Balancing two providers based on BGP and EEM
This article discusses how to manage BPG announcements on Cisco routers, running IOS XE, using Cisco Embedded Event Manager (EEM) for balancing incoming traffic and reserving uplink from several upstream providers.
Introduction
Often, in a small provider’s network, one can encounter a situation where an uplink is a BGP connection to two or more operators. Moreover, the second provider is not used as a reserve, but together with the first one. In addition, the situation is complicated by the fact that these channels may not be symmetrical in speed. For example, with a total uplink requirement of 2 Gbps, two channels are purchased from two different providers: 1500 Mbps and 500 Mbps. BGP protocol, in this case, perfectly solves the problem of reservation. Of course, there is no full reserve. It is obvious that it is impossible to reserve two gigabits by five hundred megabits without degrading the service for subscribers, however, a complete failure of the service will not occur. And if the failure occurs not in the CNN (hours of maximum load), then the service may not suffer at all.
Significantly more problems in this situation arise not with redundancy, but with balancing. Especially because of the asymmetry of the channels in speed. Moreover, balancing outgoing traffic (which we can, more or less, control) is not so important. But controlling incoming traffic is much more difficult.
Consider, as an example, the following scheme:
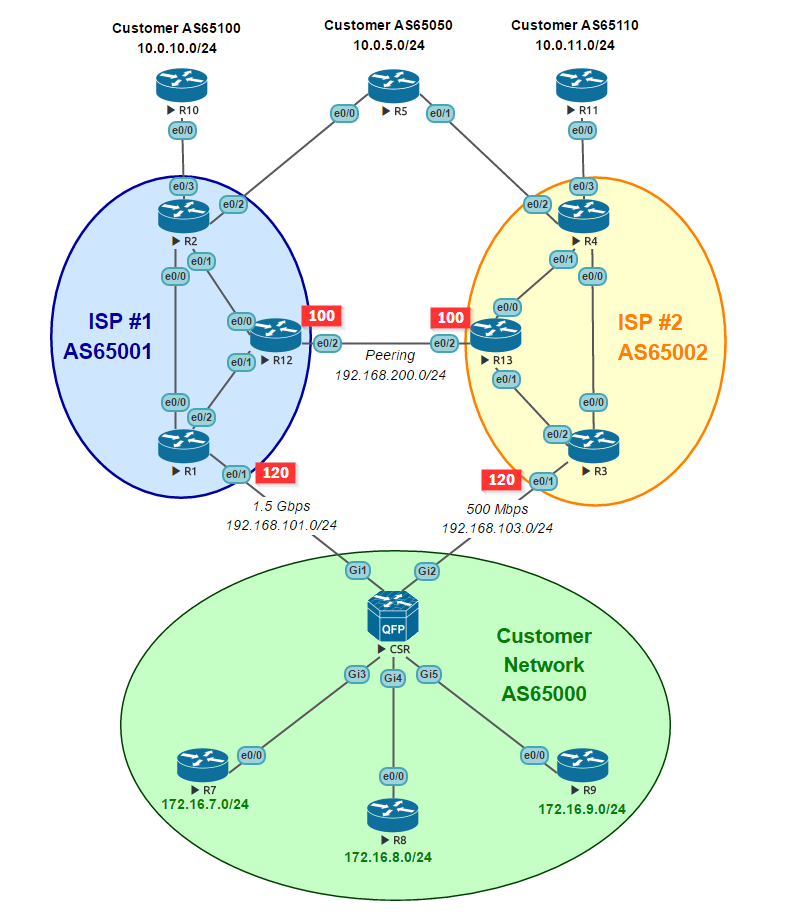
“Our” AS65000 is connected to two providers: ISP # 1 (AS65001) and ISP # 2 (AS65002) on channels 1.5 Gbps wide and 500 Mbps, respectively. Subscribers in our network are behind three local routers R7, R8 and R9 and use, respectively, three subnets:
- 172.16.7.0/24
- 172.16.8.0/24
- 172.16.9.0/24
The “resources of the global Internet” are three routers:
- R5 (AS65050, 10.0.5.0/24) - has accession to both providers;
- R10 (AS65100, 10.0.10.0/24) - attached only to ISP # 1;
- R11 (AS65110, 10.0.11.0/24) - attached only to ISP # 2.
Providers have between themselves a peering joint (between R12 and R13).
Unlike the client connection, the download of which is directly related to the revenue of the provider, the peer-to-peer junction may not bring the provider direct income, or even altogether, to be consumable. Therefore, it is normal practice to increase the BPG Local Preference for client attachments, and reduce it for peers. On our scheme, local preference values are indicated by red markers: at peering, both providers have a value of 100 (default), and connections with us, as a client, increased 120. This option allows the provider, when receiving the same BPG route from the client and other provider to explicitly give preference to client interconnection. At the same time, this is one of the reasons for the difficulties with balancing uplink with standard BGP tools.
Badassing
As I already wrote, balancing outgoing traffic, for most providers, is not so critical, so the topic of the article is the management of incoming traffic. We need to decompose our traffic in two non-symmetrical channels:
- 1500 Mbps via ISP # 1;
- 500 Mbps via ISP # 2.
Empirically, we establish two ranges of IP addresses that “consume” traffic in the proportion we need. For simplicity of a situation (the principle of the method does not change from this) let us assume that subscribers behind routers R7 and R8 consume approximately three quarters of the total incoming traffic, and the remaining quarter accounts for subscribers of router R9. In this case, using BGP announcements, we need to ensure that traffic for 172.16.7.0/24 and 172.16.8.0/24 networks goes through ISP # 1, and for 172.16.9.0/24 networks - through ISP # 2.
We form two prefix lists and consider the methods by which we can divide traffic for them by channels:
ip prefix-list isp-1-out seq 5 permit 172.16.7.0/24 ip prefix-list isp-1-out seq 10 permit 172.16.8.0/24 ip prefix-list isp-2-out seq 5 permit 172.16.9.0/24 AS-PATH Prepend
As a standard solution to this problem, BGP proposes the AS-PATH Prepend mechanism . Its essence is that when choosing the best route from several possible, BGP protocol uses the value of the AS-PATH attribute, which sequentially lists the numbers of all autonomous systems through which the BGP announcement passed. The route with the shortest AS-PATH is preferred. The AS-PATH prepend method artificially lengthens the attribute value for some routes.
Let's try to apply this method in our network. To do this, create two route-maps on the CSR and use them:
route-map isp-1-out permit 10 match ip address prefix-list isp-1-out route-map isp-1-out permit 20 match ip address prefix-list isp-2-out set as-path prepend 65000 65000 65000 route-map isp-2-out permit 10 match ip address prefix-list isp-1-out set as-path prepend 65000 65000 65000 route-map isp-2-out permit 20 match ip address prefix-list isp-2-out router bgp 65000 address-family ipv4 neighbor 192.168.101.1 route-map isp-1-out out neighbor 192.168.103.3 route-map isp-2-out out Now, in the direction of ISP # 1, the prefix 172.16.9.0/24 will be announced with AS-PATH extended to three AS65000 numbers, and in the direction of ISP # 2, the same will be done for the prefixes 172.16.7.0/24 and 172.16.8.0/24.
Now, ideally, traffic for each group of prefixes should come through its provider, and in the event of one of the uplink crashes, an announcement will start working with prepend. For example, if ISP # 2 is dropped, traffic for 172.16.9.0/24 will not be interrupted, since the whole world still “sees” this prefix through ISP # 1, even with an extended AS-PATH.
This method would work, but here various local preferences interfere with the game, which providers use for clients and peering. Since, while choosing a route, the LOCAL PREFERENCE attribute has a higher priority than AS-PATH, within each provider our prepend will not play a role and traffic will always be sent through the client channel. In our network, this method will work only for AS65050, as it is connected to both providers.
Let's look in more detail.
Indeed, on the R5 everything is fine:
R5#sh ip bgp ... * 172.16.7.0/24 192.168.45.4 0 65002 65000 65000 65000 65000 ? *> 192.168.25.2 0 65001 65000 ? * 172.16.8.0/24 192.168.45.4 0 65002 65000 65000 65000 65000 ? *> 192.168.25.2 0 65001 65000 ? *> 172.16.9.0/24 192.168.45.4 0 65002 65000 ? * 192.168.25.2 0 65001 65000 65000 65000 65000 ? R5#sh ip route ... 172.16.0.0/24 is subnetted, 3 subnets B 172.16.7.0 [20/0] via 192.168.25.2, 1d00h B 172.16.8.0 [20/0] via 192.168.25.2, 1d00h B 172.16.9.0 [20/0] via 192.168.45.4, 1d00h R5#traceroute 172.16.7.1 source 10.0.5.1 ... 1 192.168.25.2 0 msec 0 msec 1 msec 2 192.168.12.1 0 msec 1 msec 0 msec 3 192.168.101.100 3 msec 3 msec 3 msec 4 192.168.107.7 2 msec * 2 msec R5#traceroute 172.16.9.1 source 10.0.5.1 ... 1 192.168.45.4 1 msec 0 msec 1 msec 2 192.168.34.3 0 msec 1 msec 0 msec 3 192.168.103.100 3 msec 3 msec 3 msec 4 192.168.109.9 2 msec * 3 msec Based on the AS-PATH attribute for each group of prefixes, the optimal route through its provider is selected, which is confirmed by the trace.
But on R11 (AS65110) everything is not so rosy.
R11#traceroute 172.16.7.1 source 10.0.11.1 ... 1 192.168.114.4 0 msec 1 msec 4 msec 2 192.168.34.3 1 msec 0 msec 0 msec 3 192.168.103.100 3 msec 3 msec 3 msec 4 192.168.107.7 2 msec * 2 msec R11#traceroute 172.16.9.1 source 10.0.11.1 ... 1 192.168.114.4 0 msec 1 msec 0 msec 2 192.168.34.3 0 msec 0 msec 0 msec 3 192.168.103.100 3 msec 2 msec 3 msec 4 192.168.109.9 2 msec * 2 msec Traffic to both hosts goes to us through the same five hundred megabit interface.
The reason is just in local preference. We look at the ISP # 2 provider R13:
R13>sh ip bgp ... * 172.16.7.0/24 192.168.200.12 0 65001 65000 ? *>i 192.168.103.100 0 120 0 65000 65000 65000 65000 ? * 172.16.8.0/24 192.168.200.12 0 65001 65000 ? *>i 192.168.103.100 0 120 0 65000 65000 65000 65000 ? * 172.16.9.0/24 192.168.200.12 0 65001 65000 65000 65000 65000 ? *>i 192.168.103.100 0 120 0 65000 ? R13#sh ip route ... 172.16.0.0/24 is subnetted, 3 subnets B 172.16.7.0 [200/0] via 192.168.103.100, 1d00h B 172.16.8.0 [200/0] via 192.168.103.100, 1d00h B 172.16.9.0 [200/0] via 192.168.103.100, 1d00h On the router all the BGP announcements of our networks in two copies:
- received through client connection (next-hop 192.168.103.100);
- received through peering (next-hop 192.168.200.12).
But, despite the long AS-PATH, for prefixes 172.16.7.0/24 and 172.16.8.0/24, the best route is the route with local preference 120 through the client, i.e. through us, not through peering. It turns out that ISP # 2 will send all traffic of our subscribers through the channel 500Mbps. And, if the data center of some large content provider (for example VK.com) turns out to be behind this provider, it will lead to overload on the channel and problems with the service.
It turns out that the standard AS-PATH prepend does not help us.
Exclude Announcements
Another way to split traffic is simply to exclude from the BGP announcements in the direction of the operator those prefixes for which we do not want to receive traffic through this provider.
Let's try.
Instead of a route-map, we configure a filtering prefix-list for each neighbor.
router bgp 65000 address-family ipv4 neighbor 192.168.101.1 prefix-list isp-1-out out neighbor 192.168.103.3 prefix-list isp-2-out out Now, in the direction of each provider, only those routes that should receive traffic through this junction are announced:
CSR#sh ip bgp neighbors 192.168.101.1 advertised-routes ... Network Next Hop Metric LocPrf Weight Path *> 172.16.7.0/24 192.168.107.7 0 32768 ? *> 172.16.8.0/24 192.168.108.8 0 32768 ? Total number of prefixes 2 CSR#sh ip bgp neighbors 192.168.103.3 advertised-routes ... Network Next Hop Metric LocPrf Weight Path *> 172.16.9.0/24 192.168.109.9 0 32768 ? Total number of prefixes 1 With this approach, the operator builds its routing table exactly as we need:
R13>sh ip route ... 172.16.0.0/24 is subnetted, 3 subnets B 172.16.7.0 [20/0] via 192.168.200.12, 00:04:53 B 172.16.8.0 [20/0] via 192.168.200.12, 00:04:53 B 172.16.9.0 [200/0] via 192.168.103.100, 00:05:13 Now traces from R11 go through different providers:
R11#traceroute 172.16.7.1 source 10.0.11.1 ... 1 192.168.114.4 4 msec 4 msec 4 msec 2 192.168.134.13 1 msec 0 msec 1 msec 3 192.168.200.12 0 msec 1 msec 0 msec 4 192.168.121.1 0 msec 1 msec 1 msec 5 192.168.101.100 2 msec 4 msec 3 msec 6 192.168.107.7 2 msec * 2 msec R11#traceroute 172.16.9.1 source 10.0.11.1 ... 1 192.168.114.4 0 msec 4 msec 0 msec 2 192.168.34.3 0 msec 1 msec 0 msec 3 192.168.103.100 3 msec 3 msec 3 msec 4 192.168.109.9 2 msec * 2 msec However, there is a problem with the reservation. Indeed, when ISP # 2 drops, subscribers from the 172.16.9.0/24 network lose service, as the whole world no longer “sees” the route to them. Usually, this can be solved by announcing an aggregation of the prefix for the reserve. For example, if we had an address range from 172.16.6.0 to 172.16.9.255, then we could additionally announce to both providers the enlarged subnets 172.16.6.0/23 and 172.16.8.0/23, which include our prefixes. Then, if one of the providers fell and the “specificity” of the / 24 routes disappeared on the Internet, it would still remain / 23, and the service would work for all subscribers even on one uplink. But in our example this is impossible. Our client networks cannot be aggregated into one or two prefixes. Of course, the networks in the example were chosen specially, but, precisely, the collision with such a situation in practice prompted me to write a note.
Reservation
We solved the problem of balancing incoming traffic. It remains to achieve redundancy. The general solution is clear: if one of the peers falls, change the outgoing announcements filter on the peer that is still “alive”. This could be implemented “outside”, changing the settings of our border router with a script via SSH or SNMP. However, the purpose of the note is to make everything integrated with Cisco.
BGP Conditional Advertisement
One of the options for managing BGP announcements depending on the state of the BGP neighborhood is the Conditional Advertisement , which allows you to announce certain prefixes towards the neighbor, depending on the presence or absence of "control" prefixes in the BGP table.
Prefixes that need to be announced or, conversely, removed from the announcement are determined by a special route-map: advertise-map , which can be in withdraw mode (prefixes corresponding to the route-map are excluded from the announcement) or advertise (prefixes participate in the announcement). “Control” prefixes are defined by a separate condition-map , which can be declared as exist-map or non-exist-map . In the first case, prefixes from the advertise-map are announced only if there are prefixes in the BGP table that correspond to exist-map. In the case of a non-exist-map, vice versa: if a non-exist-map returns an empty list of prefixes, then the adfix-map prefixes are announced, and if not, they are excluded from the announcement.
In our case, the option with non-exist-map. The route-map configuration here has several features:
- the route-map should contain only the permit sections;
- in each section, the match must contain a prefix-list (can not be filtered only by as-path or community);
- The prefix-list should be "exact match", i.e. no parameters le or ge ;
- next-hop or interface filtering is not supported.
So we need a control prefix. You can choose something from what providers announce to us (or even tell them that you are using conditional advertisement and ask them to add a prefix to which you can orient yourself). But in most cases (if there are no other providers among your clients), instead of full-view, you will receive a default prefix of 0.0.0.0/0 from your upstream provider. We will use it as a control. And to distinguish the default of one provider from another, add to non-exist-map a filter by AS-PATH.
Create a prefix-list and two as-path ACLs:
ip prefix-list default seq 5 permit 0.0.0.0/0 ip as-path access-list 1 permit ^65001.* ip as-path access-list 2 permit ^65002.* Add two condition-maps, each of which will return a non-empty list only if the connection with the corresponding ISP is established:
route-map isp-1-is-alive permit 10 match ip address prefix-list default match as-path 1 route-map isp-2-is-alive permit 10 match ip address prefix-list default match as-path 2 Create two route-maps, which will be advertise-map for the corresponding destinations:
route-map isp-1-adv permit 10 match ip address prefix-list isp-2-out route-map isp-2-adv permit 10 match ip address prefix-list isp-1-out We will use another route-map to filter all outgoing announcements:
route-map full-out permit 10 match ip address prefix-list isp-1-out isp-2-out Now apply them in the configuration of the BGP neighbors:
router bgp 65000 address-family ipv4 neighbor 192.168.101.1 advertise-map isp-1-adv non-exist-map isp-2-is-alive neighbor 192.168.101.1 route-map full-out out neighbor 192.168.103.3 advertise-map isp-2-adv non-exist-map isp-1-is-alive neighbor 192.168.103.3 route-map full-out out Let's take a closer look at the neighbor 192.168.103.3 configuration:
- prefixes for the announcement are selected by the route-map full-out ;
- additionally checked non-exist-map isp-1-is-alive :
- if isp-1-is-alive returns a non-empty list, prior to advertise-map isp-1-adv is assigned a status of withdraw and its prefixes are excluded from the announcement;
- if isp-1-is-alive returns an empty list, before the advertise-map isp-1-adv is given the status advertise and its prefixes are announced.
Let's see what happened. Initially, “control” prefixes for both non-exist-maps are in the BGP table and the corresponding advertise-map are in withdraw status:
CSR#sh ip bgp neighbors 192.168.101.1 | i Condition Condition-map isp-2-is-alive, Advertise-map isp-1-adv, status: Withdraw CSR#sh ip bgp neighbors 192.168.103.3 | i Condition Condition-map isp-1-is-alive, Advertise-map isp-2-adv, status: Withdraw Since both providers are "alive", only part of the prefixes are announced in the direction of each of them:
CSR#sh ip bgp neighbors 192.168.101.1 advertised-routes ... Network Next Hop Metric LocPrf Weight Path *> 172.16.7.0/24 192.168.107.7 0 32768 i *> 172.16.8.0/24 192.168.108.8 0 32768 i Total number of prefixes 2 CSR#sh ip bgp neighbors 192.168.103.3 advertised-routes ... Network Next Hop Metric LocPrf Weight Path *> 172.16.9.0/24 192.168.109.9 0 32768 i Total number of prefixes 1 In case of disconnecting the BGP neighborhood with ISP # 1, the prefixes for the route-map isp-1-is-alive and advertise-map isp-2-adv for ISP # 2 go to advertise status disappear from the BGP table:
CSR#sh ip bgp neighbors 192.168.103.3 | i Condition Condition-map isp-1-is-alive, Advertise-map isp-2-adv, status: Advertise Now route-map prefixes isp-2-adv are not excluded from the announcement and the full set of prefixes are announced in the direction of ISP # 2:
CSR#sh ip bgp neighbors 192.168.103.3 advertised-routes ... Network Next Hop Metric LocPrf Weight Path *> 172.16.7.0/24 192.168.107.7 0 32768 i *> 172.16.8.0/24 192.168.108.8 0 32768 i *> 172.16.9.0/24 192.168.109.9 0 32768 i Total number of prefixes 3 When the BGP neighborhood is restored, the status changes to advertise-map back to withdraw , and the prefixes are again distributed to the providers for balancing.
Another option for using Conditional Advertismement is to localize the problem on the provider’s side or even above its area of responsibility. In the case of our test scheme, it can be imagined that the AS65110 has a datacenter for a large content provider, access to which is critical for our subscribers. In the case of a peer-to-peer connection between two providers, some subscribers whose prefixes are advertised only in the direction of ISP # 1 will lose access to AS65110. At the same time, there is a connection with the provider, there are prefixes and default from it, but the subscriber service suffers. In this case, we can use a configuration similar to that described above, only as an "control" prefix to use the addresses of our critical resources in AS65110.
Cisco Embedded Event Manager
The method described further, considering the possibilities of BGP Conditional Advertismement, looks a bit artificial for solving such a simple task. The reason for this is that in the original version of the article he was the only one, since the story about the Cisco EEM was the purpose of writing the note. In this case, the problem of balancing was chosen as the simplest and most understandable version of the illustration. However, later in the comments, it was rightly pointed out to me that describing the problem of managing BGP announcements without mentioning a tool that is not exactly intended for this purpose. So the article appeared a paragraph about BGP Conditional Advertisment, against which the use of Cisco EEM seems cumbersome and redundant. However, this is a very powerful tool that has a huge field of application, so it’s still worth getting to know it.
We solved the problem of balancing incoming traffic. It remains to achieve redundancy. The general solution is clear: if one of the peers falls, change the outgoing announcements filter on the peer that is still “alive”. This could be implemented “outside”, changing the settings of our border router with a script via SSH or SNMP. However, the purpose of the note is to make everything integrated with Cisco.
This is where the Cisco Embedded Event Manager (EEM) mechanism comes in handy. This is a very flexible mechanism for managing the router and troubleshooting problems on the network, the possibilities of which go far beyond the limits of the described task. We need from him his ability to catch the occurrence of a certain event (the fall or the restoration of the BGP-neighborhood) and execute a given set of commands.
First, create a prefix list that includes all of our prefixes.
ip prefix-list full-out seq 5 permit 172.16.7.0/24 ip prefix-list full-out seq 10 permit 172.16.8.0/24 ip prefix-list full-out seq 15 permit 172.16.9.0/24 Now we will configure the EEM applet that will be launched when a change in the status of the BGP-neighborhood appears in the log (defined by a regular expression). Applet:
- Parses the message in the log and determines:
- The router-id of the BGP neighbor that provoked the message
- his status;
- depending on the IP address and status, applies one or another prefix list for another BGP neighbor;
- “Softly” dumps the announcements in the direction of the second neighbor, which would speed up the distribution of route information and the application of the changes made.
Applet Configuration:
event manager applet isp event syslog pattern "neighbor 192.168.10[13].[13] (Up|Down|reset)" action 01.0 regexp "(192.168.10[13].[13])" "$_syslog_msg" _match _ip action 02.0 if $_ip eq "192.168.101.1" action 03.0 set _name "ISP #1" action 04.0 set _target_ip "192.168.103.3" action 05.0 set _list "isp-2-out" action 06.0 elseif $_ip eq "192.168.103.3" action 07.0 set _name "ISP #2" action 08.0 set _target_ip "192.168.101.1" action 09.0 set _list "isp-1-out" action 10.0 else action 11.0 exit action 12.0 end action 13.0 regexp "(Up|Down|reset)" "$_syslog_msg" _match _state action 14.0 if $_state eq "Up" action 15.0 set _status "UP" action 16.0 else action 17.0 set _status "DOWN" action 18.0 set _list "full-list" action 19.0 end action 20.0 syslog priority warnings msg "$_name now is $_status !" action 21.0 syslog priority warnings msg "Applying prefix list '$_list' to the neighbor $_target_ip" action 22.0 cli command "enable" action 23.0 cli command "configure terminal" action 24.0 cli command "router bgp 65000" action 25.0 cli command "address-family ipv4" action 26.0 cli command "neighbor $_target_ip prefix-list $_list out" action 27.0 cli command "end" action 28.0 syslog priority warnings msg "Soft clear BGP session $_target_ip" action 29.0 cli command "clear ip bgp $_target_ip soft out" Initially, both BGP sessions are active and the announcements are as follows:
CSR#show ip bgp summary ... Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd 192.168.101.1 4 65001 8 5 7 0 0 00:00:19 3 192.168.103.3 4 65002 8 5 7 0 0 00:00:24 3 CSR#show ip bgp neighbors 192.168.101.1 advertised-routes ... Network Next Hop Metric LocPrf Weight Path *> 172.16.7.0/24 192.168.107.7 0 32768 ? *> 172.16.8.0/24 192.168.108.8 0 32768 ? Total number of prefixes 2 CSR#show ip bgp neighbors 192.168.103.3 advertised-routes ... Network Next Hop Metric LocPrf Weight Path *> 172.16.9.0/24 192.168.109.9 0 32768 ? Total number of prefixes 1 On the ISP # 2 network, our announcements are as follows:
R13>show ip bgp ... Network Next Hop Metric LocPrf Weight Path *> 172.16.7.0/24 192.168.200.12 0 65001 65000 ? *> 172.16.8.0/24 192.168.200.12 0 65001 65000 ? *>i 172.16.9.0/24 192.168.103.100 0 120 0 65000 ? Traces from R11 go to our network as we need:
R11#traceroute 172.16.7.1 source 10.0.11.1 Type escape sequence to abort. Tracing the route to 172.16.7.1 VRF info: (vrf in name/id, vrf out name/id) 1 192.168.114.4 0 msec 1 msec 0 msec 2 192.168.134.13 0 msec 0 msec 1 msec 3 192.168.200.12 0 msec 0 msec 1 msec 4 192.168.121.1 1 msec 1 msec 1 msec 5 192.168.101.100 3 msec 3 msec 3 msec 6 192.168.107.7 2 msec * 3 msec R11#traceroute 172.16.9.1 source 10.0.11.1 Type escape sequence to abort. Tracing the route to 172.16.9.1 VRF info: (vrf in name/id, vrf out name/id) 1 192.168.114.4 1 msec 0 msec 1 msec 2 192.168.34.3 0 msec 1 msec 0 msec 3 192.168.103.100 3 msec 3 msec 3 msec 4 192.168.109.9 2 msec * 2 msec Now let's try to disable the peer with ISP # 1 from the provider. As a result, one of the BGP sessions on our border goes to IDLE:
CSR#show ip bgp summary ... Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd 192.168.101.1 4 65001 0 0 1 0 0 00:00:10 Idle 192.168.103.3 4 65002 26 26 9 0 0 00:16:31 3 At the same time, in the log we see that as soon as the event % BGP-5-NBR_RESET arose: Neighbor 192.168.101.1 reset (Peer closed the session) , our applet worked and changed the prefix list:
*Jul 20 09:00:58.208: %BGP-5-NBR_RESET: Neighbor 192.168.101.1 reset (Peer closed the session) *Jul 20 09:00:58.208: %BGP-5-ADJCHANGE: neighbor 192.168.101.1 Down Peer closed the session *Jul 20 09:00:58.214: %HA_EM-4-LOG: isp: ISP #1 now is DOWN ! *Jul 20 09:00:58.214: %HA_EM-4-LOG: isp: Applying prefix list 'full-list' to the neighbor 192.168.103.3 *Jul 20 09:00:58.778: %SYS-5-CONFIG_I: Configured from console by on vty0 (EEM:isp) *Jul 20 09:00:58.879: %HA_EM-4-LOG: isp: Soft clear BGP session 192.168.103.3 Let's see what we are now announcing in the direction of ISP # 2:
CSR#show ip bgp neighbors 192.168.103.3 advertised-routes ... Network Next Hop Metric LocPrf Weight Path *> 172.16.7.0/24 192.168.107.7 0 32768 ? *> 172.16.8.0/24 192.168.108.8 0 32768 ? *> 172.16.9.0/24 192.168.109.9 0 32768 ? Total number of prefixes 3 Those. now we announce through ISP # 2 all our prefixes. Here is what it looks like now on R13:
R13>show ip bgp ... Network Next Hop Metric LocPrf Weight Path *>i 172.16.7.0/24 192.168.103.100 0 120 0 65000 ? *>i 172.16.8.0/24 192.168.103.100 0 120 0 65000 ? *>i 172.16.9.0/24 192.168.103.100 0 120 0 65000 ? And all traces to our network go through one provider.
When restoring a BGP session with IPS # 1, the applet will again return the prefix list for ISP # 2 to its original position.
Conclusion
The purpose of this article was to briefly review the use of Cisco EEM to manage incoming traffic while balancing several uplinks, and hopefully it did. Of course, this method can hardly be called optimal. Rather, this decision is "in the forehead." However, it works and provides a certain degree of fault tolerance. For writing a note, the entire scheme was collected in UNELAB on Cisco IOL and Cisco CSRv1000 images. Configurations of all devices from the considered example can be downloaded here .
')
Source: https://habr.com/ru/post/306178/
All Articles