Isilon CloudPools Transparent Cloud Layered Storage

For several years now, the possibility of creating a multi-level storage based on EMC Isilon has been available. This implies the ability to send data to specific storage pools - systems of nodes that are combined on the basis of uniformity or density. As a result, data storage efficiency will greatly increase in terms of cost.
You can create a policy whereby all new data will be stored in Pula-1, built from fast S210 nodes.

')
The response time will be very short, but the cost will be higher (faster drives, processors, etc.). Next, you can create a second-level policy, for example, “move all data that you have not accessed for more than 30 days into Pool 2”. This complex can be built from X410 nodes with a larger capacity (36 SATA disks) and a higher response time compared to Poole-1. Even less demanded data can already be moved to Poole-3, built from HD400 nodes with very high storage density — 59 SATA drives + 1 SSD per each 4U module, but its response time is even longer than that of Tier 2. But since This level is intended only for very rarely requested data, it will not greatly affect users.
Data movement based on policies is performed in the background using the OneFS engine. This does not change the logical location of files. That is, you can create one folder, the files in which are located in three different repositories.
Pools and storage levels
The same data can go through different stages of the life cycle: raw data, raw, processed, duplicate, backup, archive. Each stage has its own set of requirements for accessibility and data integrity. Unlike many other storage systems in which different types of information are stored together, Isilon uses different levels of storage (Tier). For each level, certain policies are used for data separation, processing and storage. This approach allows you to reduce the cost of storing information that is in different stages of the life cycle, to process it faster and manage it more efficiently. These tasks are solved using storage levels, which, in turn, can be divided into more highly specialized pools.
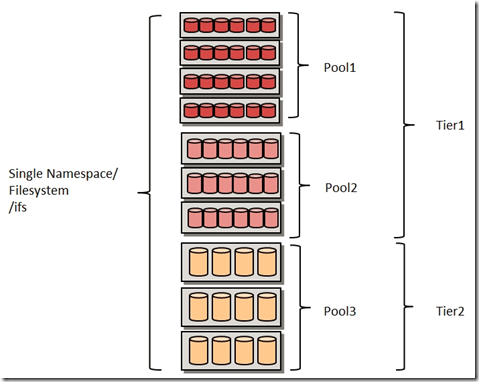
Single file system for all pools / storage levels.
Today there are several types of pools:
- S - fast, designed for transactional calculations.
- X - fast, designed for streaming tasks.
- NL - slower, designed to create "warm" archives.
- HD - slower, designed to create "cold" archives.
A fifth form also appeared - a cloud (external or internal).
As already mentioned, each pool is formed from nodes of the same type (in fact, they may differ slightly, but this is already beyond the scope of the post). If you have a very large cluster deployed, then it is reasonable to divide it into different levels of storage. Each level contains one or more pools. But in some cases there is no need for such a division. There may well be a situation where your policies will not imply the presence of pools or storage levels.
Politicians
Data tier distribution policies can be easily configured using the WebUI, CLI or API. At the same time, as criteria for creating a policy, you can use not only the frequency of accessing files, but also file types, their location, owner or any other attribute. The user interface already has pre-configured templates that you can use. For example, the Archive template contains the rules according to which older data is moved to the appropriate storage. And the ExtraProtect template helps to configure a higher level of protection for files with certain attribute values (for example, n + 3 instead of n + 2). At the same time using the WebUI is very simple, it is intuitive.

CloudPools - innovation in OneFS 8.0
One of the interesting innovations that appeared in OneFS 8.0, was a new type of pool - the cloud (Cloud). Now using the Object API, it supports:
- Amazon S3
- Microsoft Azure
- EMC Elastic Cloud Storage
- EMC Isilon
The latter two products, thanks to the support of a number of API Object REST, can be used to create a private cloud archive. You can probably expect the introduction of support from other cloud storage providers, such as Google and Virtustream .
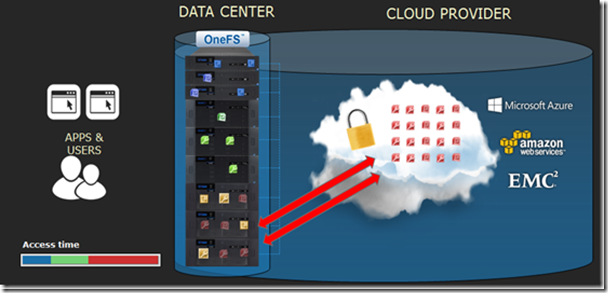
With CloudPools, you can use a single file system for working with cloud storage.
Cloud Storage Security
Suppose you set up a policy that sets requirements for files that need to be moved to the cloud. For example, you need to move:
- Files larger than 5 MB -> And
- Files located in the / ifs / data / stefan folder -> and
- Files that have not been requested for more than three months.
The policy will apply according to the schedule of Smartpools tasks. As is the case with all other tasks in OneFS, the planning and control of execution are carried out by the job engine. Tasks can be assigned priority and execution time, and depending on the current situation they can be paused.
As soon as Smartpools is launched (for example, every day at 10:00 pm), it checks all folders and files with current policies, and moves those who match the criteria to the cloud to the current policies.
The local file system stores stub files containing three types of information:
- File meta data (creation time, last access time, size, etc.)
- "Link" to data in the cloud.
- Part of the source cached data.
As already mentioned, from the point of view of a user or application, there is no difference between a “normal” file and a stub file. Of course, if you wish, you can calculate, but we'll talk about this another time.
Calling files from the cloud pool and local cache
When a file is accessed, the corresponding content is extracted from the cloud and cached locally, on an SSD or HDD. But this data will not be stored in the file system forever. Otherwise, any user could have hammered the entire local file system with viewing commands alone, because the storage capacity can be several times larger than the size of the local file system. Therefore, only an administrator or a user with the appropriate privileges can assign a persistent cache attribute to some data. The behavior of the cache itself can be adjusted using the CloudPools settings. For example, you can tell the cluster to:
- Cached or not cached locally called data.
- I used Cache Read Ahead mechanisms only for data that is allowed access, or for full files.
- Stored data in the cache for a certain time (from a second to years).
- With a certain frequency made a delayed write to the cache (that is, how often the cluster should write data modified in the local cache to the cloud).
Shelf life
The retention period is how long the archived data will be stored in the cloud after the stub file is deleted. This parameter can be configured separately for each policy. By default, the retention period is one week, after which the relevant data is deleted. In addition, you can configure:
- The retention period for incremental NDMP backup and SyncIQ. This parameter determines how long data will be stored in the cloud after synchronization with another storage using SyncIQ, or after a backup performed as part of an incremental NDMP task. By default, the shelf life in this case is 5 years. That is, after deleting the local file, the stub can be restored using NDMP or SyncIQ, while the data will be available for the specified period.
- Retention period for full NDMP backup. All the same as in the previous case, only for full NDMP backups.
Conclusion
CloudPools is a handy tool that allows you to create a transparent, multi-level storage from a horizontally scalable Isilon NAS system. Currently, two third-party cloud services and two external systems (Isilon, ECS) are supported. Surely the list of supported services and systems will be significantly expanded. From the client’s point of view, data movement is transparent and security is provided through encryption using AES-256. In other words, using CloudPools, you can implement a scalable multiprotocol system with a short response time, the growth limits of which are practically unlimited.
Outside this publication are a number of important issues. For example, performance: what will happen to the stub files during backup and replication? What about disaster recovery, access to data in CloudPools from different sites, the gradual creation of a CloudPools system? We will write about this in one of the following publications.
Source: https://habr.com/ru/post/305392/
All Articles