Part 2. DSS Universal Algorithms - Support Service Algorithm
The following article describes another approach to implementing a decision support system. Based on this DSS, an algorithm was implemented for the support service.
Initial state - I managed the implementation and maintenance service in a private medical company. The branch network of branches in the regions, which operates under a single system. Similar equipment is used at all sites. Virtually all equipment is connected to the system and gives data (dialysis machines, laboratory analyzers, ultrasound machines and cardiographs, weight and pressure meters, water treatment, ventilation system, temperature and humidity sensors).
The branch network is constantly expanding. Each branch has an IT specialist. Not always this specialist is competent in various fields. The task was quite ambitious to ensure the performance of a rather complex from the point of implementation of the system.
Description of incidents by Level 1 support specialists. This refers to the fact that everyone described the same mistake as he could, how he wanted, how he had enough imagination ... It is hard to enumerate all the variations. I also wanted to reduce the time to solve incidents. Especially those that have already happened and been described once. That is, it was necessary to ensure maximum closure of incidents at the 1st level of support with a sufficiently high speed and quality.
')
I do not like the existing way of describing the Knowledge Base. Because the same error can be caused by various reasons. Accordingly, the description of solutions should be multiple. What really is not. And the search for a solution itself is quite long in terms of the required number of steps. By and large, usually the Knowledge Base is a collection of files.
Not least and accurate description of the solution. It is important to take into account the concept of "best practice". Just give an example. When the pre-configured self-service post partially stopped working in the morning - the touchscreen stopped working, the IT specialist spent 2 hours and 5 minutes to resolve the incident. I did not specifically intervene to observe the actions and see the result. The reason was that the nurse with a mop slightly pulled out the USB cable of the touchscreen. With the help of algorithms, this problem was eliminated for a maximum of 5 minutes.
Therefore, I wanted to use the advantage of an automated solution based on DSS, which would allow me to solve a specific large-scale task. At the same time, expand the practice to all departments. Especially important for newly opened offices and new IT professionals. Because over time, the system became more complex and more and more different equipment was connected to it.
I wanted to take advantage of the system - the formation of a protocol that describes the steps of the passage of the algorithm. That is, to solve the problem of how to consistently describe incidents - copy-paste the protocol into the application.
In Algorithm-Designer, the primary structure of the algorithm was created, where sections were created to describe:
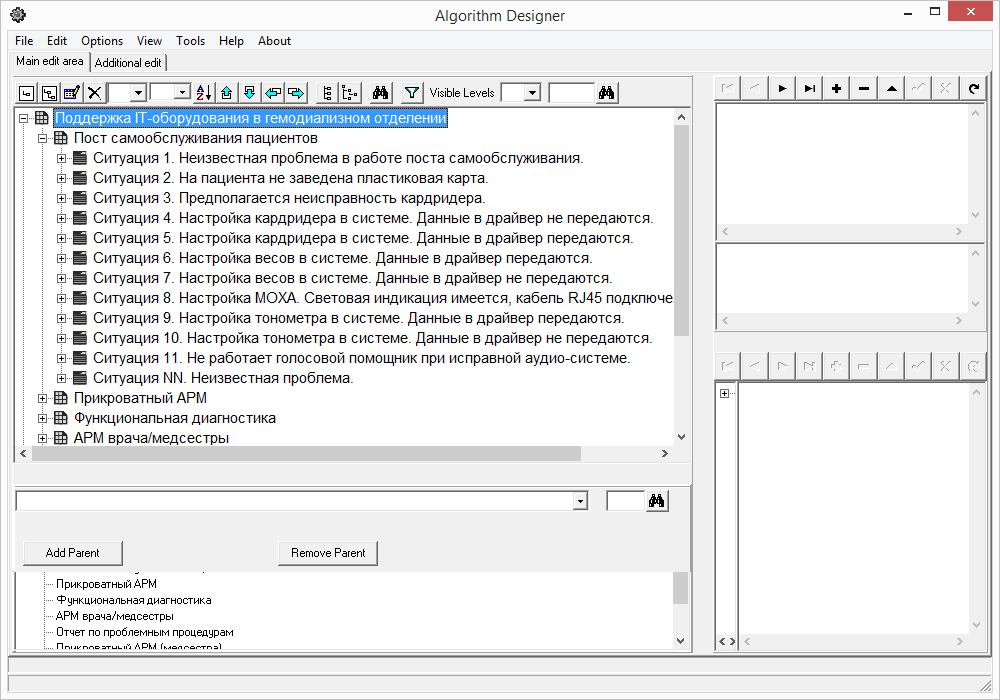
To begin with, the patient self-care post was selected. Because patients at the beginning and at the end of each shift passed through this post. And the failure of the self-service post could lead to a delay of each shift.
Post self-service patients:
• System unit
• Touch Screen Monitor
• Speakers (used for voice assistant)
• Card reader (used to identify the patient)
• Scales
• Pressure meter
• Printer
• Speech synthesizer
• The MaximusDriver program, which is responsible for all connected equipment
• Maximus program running in self-service post mode
Since the Scales and the Blood Pressure Monitor transmit data through the COM port, there were connection variations:
• Via COM port
• Using MOXA
• Via USB-COM adapter
Accordingly, it was necessary to take into account these variations. As well as the fact that the models of Libra and Blood Pressure Meters could also change.
The algorithm was filled in with the availability of free time and awareness of how it should work. Also, several decisions were made immediately after the incidents occurred and resolved.
The first situation was initially developed, which allowed to localize the problem.
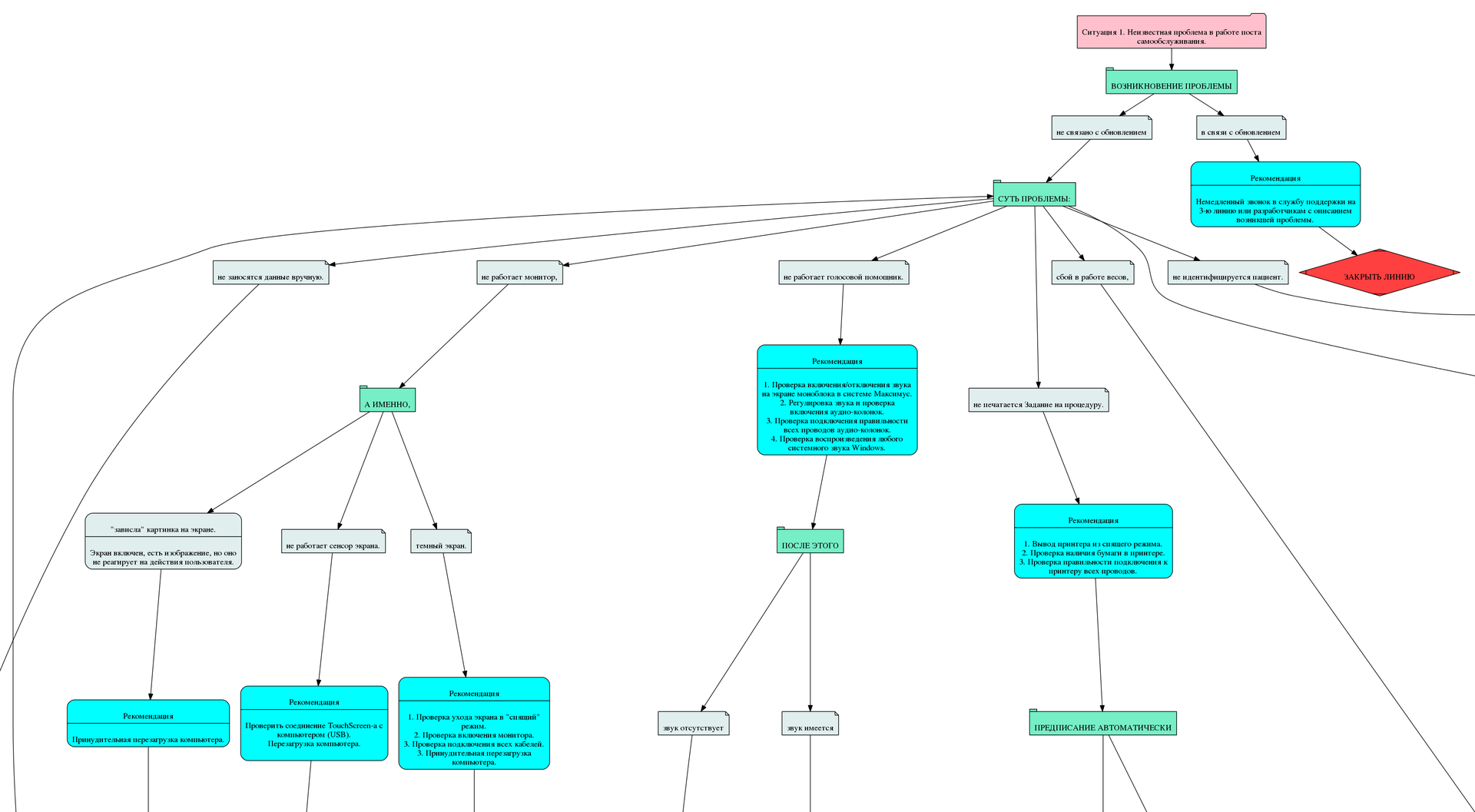
The remaining situations have already allowed to solve a specific localized problem.
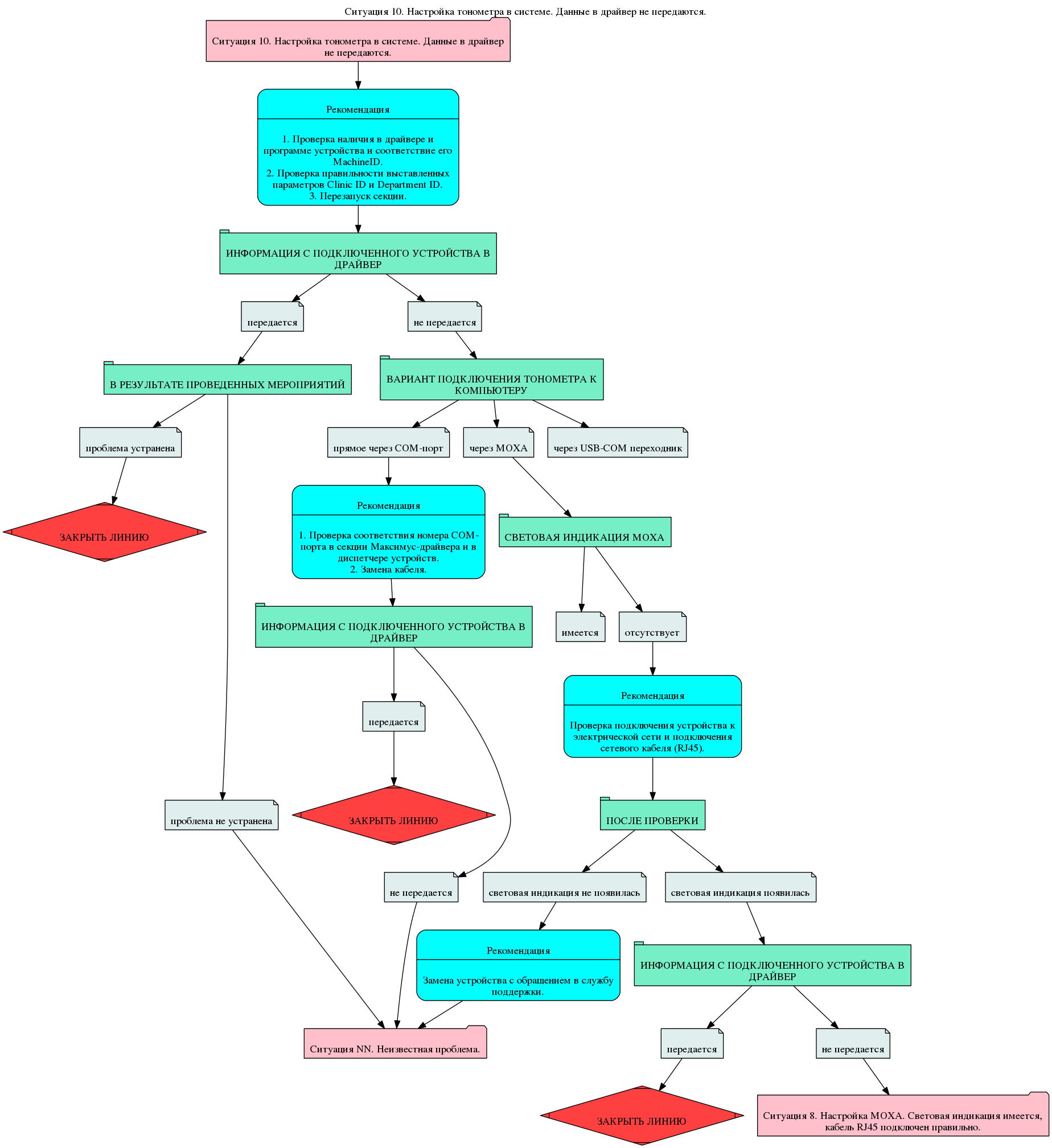
When diagnosing at the very beginning, it is established whether an error occurred as a result of updating the system. I will explain why. The fact is that the system update took place simultaneously in all branches. Accordingly, they all used the same version of the Database and the same version of the binary files. That is, errors in the system were also common. The detected and corrected error for one branch was automatically relayed to all branches.
The situation of localization of the problem turned out to be more ambitious. The situations themselves are more concise.
Also, the situation was a stub. That is, if all the described diagnostic methods and solutions did not help, the system addresses a stub for this situation. It contains a recommendation to transfer to the next level of support.
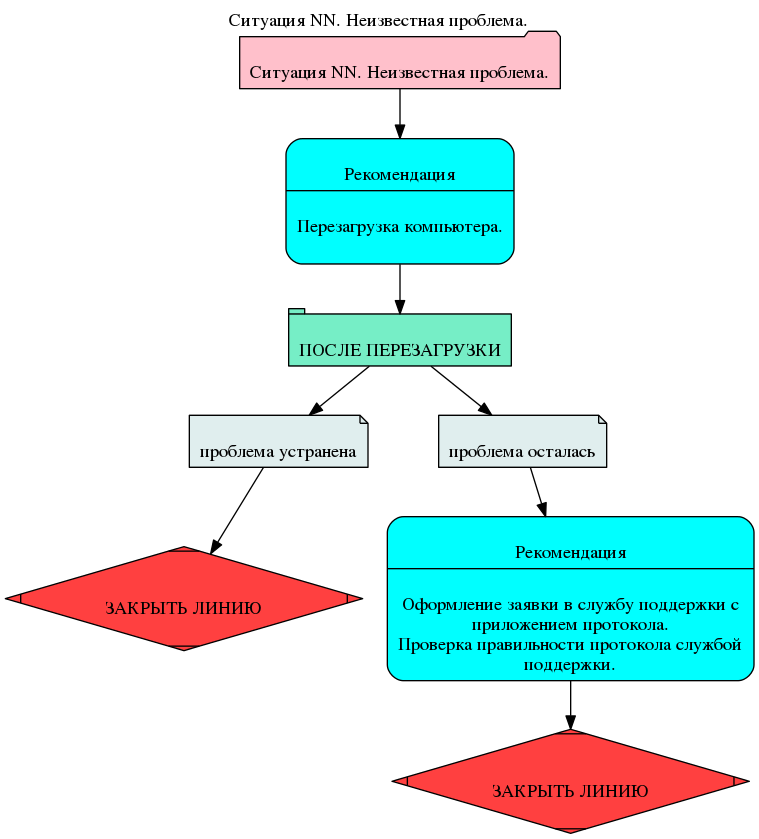
In general, the method of creating DSS allows you to create stubs for cases that have not yet been described. That allows you to actually use the system immediately without the risk that an error will occur if there is no description of a section.
The printing function of the algorithm diagrams made it possible to visually evaluate a chain of actions and recommendations.
There was also a desire to realize the ability to control for deviations. What does this mean? Usually analysis of failures, downtime, etc. Held at the end of the month or week. What gives purely statistical information. For her, of course, it is possible and necessary to make management decisions. But objectively it is ineffective.
Call me an idealist. But here we are talking about a completely normal method of control and management. That is, the ability to identify the incident and the ability to intervene or connect to fix it. That is avoiding downtime. For this purpose, an interface was planned that would display the current passes by local IT specialists in algorithms. That is, it would be possible to see in the form of a protocol what the incident was and at what stage of its decision the specialist is. Accordingly, to respond and connect additional forces from the central office. Today, such a panel is designed.
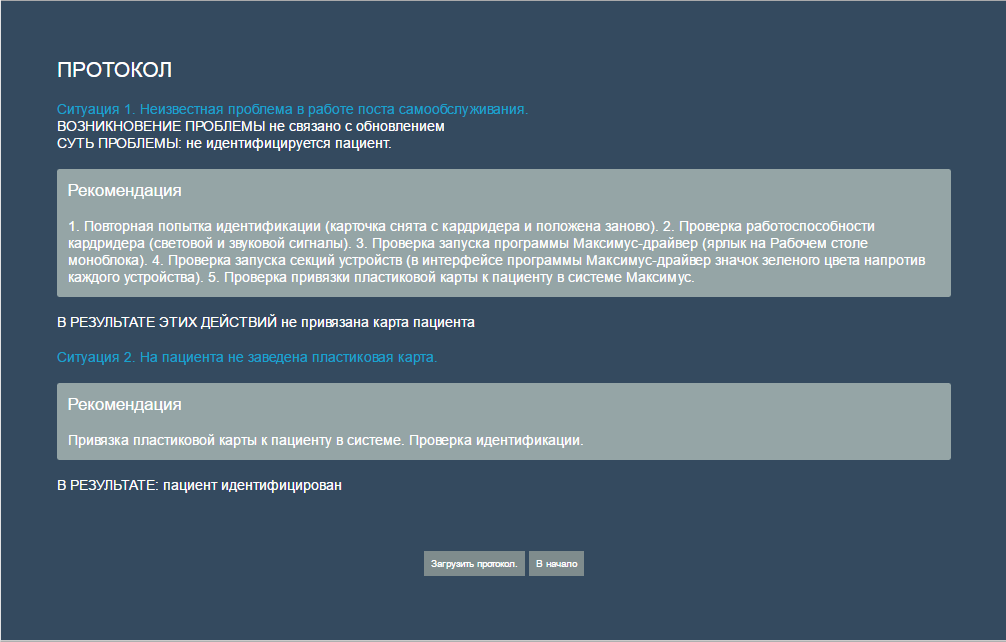
An example of the received protocol after passing by the algorithm:
An example of a Telegram chat bot that runs on the core of DSS from Part 3. The Telegram chat bot on the core of DSS logic : @DSSUABot
Initial state - I managed the implementation and maintenance service in a private medical company. The branch network of branches in the regions, which operates under a single system. Similar equipment is used at all sites. Virtually all equipment is connected to the system and gives data (dialysis machines, laboratory analyzers, ultrasound machines and cardiographs, weight and pressure meters, water treatment, ventilation system, temperature and humidity sensors).
The branch network is constantly expanding. Each branch has an IT specialist. Not always this specialist is competent in various fields. The task was quite ambitious to ensure the performance of a rather complex from the point of implementation of the system.
Problem
Description of incidents by Level 1 support specialists. This refers to the fact that everyone described the same mistake as he could, how he wanted, how he had enough imagination ... It is hard to enumerate all the variations. I also wanted to reduce the time to solve incidents. Especially those that have already happened and been described once. That is, it was necessary to ensure maximum closure of incidents at the 1st level of support with a sufficiently high speed and quality.
')
I do not like the existing way of describing the Knowledge Base. Because the same error can be caused by various reasons. Accordingly, the description of solutions should be multiple. What really is not. And the search for a solution itself is quite long in terms of the required number of steps. By and large, usually the Knowledge Base is a collection of files.
Not least and accurate description of the solution. It is important to take into account the concept of "best practice". Just give an example. When the pre-configured self-service post partially stopped working in the morning - the touchscreen stopped working, the IT specialist spent 2 hours and 5 minutes to resolve the incident. I did not specifically intervene to observe the actions and see the result. The reason was that the nurse with a mop slightly pulled out the USB cable of the touchscreen. With the help of algorithms, this problem was eliminated for a maximum of 5 minutes.
Therefore, I wanted to use the advantage of an automated solution based on DSS, which would allow me to solve a specific large-scale task. At the same time, expand the practice to all departments. Especially important for newly opened offices and new IT professionals. Because over time, the system became more complex and more and more different equipment was connected to it.
I wanted to take advantage of the system - the formation of a protocol that describes the steps of the passage of the algorithm. That is, to solve the problem of how to consistently describe incidents - copy-paste the protocol into the application.
Implementation
In Algorithm-Designer, the primary structure of the algorithm was created, where sections were created to describe:
To begin with, the patient self-care post was selected. Because patients at the beginning and at the end of each shift passed through this post. And the failure of the self-service post could lead to a delay of each shift.
Post self-service patients:
• System unit
• Touch Screen Monitor
• Speakers (used for voice assistant)
• Card reader (used to identify the patient)
• Scales
• Pressure meter
• Printer
• Speech synthesizer
• The MaximusDriver program, which is responsible for all connected equipment
• Maximus program running in self-service post mode
Since the Scales and the Blood Pressure Monitor transmit data through the COM port, there were connection variations:
• Via COM port
• Using MOXA
• Via USB-COM adapter
Accordingly, it was necessary to take into account these variations. As well as the fact that the models of Libra and Blood Pressure Meters could also change.
The algorithm was filled in with the availability of free time and awareness of how it should work. Also, several decisions were made immediately after the incidents occurred and resolved.
The first situation was initially developed, which allowed to localize the problem.
The remaining situations have already allowed to solve a specific localized problem.
Principle of operation.
When diagnosing at the very beginning, it is established whether an error occurred as a result of updating the system. I will explain why. The fact is that the system update took place simultaneously in all branches. Accordingly, they all used the same version of the Database and the same version of the binary files. That is, errors in the system were also common. The detected and corrected error for one branch was automatically relayed to all branches.
The situation of localization of the problem turned out to be more ambitious. The situations themselves are more concise.
Also, the situation was a stub. That is, if all the described diagnostic methods and solutions did not help, the system addresses a stub for this situation. It contains a recommendation to transfer to the next level of support.
In general, the method of creating DSS allows you to create stubs for cases that have not yet been described. That allows you to actually use the system immediately without the risk that an error will occur if there is no description of a section.
The printing function of the algorithm diagrams made it possible to visually evaluate a chain of actions and recommendations.
There was also a desire to realize the ability to control for deviations. What does this mean? Usually analysis of failures, downtime, etc. Held at the end of the month or week. What gives purely statistical information. For her, of course, it is possible and necessary to make management decisions. But objectively it is ineffective.
Call me an idealist. But here we are talking about a completely normal method of control and management. That is, the ability to identify the incident and the ability to intervene or connect to fix it. That is avoiding downtime. For this purpose, an interface was planned that would display the current passes by local IT specialists in algorithms. That is, it would be possible to see in the form of a protocol what the incident was and at what stage of its decision the specialist is. Accordingly, to respond and connect additional forces from the central office. Today, such a panel is designed.
An example of the received protocol after passing by the algorithm:
An example of a Telegram chat bot that runs on the core of DSS from Part 3. The Telegram chat bot on the core of DSS logic : @DSSUABot
Source: https://habr.com/ru/post/306450/
All Articles