Go Way: how garbage collection accelerated
Go language in Twitch is used in many loaded systems. Simplicity, security, performance and readability make it a good tool for solving problems encountered by services, such as video streaming and the correspondence service of millions of users.
But this article is not another Go. It is about how our use of this language pushes some of the boundaries of the current runtime implementation and how we react to the achievement of these borders.
This is a story about how improving runtime from Go 1.4 to Go 1.6 gave us a 20-fold reduction in pauses when the garbage collector works, how we got another 10-fold reduction in pauses in Go 1.6 and how, passing our experience to the development team working over runtime Go, provided 10-fold acceleration in Go 1.7 without additional manual settings on our side.
Our IRC-based chat system was first implemented on Go at the end of 2013. It replaced the previous implementation in Python. For its creation, pre-release versions of Go 1.2 were used, and the system was able to simultaneously serve up to 500,000 users from each physical host without any special tricks.
')
When servicing each connection with a group of three gorutins (lightweight execution threads in Go), the program scrapped 1,500,000 gorutins per process. And even with such a number of them, the only serious performance problem that we encountered in versions prior to Go 1.2 was the length of pauses for garbage collection. The application stopped for tens of seconds each time the builder started, and this was unacceptable for our interactive chat service.
Not only that each pause for garbage collection was very expensive, so the assembly was launched several times a minute. We spent a lot of effort on reducing the number and size of allocated blocks of memory so that the collector runs less frequently. For us, an increase in heap (heap) of only 50% every two minutes was a victory. And although the pauses were less, they remained very long.
After the release of Go 1.2, the pauses were reduced “just” to a few seconds. We distributed traffic across more processes, which made it possible to reduce the duration of pauses to a more comfortable value.
Work on reducing memory allocation on our chat server continues to bring benefits even now, despite the development of Go, but splitting into several processes is a workaround for only certain versions of Go. Such tricks do not stand the test of time, but are important for the solution of short-term tasks to ensure quality service. And if we share with each other the experience of using workarounds, it will help to make improvements in runtime Go that will benefit the whole community, not just one program.
Starting in Go 1.5 in August 2015, the Go garbage collector began to work mostly competitively and incrementally. This means that almost all work is performed without a complete stop of the application. In addition to the fact that the preparation and interruption phases are rather short, our program continues to work while the garbage collection process is already underway. The transition to Go 1.5 instantly led to a 10-fold reduction in the pauses in our chat system: with a large load in the test environment, from two seconds to approximately 200 ms.
Although reducing the delay in Go 1.5 was in itself a holiday for us, the best feature of the new garbage collector was that it set the stage for further consistent improvements.
Garbage collection in Go 1.5 still consists of two main phases:
But each of these phases now consists of two stages:
The
Of course, we needed to collect more details about the work of the collector during pauses. The basic packages in Go include a wonderful user-level CPU profiler , but for our task we used the perf tool from Linux. While in the core, it allows you to get samples with higher frequency and visibility. Monitoring kernel loops can help us debug slow system calls and make virtual memory management transparent.
Below is a profile view of our chat server running Go 1.5.1. The graph (Flame Graph) is constructed using the Brendan Gregg tool . Only those samples are included that have the
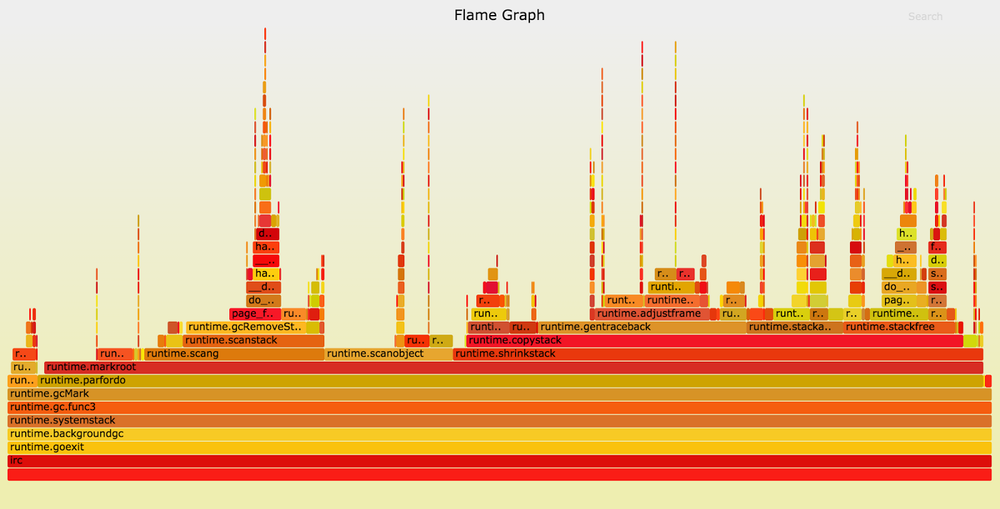
The peaks in the graph show an increase in the stack depth, and the width of each section reflects the CPU time. On the colors and order on the X axis do not pay attention, they do not matter. On the left side of the graph, we see that in almost each of the sample stacks,
The
Go to
It seemed to us that it was worthy of the Go team. We wrote to the developers, and they really helped us with their tips on how to diagnose performance problems and how to highlight them in minimal test cases. In Go 1.6, developers moved the scan of finalizers to the parallel mark-phase, which made it possible to reduce the pause in applications with a large number of TCP connections. Many other improvements were made, as a result of the transition to Go 1.6, the pauses on our chat server were reduced by half compared to Go 1.5 - to 100 ms. Progress!
The approach to concurrency adopted in Go implies the cheapness of using a large number of Gorutin. If an application that uses 10,000 OS threads can run slowly, for gorutin, that number is fine. Unlike the traditional large fixed-size stacks, the gorutines start with a very small stack — just 2 Kb — that grows as needed. At the beginning of a function call, Go checks whether the stack size is sufficient for the next call. And if not, before continuing with the call, the stack of the gorutina moves to a larger memory area, overwriting pointers if necessary.
Consequently, as the application runs, the gorutin stacks grow in order to fulfill the deepest challenges. The task of the garbage collector is to return unused memory. The function of the
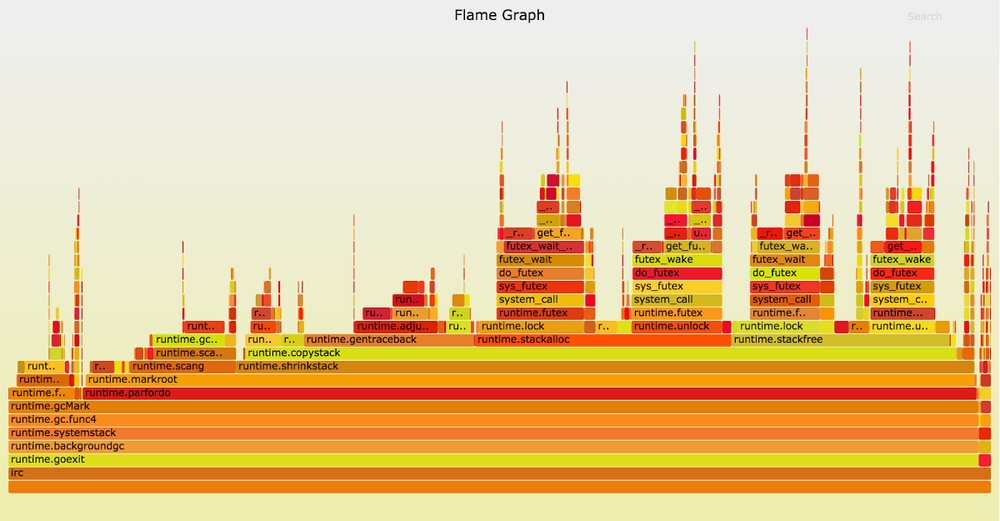
This graph is recorded on pre-release version 1.6 dated October 2015.
The Go runtime documentation explains how to disable stack reductions. For our chat server, the loss of some part of the memory is a small fee for reducing pauses for garbage collection. We did so by going to Go 1.6. After turning off the stack reduction, the duration of the pauses was reduced to 30–70 ms, depending on the “wind direction”.
The structure and layout of our chat server almost did not change, but from multi-second pauses in Go 1.2 we reached 200 ms in Go 1.5, and then to 100 ms in Go 1.6. In the end, most of the pauses were shorter than 70 ms, that is, we received an improvement of more than 30 times.
But surely there should be potential for further improvement. It's time to shoot the profile again!
Up to this point, the variation in the length of the pauses was small. But now they began to vary widely (from 30 to 70 ms), without correlating with any
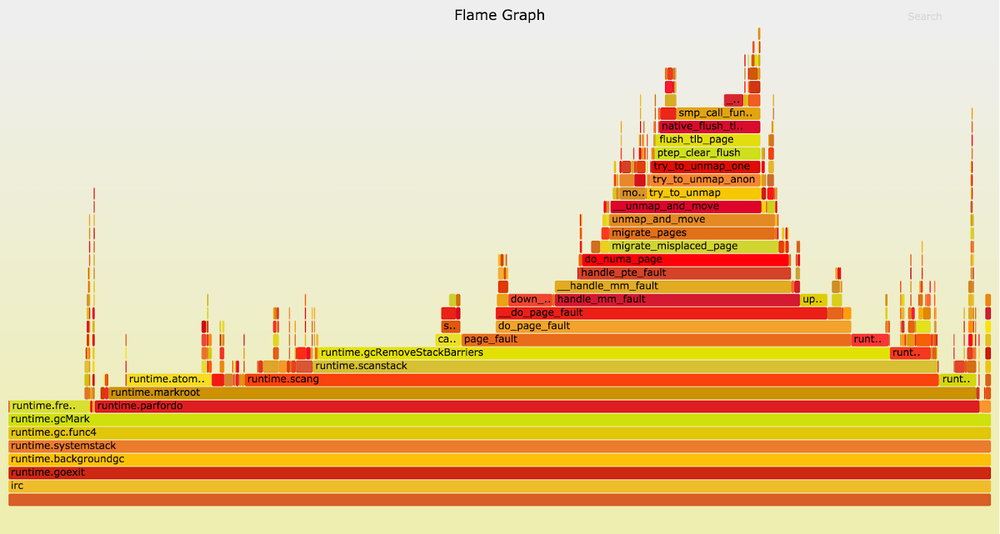
When the garbage collector calls the
The
Hint may be hiding in our equipment. For chat systems we use modern dual-processor servers. Several memory banks are directly connected to each socket. This configuration allows for non-uniform memory access (NUMA, Non-Uniform Memory Access). When a thread (thread) is executed in socket core 0, it has faster access to the memory connected to this socket than to the rest of the memory. The Linux kernel tries to reduce this difference by running threads on the kernel to which the memory they use is connected, and moving pages of physical memory “closer” to the corresponding threads.
Given this scheme, let's take a closer look at the behavior of the
The Linux kernel picked up the almost meaningless memory access patterns during the interruption of the mark-phase and because of them transfers memory pages that cost us dearly. This behavior was very weak in the Go 1.5.1 chart, but when we noticed
Here the benefits of profiling with perf are most clearly manifested. This tool can show kernel stacks, while a user-level Go profiler would only show that Go functions are inexplicably slow. Perf is much harder to use, it requires root access to view kernel stacks and in Go 1.5 and 1.6 it requires the use of a non-standard toolchain (GOEXPERIMENT = framepointer ./make.bash, in Go 1.7 will be standard). But solving the problems described is worth the effort.
If using two sockets and two memory banks is difficult, let's reduce the number. It is best to use the

After being tied to a single NUMA node, the duration of the interruption of the mark phase decreased to 10-15 ms. Significant improvement compared to 200 ms in Go 1.5 or two seconds in Go 1.4. The same result can be obtained without sacrificing half the server. It is enough to set the process memory
Up to Go 1.6, we disabled the stack reduction feature. This had a minimal impact on the use of memory by our chat server, but significantly increased operational complexity. For some applications, stack reduction plays a very large role, so we turned off this feature very selectively. In Go 1.7, the stack is now reduced right while the application is running. So we got the best of both worlds: low memory consumption without special settings.
Since the appearance of a concurrently running garbage collector in Go 1.5, the runtime tracks whether each gorutin has been executed since its last scan. During the interruption of the mark-phase, gorutines that have recently been executed and are scanned are again detected. In Go 1.7 runtime maintains a hotel short list of such gorutin. This allows you to no longer search the entire list of gorutins when the code is paused, and greatly reduces the number of memory accesses that can trigger the memory migration in accordance with NUMA algorithms.
Finally, AMD64 compilers by default support frame pointers, so standard debugging and performance tools like perf can define the current function call stack. Users who build their applications using Go packages prepared for their platform can, if necessary, select more advanced tools without learning the rebuild toolchain and rebuild / redeploy their apps. This promises a good future in terms of further improvements in the performance of basic packages and Go runtime, when engineers like me and you will be able to collect enough information for high-quality reports.
In the pre-release version of Go 1.7 of June 2016, the pauses for garbage collection became even smaller, without any additional tweaks. At our server they are “out of the box” close to 1 ms - ten times less compared to the configured Go 1.6 configuration!
Our experience has helped the Go development team find a permanent solution to the problems we have encountered. For applications like ours, when going from Go 1.5 to 1.6, profiling and tuning allowed us to reduce pauses by a factor of ten. But in Go 1.7, developers were able to achieve an already 100-fold difference compared to Go 1.5. Hats off to their efforts to improve runtime performance.
All this analysis is devoted to the curse of our chat server - pauses in work, but this is only one measure of the performance of the garbage collector. Having solved the pause problem, the Go developers can now tackle the bandwidth problem.
According to the description of the transaction collector ( Transaction Oriented Collector ), it uses the approach of transparent low-cost allocation and assembly of memory, which is not shared by the gorutines. This will postpone the need for a full-fledged launch of the collector and reduce the total number of CPU cycles per garbage collection.
But this article is not another Go. It is about how our use of this language pushes some of the boundaries of the current runtime implementation and how we react to the achievement of these borders.
This is a story about how improving runtime from Go 1.4 to Go 1.6 gave us a 20-fold reduction in pauses when the garbage collector works, how we got another 10-fold reduction in pauses in Go 1.6 and how, passing our experience to the development team working over runtime Go, provided 10-fold acceleration in Go 1.7 without additional manual settings on our side.
The beginning of the saga of pauses for garbage collection
Our IRC-based chat system was first implemented on Go at the end of 2013. It replaced the previous implementation in Python. For its creation, pre-release versions of Go 1.2 were used, and the system was able to simultaneously serve up to 500,000 users from each physical host without any special tricks.
')
When servicing each connection with a group of three gorutins (lightweight execution threads in Go), the program scrapped 1,500,000 gorutins per process. And even with such a number of them, the only serious performance problem that we encountered in versions prior to Go 1.2 was the length of pauses for garbage collection. The application stopped for tens of seconds each time the builder started, and this was unacceptable for our interactive chat service.
Not only that each pause for garbage collection was very expensive, so the assembly was launched several times a minute. We spent a lot of effort on reducing the number and size of allocated blocks of memory so that the collector runs less frequently. For us, an increase in heap (heap) of only 50% every two minutes was a victory. And although the pauses were less, they remained very long.
After the release of Go 1.2, the pauses were reduced “just” to a few seconds. We distributed traffic across more processes, which made it possible to reduce the duration of pauses to a more comfortable value.
Work on reducing memory allocation on our chat server continues to bring benefits even now, despite the development of Go, but splitting into several processes is a workaround for only certain versions of Go. Such tricks do not stand the test of time, but are important for the solution of short-term tasks to ensure quality service. And if we share with each other the experience of using workarounds, it will help to make improvements in runtime Go that will benefit the whole community, not just one program.
Starting in Go 1.5 in August 2015, the Go garbage collector began to work mostly competitively and incrementally. This means that almost all work is performed without a complete stop of the application. In addition to the fact that the preparation and interruption phases are rather short, our program continues to work while the garbage collection process is already underway. The transition to Go 1.5 instantly led to a 10-fold reduction in the pauses in our chat system: with a large load in the test environment, from two seconds to approximately 200 ms.
Go 1.5 - a new era of garbage collection
Although reducing the delay in Go 1.5 was in itself a holiday for us, the best feature of the new garbage collector was that it set the stage for further consistent improvements.
Garbage collection in Go 1.5 still consists of two main phases:
- Mark - first marked those memory areas that are still used;
- Sweep - all unused areas are prepared for reuse.
But each of these phases now consists of two stages:
- Mark:
- the application is suspended, waiting for the completion of the previous sweep-phase;
- then, simultaneously with the operation of the application, a search for used memory blocks is performed.
- Sweep:
- the application is paused again to interrupt the mark-phase;
- simultaneously with the operation of the application, unused memory is gradually being prepared for reuse.
The
gctrace runtime function allows you to display information on the results of each iteration of the garbage collection, including the duration of all phases. For our chat server, it showed that most of the pause falls on the interruption of the mark phase, so we decided to focus our attention on this. And although the Go development team responsible for runtime asked for bug reports from applications that have long pauses for garbage collection, we were slobs and kept it secret!Of course, we needed to collect more details about the work of the collector during pauses. The basic packages in Go include a wonderful user-level CPU profiler , but for our task we used the perf tool from Linux. While in the core, it allows you to get samples with higher frequency and visibility. Monitoring kernel loops can help us debug slow system calls and make virtual memory management transparent.
Below is a profile view of our chat server running Go 1.5.1. The graph (Flame Graph) is constructed using the Brendan Gregg tool . Only those samples are included that have the
runtime.gcMark function in the stack, in Go 1.5 approximating the time spent interrupting the mark-phase.The peaks in the graph show an increase in the stack depth, and the width of each section reflects the CPU time. On the colors and order on the X axis do not pay attention, they do not matter. On the left side of the graph, we see that in almost each of the sample stacks,
runtime.gcMark calls runtime.parfordo . Having looked above, we notice that most of the time is taken by runtime.markroot runtime.scang , runtime.scanobject and runtime.shrinkstack .The
runtime.scang function runtime.scang designed to rescan memory to help complete the mark-phase. The essence of the interruption lies in ending the application’s memory scan, so this work is absolutely necessary. It is better to figure out how to improve the performance of other functions.Go to
runtime.scanobject . This function has several tasks, but its execution during the interruption of the mark-phase in Go 1.5 is necessary for the implementation of finalizers (the function performed before the object is deleted by the garbage collector. - Note of the translator). You may ask: “Why does the program use so many finalizers that they significantly affect the duration of pauses during garbage collection?” In this case, the application is a chat server that processes messages from hundreds of thousands of users. The main “network” packet in Go attaches a finalizer to each TCP connection to help manage the leaks of file descriptors. And since each user gets their own TCP connection, this makes a small contribution to the duration of the interruption of the mark phase.It seemed to us that it was worthy of the Go team. We wrote to the developers, and they really helped us with their tips on how to diagnose performance problems and how to highlight them in minimal test cases. In Go 1.6, developers moved the scan of finalizers to the parallel mark-phase, which made it possible to reduce the pause in applications with a large number of TCP connections. Many other improvements were made, as a result of the transition to Go 1.6, the pauses on our chat server were reduced by half compared to Go 1.5 - to 100 ms. Progress!
Stack reduction
The approach to concurrency adopted in Go implies the cheapness of using a large number of Gorutin. If an application that uses 10,000 OS threads can run slowly, for gorutin, that number is fine. Unlike the traditional large fixed-size stacks, the gorutines start with a very small stack — just 2 Kb — that grows as needed. At the beginning of a function call, Go checks whether the stack size is sufficient for the next call. And if not, before continuing with the call, the stack of the gorutina moves to a larger memory area, overwriting pointers if necessary.
Consequently, as the application runs, the gorutin stacks grow in order to fulfill the deepest challenges. The task of the garbage collector is to return unused memory. The function of the
runtime.shrinkstack is responsible for moving the gorutin stacks to more suitable memory runtime.shrinkstack , which in Go 1.5 and 1.6 is performed during the interruption of the mark-phase, when the application pauses.This graph is recorded on pre-release version 1.6 dated October 2015.
runtime.shrinkstack takes about three-fourths of the samples. If this function were performed while the application was running, we would get a serious reduction in pauses on our chat server and other similar applications.The Go runtime documentation explains how to disable stack reductions. For our chat server, the loss of some part of the memory is a small fee for reducing pauses for garbage collection. We did so by going to Go 1.6. After turning off the stack reduction, the duration of the pauses was reduced to 30–70 ms, depending on the “wind direction”.
The structure and layout of our chat server almost did not change, but from multi-second pauses in Go 1.2 we reached 200 ms in Go 1.5, and then to 100 ms in Go 1.6. In the end, most of the pauses were shorter than 70 ms, that is, we received an improvement of more than 30 times.
But surely there should be potential for further improvement. It's time to shoot the profile again!
Page fault'y ?!
Up to this point, the variation in the length of the pauses was small. But now they began to vary widely (from 30 to 70 ms), without correlating with any
gctrace results. Here is a schedule of cycles during fairly long pauses of the interruption of the mark phase:When the garbage collector calls the
runtime.gcRemoveStackBarriers , the system generates a page fault error, which causes the page_fault kernel function to be page_fault . This reflects a wide "tower" to the right of the center of the graph. Using page faults, the kernel distributes virtual memory pages (usually 4 KB in size) in physical memory. Often, processes can accommodate huge amounts of virtual memory, which is converted to resident when the application is accessed only through page faults.The
runtime.gcRemoveStackBarriers function converts the stack memory that the application recently accessed. In fact, it is intended to remove stack barriers added some time before, at the beginning of the garbage collection cycle. The system has enough memory available, it does not assign physical memory to some other, more active processes. So why does access to it lead to errors?Hint may be hiding in our equipment. For chat systems we use modern dual-processor servers. Several memory banks are directly connected to each socket. This configuration allows for non-uniform memory access (NUMA, Non-Uniform Memory Access). When a thread (thread) is executed in socket core 0, it has faster access to the memory connected to this socket than to the rest of the memory. The Linux kernel tries to reduce this difference by running threads on the kernel to which the memory they use is connected, and moving pages of physical memory “closer” to the corresponding threads.
Given this scheme, let's take a closer look at the behavior of the
page_fault kernel page_fault . If you look at the call stack (above in the graph), you will see that the kernel calls do_numa_page and migrate_misplaced_page . This means that the kernel moves the application's memory between banks of physical memory.The Linux kernel picked up the almost meaningless memory access patterns during the interruption of the mark-phase and because of them transfers memory pages that cost us dearly. This behavior was very weak in the Go 1.5.1 chart, but when we noticed
runtime.gcRemoveStackBarriers , it became much more noticeable.Here the benefits of profiling with perf are most clearly manifested. This tool can show kernel stacks, while a user-level Go profiler would only show that Go functions are inexplicably slow. Perf is much harder to use, it requires root access to view kernel stacks and in Go 1.5 and 1.6 it requires the use of a non-standard toolchain (GOEXPERIMENT = framepointer ./make.bash, in Go 1.7 will be standard). But solving the problems described is worth the effort.
Migration Management
If using two sockets and two memory banks is difficult, let's reduce the number. It is best to use the
taskset command, which can force the application to work on the cores of only one socket. As program threads access memory from a single socket, the kernel will transfer their data to the appropriate banks.After being tied to a single NUMA node, the duration of the interruption of the mark phase decreased to 10-15 ms. Significant improvement compared to 200 ms in Go 1.5 or two seconds in Go 1.4. The same result can be obtained without sacrificing half the server. It is enough to set the process memory
MPOL_BIND policy set_mempolicy(2) using set_mempolicy(2) or mbind(2) . The profile shown was obtained on the pre-release version of Go 1.6 in October 2015. The left side shows that execution of runtime.freeStackSpans takes a lot of time. After this function has been moved to the garbage collection phase executed in parallel, it no longer affects the length of the pause. Little can now be removed from the mark-phase interruption stage!Go 1.7
Up to Go 1.6, we disabled the stack reduction feature. This had a minimal impact on the use of memory by our chat server, but significantly increased operational complexity. For some applications, stack reduction plays a very large role, so we turned off this feature very selectively. In Go 1.7, the stack is now reduced right while the application is running. So we got the best of both worlds: low memory consumption without special settings.
Since the appearance of a concurrently running garbage collector in Go 1.5, the runtime tracks whether each gorutin has been executed since its last scan. During the interruption of the mark-phase, gorutines that have recently been executed and are scanned are again detected. In Go 1.7 runtime maintains a hotel short list of such gorutin. This allows you to no longer search the entire list of gorutins when the code is paused, and greatly reduces the number of memory accesses that can trigger the memory migration in accordance with NUMA algorithms.
Finally, AMD64 compilers by default support frame pointers, so standard debugging and performance tools like perf can define the current function call stack. Users who build their applications using Go packages prepared for their platform can, if necessary, select more advanced tools without learning the rebuild toolchain and rebuild / redeploy their apps. This promises a good future in terms of further improvements in the performance of basic packages and Go runtime, when engineers like me and you will be able to collect enough information for high-quality reports.
In the pre-release version of Go 1.7 of June 2016, the pauses for garbage collection became even smaller, without any additional tweaks. At our server they are “out of the box” close to 1 ms - ten times less compared to the configured Go 1.6 configuration!
Our experience has helped the Go development team find a permanent solution to the problems we have encountered. For applications like ours, when going from Go 1.5 to 1.6, profiling and tuning allowed us to reduce pauses by a factor of ten. But in Go 1.7, developers were able to achieve an already 100-fold difference compared to Go 1.5. Hats off to their efforts to improve runtime performance.
What's next
All this analysis is devoted to the curse of our chat server - pauses in work, but this is only one measure of the performance of the garbage collector. Having solved the pause problem, the Go developers can now tackle the bandwidth problem.
According to the description of the transaction collector ( Transaction Oriented Collector ), it uses the approach of transparent low-cost allocation and assembly of memory, which is not shared by the gorutines. This will postpone the need for a full-fledged launch of the collector and reduce the total number of CPU cycles per garbage collection.
Source: https://habr.com/ru/post/305614/
All Articles