As we NoSQL in "Relation" replicated
Nowadays, NoSQL continues to gain popularity, but few know that non-relational DBMS appeared much earlier than even the relational algebra itself. 40 and even 50 years ago, only NoSQL products “cooked” in the primary “broth” of the emerging IT industry. And what is most interesting - products born in those difficult times are still alive and feel great.
One such product was the DBMS GT.m , developed by Graystone Tehnologies in the 1970s and 1980s. DBMS has found wide application in medicine, insurance and banking.
In our bank, we also use GT.m, and this tool does an excellent job of processing a large number of transactions. But ... There is one problem: GT.m is not for analytics, it does not contain SQL, analytical queries and everything that makes financial analytics happy. Therefore, we have developed our own “bicycle” for replicating data from GT.m to “relational” DBMS.

And here was supposed to be a picture with a flying bicycle
')
All interested invite under the cat.
Pss ... do you want some more GT.m? Already in those prehistoric times, GT.m had (or had) ACID, transactional serialization, and the presence of indices and the procedural language MUMPS. By the way, MUMPS is not just a language, it is a whole direction that emerged in the 60s of the 20th century!
One of the most successful and popular MUMPS-based DBMS has become Caché , and you most likely heard about it.
The basis of MUMPS DBMS are hierarchical structures - globals. Imagine JSON, XML, or the structure of folders and files on your computer - about the same. And all this our fathers and grandfathers enjoyed before it became mainstream.
One important point - in 2000, the database became Open Source.
So, the old woman GT.m is reliable and, despite its advanced years, serves a large number of specific transactions without any effort, unlike, for example, from its SQL counterparts (the phrase is, of course, holivarnaya, but for us this is a fact: load NoSQL is still faster than SQL). However, all the problems begin when we need to do the simplest analytics, transfer data to analytical systems or, God forbid, automate all this.
For a long time, the solution to this problem was the ubiquitous "unloading." CSV files were generated by procedures written in the M language (MUMPS), and each such upload was developed, tested and implemented by highly qualified specialists. The effort involved in the development of each unloading was enormous, and the contents of two different unloadings could overlap significantly. It happened that customers required unloading, to several fields different from the existing ones, and they had to do it all over again. At the same time, the M language itself is rather hard to understand and read, which entails additional “costs” both for development and for supporting all this hardcode.

Solution with uploads
We already had an implemented architectural pattern called ODS ( Operational Data Store ), in which we replicate our sources with minimal backlog from 2 seconds to 15 minutes.
We load data from ODS into the data warehouse (DWH) or build operational reports on it. And with relational databases such as Oracle, MS SQL, Sybase, etc. no problem - we will load source tables into the same tables on the ODS.
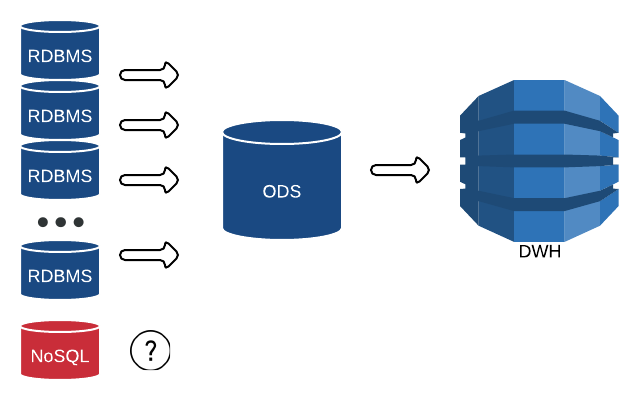
We really wanted to implement a similar replication of GT.m in ODS.
But how to load NoSQL structures into simple tables? How, for example, download a client that can have 2 phones, and maybe 22?

We understood that it would be more correct to organize replication based on binary logs of the DBMS (in other DBMS they are called WAL, Redo, transaction log, etc.), since GT.m logs each transaction, the data being changed. At the same time, ready-made products already existed on the market, one of which is the Evolve Replicator from CAV systems .
Evolve reads transaction logs, transforms them, and writes rows to tables already on the relational receiver.
But there was one very small problem - this solution did not suit us ... In our structures there was a large number of calculated values (Computed Data Items or CDI).
I'll try to explain on the fingers. This is somewhat reminiscent of a “virtual field” in a DBMS such as Oracle, in which the value is not stored, but calculated at the time of accessing this field. At the same time, CDI can have quite complex logic and be based on data from child nodes, etc. And, as you probably already guessed, such Computed Data Items cannot be replicated from DBMS logs, since information on them is not stored there, because only changes in physical fields are recorded in logs. But we really need such ghost fields for analytics, they have complex logic, and it would be meaningless to have an analytical replica without these fields.
Implementing similar logic with calculated fields in a replica is unrealistic. First, because of performance, and second, to rewrite this entire hardcode from M to SQL is a thankless task.

In addition to the data level, in our system we have the level of applications written in the M. Language. Yes, in our times it sounds crazy, but most banking systems still live in the paradigm of two-tier architecture.
Such an application is the FIS Profile (hereinafter Profile) - this is an automated banking system, fully integrated with GT.m. In addition to banking automation functions, Profile provides the following functionality:
1. The simplest SQL (select * from table where id = 1)
2. Access to JDBC data
3. Representation of globals in a table view, with one global can be presented in several different tables
4. Triggers
5. Secury
In fact, we have another DBMS on top of another DBMS. In this case, one of them will be relational, and the other - NoSQL.
Profile is completely proprietary software, but there are also Open Source analogues, for example, Vista Fileman .

The logical levels of our GT.m-system.
To replicate NoSQL data structures to SQL DBMS, first of all:
1. Present globaly in tabular form.
In this case, one node of the "tree" can be represented in the form of several, interconnected tables. This feature is already provided by the Profile, and all we need is to properly configure such table views. The task, though difficult, is quite solvable.
2. Capture change.
Unfortunately, the presence of CDI in our system does not allow making “correct replication” from the DBMS logs. The only possible option is logical replication with triggers. The value in the table has changed - the trigger caught it and recorded the change in the journal table. By the way, the journal table is the same global. Now all see for yourself!
This is what a typical global looks like:

We understand that it looks at least ... strange, but in those early years the concepts of beauty were completely different. The structure of the global is also called “multidimensional sparse array”. And the key is like the coordinate of the data that lies in it.
By the way, according to the "data" you can also build indexes, which is very convenient for the table view.
Actually, from this global we can get 2 tables:
TABLE_HEADER:

TABLE_SHED - change log:
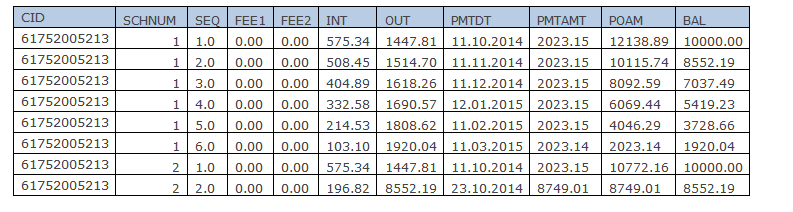
By the way, the numerical values are converted to dates, for example, for the TJD field.
A query is made on the available tables.
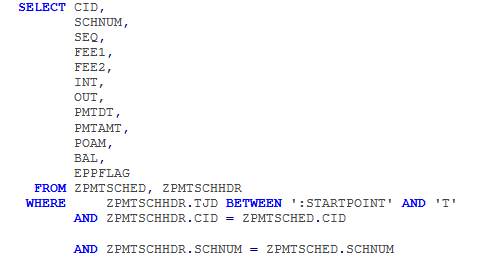
Where:
: STARTPOINT - the last run date;
'T' is the current date (it looks at least strange, but this function is analogous to sysdate () or now () innormal other DBMS)
As we can see, the “tables” join; in fact, the connection is local, within each node, which does not create a significant load.
3. Selection of data from journal tables and their subsequent transfer to the ODS.
The JDBC driver that existed at that time worked perfectly with atomic queries, but caused memory leaks during massive Select operations. The existing driver had to be significantly rewritten.
4. Delivery and application of changes.
A very important aspect is the rapid application of data on the receiver. If GT.m successfully copes with a large number of atomic transactions, then for Oracle relational DBMS such as it carries a large load. At the same time, data from a large number of other sources (about 15 in total) are being poured into our ODS.
To solve this problem, it is necessary to collect all such operations in batches and apply them as a group. Such operations are called Bulk and are completely dependent on the specifics of the receiver DBMS.

Current replication architecture
Our application - by the way, we called it Profile Loader - loads two types of tables into ODS: journal and mirror. We will try to tell about ODS in future articles, but if it is short, then:
log tables - change log tables, these tables are convenient for incremental loading, for example, to analytical systems and DWH
mirror tables - tables containing a complete copy of the source data, such tables are convenient to use for auditing and for operational analytics.
5. Point of management.
For easy administration, we made a web snout to start and stop replication streams. And in general, all the main logic was written in Java, which allowed the use of ready-made Open Source components to solve some specific cases.
1. Disposal of scattered discharges. We received a single window for all data consumers.
2. Audit. The audit procedure is simplified due to the fact that the data lie in a convenient form, and the power of SQL allows you to conveniently and quickly operate with this data.
3. Data quality. For example, in GT.m there are only 2 data types - numeric and string. When the data arrive in ODS, it is converted to other types, including dates. If the date is in the wrong format, we can easily catch such an incident and improve the quality of the data already at the source.
4. Calculation of increment for further loading in DWH.
For the future we plan to implement the following:
1. Completely get rid of existing CSV uploads. Now they are still alive, but we will slowly "shoot them off."
2. Optimize some performance issues.
3. Share ideas with the interested community, and possibly support the project in OpenSource.
4. Try integration with Oracle GoldenGate at the change delivery level.
5. It is possible to make a return replica (optional, not ODS) Replica -> GT.m, for service processes of improving data quality.
6. Develop operational reporting on top of ODS.
In the article we talked about our offspring - Profile Loader and how NoSQL data can be analyzed in SQL DBMS. This decision may not be entirely correct and elegant, but it works perfectly and fulfills its obligations.
If you decide to replicate your NoSQL database into a "relational" for convenient analytics, first of all, estimate the amount of changes, the data model and the capabilities of the technologies that will provide all this.
We wish you success in your endeavors!
Always ready to answer your questions.
PS We are also grateful to the colleagues who participated and actively assisted in the project: Shevelev Dmitriy, Olya Chechnya, Olya Zhukov, Olya Zhukov, Zhenya, Oksana, Lyubko Andrey, Kudyurova Pavel, Vorobiova Sergey, Lysykh Sergey, Kuleshov Sergey, Lyudko Andrey, Kudyurova Pavel, Vorobiova Sergey, Lysykh Sergey, Kuleshov Dmitry, Lyudko Andrey Yulia, Pasynkova Yuri and colleagues from CAV Systems and FIS.
One such product was the DBMS GT.m , developed by Graystone Tehnologies in the 1970s and 1980s. DBMS has found wide application in medicine, insurance and banking.
In our bank, we also use GT.m, and this tool does an excellent job of processing a large number of transactions. But ... There is one problem: GT.m is not for analytics, it does not contain SQL, analytical queries and everything that makes financial analytics happy. Therefore, we have developed our own “bicycle” for replicating data from GT.m to “relational” DBMS.
And here was supposed to be a picture with a flying bicycle
')
All interested invite under the cat.
Pss ... do you want some more GT.m? Already in those prehistoric times, GT.m had (or had) ACID, transactional serialization, and the presence of indices and the procedural language MUMPS. By the way, MUMPS is not just a language, it is a whole direction that emerged in the 60s of the 20th century!
One of the most successful and popular MUMPS-based DBMS has become Caché , and you most likely heard about it.
The basis of MUMPS DBMS are hierarchical structures - globals. Imagine JSON, XML, or the structure of folders and files on your computer - about the same. And all this our fathers and grandfathers enjoyed before it became mainstream.
One important point - in 2000, the database became Open Source.
So, the old woman GT.m is reliable and, despite its advanced years, serves a large number of specific transactions without any effort, unlike, for example, from its SQL counterparts (the phrase is, of course, holivarnaya, but for us this is a fact: load NoSQL is still faster than SQL). However, all the problems begin when we need to do the simplest analytics, transfer data to analytical systems or, God forbid, automate all this.
For a long time, the solution to this problem was the ubiquitous "unloading." CSV files were generated by procedures written in the M language (MUMPS), and each such upload was developed, tested and implemented by highly qualified specialists. The effort involved in the development of each unloading was enormous, and the contents of two different unloadings could overlap significantly. It happened that customers required unloading, to several fields different from the existing ones, and they had to do it all over again. At the same time, the M language itself is rather hard to understand and read, which entails additional “costs” both for development and for supporting all this hardcode.
Solution with uploads
ODS (Operational Data Store)
We already had an implemented architectural pattern called ODS ( Operational Data Store ), in which we replicate our sources with minimal backlog from 2 seconds to 15 minutes.
We load data from ODS into the data warehouse (DWH) or build operational reports on it. And with relational databases such as Oracle, MS SQL, Sybase, etc. no problem - we will load source tables into the same tables on the ODS.
We really wanted to implement a similar replication of GT.m in ODS.
But how to load NoSQL structures into simple tables? How, for example, download a client that can have 2 phones, and maybe 22?
We understood that it would be more correct to organize replication based on binary logs of the DBMS (in other DBMS they are called WAL, Redo, transaction log, etc.), since GT.m logs each transaction, the data being changed. At the same time, ready-made products already existed on the market, one of which is the Evolve Replicator from CAV systems .
Evolve CAV systems
Evolve reads transaction logs, transforms them, and writes rows to tables already on the relational receiver.
But there was one very small problem - this solution did not suit us ... In our structures there was a large number of calculated values (Computed Data Items or CDI).
I'll try to explain on the fingers. This is somewhat reminiscent of a “virtual field” in a DBMS such as Oracle, in which the value is not stored, but calculated at the time of accessing this field. At the same time, CDI can have quite complex logic and be based on data from child nodes, etc. And, as you probably already guessed, such Computed Data Items cannot be replicated from DBMS logs, since information on them is not stored there, because only changes in physical fields are recorded in logs. But we really need such ghost fields for analytics, they have complex logic, and it would be meaningless to have an analytical replica without these fields.
Implementing similar logic with calculated fields in a replica is unrealistic. First, because of performance, and second, to rewrite this entire hardcode from M to SQL is a thankless task.
FIS Profile
In addition to the data level, in our system we have the level of applications written in the M. Language. Yes, in our times it sounds crazy, but most banking systems still live in the paradigm of two-tier architecture.
Such an application is the FIS Profile (hereinafter Profile) - this is an automated banking system, fully integrated with GT.m. In addition to banking automation functions, Profile provides the following functionality:
1. The simplest SQL (select * from table where id = 1)
2. Access to JDBC data
3. Representation of globals in a table view, with one global can be presented in several different tables
4. Triggers
5. Secury
In fact, we have another DBMS on top of another DBMS. In this case, one of them will be relational, and the other - NoSQL.
Profile is completely proprietary software, but there are also Open Source analogues, for example, Vista Fileman .
The logical levels of our GT.m-system.
Concept implementation
To replicate NoSQL data structures to SQL DBMS, first of all:
1. Present globaly in tabular form.
In this case, one node of the "tree" can be represented in the form of several, interconnected tables. This feature is already provided by the Profile, and all we need is to properly configure such table views. The task, though difficult, is quite solvable.
2. Capture change.
Unfortunately, the presence of CDI in our system does not allow making “correct replication” from the DBMS logs. The only possible option is logical replication with triggers. The value in the table has changed - the trigger caught it and recorded the change in the journal table. By the way, the journal table is the same global. Now all see for yourself!
This is what a typical global looks like:
We understand that it looks at least ... strange, but in those early years the concepts of beauty were completely different. The structure of the global is also called “multidimensional sparse array”. And the key is like the coordinate of the data that lies in it.
By the way, according to the "data" you can also build indexes, which is very convenient for the table view.
Actually, from this global we can get 2 tables:
TABLE_HEADER:
TABLE_SHED - change log:
By the way, the numerical values are converted to dates, for example, for the TJD field.
A query is made on the available tables.
Where:
: STARTPOINT - the last run date;
'T' is the current date (it looks at least strange, but this function is analogous to sysdate () or now () in
As we can see, the “tables” join; in fact, the connection is local, within each node, which does not create a significant load.
3. Selection of data from journal tables and their subsequent transfer to the ODS.
The JDBC driver that existed at that time worked perfectly with atomic queries, but caused memory leaks during massive Select operations. The existing driver had to be significantly rewritten.
4. Delivery and application of changes.
A very important aspect is the rapid application of data on the receiver. If GT.m successfully copes with a large number of atomic transactions, then for Oracle relational DBMS such as it carries a large load. At the same time, data from a large number of other sources (about 15 in total) are being poured into our ODS.
To solve this problem, it is necessary to collect all such operations in batches and apply them as a group. Such operations are called Bulk and are completely dependent on the specifics of the receiver DBMS.
Current replication architecture
Our application - by the way, we called it Profile Loader - loads two types of tables into ODS: journal and mirror. We will try to tell about ODS in future articles, but if it is short, then:
log tables - change log tables, these tables are convenient for incremental loading, for example, to analytical systems and DWH
mirror tables - tables containing a complete copy of the source data, such tables are convenient to use for auditing and for operational analytics.
5. Point of management.
For easy administration, we made a web snout to start and stop replication streams. And in general, all the main logic was written in Java, which allowed the use of ready-made Open Source components to solve some specific cases.
Tasks solved by SQL replica
1. Disposal of scattered discharges. We received a single window for all data consumers.
2. Audit. The audit procedure is simplified due to the fact that the data lie in a convenient form, and the power of SQL allows you to conveniently and quickly operate with this data.
3. Data quality. For example, in GT.m there are only 2 data types - numeric and string. When the data arrive in ODS, it is converted to other types, including dates. If the date is in the wrong format, we can easily catch such an incident and improve the quality of the data already at the source.
4. Calculation of increment for further loading in DWH.
Further development
For the future we plan to implement the following:
1. Completely get rid of existing CSV uploads. Now they are still alive, but we will slowly "shoot them off."
2. Optimize some performance issues.
3. Share ideas with the interested community, and possibly support the project in OpenSource.
4. Try integration with Oracle GoldenGate at the change delivery level.
5. It is possible to make a return replica (optional, not ODS) Replica -> GT.m, for service processes of improving data quality.
6. Develop operational reporting on top of ODS.
Summary
In the article we talked about our offspring - Profile Loader and how NoSQL data can be analyzed in SQL DBMS. This decision may not be entirely correct and elegant, but it works perfectly and fulfills its obligations.
If you decide to replicate your NoSQL database into a "relational" for convenient analytics, first of all, estimate the amount of changes, the data model and the capabilities of the technologies that will provide all this.
We wish you success in your endeavors!
Always ready to answer your questions.
PS We are also grateful to the colleagues who participated and actively assisted in the project: Shevelev Dmitriy, Olya Chechnya, Olya Zhukov, Olya Zhukov, Zhenya, Oksana, Lyubko Andrey, Kudyurova Pavel, Vorobiova Sergey, Lysykh Sergey, Kuleshov Sergey, Lyudko Andrey, Kudyurova Pavel, Vorobiova Sergey, Lysykh Sergey, Kuleshov Dmitry, Lyudko Andrey Yulia, Pasynkova Yuri and colleagues from CAV Systems and FIS.
Source: https://habr.com/ru/post/306954/
All Articles