Who is aggregated by Meduza?
Hegel believed that society becomes modern when news replaces religion.
The News: A User's Manual, Alain de Botton
Read all the news has become extremely impossible. And it's not just that Stephen Bushemi writes them in between bowling with Lebowski, but rather that there are too many of them. Here news aggregators come to the rescue and the question naturally arises: who and how do they aggregate?
Noticing a couple of interesting articles on Habré about the API and data collection of the popular Meduza news site, I decided to uncover the Perseus shield and continue the glorious affair. Meduza monitors a variety of different news sites, and today we will understand which sources prevail in it, whether they can be grouped intelligently and whether there is a core here that forms the backbone of the news feed.
A brief definition of what Meduza is:
"Remember how stupid people all the time called the" Tape "? They said that "Tape" - aggregator. And let’s make an aggregator ”( Forbes interview )
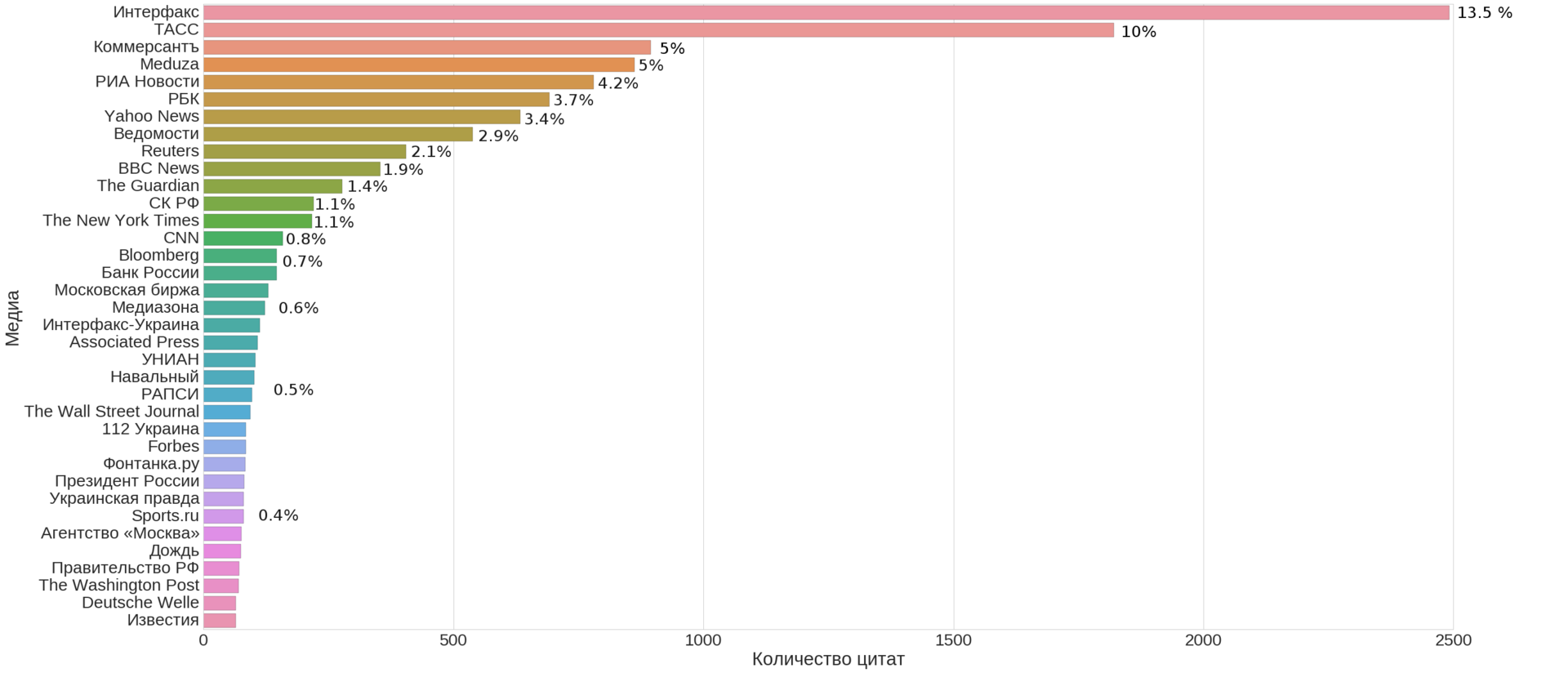
(this is not just KDPV, but the top 35 media by the number of news items listed as sources on the Meduza website, including its own)
We concretize and formalize the questions:
- Q 1 : What are the key sources of the news feed?
In other words, can we select a small number of sources that sufficiently cover the entire news feed?
- Q 2 : Is there some kind of simple and interpretable structure on them?
Simply put, can we cluster sources into meaningful groups?
- Q 3 : Is it possible to determine the general parameters of the aggregator by this structure?
General parameters here are values such as the amount of news in time.
What is the source?
Each news item on the site has a specified source, marked as an example in red below.
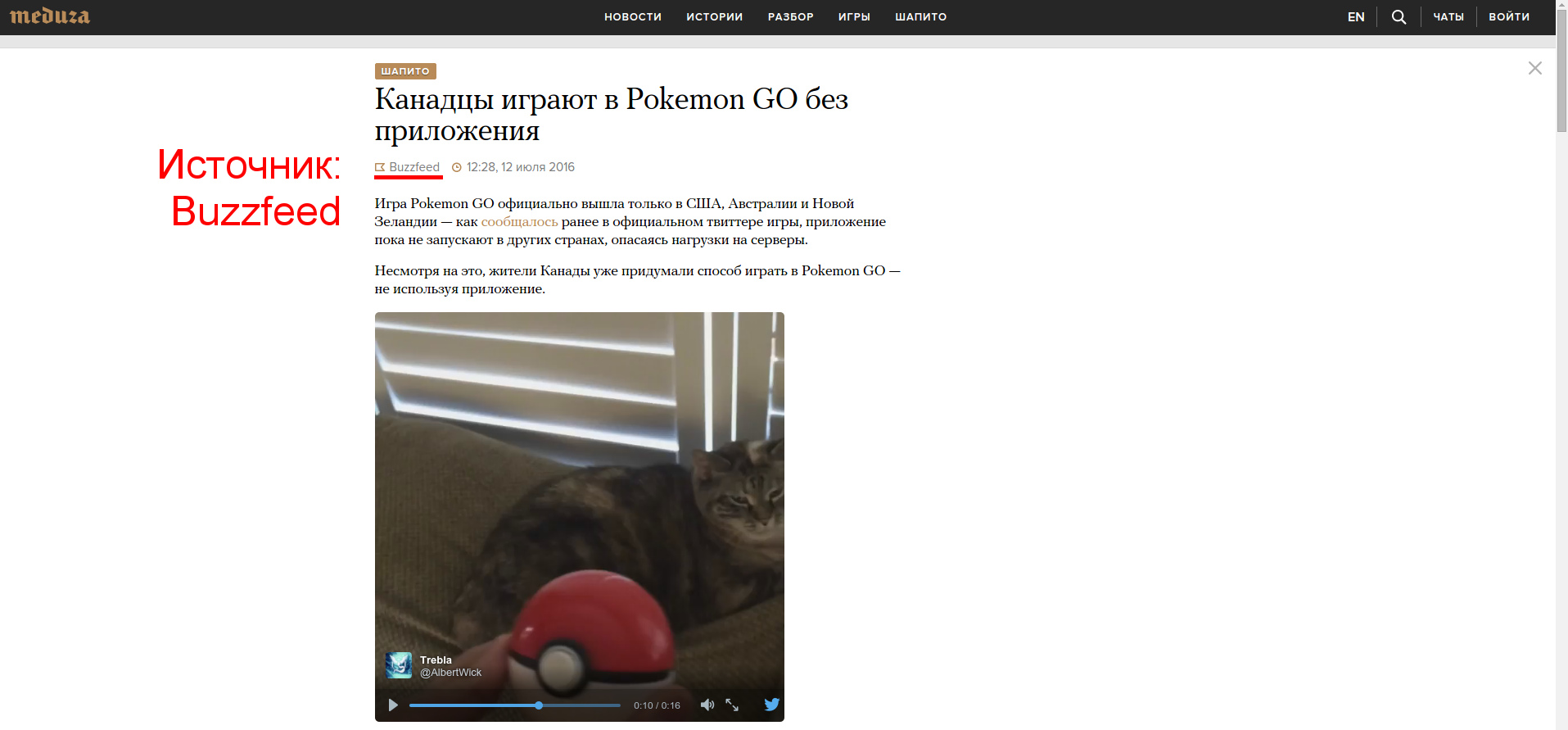
This parameter will be of particular interest to us today. For the analysis, we need to collect meta-data on all the news. To do this, Meduza has an internal API that can be used for its needs - the query below will return the 10 latest Russian-language news:
https://meduza.io/api/v3/search?chrono=news&page=0&per_page=10&locale=ru
Based on this Habra article with a brief description of the API and similar requests, we get the code for downloading data
import requests import json import time from tqdm import tqdm stream = 'https://meduza.io/api/v3/search?chrono=news&page={page}&per_page=30&locale=ru' social = 'https://meduza.io/api/v3/social' user_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.3411.123 YaBrowser/16.2.0.2314 Safari/537.36' headers = {'User-Agent' : user_agent } def get_page_data(page): # ans = requests.get(stream.format(page = page), headers=headers).json() # ans_social = requests.get(social, params = {'links' : json.dumps(ans['collection'])}, headers=headers).json() documents = ans['documents'] for url, data in documents.items(): try: data['social'] = ans_social[url]['stats'] except KeyError: continue with open('dump/page{pagenum:03d}_{timestamp}.json'.format(pagenum = page, timestamp = int(time.time())), 'w', encoding='utf-8') as f: json.dump(documents, f, indent=2) for i in tqdm(range(25000)): get_page_data(i) An example of what the data looks like to study:
affiliate NaN authors [] bg_image NaN chapters_count NaN chat NaN document_type news document_urls NaN full False full_width False fun_type NaN hide_header NaN image NaN keywords NaN layout_url NaN live_on NaN locale ru modified_at NaN one_picture NaN prefs NaN pub_date 2015-10-23 00:00:00 published_at 1445601270 pushed False second_title NaN share_message NaN social {'tw': 0, 'vk': 148, 'reactions': 0, 'fb': 4} source sponsored NaN sponsored_card NaN table_of_contents NaN tag {'name': '', 'path': ''} thesis NaN title topic NaN updated_at NaN url news/2015/10/23/rostrud-ob-yavil-o-prekraschen... version 2 vk_share_image /image/share_images/16851_vk.png?1445601291 webview_url NaN with_banners True fb 4 reactions 0 tw 0 vk 148 trust 3 Name: news/2015/10/23/rostrud-ob-yavil-o-prekraschenii-rosta-bezrabotitsy, dtype: object Data for the article was collected in mid-July 2016 and available here {git}.
Document types and source reliability
Let's start with the following simple question: what is the share of news among all the available documents and what type of distribution of document types does it have?
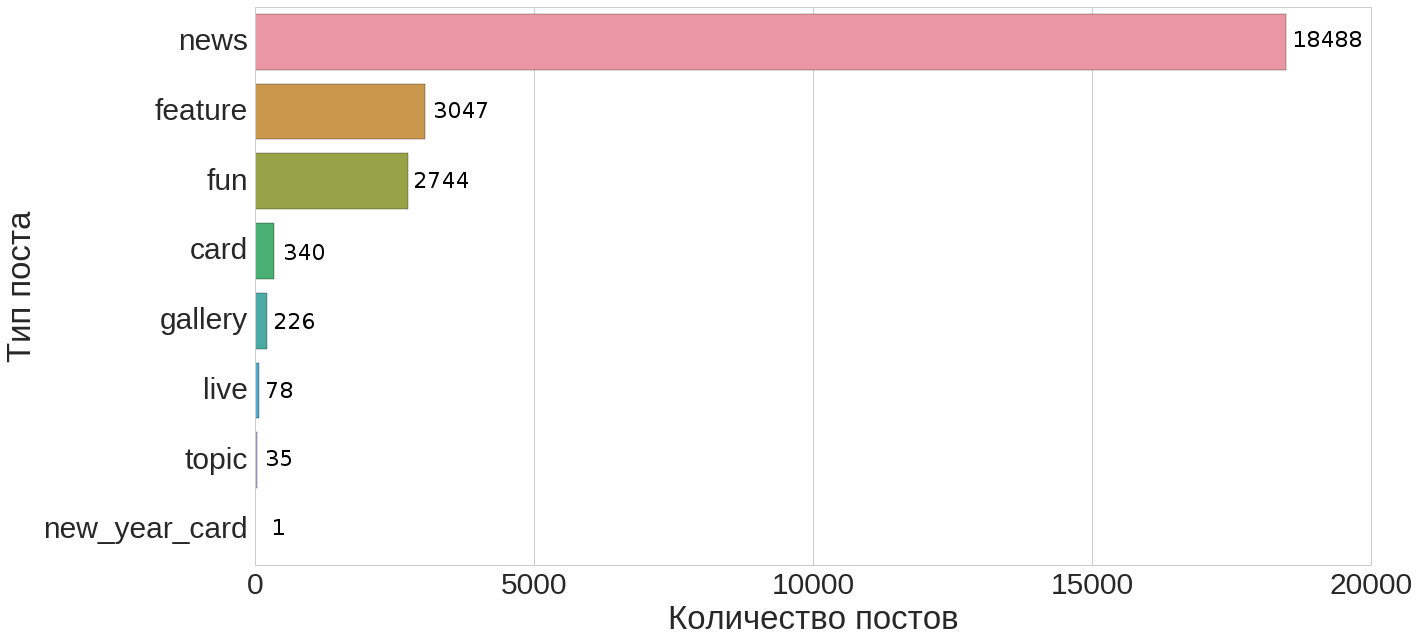
From this distribution it can be seen (for convenience, here is a tabular representation of this distribution below) that news makes up about 74% of all documents.
Next, we focus on the news and, as an illustration, consider the “source reliability” parameter, applicable only to news:
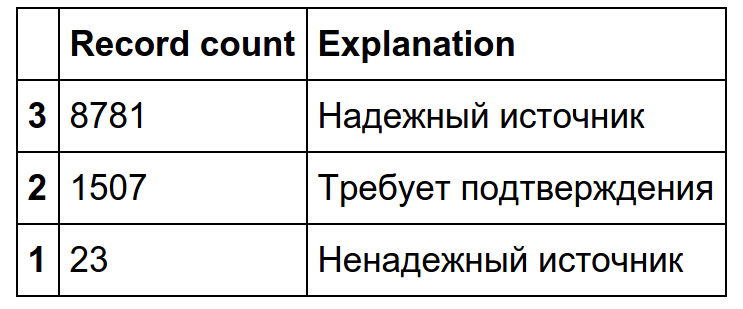
As we see, virtually all news falls into the category of "reliable source" or "requires confirmation."
Analysis and clustering of sources
On the very first graph (at the beginning of the article) we see that a significant contribution is made by several top sources. Let's take the sources, which account for about 100 links and try to find a structure on them.
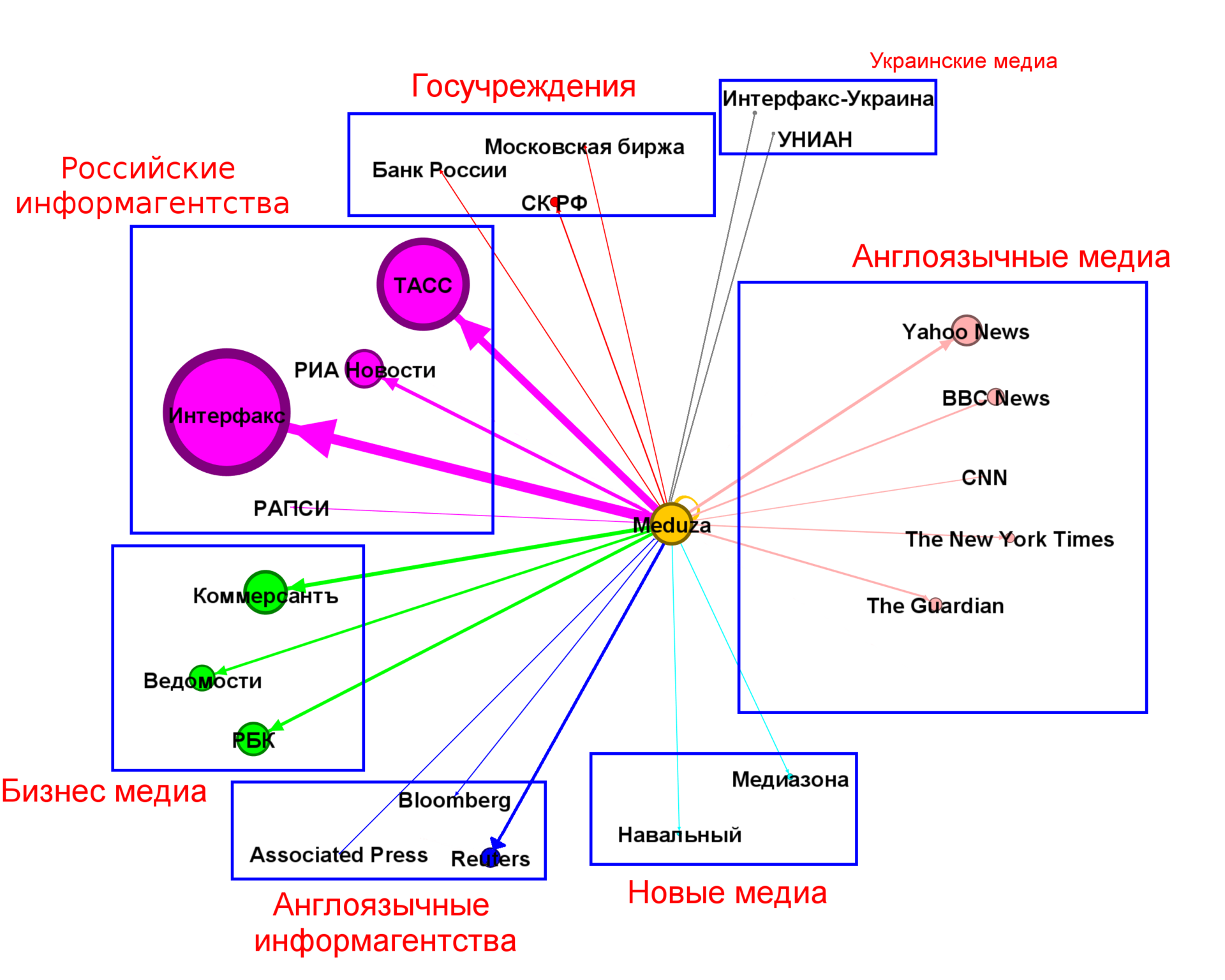
(the dimensions of the vertex and the arcs are proportional to the number of links)
Of course, the number of clusters and the partition itself may be different and in many respects here is subjective.
From the chart above, we see that the largest contribution is made by Russian news agencies ~ 30% of all news, followed by business media with ~ 11.5%, then English-language media transfers ~ 8.5% and world news agencies ~ 3.5%. Together, these four clusters cover most of the news (50% +). The remaining clusters <3%. Author's material (source: Meduza itself) is about 5%.
Analysis of the total number of publications
It is also interesting: how much the amount of news from various sources is comparable in time and whether we can take the top (for example, the top 10) and evaluate the general trend for the entire amount of news.
We see that only TASS and Interfax are quantitatively significantly different from the rest of the top, the other sources are quantitatively quite close to each other.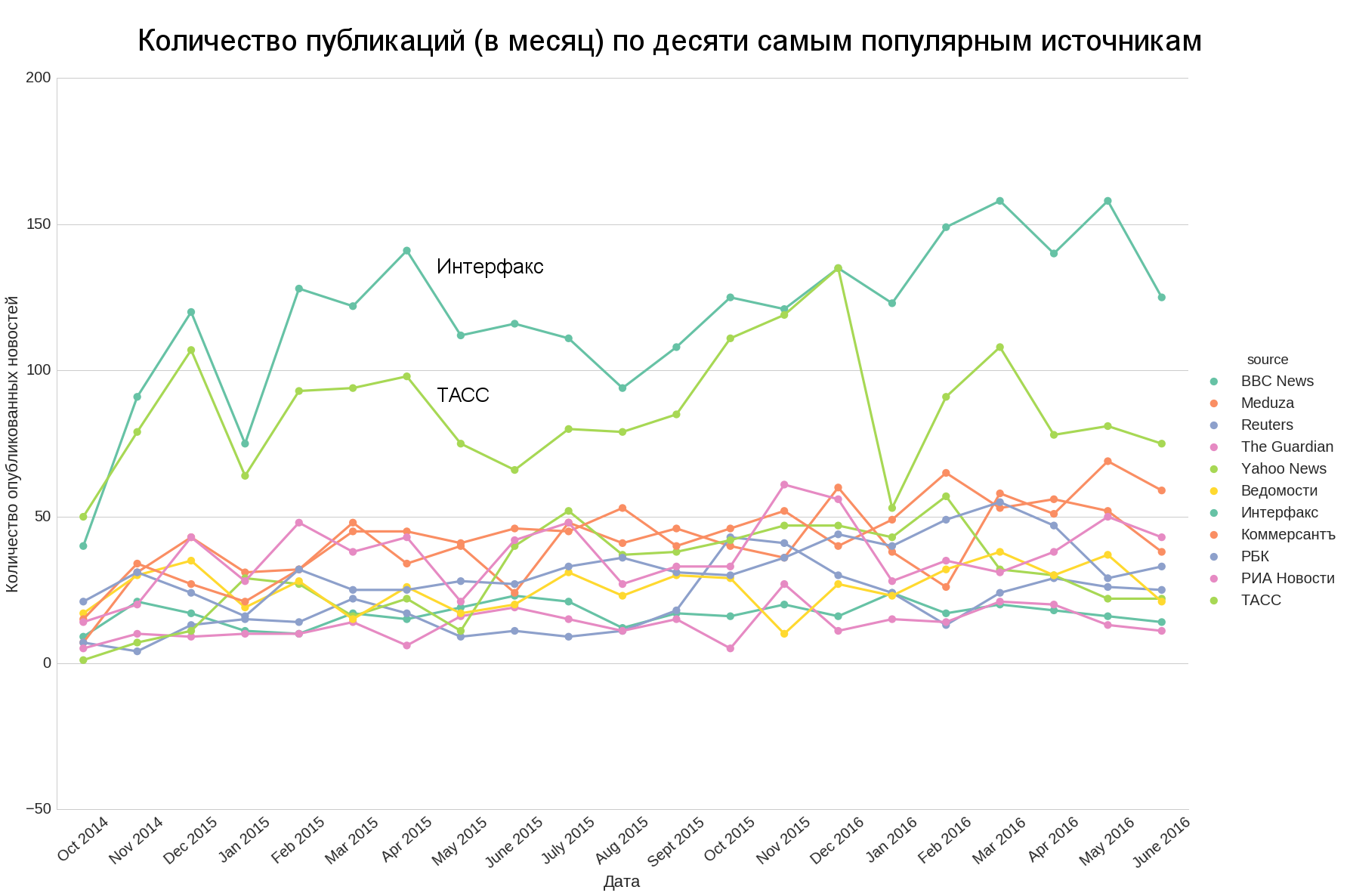
If we add the top 10 and the total number of news, we note that the first well approximates the second, that is, the number of news in the top 10 gives a good idea of the total number of news.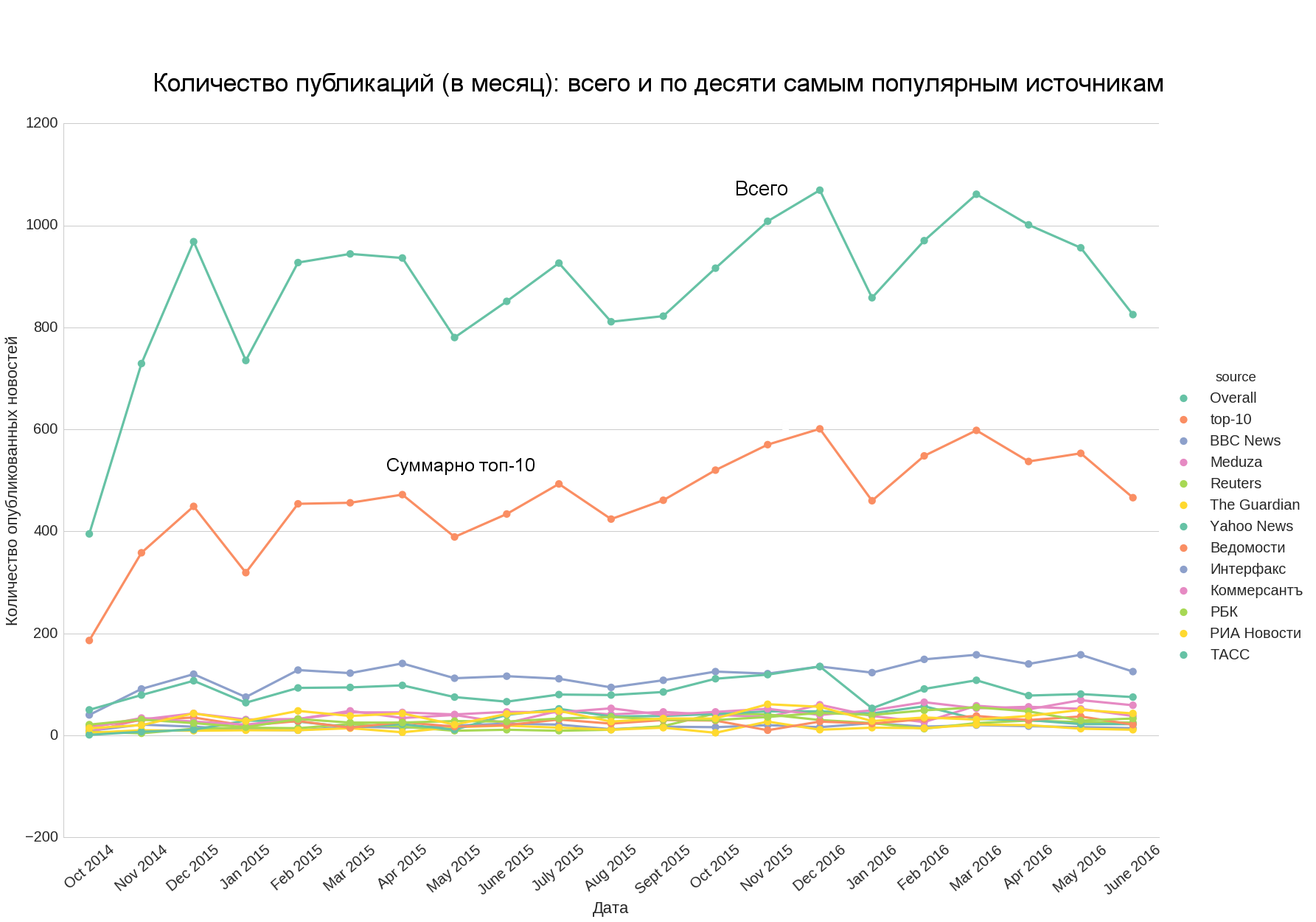
Comparison with Medialogy
The data and graphics in this part are taken from here .
It is interesting to look at how such a sample correlates with the overall ratings of quoted news on the network. Consider the available data medialogiya for May 2016:
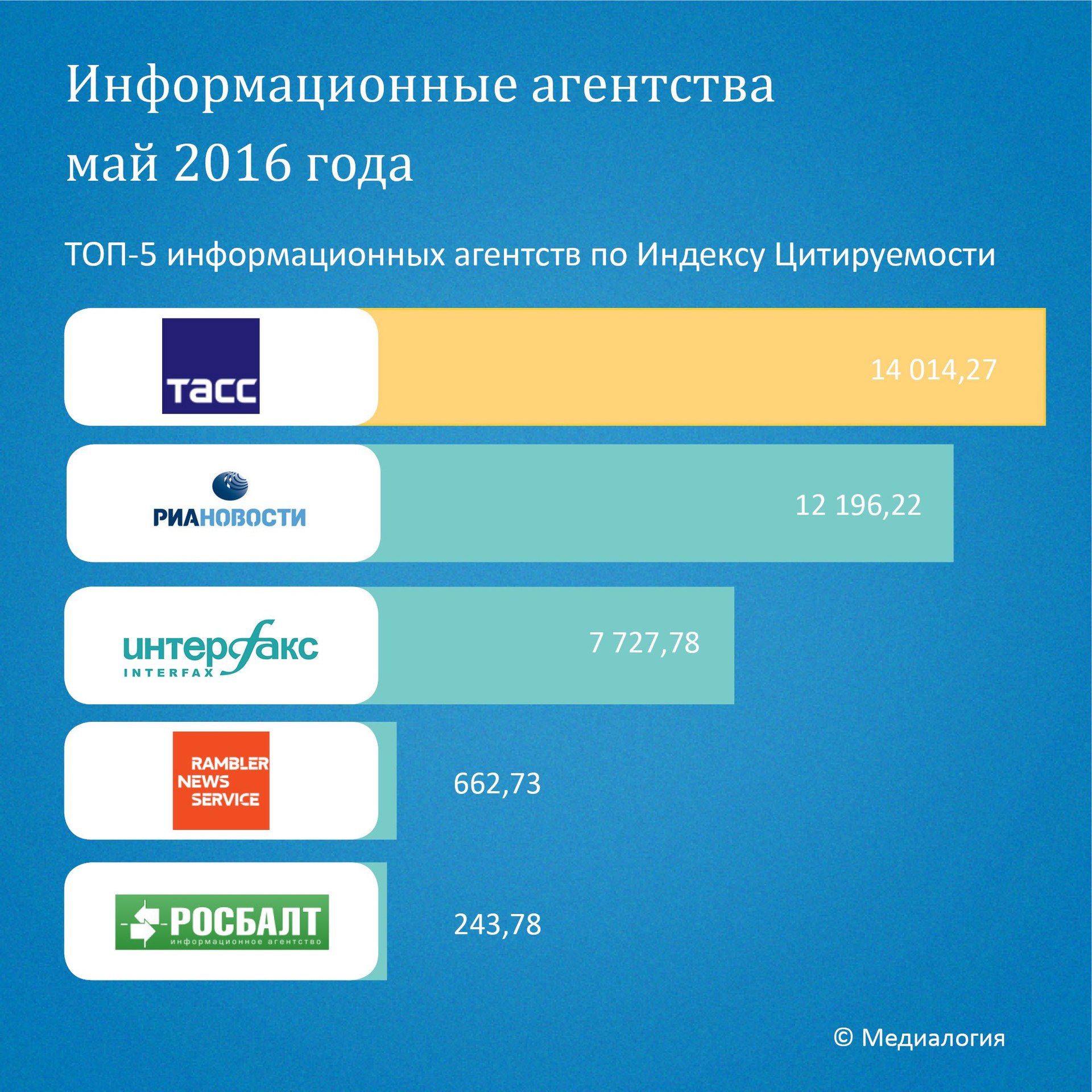
In general, we see that the troika is presented in the top just as well, although in a different order (which is quite natural, the aggregator may not necessarily deliver high-cited news to itself, for example, because it may consider it viral and unworthy of significant attention , or attributable to an unreliable source - which is consistent with the distribution of news reliability).
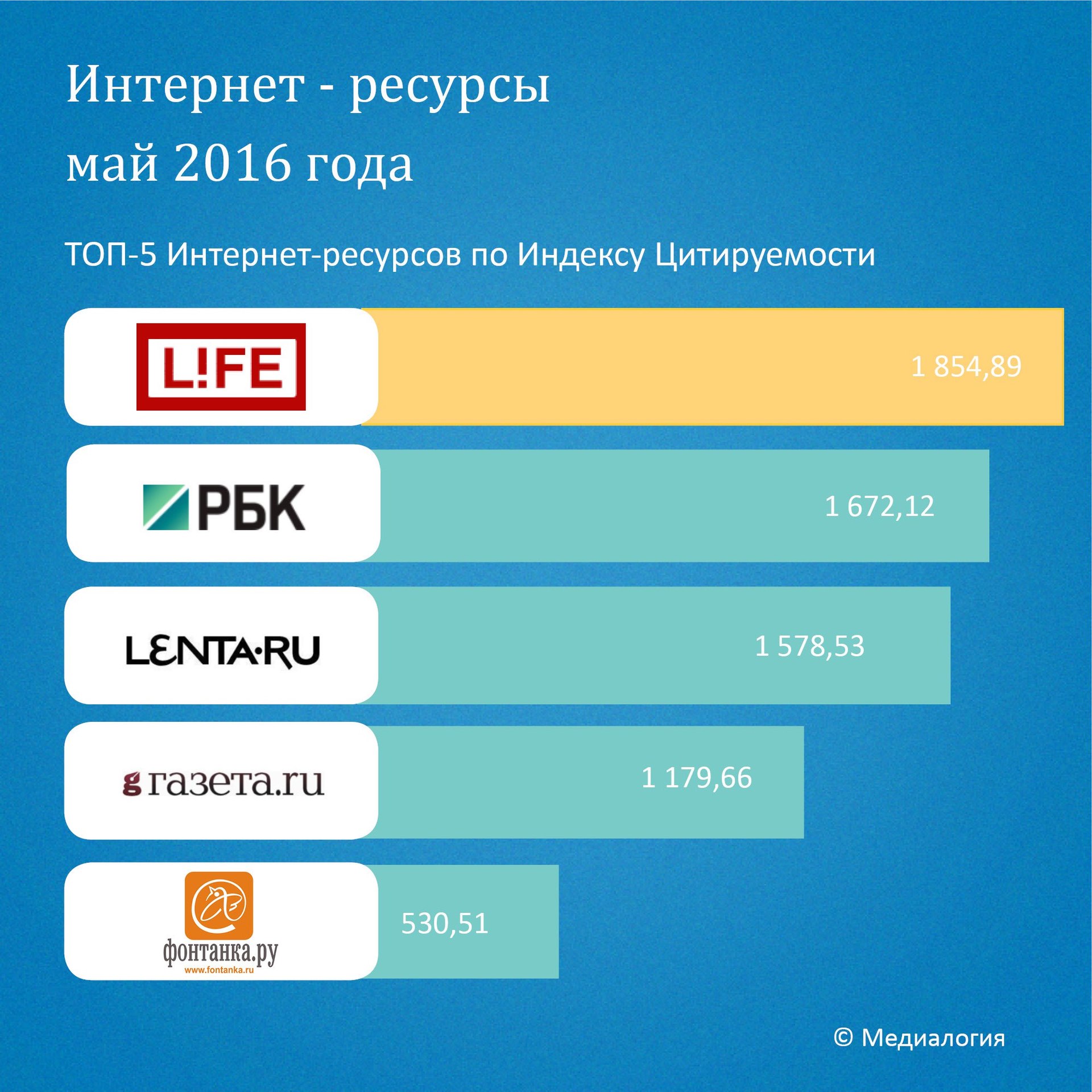

Conclusions and reference to data
Tezisno, conclusions on the issues at hand:
Q 1 : Top 10-15 news sources constituting the majority of news: Russian news agencies and business media, as well as translations of well-known international news agencies and media (more than half of all news) - see the first chart.
Q 2 : Seven clusters are identified on top sources: the four key sources listed above ( Q 1 ) cover most of the top sources and most of the news themselves - see the chart in the section “Analysis and Clustering of Sources”.
- Q 3 : Top 10 sources allow you to assess the overall trend in the number of news aggregator over time - see the graph in the "Analysis of the total number of publications" section.
Data (relevance - mid July 2016) are available in the git repository .
')
Source: https://habr.com/ru/post/305546/
All Articles