Testing Product Integration at Netflix Speed
The normal interaction of Netflix members is provided by microservice architecture and is tied personally to each of our more than 80 million members. Services belong to different teams (groups), each of which has its own development and release cycle. This means that it is necessary to have a permanent and competent integration testing team that ensures the implementation of end-to-end quality standards in a situation where microservices are deployed every day in a decentralized manner.
As a testing group for integrating developed products, we are obliged not to slow down the rate of introduction of a new one, while at the same time ensuring quality control and quick feedback for developers. Each development team is responsible for the quality of the product it supplies. Our task is to work smoothly with various technical groups with a focus on end-to-end functionality and coordination of group activities. We are a small group of integration testing specialists in an organization with more than 200 developers.
Rapid introduction of new developments in order to ensure the required quality creates interesting challenges for our team. In this article we will look at three such tasks:
')
1. Testing and monitoring of high-rating shows (High Impact Title = HIT = hit)
2. A / B testing
3. Global launch
There are many high-ranking shows - such as the television series "Orange - hit of the season," which regularly appear on Netflix. The shape and size of these shows is the most different. Some are serials, some are separate pictures; there are only children oriented; some shoot all series of the season at once, while others release several series every week. Some of these shows run with complex A / B tests, in which each element of the test has a different interaction with the participant.
These shows are highly popular with our participants and therefore should be subjected to comprehensive testing. Testing begins a few weeks before launch and goes on increasing until the very launch. After launch, we track these impressions on different hardware platforms in all countries.
Testing strategy depends on its phase. There is a different promotion strategy at different phases, which makes the task of testing / automation quite complex. Basically, two phases can be distinguished:
1. Before running the show. Before launching, it is necessary to ensure that the metadata of the display is located in the required place so that everything runs perfectly on the launch day. Since many groups (teams) participate in the launch of the hit, it is necessary to make sure that all the internal (server) systems dock with each other and with the client part of the user interface perfectly. The promotion of the show is done via Spotlight (a large window, similar to a bulletin board, at the top of the Netflix home page), through teasers and trailers. But since there is personalization at every level of Netflix, you need to create complex test suites to ensure that the type of display matches the participant’s profile. As the system is constantly changing, automation becomes difficult. The main testing on this phase is manual.
2. After launching the show. Our work does not end on launch day. We must constantly monitor the running shows, so as not to prevent the interaction with the participant from deteriorating. The show becomes part of the Netflix extended directory, and this in itself creates a problem. We must now write tests that check whether the show continues to find its audience in a consistent manner and whether the integrity of the data is preserved by this show (for example, some checks find out if the total number of episodes has changed since the launch; another check controls whether the search results continue to return in the proper search strings). But, having 600 hours of original programming on Netflix, going online only this year, in addition to licensed content, we cannot rely here on manual testing. Also, when the show is running, there are general assumptions that we can make about it, since the data for this show and the promotion logic will not change - for example, the number of episodes is greater than 0 for TV releases, the show is searchable (really like for movies, so for TV releases), etc. This allows us to automatically monitor whether certain operations related to each show continue to work correctly.
Testing hits is challenging and time bound. But participation in the launch of the show, tracking that all functions related to the show, server logic work correctly during the launch, provides an exciting experience. Watching celebrity movies and Netflix cool promo materials are also a nice addition. :)
We carry out many A / B tests . At any given time there are many A / B tests with different levels of complexity.
In the past, the bulk of testing in A / B tests was a combination of automated and manual testing: automation was used for individual components (white box testing), and end-to-end testing (black box testing) occurred mostly by hand. When the volume of A / B tests increased noticeably, it turned out to be impossible to manually perform all the required end-to-end tests, and we began to increase automation.
One of the main problems with the introduction of end-to-end automation of A / B tests has been a huge number of components to be automatically processed. Our approach was to consider testing automation as a supplied product and focus on delivering a product with minimal functionality (minimum viable product = MVP) consisting of reusable parts. Our requirement for MVP was to provide confirmation of the basic interaction with the participant by validating the data from the final REST points of various microservices. This gave us the opportunity to iteratively move to a solution instead of finding the best solution right at the start.

An essential starting point for us was the creation of a common library that provides reusability and reassignment of modules for any automated test. For example, we had an A / B test that modified the “My list” of a participant — when we automated it, we wrote a script that added the show (s) to the “My list” of the participant or deleted the show (s) from this list. These scripts were parameterized so that they could be reused in any future A / B test that dealt with My List. This approach allowed us to automate A / B tests more quickly due to the large number of reusable building blocks. Work efficiency has been enhanced by maximizing the use of existing automation. For example, instead of writing our own user interface automation program, we were able to use Netflix Test Studio to switch between test scripts that require user interface actions for various devices.
When choosing a language / platform for implementing our automation, we proceeded from the need to provide quick feedback for product development teams. This required a really fast test complex - literally in seconds. We also sought to make our tests as easy as possible for implementation and distribution. Bearing in mind these two requirements, we abandoned our first choice - Java. Our tests would be dependent on the use of many interconnected jar files, and would have to deal with dependency management, version control, and being exposed to changes in different versions of the JAR file format. All this would significantly increase the duration of the tests.
We decided to introduce our automation by accessing microservices through their final REST points, so that we could customize the use of jar files and not write any business logic. To ensure ease of implementation and distribution of our automation, we decided to use a combination of a parameterized shell and python scripts that can be executed from the command line. It should have been a separate shell script to control the execution of the test script, during which other shell scripts and python scripts acting as reusable utilities should be called.

This approach has several positive points:
1. We were able to get the test duration (including the time to install and detach) 4-90 seconds; the median running time is 40 seconds. When using Java-based automation, the median runtime could be 5-6 minutes.
2. Continuous integration has been simplified. All we needed was the Jenkins Job system, which performs a downward download from our repository, runs the required scripts, and logs the results. The console analysis of records built into Jenkins turned out to be sufficient for obtaining the “passed / failed” test.
3. Easy start. In order for a third-party specialist to launch our test suite, you only need access to our git repository and terminal.
One of our biggest projects in 2015 was to make sure that we had sufficient integration testing to ensure that Netflix runs smoothly in 130 countries. In fact, we needed to automate, at a minimum, a test complex for general performance for each combination of country and language. This markedly complicated the functionality of our automation product.
Our tests worked fairly quickly, so we initially decided that it would be enough to run the test program in a loop for each combination of country and language. The result was that the tests, which took about 15 seconds, began to work for an hour or more. It was necessary to find a more acceptable approach to this problem. In addition, each testing protocol has grown about 250 times, which has made failure analysis more difficult. To deal with these problems, we did two things:
1. We used the Jenkins Matrix plug-in to parallelize our tests, so that tests for each country began to run in parallel. We also had to configure our Jenkins slaves to use different artists so that other tasks did not stand in line when our tests encountered any adversarial situation or endless cycles. This was doable for us, because our automation had only costs associated with running shell scripts, and there was no need to preload the binary files.
2. We did not want to refactor each test written up to this point, and we didn’t want each test to work with each country / language combination. As a result, we decided to use the “on demand” model, in which we could continue to write automated tests as we did before, and to add it to global readiness, we would add an add-on to it. This add-on should contain the test case ID and country / language combination as parameters, and then should run the test case with these parameters, as shown below:
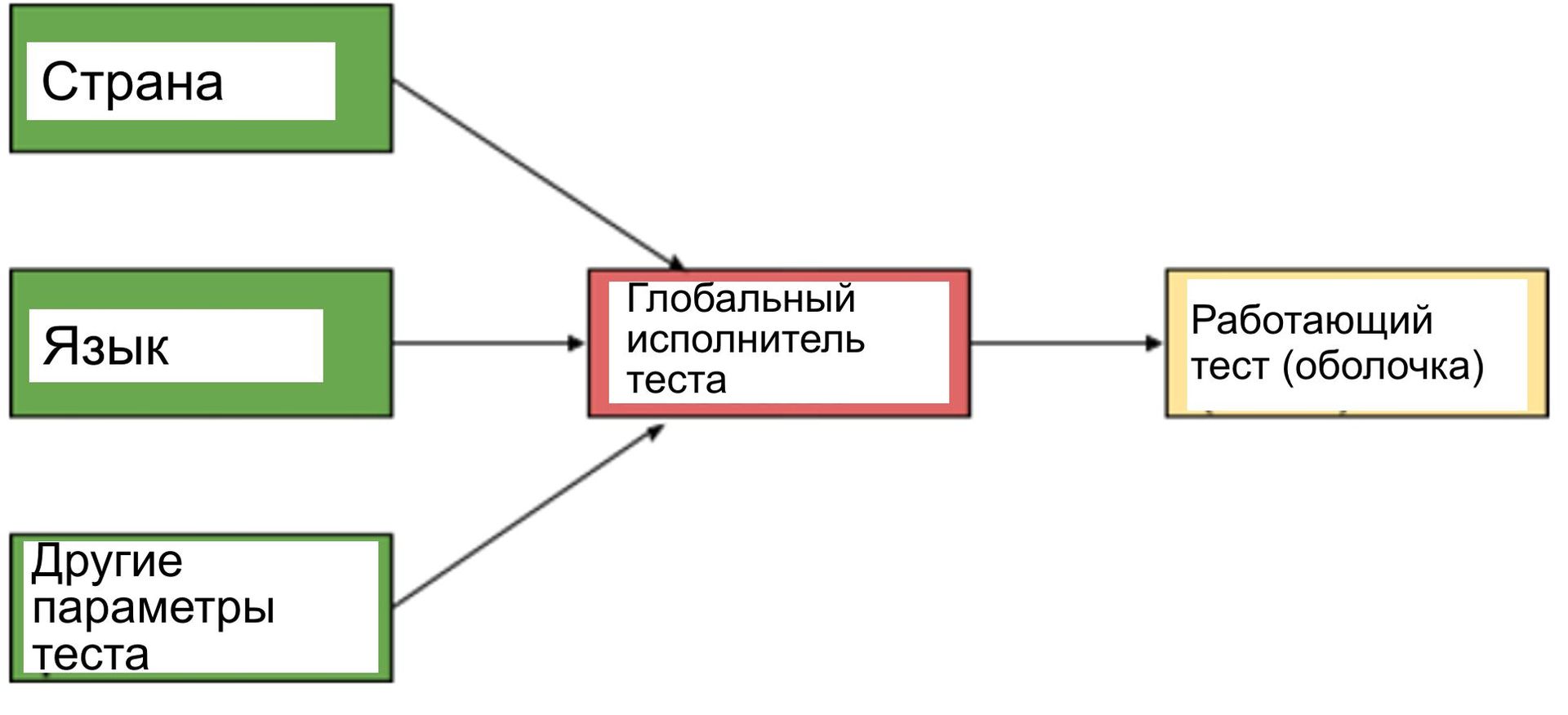
Currently, automated tests work globally, closing all high-priority integration test suites, including monitoring of hits in all regions where such a show is available.
The pace of the introduction of new does not slow down on Netflix - it only grows. Therefore, our automation product continues to evolve. Here are some of the projects on our roadmap:
1. Tests based on workflow. They should include presenting the test suite as a workflow or as a series of steps to simulate the flow of data through the Netflix service funnel. The motive for this is to reduce the cost of analyzing test failures due to the easy identification of the step in which the test failed.
2. Embedding alerts. There are several warning systems in Netflix. But the inclusion of certain warnings is sometimes irrelevant to the implementation of the corresponding test complexes. This is caused by the fact that tests depend on services that may not function 100% and may be completely faulty, giving us inapplicable results. You need to create a system that can analyze these warnings and then determine which tests should be run.
3. Accounting for clutter. Our tests currently suggest that the Netflix environment is 100% functioning, but this is not always the case. A team of reliability experts constantly performs disarray tests to test the complete integrity of the system. Currently, test automation results in a degraded environment show a failure rate of more than 90%. We need to improve our test automation to ensure consistent results when working in a degraded environment.
As a testing group for integrating developed products, we are obliged not to slow down the rate of introduction of a new one, while at the same time ensuring quality control and quick feedback for developers. Each development team is responsible for the quality of the product it supplies. Our task is to work smoothly with various technical groups with a focus on end-to-end functionality and coordination of group activities. We are a small group of integration testing specialists in an organization with more than 200 developers.
Rapid introduction of new developments in order to ensure the required quality creates interesting challenges for our team. In this article we will look at three such tasks:
')
1. Testing and monitoring of high-rating shows (High Impact Title = HIT = hit)
2. A / B testing
3. Global launch
Testing and monitoring of high-ranking shows
There are many high-ranking shows - such as the television series "Orange - hit of the season," which regularly appear on Netflix. The shape and size of these shows is the most different. Some are serials, some are separate pictures; there are only children oriented; some shoot all series of the season at once, while others release several series every week. Some of these shows run with complex A / B tests, in which each element of the test has a different interaction with the participant.
These shows are highly popular with our participants and therefore should be subjected to comprehensive testing. Testing begins a few weeks before launch and goes on increasing until the very launch. After launch, we track these impressions on different hardware platforms in all countries.
Testing strategy depends on its phase. There is a different promotion strategy at different phases, which makes the task of testing / automation quite complex. Basically, two phases can be distinguished:
1. Before running the show. Before launching, it is necessary to ensure that the metadata of the display is located in the required place so that everything runs perfectly on the launch day. Since many groups (teams) participate in the launch of the hit, it is necessary to make sure that all the internal (server) systems dock with each other and with the client part of the user interface perfectly. The promotion of the show is done via Spotlight (a large window, similar to a bulletin board, at the top of the Netflix home page), through teasers and trailers. But since there is personalization at every level of Netflix, you need to create complex test suites to ensure that the type of display matches the participant’s profile. As the system is constantly changing, automation becomes difficult. The main testing on this phase is manual.
2. After launching the show. Our work does not end on launch day. We must constantly monitor the running shows, so as not to prevent the interaction with the participant from deteriorating. The show becomes part of the Netflix extended directory, and this in itself creates a problem. We must now write tests that check whether the show continues to find its audience in a consistent manner and whether the integrity of the data is preserved by this show (for example, some checks find out if the total number of episodes has changed since the launch; another check controls whether the search results continue to return in the proper search strings). But, having 600 hours of original programming on Netflix, going online only this year, in addition to licensed content, we cannot rely here on manual testing. Also, when the show is running, there are general assumptions that we can make about it, since the data for this show and the promotion logic will not change - for example, the number of episodes is greater than 0 for TV releases, the show is searchable (really like for movies, so for TV releases), etc. This allows us to automatically monitor whether certain operations related to each show continue to work correctly.
Testing hits is challenging and time bound. But participation in the launch of the show, tracking that all functions related to the show, server logic work correctly during the launch, provides an exciting experience. Watching celebrity movies and Netflix cool promo materials are also a nice addition. :)
A / B testing
We carry out many A / B tests . At any given time there are many A / B tests with different levels of complexity.
In the past, the bulk of testing in A / B tests was a combination of automated and manual testing: automation was used for individual components (white box testing), and end-to-end testing (black box testing) occurred mostly by hand. When the volume of A / B tests increased noticeably, it turned out to be impossible to manually perform all the required end-to-end tests, and we began to increase automation.
One of the main problems with the introduction of end-to-end automation of A / B tests has been a huge number of components to be automatically processed. Our approach was to consider testing automation as a supplied product and focus on delivering a product with minimal functionality (minimum viable product = MVP) consisting of reusable parts. Our requirement for MVP was to provide confirmation of the basic interaction with the participant by validating the data from the final REST points of various microservices. This gave us the opportunity to iteratively move to a solution instead of finding the best solution right at the start.
An essential starting point for us was the creation of a common library that provides reusability and reassignment of modules for any automated test. For example, we had an A / B test that modified the “My list” of a participant — when we automated it, we wrote a script that added the show (s) to the “My list” of the participant or deleted the show (s) from this list. These scripts were parameterized so that they could be reused in any future A / B test that dealt with My List. This approach allowed us to automate A / B tests more quickly due to the large number of reusable building blocks. Work efficiency has been enhanced by maximizing the use of existing automation. For example, instead of writing our own user interface automation program, we were able to use Netflix Test Studio to switch between test scripts that require user interface actions for various devices.
When choosing a language / platform for implementing our automation, we proceeded from the need to provide quick feedback for product development teams. This required a really fast test complex - literally in seconds. We also sought to make our tests as easy as possible for implementation and distribution. Bearing in mind these two requirements, we abandoned our first choice - Java. Our tests would be dependent on the use of many interconnected jar files, and would have to deal with dependency management, version control, and being exposed to changes in different versions of the JAR file format. All this would significantly increase the duration of the tests.
We decided to introduce our automation by accessing microservices through their final REST points, so that we could customize the use of jar files and not write any business logic. To ensure ease of implementation and distribution of our automation, we decided to use a combination of a parameterized shell and python scripts that can be executed from the command line. It should have been a separate shell script to control the execution of the test script, during which other shell scripts and python scripts acting as reusable utilities should be called.
This approach has several positive points:
1. We were able to get the test duration (including the time to install and detach) 4-90 seconds; the median running time is 40 seconds. When using Java-based automation, the median runtime could be 5-6 minutes.
2. Continuous integration has been simplified. All we needed was the Jenkins Job system, which performs a downward download from our repository, runs the required scripts, and logs the results. The console analysis of records built into Jenkins turned out to be sufficient for obtaining the “passed / failed” test.
3. Easy start. In order for a third-party specialist to launch our test suite, you only need access to our git repository and terminal.
Global launch
One of our biggest projects in 2015 was to make sure that we had sufficient integration testing to ensure that Netflix runs smoothly in 130 countries. In fact, we needed to automate, at a minimum, a test complex for general performance for each combination of country and language. This markedly complicated the functionality of our automation product.
Our tests worked fairly quickly, so we initially decided that it would be enough to run the test program in a loop for each combination of country and language. The result was that the tests, which took about 15 seconds, began to work for an hour or more. It was necessary to find a more acceptable approach to this problem. In addition, each testing protocol has grown about 250 times, which has made failure analysis more difficult. To deal with these problems, we did two things:
1. We used the Jenkins Matrix plug-in to parallelize our tests, so that tests for each country began to run in parallel. We also had to configure our Jenkins slaves to use different artists so that other tasks did not stand in line when our tests encountered any adversarial situation or endless cycles. This was doable for us, because our automation had only costs associated with running shell scripts, and there was no need to preload the binary files.
2. We did not want to refactor each test written up to this point, and we didn’t want each test to work with each country / language combination. As a result, we decided to use the “on demand” model, in which we could continue to write automated tests as we did before, and to add it to global readiness, we would add an add-on to it. This add-on should contain the test case ID and country / language combination as parameters, and then should run the test case with these parameters, as shown below:
Currently, automated tests work globally, closing all high-priority integration test suites, including monitoring of hits in all regions where such a show is available.
Problems of the future
The pace of the introduction of new does not slow down on Netflix - it only grows. Therefore, our automation product continues to evolve. Here are some of the projects on our roadmap:
1. Tests based on workflow. They should include presenting the test suite as a workflow or as a series of steps to simulate the flow of data through the Netflix service funnel. The motive for this is to reduce the cost of analyzing test failures due to the easy identification of the step in which the test failed.
2. Embedding alerts. There are several warning systems in Netflix. But the inclusion of certain warnings is sometimes irrelevant to the implementation of the corresponding test complexes. This is caused by the fact that tests depend on services that may not function 100% and may be completely faulty, giving us inapplicable results. You need to create a system that can analyze these warnings and then determine which tests should be run.
3. Accounting for clutter. Our tests currently suggest that the Netflix environment is 100% functioning, but this is not always the case. A team of reliability experts constantly performs disarray tests to test the complete integrity of the system. Currently, test automation results in a degraded environment show a failure rate of more than 90%. We need to improve our test automation to ensure consistent results when working in a degraded environment.
Source: https://habr.com/ru/post/306460/
All Articles