: 47.426 INF t25 IoSlot [11/5] ONLINE / NONE -> DUPLEX / NONE
06 / 06-08: 30: 56.144 INF t25 IoSlot [10/5] SIMPLEX / NONE -> DUPLEX / NONE
06 / 06-08: 30: 56.151 INF t25 IoSlot [10/3] SIMPLEX / NONE -> DUPLEX / NONE
iv. RAM and CPU. Turning on the CPU Enclosure closes the synchronization of the cluster nodes:
06/06-08: 28: 46.409 INF t25 CpuBoard [1] REMOVED_FROM_SERVICE / OK_FOR_BRINGUP -> DIAGNOSTICS / NONE
After 2 minutes, the CPU transition from the DIAGNOSTICS status to the INITIALIZING status occurred and the firmware reading from the failed cluster node began:
06 / 06-08: 31: 21.105 INF t102 Fosil event on cpu [1]
06/06-08: 31: 21.105 INF t25 CpuBoard [1] DIAGNOSTICS / NONE -> INITIALIZING / NONE
06 / 06-08: 31: 26.105 INF t25 Read IDPROM / board data for CpuBoard [1]
06/06-08: 32: 02.048 INF t102 CIM Indication received for: ftmod
06 / 06-08: 32: 02.053 INF t102 Ftmod - indicationArrived. Index = 153, OSM index = 152
06/06-08: 32: 02.112 INF t102 Fosil event on cpu [1]
During RAM and CPU synchronization, performance dropped to 20% or 125 TPM, and in the period from 8:31:50 to 8:32:15 (25 seconds) TPS was zero.
It is also worth paying attention to Response Time, in this period of time its figure reached an absolute maximum of 313686 ms and lasted 3 s.
Synchronization ended 08: 37: 29.351, although according to the chart below, the drawdown was completed at 08:33:35.
06/06-08: 32: 04.280 INF t25 CpuBoard [1] INITIALIZING / NONE -> DUPLEX / SECONDARY
06 / 06-08: 34: 29.351 INF t25 Bringup Complete event, restoring bring up policy.
06 / 06-08: 37: 29.351 INF t25 BringupPolicy: enableCPU bringup
It can be concluded that the synchronization of cluster nodes after failover does not greatly affect the performance of the cluster until the synchronization of CPU and RAM, the latter squander the main indicators of the cluster. It is important to note that in this case the processors were utilized by 75% and RAM by 52%.

Initialization of CPU Enclosure. Performance impact
Stage II. Comparing Stratus FT with VMware FT
To carry out stage II, the virtual machine from stage I was cloned into a HA cluster of four Cisco UCS B200 M3 blade servers (CPU: Intel Xeon E5-2650, 2.0GHz; RAM: 128 GB DDR3) running ESXi 6 Update 2. Servers also were connected via SAN (8 Gb) to storage systems (Hitachi AMS 2300).
The average performance without VMware FT (compare the performance of VMware and Stratus (Stage I) does not make sense because of the limitations on the number of vCPUs and the type of CPUs themselves (differ in family and clock frequency):
- Transactions-per-Minute, TPM: 190;
- Transactions-per-Second, TPS: 3;
- Response Time (db query processing time): 2902 ms.
Before you turn on FT, let's designate its main features:
- A maximum of 4th vCPU and 64 GB Ram per VM are available;
- On a single host, a maximum of 8 vCPUs can be used in FT mode;
- Requires a dedicated 10 GB vNIC to synchronize cluster nodes;
- Requires shared storage;
Synchronization occurs at the level of virtual machines (Primary and Secondary), vCenter is the arbiter.
Average performance with VMware FT:
- Transactions-per-Minute, TPM: 160;
- Transactions-per-Second, TPS: 2;
- Response Time (db query processing time): 3652 ms.
It can be concluded that we are losing 16% of the overall cluster performance, especially FT significantly affects Response Time.

VMware average performance

VMware FT average performance
We estimate the impact of failover and recovery of the FT cluster on VM performance in the case of VMware FT and Stratus ftServer.
VMware FT
When failover is developed, VM performance increases from 160 to 190 TPM, since at this time the replication mechanism does not work.
After the switch is completed, a new Secondary VM is raised by the Storage vMotion forces and a mechanism is enabled that allows the machines to operate synchronously - vLockstep.Note that after the return of the FT cluster to its normal state, the TPM indicator sank to 140 and back to the average value of 160 never returned.
The average time for synchronization and the transition from standing “starting” to “protected” is on average 10 minutes.
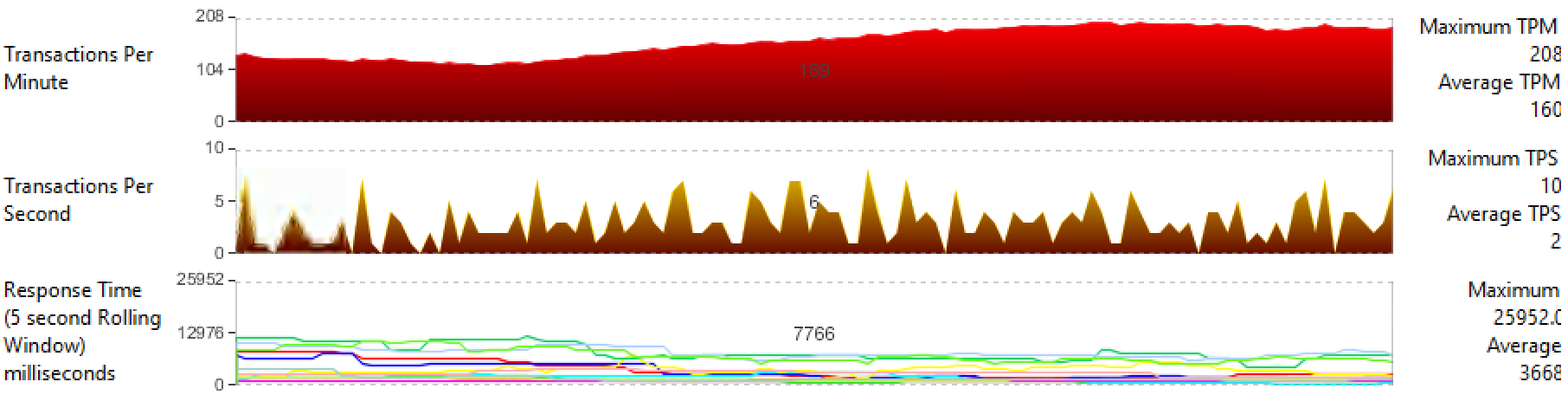
Stratus ftServer
The synchronization loss was 42% of the initial performance or 143 TPM with an average of 241 (Figure 26). As in the previous case, at the initial moment of replication of the CPU Enclosure, the TPS indicator dropped to 0. The
average time for synchronization and the transition from the SIMPLEX state to DUPLEX for the components of both cluster nodes is on average 2 minutes.
The differences between Stratus and VMware solutions are due to the fact that Stratus ftServer was originally developed as an FT cluster, so we have no significant limitations on CPU, memory or the need for shared storage (using only the internal disk subsystem of nodes). VMware FT is only an additional option that until the 6th version of the vSphere arrived in isolation due to the limitation of one vCPU and was unclaimed on the market.
Vmware FT. Performance gains in the failover

Vmware FT process . Performance drop after restoring FT

Stratus ftServer. Solution performance with failover and after node synchronization is complete
findings
ftServer is distinguished by a well-developed architecture that provides a full-mesh connection between the modules of the cluster nodes, which leads to an increase in the already high level of protection from the failure of any component. The solution is not limited to software, supports the latest versions of Windows and Linux, as well as vSphere and Hyper-V virtualization.
The situation is excellent with the documentation - detailed and well written. In addition, it is worth noting the presence of Russian-speaking support and a warehouse in Moscow, which guarantees timely assistance.
It is worth noting the small time for synchronization (after replacing the node) of the processor modules (during which there is a significant decrease in performance) and almost imperceptible replication of IO modules.
Given all the above, we note that Stratus has turned out an excellent cluster solution, and the declared availability of 99,999 really has a solid foundation.
Where is applied
In world and Russian practice such systems are used:
- For automation of continuous and discrete production processes and in energy accounting systems (APCS / SCADA and AMR).
- For MES - control systems and accounting of administrative and economic activities of enterprises.
- Naturally, in finance. This is Processing / ERP, exchange gateways. As a rule, this is bank processing or Oracle.
- Like VoIP gateways, softphones, call centers, billing, where a minute of downtime can mean with a thousand lost clients.
- Remote computing nodes that are difficult to access for maintenance, usually without personnel, are the very same “space”.
License
Another important point. Management is done as a single server, licensing is also like a single server (this is very important for banking licenses for DBMS).
References:
- Vendor documentation
- Architecture
- Cases and application
- My mail: GMogilev@croc.ru
Source: https://habr.com/ru/post/307086/
All Articles