Strata + Hadoop 2016 review

In the last year, Badoo began to actively use the Hadoop + Spark bundle and built their own system for collecting and processing tens of millions of metrics using Spark Streaming.
In order to expand our knowledge and get acquainted with the latest innovations in this field, at the end of May this year, the developers of the BI (Business Intelligence) department went to London, where the next Hadoop + Strata conference took place, dedicated to a wide range of issues in machine learning, processing and big data analysis.
First of all, we were interested in the technology stack that we use. For reports on Spark, a whole stream was highlighted, which featured creators, active "contributors" and authors of books from Cloudera, Databricks, Hortonworks and IBM.
The conference was organized by O'Reilly, known to all as an IT publishing company, publishing books with fancy animals on the covers, and Cloudera IT company specializing in Hadoop-based solutions.
')
This year, the venue for the conference was the huge London ExCel showroom . Its size shakes the imagination. It is located between the two stations of the DLR train, and if you don’t know in which part the event will take place, you can spend 15-20 minutes to walk from one end of the building to the other.
No less ambitious was the scope of the event itself. The conference lasted 4 days, from Tuesday to Friday. In the first two days, introductory lectures, seminars and master classes were held, and in the following days, the conference itself. As, probably, and it is necessary to the conference devoted to work with big data, the information volume presented on it was enormous. It began with a series of eight (!) Plenary reports, after which more than 10 parallel sections opened, each with 6 hourly reports.
With such a tight schedule, the organizers should pay more attention to how to make it understandable. It would be possible, for example, to indicate the topics of each section, or to make a division of reports by target audience (ie, divided into reports for engineers, analysts and business representatives).
Instead, during registration sheets A3 were distributed with a timetable written in the smallest font. True, as an alternative, it was possible to use a mobile application, in which there was an opportunity to track events that are currently taking place and to make up their own schedule.
Each day of the conference opened with a series of short keynotes, in which the speakers for 10-15 minutes shared their views on the main trends in the field of artificial intelligence, data analysis, machine learning, security. After these presentations, sections with reports were opened. About the reports that seemed to us the most interesting, we will tell in today's review.
Spark 2.0 What's next?
The first in the section devoted to Apache Spark was Tathagata Daz, the developer from Databricks (he immediately noted that no one could speak his name, so everyone calls him just TD). In his report, he talked about what to expect in the release of Apache Spark 2.0.
TD announced that a major release is scheduled for June this year. At the time of this writing, only the unstable preview release version is still available to everyone. Also, the speaker assured that despite the "major" release, backward compatibility with 1.x is almost completely preserved.
Now directly about the promised breakthrough features of this release:
- Tungsten Phase 2 . The Tungsten project is a set of optimizations aimed at improving memory performance and iron utilization in the Spark framework. The updated version promises to accelerate the work of Tungsten 5-10 times. It was achieved by optimizing code generation and improving memory algorithms. If earlier a request from several consecutive operations required a chain of virtual calls, now it will be compiled into a single piece of code.
- Structured Streaming . Having received a lot of feedback from the developers, the Spark team seriously reworked the streaming model. The updated version involves the use of "interactive" streaming called Structured Streaming, in which it will be possible at runtime to perform various requests on the existing stream and build machine learning models. In fact, this is a high-level API built on top of the SQL API. Thanks to this streaming should get all the optimizations from Tungsten.
- Datasets and DataFrames . In the new version, when creating the DataFrame = Dataset [Row] object, these two APIs are merged. This makes it possible to perform operations on map, filter, etc. on DataFrame objects in the Dateset. The Dataset functionality is marked as experimental and is one of those places where compatibility with 1.x versions breaks.

If you are developing applications on Spark, then be sure to take the time in the summer to prepare and switch to the new version. API improvements and performance gains promise to be impressive.
A very similar report from the Spark Summit from Matei Zaharia, CTO Databricks and the creator of Spark can be found here: Spark 2.0 .
The future of streaming in Spark. Structured streaming
The second report from TD at the conference was a more detailed story about how Spark Streaming will develop - a component of the framework that is responsible for fast and fault-tolerant real-time data stream processing. According to the speaker, more than half of developers using Spark believe that Spark Streaming is the most important component of the system.
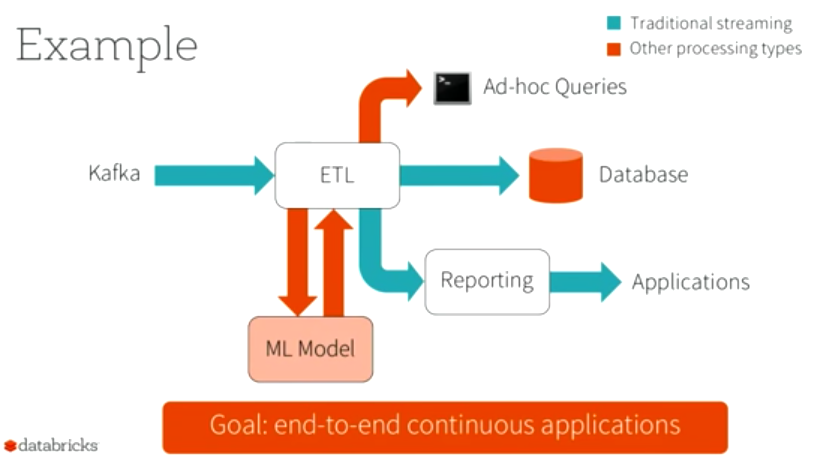
The main conclusion that the developers have made during the 3 years of the existence of streaming: this process should not occur in isolation. Users need not just to get the data stream, process it and put it in the database for later use. In most cases, it is also necessary to connect monitoring to this stream, collect data for machine learning, etc.
In this regard, the developers began to think more broadly and call the new project not just Streaming, but Continuous Applications, within which all of the above features will be added.
TD reviewed the main problem areas of the current D-Streams model, after which it introduced a new solution called Structured Streaming.
Structured Streaming is a new concept that offers a look at streaming as a job with an infinite table.

Data from this table can be queried using SQL queries through the DataFrames API. Depending on what the user needs, the request can be called for all data, or only for the delta of the data received.
Due to the integration of the API dstreams and DataFrames it became possible to perform operations of combining data from the stream with a static set.
Also in this report, we looked at how the new system works “under the hood” and, most importantly, how to achieve fault tolerance.
If you build complex systems on top of Spark Streaming, then you should definitely explore the new concept of Structured Streaming, because, according to the developers, you will get fast, fault-resistant streaming with the most simplified API.
The specification can be read here: Structured Streaming Programming Abstraction Semanticsand APIs .
A recording of a similar report from the same author, but with the Spark Summit, can be found here: A Deep Dive Into Structured Streaming
Scheduled Lunch
In between the presentations, the organizers arranged completely standard coffee breaks, and at one o'clock the lunch began. Unlike many IT conferences, lunch at Hadoop + Strata was not an option, but was provided by conference sponsors. For example, on the first day, lunches from Teradata were cold and bland, and on the second day, from IBM, hearty and hot.
Beyond shuffling by Holden Karau

An extravagant speaker at the ringing of metal rings around her neck told a lot of interesting things about Spark's insides.
The Spark task is running, the Shuffle stage time comes and ... OOM-killer!
And you want happiness and cats. Speaking of cats: there were plenty of them in the report. Well, they like her. Do not attach importance, just "mi-mi-mi" and that's it.
So, from where can excess memory consumption and performance drop occur?
- Perform unnecessary grouping by key. If possible, you need to use not groupByKey, but reduceByKey. This immediately reduces the amount of data.
- Unevenly distributed data. If there is much more data for one key than for the others, then after performing shuffle, all these data will fall on one reducer and ... OOM-killer is right there! Therefore, a replacement shuffler may be useful.
- The need to use join with other data sets. Well, this is generally the trouble of all map-reduce-algorithms, because it is impossible to reduce the amount of data, you can only increase. We must be careful that there is no explosive increase.
All this is analyzed and explained, suggested solutions. It is told what problems may lie in wait for further optimizations.
And of course, where are the new features of the upcoming Spark 2.0?
Then it was about unit testing for Spark. And for a snack - an offer to send a non-optimizable code.
In general, it was interesting and informative, although without application in practice, not all and not everything is clear.
Slides to the report on Slideshare
Demonstrations at the stands
At the stands of the companies it was possible to talk with their representatives, and at some - with the authors of the products.
For example, at the MapR stand, Ted Dunning showed me how MapR-FS works. I mounted the cluster as a home directory, in one console I began to periodically write the current time to the file, and in the other I started tail -f . In general, cool! We just work with files, and the file system itself is involved in servers, replication, and all the rest. And, again, you can read the data not only as files mounted to the client FS, but also use it in Hive / Spark for processing.
This FS has a community version. I think we should try to use!
Securing Apache Spark on production Hadoop clusters

If you have to configure the security of Spark or Hadoop - definitely add this performance to your bookmarks! First, the speaker told a little about the history of the development of the security system in Hadoop, what components it includes. In general, initially no security was intended there, everything appeared much later, and this partly explains how everything works.
Data security in Spark is based on data security in Hadoop. Therefore, the story begins with Kerberos to authorize users and configure HDFS / YARN.
So, we protect everything in order:
- user authorization;
- HDFS;
- YARN;
- Web UI;
- PRC API;
- EncryptedFS;
- on-the-wire data encryption;
- JVM memory;
- encryption of temporary shuffle blocks.
Uh, like I forgot nothing. If you forgot - everything is in the report!
Then it was told what are the options for distributing privileges: at the file level, at the level of the Hive tables, at the row and column levels. When what are possible, how different.
It is told about the prospects of security development in Spark.
So now I know everything about security. Well, I think.
A similar report from Hadoop Summit can be viewed here Securing Spark on Production Hadoop Clusters
Bread and Spectacles

At the end of the first day of the reports, two afterparty took place immediately. At first, most of the speakers and participants of the conference went to the exhibition hall, where, right at the sponsors' stands, the organizers put on alcoholic and soft drinks and hot snacks, which reduced the degree of formality of the event to a minimum and warmed up the audience for the second party - the traditional London fun when participants spend the evening moving from one pub to another along a certain route).
During the day, the organizers and volunteers distributed to the participants of the conference “route sheets”, in which a chain of 4 London pubs was indicated, in which it was necessary to “relax” consistently. As well as lunch, beer and snacks in pubs were provided by sponsors. Some establishments were fully rented for the whole evening; in others, the participants were terrified by local patrons.

On the morning of the next day, it was easy to distinguish the participants who were able to visit all the pubs by dented faces and prize hoods.
After a stormy night, not everyone was able to come to the second day of the conference. But we could and even got a couple of interesting reports. Next we share our impressions.
Why is my Hadoop job slow?
Cognitive report about the tools for monitoring the status of Apache Ambari Hadoop cluster.
Examples of using Ambari Metrics System, standard dashboards on subsystems (HDFS, YARN, HBase) are given.
Shown and specific cases of observed situations.

It is shown how and what can be detected in the HDFS and YARN audit logs, how to work with logs through Ambari.
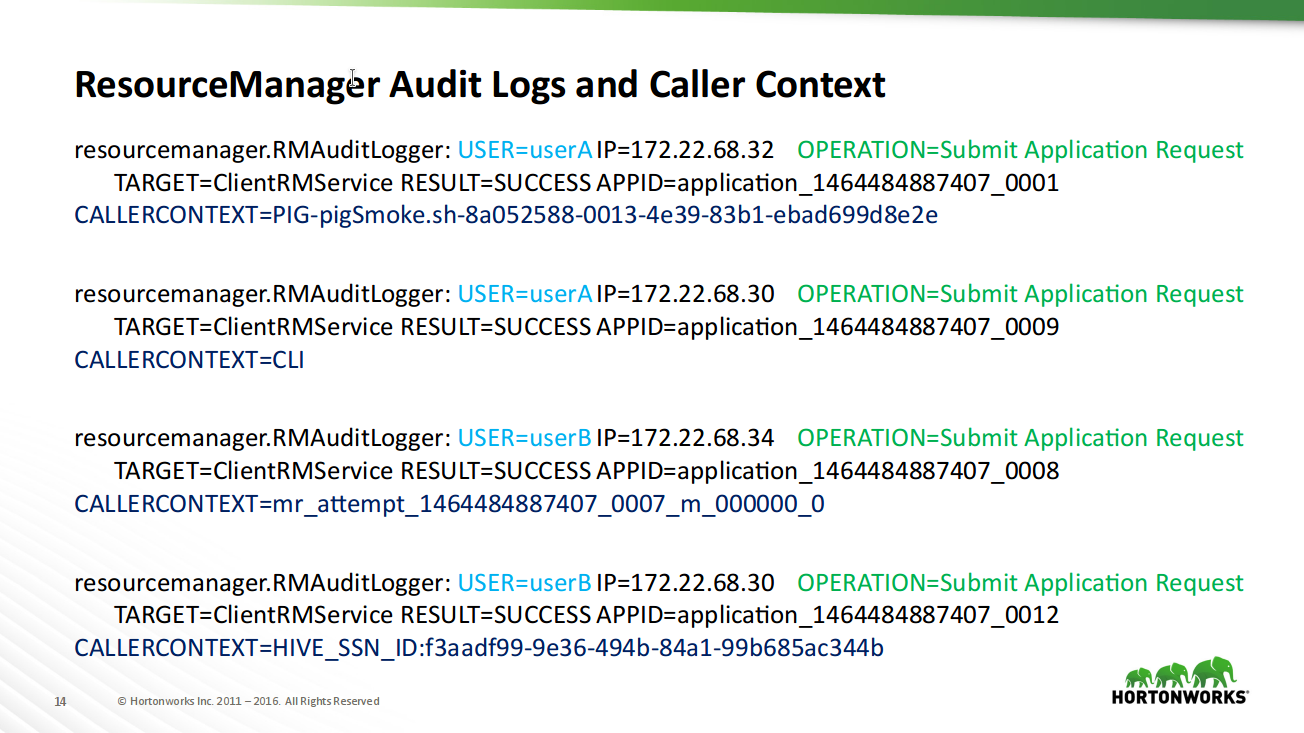
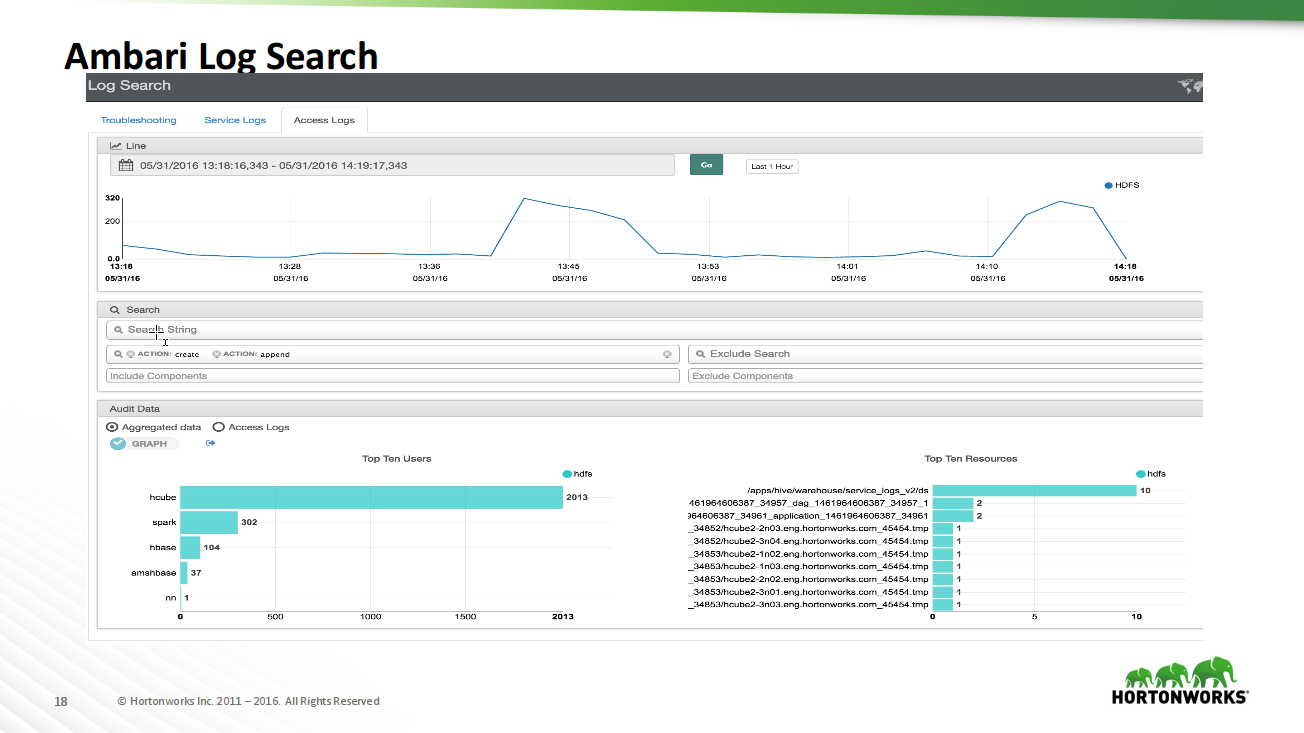
Useful tool! It allows you to understand in more detail why a cluster behaves one way or another, whether there are enough resources for tasks, and how and what is being done.
I tried to figure out how to use such a thing for us, but so far I stumbled on the fact that according to official documentation the cluster should be deployed through Ambari, and we already have a cluster. Do not kill him? So I will dig further.
Presentation slides (carefully link to the .pptx file)
Autograph session
The conference was organized by O'Reilly, and of course, it owned a large booth at the very entrance to the exhibition hall. Here you could buy their new books on Big Data at discounted prices, and then find authors and sign books at the conference.
Also on the stand was a schedule of autograph sessions, and in the long breaks between presentations, it was possible to receive signed early release future books as a gift from the hands of the authors.

However, like all free, these early release books turned out to be rather useless, and in some cases frankly promotional.
Spoon of tar and sponsors tricks
Like any conference, Strata was not spared by marketers, who don’t feed them with bread, but let them set their cunning traps throughout the territory.
Even before the beginning of the conference, smart experienced people warned against visiting the reports marked in the schedule with the words Sponsored by X, since all of them are purely advertising.
Also, unfortunately, there were reports, in the title and description of which the buzzwords needed by the listeners were used, but in practice the speakers promoted their product and could not speak at all about the technologies stated in the description.
Each participant at the conference had a badge with a personal plastic card and an installed rfid tag, and on each stand, tricky sponsors distributed stickers, soft toys and other souvenirs only after the person approached allowed them to scan their badge, i.e. shared all his credentials with this sponsor.
On some stands, they managed to scan the badge even before they answered the listener.
Because of these tricks, then I had to spend some time on unsubscribing from all sponsored mailings.
Instead of conclusion
The Strata + Hadoop conference takes place in different countries of the world 5 times a year. The next, for example, will be in early August in Beijing. If you have not yet decided whether you should attend conferences of this series, then it is rather difficult to recommend here.
On the one hand, if your interest is mainly focused on engineering reports and specific technologies, then you should rather visit some more specialized event. For example, Spark Summit . Judging by the description, there are a lot of engineers there, and many of them are eager to get feedback from the listeners and “featurekvests” for future development.
On the other hand, if you have a fairly large BI team, then thanks to a very wide range of reports, there will be a lot of interesting things for everyone and you will not waste your time. Also, you will definitely get a very professional event organization, a positive atmosphere and the opportunity to talk with the creators of all popular products in the field of data science, machine learning and business analytics.
Vadim Babayev, BI Software Engineer
Valery Starynin, BI Software Engineer
Source: https://habr.com/ru/post/306208/
All Articles