Overview of the two courses “Machine Learning” from Coursera
I want to share my learning experience on the resource “Coursera”, namely, the development of the courses “Machine Learning Foundations: A Case Study Approach” and “Machine Learning: Regression” . These courses are part of the specialty “Machine Learning” (University of Washington).
Machine learning is not related to my current specialty. Interest in him was due to the desire to get acquainted with what is now paid a lot of attention. In my university days (2003-2010), this topic was not touched upon, so machine learning and big data are an unknown area for me. I would like to build in my head an idea about this topic and be able to solve simple tasks in order to delve into something concrete as necessary.
There were several reasons for choosing the Coursera portal and this particular course. First, reading articles on disparate topics about a little-known subject is not useful, since knowledge is not systematized. Therefore, there is a need for a built course. Secondly, there was a negative experience of listening to lectures, where the authors for a very long time tried to explain the obvious things, without actually getting to the point. What attracted me to the Machine Learning course is that the lecturers Carlos Guestrin and Emily Fox look extremely passionate about their subject matter (passioned & excited), speak quickly and to the point. And besides, it is noticeable that the authors deal with practical application, i.e. with industry.
According to the authors of the course, the reason for its creation was an attempt to convey the tasks of machine learning to a wide audience, i.e. for those whose training took place in different areas. The main differences include the fact that first focuses on specific tasks that can be found in existing applications, and how machine learning can help solve them. Then the methods used are analyzed, how they are arranged and how they can be useful. Thus, it can be seen in simple examples of how machine learning can be applied in practice. Moreover, nowadays, according to the authors, the consequences of using machine learning are noticeable. Previously, it was perceived differently. A certain set of data was fed to the input of a poorly understood algorithm, with the result that the conclusion “my graph is better than yours” was made, and the results were sent to a scientific journal.
')
Classes are divided into theoretical and practical part, and tests. In the theoretical part of the lecture (in English, English or Spanish subtitles). There are pdf presentations on which you can prepare for tests. Also on the forum are links to additional literature. In the 1st course of “Machine Learning Foundations: A Case Study Approach” there are lectures where you learn how to work in the IPython interactive shell. Here they talk about the basics of programming in Python (just everything you need to be able to perform tasks). In addition, there are lectures, where they talk about the principles of working with the library GraphLab Create. Tests are divided into theoretical and practical. Questions in theoretical tests require understanding, superficially listening to the material and successfully passing the test is unlikely to turn out. Sometimes lectures are not enough and you have to use additional materials. It is worth noting that here in one lesson you can yourself demonstrate with the help of assignments the main theoretical points.
The practical part is a test with tasks. The execution of tasks involves the ability to process a large set of data, as well as to perform operations on them. The authors recommend using the GraphLab Create library, which has an API in the Python language. With it, you can load data files from files into convenient structures (SFrame). These structures allow you to visualize data (special interactive graphs) and conveniently modify them (add columns, apply operations on rows, etc.). The library has machine learning algorithms with which to work. To perform tasks, you can use the template implemented in the IPython Notebook web shell. This is the file that stores the framework functions, as well as recommendations. For local work with GraphLab Create and IPython Notebook, the authors recommend using the Anaconda installer. You can also work on the Amazon EC2 web service, where all the necessary programs are already installed. I have chosen the second option, since you can immediately get down to work.
Now it’s worth talking about the course plan. The first course in Machine Learning Foundations: A Case Study Approach is introductory. Lectures of the first week are devoted to the description of the language Python, the library GraphLab Create. The authors also briefly talk about the content of other specialization courses. This is very useful, because the designated action plan does not forget which way you are moving and what you should be able to do at the end of the training. The remaining weeks contain an introduction to topics that will be covered in detail in future courses. What is given in these introductions requires a good understanding, you also need to be able to use algorithms in practical tasks. It should be noted that these tasks clearly demonstrate the read theory. Below is a course plan for Machine Learning Foundations: A Case Study Approach.
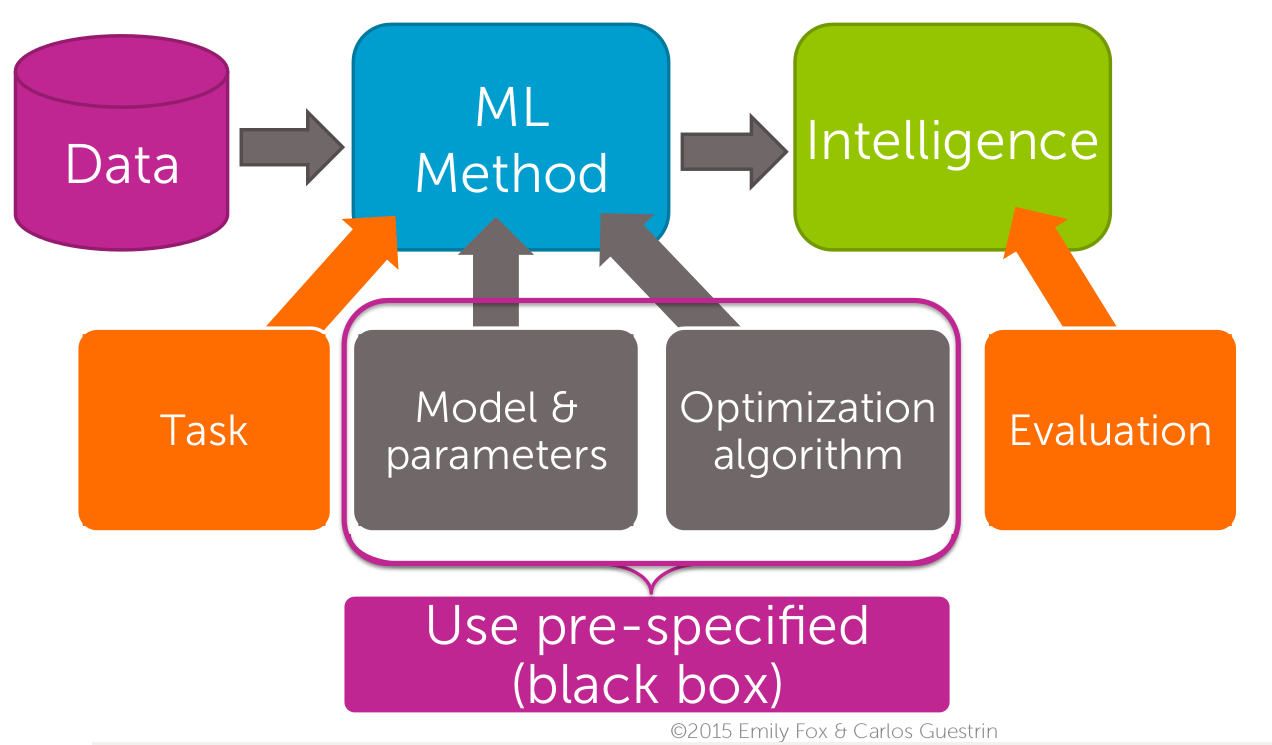
Figure 1. Machine Learning specialization structure (taken from the materials of the Machine Learning: Regression course, © 2015 Emily Fox & Carlos Guestrin)
To complete the second course of “Machine Learning: Regression” specialization, you need to have an idea about derivatives, matrices, vectors and basic operations on them. The ability to create at least simple Python programs will be useful. A brief description of the second course of specialization “Machine Learning: Regression” is given below.
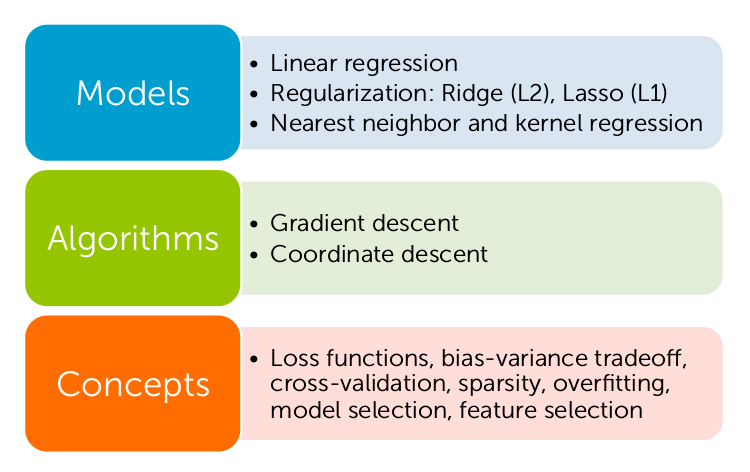
Figure 2. Topics studied in the Machine Learning: Regression course (Taken from the materials of the Machine Learning: Regression course, © 2015 Emily Fox & Carlos Guestrin)
Weekly load is adequate. However, the second course of “Machine Learning: Regression” is more intense. If you are more than two weeks late, you will be asked to switch to another session, but this is not necessary. I listened to lectures during the working week, on Friday or on weekends practical tasks were performed. I spent about three hours on them.
In conclusion, I would like to say that the described courses of the specialty “Machine Learning” made a good impression. The advantages I take practical tasks, they are carefully thought out and illustrate the theory. I liked the lectures, which are capacious and in which there is no "water". The courses are structured, there are diagrams that help you understand what “part” of machine learning you are currently studying, what you know and what you have to learn. The disadvantages are that sometimes there is not enough read theory. I would like more links to other resources, although the official forum lists recommended books, which can also be downloaded there. In general, the Machine Learning specialization courses will be very useful if you want to learn how to practically use machine learning methods.
Machine learning is not related to my current specialty. Interest in him was due to the desire to get acquainted with what is now paid a lot of attention. In my university days (2003-2010), this topic was not touched upon, so machine learning and big data are an unknown area for me. I would like to build in my head an idea about this topic and be able to solve simple tasks in order to delve into something concrete as necessary.
There were several reasons for choosing the Coursera portal and this particular course. First, reading articles on disparate topics about a little-known subject is not useful, since knowledge is not systematized. Therefore, there is a need for a built course. Secondly, there was a negative experience of listening to lectures, where the authors for a very long time tried to explain the obvious things, without actually getting to the point. What attracted me to the Machine Learning course is that the lecturers Carlos Guestrin and Emily Fox look extremely passionate about their subject matter (passioned & excited), speak quickly and to the point. And besides, it is noticeable that the authors deal with practical application, i.e. with industry.
According to the authors of the course, the reason for its creation was an attempt to convey the tasks of machine learning to a wide audience, i.e. for those whose training took place in different areas. The main differences include the fact that first focuses on specific tasks that can be found in existing applications, and how machine learning can help solve them. Then the methods used are analyzed, how they are arranged and how they can be useful. Thus, it can be seen in simple examples of how machine learning can be applied in practice. Moreover, nowadays, according to the authors, the consequences of using machine learning are noticeable. Previously, it was perceived differently. A certain set of data was fed to the input of a poorly understood algorithm, with the result that the conclusion “my graph is better than yours” was made, and the results were sent to a scientific journal.
')
Classes are divided into theoretical and practical part, and tests. In the theoretical part of the lecture (in English, English or Spanish subtitles). There are pdf presentations on which you can prepare for tests. Also on the forum are links to additional literature. In the 1st course of “Machine Learning Foundations: A Case Study Approach” there are lectures where you learn how to work in the IPython interactive shell. Here they talk about the basics of programming in Python (just everything you need to be able to perform tasks). In addition, there are lectures, where they talk about the principles of working with the library GraphLab Create. Tests are divided into theoretical and practical. Questions in theoretical tests require understanding, superficially listening to the material and successfully passing the test is unlikely to turn out. Sometimes lectures are not enough and you have to use additional materials. It is worth noting that here in one lesson you can yourself demonstrate with the help of assignments the main theoretical points.
The practical part is a test with tasks. The execution of tasks involves the ability to process a large set of data, as well as to perform operations on them. The authors recommend using the GraphLab Create library, which has an API in the Python language. With it, you can load data files from files into convenient structures (SFrame). These structures allow you to visualize data (special interactive graphs) and conveniently modify them (add columns, apply operations on rows, etc.). The library has machine learning algorithms with which to work. To perform tasks, you can use the template implemented in the IPython Notebook web shell. This is the file that stores the framework functions, as well as recommendations. For local work with GraphLab Create and IPython Notebook, the authors recommend using the Anaconda installer. You can also work on the Amazon EC2 web service, where all the necessary programs are already installed. I have chosen the second option, since you can immediately get down to work.
Now it’s worth talking about the course plan. The first course in Machine Learning Foundations: A Case Study Approach is introductory. Lectures of the first week are devoted to the description of the language Python, the library GraphLab Create. The authors also briefly talk about the content of other specialization courses. This is very useful, because the designated action plan does not forget which way you are moving and what you should be able to do at the end of the training. The remaining weeks contain an introduction to topics that will be covered in detail in future courses. What is given in these introductions requires a good understanding, you also need to be able to use algorithms in practical tasks. It should be noted that these tasks clearly demonstrate the read theory. Below is a course plan for Machine Learning Foundations: A Case Study Approach.
- Week 1. Introduction. The authors describe case studies that will be presented in the next weeks of this course. Subsequent courses of specialization are in detail devoted to the same examples. The authors describe how machine learning methods help solve existing problems. Learn to work with GraphLab Create. There is an introduction to the Python language and the IPython Notebook shell. Schemes of the course structure are given (see figure 1 for an example).
- Week 2. Regression: Real Estate Price Forecasting ("Regression: Predicting House Prices"). Here they talk about the methods that allow according to the available data [price for a house - its parameters], to predict the price for a house, the parameters of which are not in the set. Regression is dedicated to the second course of specialization “Machine Learning: Regression”.
- Week 3. Classification: text tonality analysis ("Classification: Analyzing Sentiment"). The authors talk about how to classify objects. Examples include such tasks as grading a restaurant based on review texts; definition of topics for articles on their content; definition of what is shown in the picture. The classification is devoted to the third course of specialization "Machine Learning: Classification".
- Week 4. Clustering and similarity search: document retrieval ("Clustering and Similarity: Retrieving Documents"). As an educational example, here is the task of recommending a user of articles based on articles that he has already read. They talk about the methods of presenting text documents and how to measure the similarity between them. Describe the tasks of clustering objects (the process of grouping them according to certain characteristics). Clustering is dedicated to the fourth course in Machine Learning: Clustering & Retrieval.
- Week 5. Recommending Products. Here they talk about applications where recommendation systems can be useful; about how to build recommendation systems; metrics for evaluating the effectiveness of recommendation systems. The recommendation system is dedicated to the fifth course of specialization "Machine Learning: Recommender Systems & Dimensionality Reduction".
- Week 6. Deep Learning: Image Search (“Deep Learning: Searching for Images”). Last week is devoted to multi-level neural networks. This topic is covered in more detail in the latest course in Machine Learning Capstone: An Intelligent Application with Deep Learning.
Figure 1. Machine Learning specialization structure (taken from the materials of the Machine Learning: Regression course, © 2015 Emily Fox & Carlos Guestrin)
To complete the second course of “Machine Learning: Regression” specialization, you need to have an idea about derivatives, matrices, vectors and basic operations on them. The ability to create at least simple Python programs will be useful. A brief description of the second course of specialization “Machine Learning: Regression” is given below.
- Introduction The authors tell what place regression takes in machine learning. Lists the applications where regression is used, and the objectives of the case study — real estate price forecasting — are described. It gives an overview of the topics to be studied. These themes are illustrated in Figure 2. Linear regression, two types of regularization (Ridge, Lasso), nearest neighbors regression, nuclear regression (non-parametric regression - nuclear smoothing) ( kernel regression). Algorithms such as gradient descent, coordinate descent are analyzed. The key terms of the course are the loss functions, the trade-off between displacement and dispersion (bias-variance tradeoff), cross-validation (cross-validation), sparsity, overfitting, model selection, choice characteristics (feature selection) (I apologize if the translation is incorrect).
- Week 1. Simple regression. The principle of this model is explained, and the features of the choice of its input data are discussed. A metric for evaluating the quality of a simple linear regression is introduced. Algorithms for calculating model parameters that optimize quality metrics (gradient descent) are presented. Explains the meaning of the parameters. It shows how to make a forecast using the calculated parameters. The sources of errors are discussed.
- Week 2. Multiple regression. It describes polynomial regression and displays a regression model with several parameters. The process of minimization of the quality assessment metrics is demonstrated, and algorithms for calculating the parameters of the regression model (gradient descent and coordinate gradient) are described. The algorithm for generating predictions is described.
- Week 3. Assessing performance. Issues discussed during this week are: model quality assessment metrics; properties of the loss function in comparison with a learning error, a generalization error and a test error; the implications of choosing a test error as a performance metric; the trade-off of choosing the proportion of data partitioning into test and training sets; sources of predicted data error; the choice of the complexity of the model; validation set.
- Week 4. Ridge regression. The behavior of the calculated parameters of the model with its excessive training is considered; description of the dependence of the model coefficients on the ridge regression adjustment parameter; implementation of the gradient descent algorithm; cross-validation algorithm for selecting the best adjustment parameter.
- Week 5. Lasso regression. The choice of significant parameters of the model is discussed. "Greedy" and optimal algorithms are compared. The model coefficients depend on the lasso regression adjustment parameter. A cross-validation algorithm for selecting the best adjustment parameter is described.
- Week 6. Nearest neighbor and kernel regression and nonparametric regression with nuclear smoothing. Lists the reasons for using the method of nearest neighbors. The definition of nuclear regression is given and examples of its use are given.
Figure 2. Topics studied in the Machine Learning: Regression course (Taken from the materials of the Machine Learning: Regression course, © 2015 Emily Fox & Carlos Guestrin)
Weekly load is adequate. However, the second course of “Machine Learning: Regression” is more intense. If you are more than two weeks late, you will be asked to switch to another session, but this is not necessary. I listened to lectures during the working week, on Friday or on weekends practical tasks were performed. I spent about three hours on them.
In conclusion, I would like to say that the described courses of the specialty “Machine Learning” made a good impression. The advantages I take practical tasks, they are carefully thought out and illustrate the theory. I liked the lectures, which are capacious and in which there is no "water". The courses are structured, there are diagrams that help you understand what “part” of machine learning you are currently studying, what you know and what you have to learn. The disadvantages are that sometimes there is not enough read theory. I would like more links to other resources, although the official forum lists recommended books, which can also be downloaded there. In general, the Machine Learning specialization courses will be very useful if you want to learn how to practically use machine learning methods.
Source: https://habr.com/ru/post/307048/
All Articles