Fear and hate and pagination
What's the problem?

As much as we would not want to deny this, practice shows that the typical iOS developer spends the vast majority of his time at work with tablets. Designing the service layer is intriguing, the development of universal routing in the application is exciting, and the configuration of flexible caching policies generally blows away the roof, but working with tabular interfaces is our everyday life. Sometimes a ray of light still falls into this area, and instead of another fuss with constraints, we may face the task of implementing paginated loading — or, as it is fashionable to call it in mobile applications, the infinite scroll.
Downloading at once all news, announcements, movie lists from a remote resource is at least not efficient, so in most cases the server provides clients with various mechanisms for breaking the entire data volume into pieces of limited size.
As they say, so far so good. We load the first batch of data, display them in the table, scroll to the end, load the next batch - and so on to infinity. Unfortunately - well or fortunately, we love the challenge - this is just the beginning.
Depending on the complexity of the project and the degree of API's chilliness, a fairly simple task runs the risk of being reborn into Something. Something with a capital letter, because this creation eventually finds its own life and starts destroying the fate of all who touch it. Closer to the point - I will give an example from real life, which happened, nevertheless, in a completely abstract project.
Conditions with which it was necessary to work:
- any of the loaded items may change over time;
- on the client side, you need to be able to hide the posts of authors from the blacklist - given that the server continues to return them;
- despite local filtering, when requesting the next page, the user must receive at least 20 new elements;
- the issue is completely rebuilt once an hour - some posts are added, some disappear, and all positions in the list change;
- access to the server is not directly, but through the CDN, which entails interesting artifacts;
- the only paging mechanism the server can offer is limit / offset.
The bad news is to make things right in such cases is difficult. The good news is that I have a whole structured set of crutches in my inventory that helps to cope with most of the issues and problems that arise.
Decomposition
An arbitrarily complex problem or problem becomes solvable if you break it into a limited number of steps. Our case is no exception. To understand how the entire pagination system works in your application, simply decompose it into several sections:
- Rules for changing the number of items in the issue:
- The tape is static. Example: List of institutions in the editorial compilation. Once compiled, it does not change.
- New items are added strictly on top. Example: Application browsing history. In its simplest form, its only change is the addition of new page views to the top of the list.
- Any part of the issue can be changed. Example: List of letters in the mail client. The user can delete, move and receive new letters, so the list can be changed at any position.
- Rules for changing the relevance of issuance:
- Extradition always remains relevant. Example: All the same email application. Its elements can change gradually, there is no strictly deterministic transition point from one state to another.
- Extraction can be re-formed at an indefinite point in time. Example: News app with intelligent ranking. Once an hour, the news is reassembled and the most relevant materials are moved to the top of the list.
- Content update rules:
- Displayed data is not updated. Example: Cells with restaurant names. The change of names is so rare that this probability can be safely neglected.
- Displayed data is subject to change. Example: Cell with likes counter. Over time, this counter changes - and you need to be able to update this data for already cached items.
The task of implementing pagination is often divided into two major parts: loading data down and updating the tape, usually done during a pull-to-refresh. Each of these tasks requires its own approach, entirely dependent on the above scheme.
Crutches
This section is a key part of the entire material. I collected all the crutches that I had to use when implementing the complex limit / offset pagination mechanism.
A small educational program. Limit / offset is the most common approach to implementing paginated data loading. Offset is a shift relative to the first element. Limit - the amount of data loaded.
Example: a user wants to download 10 news items starting from the twentieth. offset: 20, limit: 10 .
Load down / Tape changes
If the tape can be changed, no matter how, then when we try to request the next page, we may encounter elements moving up or down. Solving the problem consists of two steps. The first relates to downward shifts. Imagine a situation in which we have already loaded the first page of five elements. Until the next request, the data structure on the server changed and two new elements were added on top of the output. Now when loading the next page we get two items that we already have in the cache.
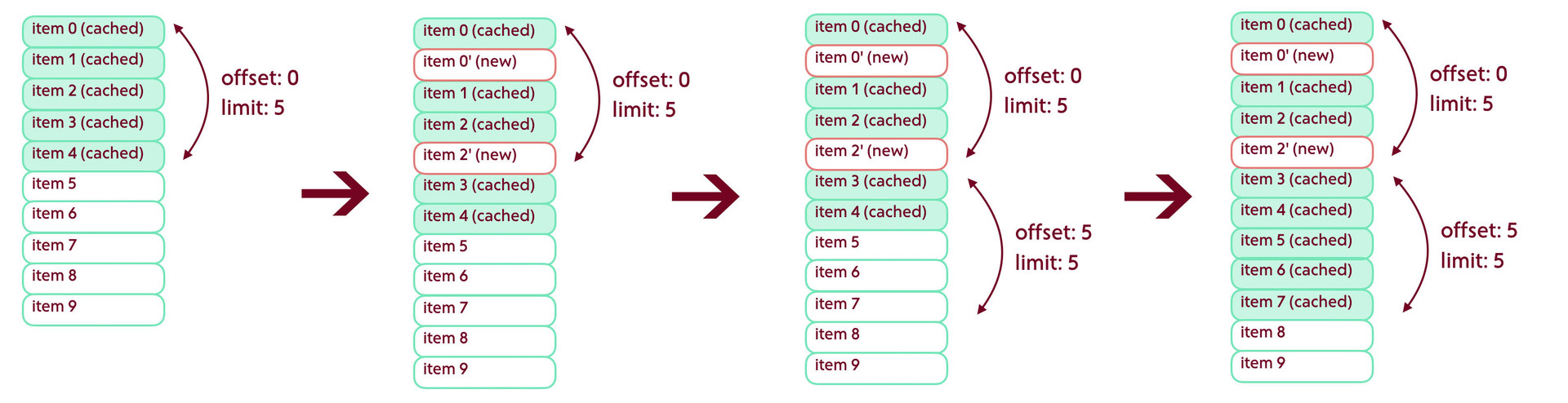
The situation may be worse if, during the absence of synchronization, more elements were added to the server than set in the limit property - then we will not receive any new elements. If, as an offset, we will use the total number of items in the cache, we will be stuck at this point forever, as we continue to query those items that have already been loaded.
The problem is solved quite simply. When receiving the next portion of data, we calculate the number of intersections with cached content - and then use the resulting value as an offset offset. In the example above, this shift will be 2.
paging.startIndex = cachedPosts.count + intersections; paging.count = 5; Down load / Any part of the issue can be changed
Consider the following situation: we loaded the page, but then the first two elements were deleted. Having requested the next portion of data, we get a hole in two elements. If you do nothing, the application will not know anything about it - and the data will never load.
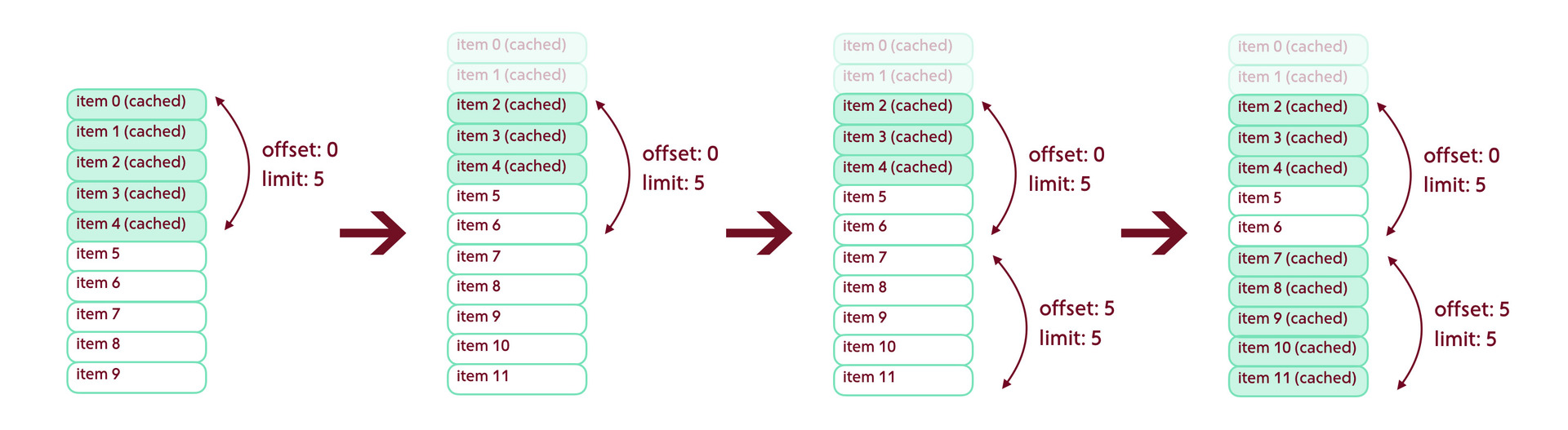
The way out of this situation is to always request data with a single element overlay. If we do not find any intersections when receiving data, we can either cancel the result of the query or repeat it with other parameters.
paging.startIndex = startIndex - 1; paging.count = 5; A small life hacking in the piggy bank - if any elements in the tape are lost, you can always make a serious face and give a lecture on intelligent data ranking performed on the client. Do not believe - show Facebook, in which the same issue on each device always looks completely different.
Down load / Delivery can be restructured at a random point in time.
In this case, the simplest implementation option would be to work with a so-called ribbon cast. This term is usually understood as a list of identifiers of all issuance records. When you first open, we request such an impression and store it in the database, or simply keep it in memory. Now, to get the next page, we will not use the standard limit / offset, but a more complex request - ask the server to give posts on specific 20 identifiers.
NSRange pageRange = NSMakeRange = (startIndex, 20); NSArray *postIds = [snapshot subarrayWithRange:pageRange]; [self makeRequestWithIds:postIds]; Even if the issue is unexpectedly restructured, it does not hurt us - we work with the impression that was relevant at the time of the first request - and the tape will be sorted for the client in the same way as at the time of the first opening.
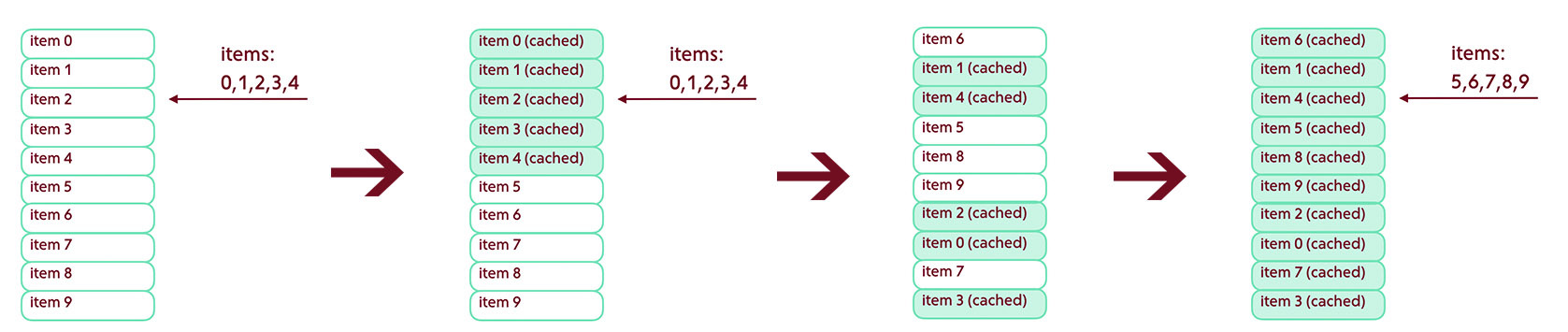
Ribbon Update / Items added on top
In this case, we first need to be able to determine the presence of holes formed if a large number of new elements have been added since the last synchronization.
We request a constant amount of data and check for intersections with data from the cache. If there is an intersection, everything is fine, you can continue to work as usual. If there are no intersections, this means that we have missed several posts.

What to do in this case - you need to decide for each specific application. You can reset all data, except for the requested five elements. You can continue to load elements from the top page by page until the intersection is detected.
if (intersections == 0) { [self dropCache]; } Tape update / Any part of the issue can be changed
There are two ways to solve a problem:
The server sends diffs of changes to the tape, for example, based on the last-synchronized last state of the issue that was saved Last-Modified. We get the Last-Modified parameter from the server response headers. The client in this case will just apply these changes to the state of the database.
for (ShortPost *post in diff) { [self updateCacheWith:post]; }If the server does not know how, then you have to write an additional hundred lines on the client again. We need to get a cast of posts (just like in one of the previous paragraphs) and compare it with the current state of the data stored in the cache.
for (ShortPost *post in snapshot) { if (![cachedPosts containsObject:post]) { [self downloadPost:post]; } } for (Post *post in cachedPosts) { if (![snapshot containsObject:post]) { [self deletePost:post]; } }
All missing elements in the cast are deleted, all missing elements are loaded.
Ribbon Update / Sort Changing
If the issue has been restructured, we need to know about it. The easiest way to do this is by sending a head request to the server and comparing the etag or Last-Modified parameters with the saved values.
NSString *lastModified = [self makeFeedHeadRequest]; if (![lastModified isEqual:cachedLastModified]) { [self dropCache]; [self obtainPostSnapshot]; [self obtainFirstPage]; } If the comparison result is negative, the cache state is reset, the id id is updated.
Ribbon update / Issuing elements may vary
If the list items contain data that changes over time, such as a rating or a number of likes, they need to be updated. The solution of the problem, in principle, correlates with one of the preceding paragraphs — we work either with the diff returned by the server, or we request short data structures containing only significant fields. After that, manually update the state of the elements.
for (NSUInteger i = 0; i < cachedPosts.count; i++) { Post *cachedPost = cachedPosts[i]; ShortPost *post = snapshot[i]; if (![cachedPost isEqual:post]) { [cachedPost updatePostWithShortPost:post]; } } The main thing is to minimize the amount of transmitted data.
Tips for the future
In conclusion, I want to give some tips of different degrees of utility.
Tip 1, obvious
It is very convenient to have a special object that describes the current issue. Call it a list, category, feed - it does not matter.
@interface Feed: NSObject @property (nonatomic, copy) NSArray <Post *> *posts; @property (nonatomic, copy) NSArray <NSString *> *snapshot; @property (nonatomic, assign) NSUInteger offset; @property (nonatomic, assign) NSUInteger maxCount; @property (nonatomic, strong) NSDate *lastModified; @end It can contain the current offset, the maximum number of tape items, the Last-Modified date, the id cast — everything you need to describe the list of items.
Tip 2, architectural
You should not mix in one place requests for data and processing of results. If you try to immediately display the data received from the server, you will surely encounter a number of problems and limitations.
Separate the logic of data request from the logic of their receipt, processing and display.
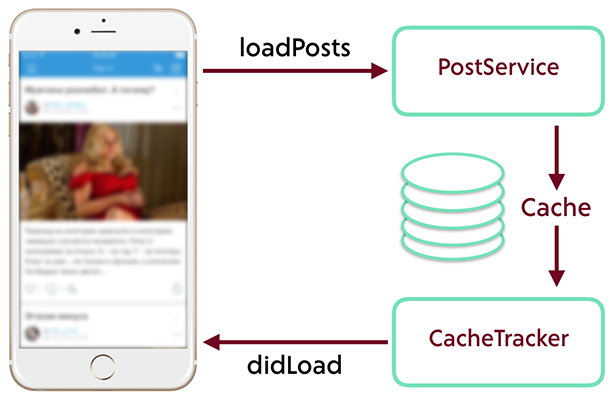
Abstract from the complexities and crutches that we discussed in this article. Our main goal is to ensure constant synchronization of the state of the cache and the display. If the screen displays the same thing that is in the database - life becomes much easier.
In this, for example, NSFetchedResultsController , CoreData notifications or similar mechanisms of other ORMs can help.
Tip 3, camouflage
Encapsulate all of the ribbon update and pagination logic in a separate object — the front over the direct loading services.
It is in this object are the most terrible things - nested blocks, verification of indices and intersections, logical branches. For consumers, the interface of the facade looks extremely simple and provides basic methods for working with page data - loading the next page, updating the list and reloading it completely. Pay special attention to the fact that this object should be as well tested as possible.
Tip 4, the most important
Until recently, try to insist on the normal implementation of pagination on the server. Limit / offset is, of course, a fairly flexible solution, but the client should be simple. No, really, as simple as possible!
useful links
')
Source: https://habr.com/ru/post/306158/
All Articles