Agile API - is it possible?
 Many articles and books are devoted to how to design an API correctly, but hardly anyone touched upon the topic of the ever-changing (flexible) API. A dynamic company often releases several releases a week, and sometimes a day. At the same time to add new features, you must constantly make changes to the existing API. In this article we will talk about how we in Badoo solve this problem, what approaches and ideas we use in our work.
Many articles and books are devoted to how to design an API correctly, but hardly anyone touched upon the topic of the ever-changing (flexible) API. A dynamic company often releases several releases a week, and sometimes a day. At the same time to add new features, you must constantly make changes to the existing API. In this article we will talk about how we in Badoo solve this problem, what approaches and ideas we use in our work.First of all, I have to tell a little more about Badoo so that you understand who works with our API and why it changes so often.
Our internal API and its use
Our Badoo API (messaging protocol) is a set of data structures (messages) and values (enums) that clients and server exchange. The structure of the protocol is set on the basis of the Google protobuf definitions and is stored in a separate git repository. Based on these definitions, model classes are generated for different platforms.
')
It is used for six server platforms and five clients: Android, iOS, Windows Phone, Mobile Web, and Desktop Web. In addition, the same API is used in several stand-alone applications on each platform. In order for all these applications and the server to share the required information, our API “grew” large enough. Some numbers:
- 450 messages, 2665 fields.
- 135 enum, 2096 values.
- 125 feature flags that can be managed on the server side.
- 165 flags of client behavior that tell the server how to behave the client and the protocol supported by the client.
When should it be done? Yesterday!
In Badoo, we try to implement new features as quickly as possible. The logic is simple: the sooner a version with new features appears, the faster users will be able to use them. In addition, we conduct parallel A / B testing, but in this article we will not dwell on it in detail.
The implementation time of the feature - from idea to release - is sometimes only a week, including writing requirements, changing the API and technical documentation, implementing and releasing a new version. On average, everything takes about a month. However, this does not mean that we add one feature to the application per month. We are working in parallel on many new features.
In order to be capable of such exploits, we had to develop a process that allows us to move at the right speed.
Which way to go?
For example, a product owner offers a new idea and asks API developers to extend the protocol in order to implement new features on the client side.
First of all, you need to understand that many people are working on the implementation of the new function:
- Product Owner;
- designers;
- server solutions developers;
- API developers
- client application developers for different platforms;
- QA;
- data analytics.
How can you ensure that they all understand each other and speak the same language? We need a document with a description of the requirements for functionality ( PRD ). Usually such a document is prepared by the Product Owner. He creates a wiki page with a list of requirements, use cases, flow description, design sketches, etc.
Based on PRD, we can begin planning and implementing the necessary changes to the API.
Here again, not so simple.
Protocol Design Approaches
There are many approaches to the “distribution of duties” between the server and the client. Approaches range from "all logic is implemented on the server" to "all logic is implemented in the client." Let's discuss the pros and cons of each approach:
Option 1. All logic is implemented on the server (the client works as a View from the MVC template).
Pros:
- New functionality for all platforms is enough to implement only once - on the server.
- You can update only server logic and tokens, there is no need to make changes to client applications and prepare a new release (a very big plus when it comes to native applications).
Minuses:
- A more complex protocol (often a feature requires several sequential actions that are easy to implement on the client, and adding these steps to the protocol makes everything very difficult).
- If something works differently on different client applications, it is necessary to have on the server a separate implementation of functionality for each client application and each supported version of the application.
- May adversely affect the usability of the application through a slow or unstable connection.
- If business logic is implemented on the server side, some functions will be very difficult or even impossible to implement without a connection to the server.
Option 2. All logic is implemented in the client - the client application contains all the logic and uses the server as a data source (typical of most public APIs).
Pros:
- The number of requests to the server is less, the user has to wait less for answers.
- It works better offline and through a slow or unstable network.
- Caching is greatly simplified.
- If necessary, it is much easier to implement different behaviors for different platforms and client versions.
- Easier interaction with the server - teams can work without looking at each other.
Minuses:
- Takes more time. All logic needs to be implemented on each of the clients, and not once on the server.
- To implement even the most minor changes, you must release each client application.
- The higher the probability of errors in the code, since each application has a separate implementation of logic.
On the one hand, the first approach allows you to implement business logic only once on the server, and then it will be used on all clients. On the other hand, different platforms have their own characteristics, their structure of lexemes, a different set of features, and the features themselves are often implemented at different times. In most cases, it is easier to make the protocol more data-oriented, so that client applications have some freedom and can work in their own way. But, as always, there is no one right decision, therefore we constantly balance between these two approaches.
Technical documentation
A few years ago, when our company was smaller, only two clients (Android and iOS) used the protocol. There were few developers, we discussed all the working points verbally, therefore the documentation on the protocol contained only a description of the general logic in the comments for the protobuf definitions. Usually it looked like this:
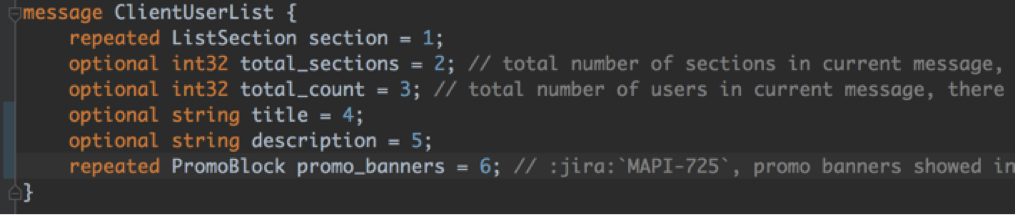
Then three more client platforms appeared: Windows Phone, Mobile Web and Desktop Web, and the number of developers in Android and iOS teams increased threefold. Oral discussion was becoming more and more expensive, and we decided that it was time to document everything carefully. Now this documentation includes much more than just comments about fields. For example, we add a brief description of features, sequence diagrams, screenshots and sample messages. In the simplest case, the documentation might look like this:
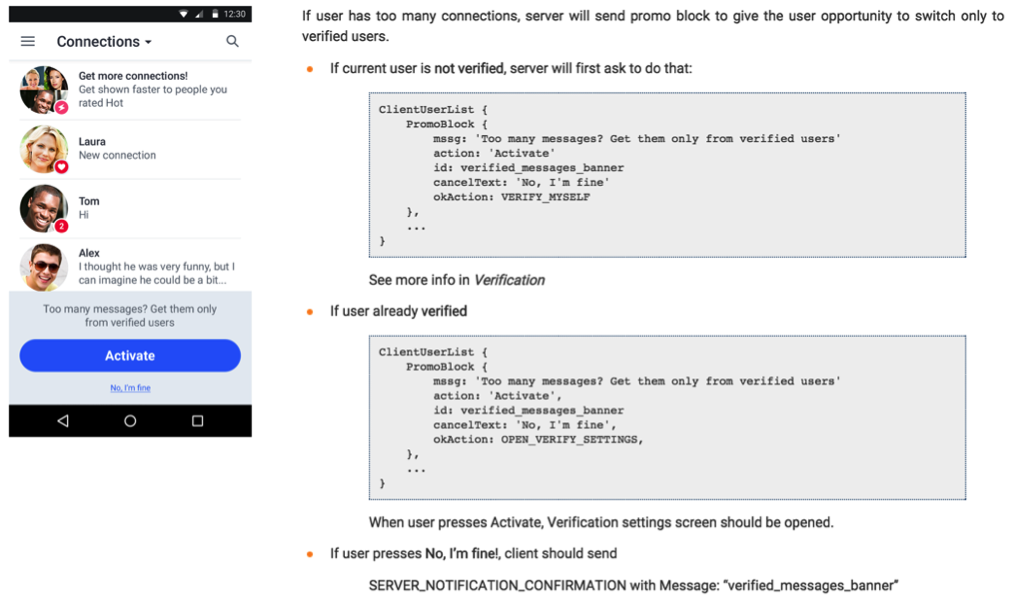
Application developers and QA for all six platforms use this documentation and PRD as their main sources of knowledge.
This documentation helps not only to implement new functions, but also with significant redesign and refactoring of applications, when you need to know how the already implemented functionality works.
Now we can easily tell the developers of "RTFM", which saves us a lot of time. In addition, this approach helps beginners to understand how everything works, and quickly get involved in the development process.
We serve the documentation
We prepare technical documentation in the reStructuredText format and store it in the git repository along with the protocol definitions, and with the help of Sphinx we generate the HTML version that is available on the company's internal network.
The documentation is divided into a number of main sections devoted to various aspects of protocol implementation and other issues:
- Protocol - documentation created based on comments for protobuf definitions. Product functions - technical documentation on the implementation of functions. (conveyor diagram, etc.).
- General - protocol and flow documents not related to specific product features.
- Application Features - since we have several different applications, this section describes the differences between them. As mentioned above, the protocol is shared.
- Statistics — A general description of the protocol and processes associated with collecting statistics and application performance information.
- Notifications - documentation of various types of notifications that can be sent to our users.
- Architecture and infrastructure - the structure of the lower level for the protocol, binary protocol formats, framework for A / B testing, etc.
So we made changes to the API. What's next?
After making changes to the protocol and documentation based on PRD, and PRD and API go through two stages of a review. First, within the team responsible for the protocol, then among the application developers of those platforms where this feature will be implemented.
At this stage, we get feedback on the following issues:
- Sufficiency - whether these API changes are enough to implement features on each platform.
- Compatibility — Whether changes are compatible with the application code on the platforms. Maybe you can tweak the protocol a bit and save one or two platforms a lot of time and resources?
- Comprehensibility
After discussing and approving all the changes, the server and client commands can proceed to the implementation of the feature.
To finish at this stage would be too good. Often, ProductOwner has further plans to improve this feature, but he still wants to release the application now in its current form. Or more interesting. Sometimes we are asked to make changes for one platform, and for the rest to leave everything as it is.
Feature as a child, it grows and develops
Features develop. We conduct A / B tests and (or) analyze feedback after the release of new features. Sometimes analysis shows that the feature needs to be improved. Then the product owners make changes to the PRD. And here comes the “problem”. Now PRD does not match the format of the protocol and documentation. Moreover, it may happen that for one platform the changes have already been made, and the other team is just starting to work. To prevent possible inconsistencies, we use versioning PRD. For example, for one platform, a feature can be implemented in accordance with version R3. After some time, the Product Owner decides to refine the new functionality and updates the PRD to version R5. And we need to update the protocol and technical documentation to reflect the new version of PRD.
To monitor PRD updates, we use the Confluence change history (wiki from Atlassian). In the technical documentation for the protocol, we add links to a specific version of the PRD, simply by specifying? PageVersion = 3 in the address of the wiki page, or take a link from the change history. Because of this, each developer always knows on the basis of which version or part of the PRD a particular function is implemented.
All changes in PRD are considered as new functionality. Product owners accumulate changes (R1, R2 ...) until they decide that it is time to send them to development. They prepare an assignment for API developers with a description of the required changes in the protocol, and then all development teams responsible for different platforms receive the same assignments. When the next set of changes is ready for the feature, another API ticket is created, then the changes are implemented for all platforms in the same way:
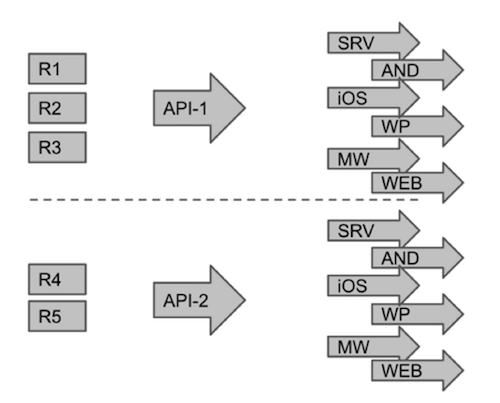
Having received the list of changes in the PRD, we return to the beginning of this process, that is, we make changes to the protocol and so on. Of course, this makes life difficult for us, since no one has canceled the need to support previously implemented functions and client applications that were based on version R3. To solve this problem, we use several protocol change management tools.
Protocol Change Management
In the previous section, we discussed PRD versioning. To implement these changes in the API, we must consider the protocol version control options. For simplicity, we can say that there are three options (levels) with their own advantages and disadvantages.
Protocol level
This approach is widely used for slowly changing public APIs. When a new version of the protocol comes out, all clients should start using it instead of the old one. We can not use this option, because we have a set of features and the time of their implementation are very different on different platforms. For example, we have several versions of the protocol:
- V1. Supports A, B, C functions.
- V2. It supports functions B ', C and D, where B' is the updated function B (requiring a different command sequence).
Therefore, if you need to implement feature D in the application, you will also need to update feature B to version B ', although perhaps this is not required now.
We at Badoo have never used this approach to version control. In our case, the following two options are more suitable.
Message Based Versioning
With this approach, after making changes to the function, a new message is created (data structure in protobuf) with a new set of fields. This approach works well if requirements change significantly.
For example, in the company Badoo each user has albums. Previously, users could create their own albums and put photos into them:
AddPhotoToAlbumV1 {
required string album_id = 1;
required string photo_id = 2;
}
Then the Product Owner decided that three predefined album types would be enough: my photos, other photos, and private photos. In order for clients to distinguish between these three types, it was necessary to add an enum; accordingly, the next version of the message will look like this:
AddPhotoToAlbumV2 {
required AlbumType album_type = 1;
required string photo_id = 2;
}
This approach is sometimes quite justified, but care must be taken. If the change is not quickly implemented on all platforms, you will have to maintain (by adding new changes) both old and new versions, that is, chaos will increase.
Field / Value Level
If possible, we use the same message or enumeration, deleting some fields / values or adding new ones. This is perhaps the most common approach in our practice.
Example:
AddPhotoToAlbum {
optional string album_id = 1 [deprecated=true];
optional string photo_id = 2;
optional AlbumType album_type = 3;
}
In this case, client applications continue to use the old message, and new versions of applications can use album_type instead of album_id.
By the way, we always use optional fields. This allows you to delete fields if necessary (Google developers have come to the same conclusion ).
Protocol change support
As mentioned earlier, our API is used by the server and five client platforms. New versions of our client applications are released every week (about 20 versions of applications per month, which can work differently and use different parts of the protocol), so we cannot simply create a new version of the protocol for each new version of the application. This approach to protocol versioning will require the server to support thousands of different application combinations. This solution is far from ideal.
Therefore, we stopped at the option where each application immediately sends to the server information about which protocol versions it supports. In this case, the server can interact with any client application, simply relying on the list of supported features provided by the application itself.
For example, we recently implemented the “What's New” feature. Thus, we inform our users about new features in the application. Applications that support this feature send the SUPPORTS_WHATS_NEW flag to the server. As a result, the server knows that it is possible to send messages to the client about new features and they will be displayed normally.
How to maintain order in the API?
If this is a public API, then a specific date is usually determined after the occurrence of which the old part stops working. For Badoo, this is almost impossible, since it is more important for us to implement new functions than to remove support for old ones. In this situation, we follow the procedure consisting of three stages.
At the first stage, as soon as we finally decided that a part of the protocol should be removed, it is marked as “outdated”, and application developers for all client platforms receive the task of deleting the corresponding code.
At the second stage, the outdated part of the protocol should be removed from the code of all clients, but on the server it is impossible to delete this code for quite a long time - not all users update their applications quickly.
At the last stage, when outdated code is removed from all client applications, and none of the versions that use this part of the protocol is used anymore, it can be removed from the server code and from the API.
Communication
In this article, we described several technical and organizational approaches that we borrowed or created ourselves. However, we did not address the issues of communication at all. But communication is 80% of our work. It is often necessary to discuss the feature itself and possible implementation paths with a large number of people before it can be understood how this feature can be implemented at the protocol level.
The basis of any successful project is the hard work of a well-coordinated team. Fortunately, most developers support us, because they are well aware of how difficult it is to work with solutions for various platforms without standardization.
We realized that a well-documented API also helps people who are not developers to understand the API itself and its development process. Testers turn to documentation during testing, and Product Owners use it to think through solutions to the tasks with minimal changes in the protocol (yes, we have such cool Product Owners!).
Conclusion
When developing flexible APIs and related processes, you must be patient and pragmatic. The protocol and process should work with various combinations of commands, software versions and platforms, outdated versions of the application, and also take into account many other factors. Nevertheless, this is a very interesting task, on which very little information is currently published. Therefore, we were very happy to share our work in this direction. Thanks for attention!
Source: https://habr.com/ru/post/305888/
All Articles