Distributed execution of Python tasks using Apache Mesos. Yandex experience
Preparation of release of cartographic data includes the launch of mass data processing. Some tasks fit well with the ideology of Map-Reduce. In this case, the infrastructure task is traditionally solved using Hadoop or YT.
In reality, part of the tasks are such that splitting them into small subtasks is impossible, or impractical (due to the presence of an existing solution and expensive development, for example). To do this, we in Yandex.Maps have developed and use our own system for planning and performing interrelated tasks. One of the elements of such a system is a scheduler that runs tasks on a cluster based on available resources.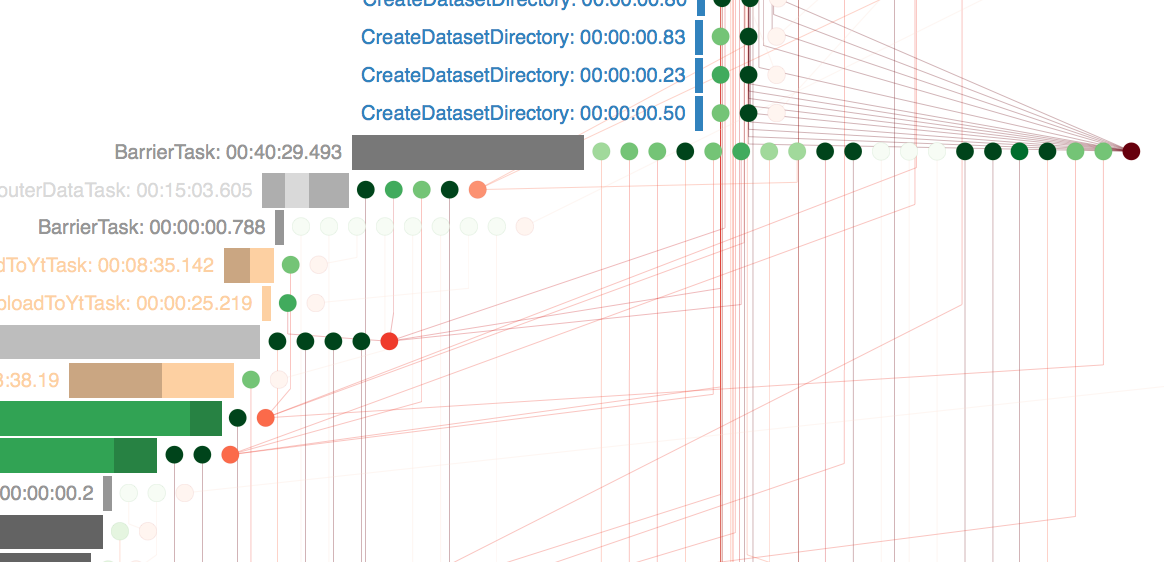
This article is about how we solved this problem using Apache Mesos .
For simplicity, let's assume that the existing implementation dictates the following interface in Python:
class Task(object): # "" . , # . def consumption(self): # dict < > -> < > # : "cpu" ( ), "ram" , "db_connections" pass def run(self): # , # exception -- # ( ). pass class TaskExecuter(object): def execute(self, task): # `task` pass def cancel(self, task): # `task`, # , . pass def pop_finished(self, task): # . # tupple `(task, return_value, exception)` # return_value exception. pass Terminology
Let us examine the main concepts used in Mesos, which are necessary for performing tasks. Mesos-master is the cluster coordinator, collects information about the available hosts and their resources, and offers applications.
- Mesos-agent , Mesos-slave - a program running on each worker, reports its resources to the master, starts tasks.
- Scheduler - a task scheduler, program, or part of a supervisor program. He knows what tasks to perform. Decides what tasks to perform with the available resources.
- Executor - "executor" of tasks, a separate program running on agent-hosts. Receiving a task sent by Scheduler performs it. Reports the status of its execution and sends the result.
- The communication protocol between Scheduler and Executor is the protobuf messages described in Mesos. Each task is actually described by a string field in this message. The interpretation of this line is the internal affair of Scheduler and Executor. As you can see, Scheduler and Executor are closely related, together in Mesos terminology they are called Framework .
The scheme of work with this:
- An application that wants to run tasks in Mesos, creates a Scheuler object and registers it in Mesos-master
- The Mesos master collects available resources and offers them to Schedulers as resourceOffer .
- If the Scheduler has a suitable task, then it sends it to the master, together with the resourceOffer ID.
- Mesos delivers the task to the slave, and runs the Executor there (if not already started).
And passes the task into it. - Executer performs the task, and reports the result of the slave 'at
- The result is delivered to the Scheduler as a StatusUpdate message.
Installing the local version of Mesos
Generally speaking, the recommended installation of Mesos includes 3 hosts running the Mesos wizard process and using Zookeeper to synchronize them.
But for development, one running on a local machine is sufficient. At the moment, the easiest way to install Mesos, collecting it from the source. Installation for various platforms is described in the Getting Started section of the Mesos documentation.
Here’s how it looked for Mac OS (given that I already have all the development tools):
$ git clone https://github.com/apache/mesos.git Cloning into 'mesos'... remote: Counting objects: 90921, done. remote: Compressing objects: 100% (13/13), done. remote: Total 90921 (delta 3), reused 0 (delta 0), pack-reused 90908 Receiving objects: 100% (90921/90921), 281.56 MiB | 5.06 MiB/s, done. Resolving deltas: 100% (65917/65917), done. Checking connectivity... done. $ cd mesos/ $ git checkout 0.28.2 # $ ./bootstrap $ mkdir build && cd build $ ../configure --prefix=$HOME/opt/usr --with-python $ make -j6 # 6 , , # $ make install For convenience, you can add paths to Mesos in environment variables.
export PATH=$PATH:$HOME/opt/usr/bin export PYTHONPATH=$HOME/opt/usr/lib/python/site-packages/ export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$HOME/opt/usr/lib/ Run local version
$ mesos-local Mesos is now installed and running. His status can be viewed at localhost: 5050
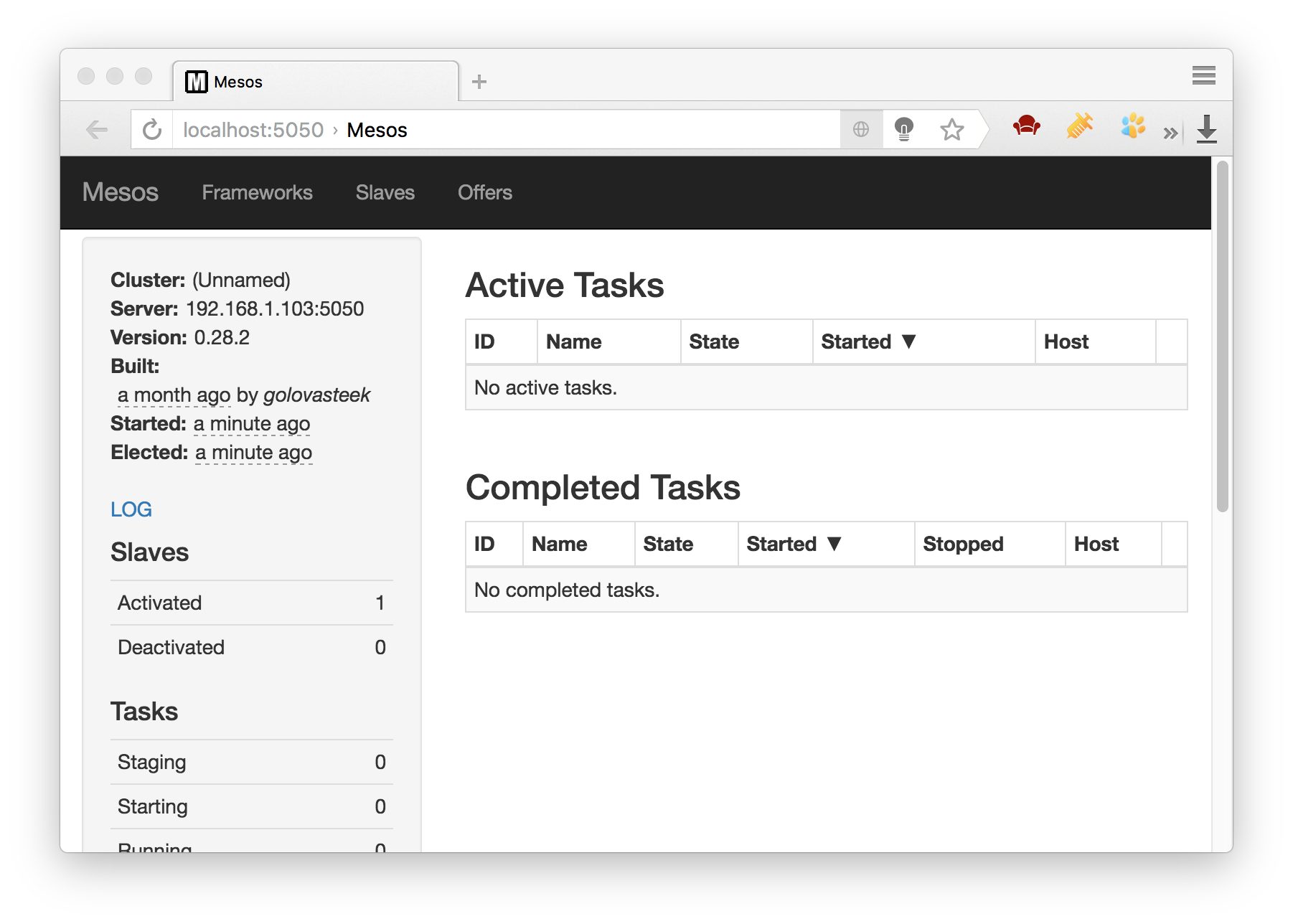
First Framework
To get started, import the necessary libraries:
import mesos.interface from mesos.interface import mesos_pb2 import mesos.native To start, we need a Scheduler, for a start we will just make a stub:
class SimpleScheduler(mesos.interface.Scheduler): pass We describe our framework:
framework = mesos_pb2.FrameworkInfo() framework.user = "" # framwork framework.name = "Simple Scheduler" Create an instance scheduler:
scheduler = SimpleScheduler() Run the driver through which the scheduler communicates with the Mesos master.
driver = mesos.native.MesosSchedulerDriver( scheduler, framework, "localhost:5050" ) driver.run() Hooray! We have created a framework that infinitely receives offers of resources, and never uses them.
Let's try running tasks. Let's start with a simple, with the execution of shell commands. For such tasks, Mesos already has a built-in Executor.
To run a task in SimpleScheduler you need to describe the resourceOffers function. This function accepts as input a driver object, which we have already created, and a list of resource offers. We will always take the first for simplicity.
class SimpleScheduler(mesos.interface.Scheduler): #... def resourceOffers(self, driver, offers): # task = mesos_pb2.TaskInfo() # task.name = "Simple Scheduler Task" # , # task.task_id.value = str(self._next_id) self._next_id +=1 # , , slave_id offer'a task.slave_id.value = offers[0].slave_id.value # command , Mesos # CommandExecutor, # shell' task.command.value = "echo Hello Mesos World" # # . cpus = task.resources.add() cpus.name = "cpus" cpus.type = mesos_pb2.Value.SCALAR cpus.scalar.value = 1 # mem = task.resources.add() mem.name = "mem" mem.type = mesos_pb2.Value.SCALAR mem.scalar.value = 1 # 1 # # , # . # -- . # -. , . driver.launchTasks([offer.id for offer in offers], [task]) In principle, this is enough to start the task (if we are not interested in its fate). You can run our script, and see the treasured lines "Hello Mesosphere World" in mesos-local logs
Apparently one article is too small to solve the task of implementing a distributed queue. We continue its decision in the second part.
Materials on the topic
Apache Mesos official documentation, http://mesos.apache.org/documentation/latest/
David Greenberg, Building Applications on Mesos, http://shop.oreilly.com/product/0636920039952.do
')
Source: https://habr.com/ru/post/306548/
All Articles