Our experience in creating applications on microservices in the field of advertising technologies
In August 2015, we launched a new adtech project, Atuko .
This is a mobile advertising management system designed for professionals.

At Atuko, we focused on managing one traffic channel — myTarget , the main Mail.ru advertising system, combining advertising on Odnoklassniki, VK mobile and some other Mail.ru resources, and covering> 90% of Runet’s audience. And of course, advertisers need tools to create campaigns, analyze results and manage.
We want to tell you exactly how we approached the creation of these tools and the system architecture.
')
For our team this is not the first project in the field of advertising technologies. We have been developing advertising management systems since 2009, creating tools for Yandex.Direct, Google Adwords, Google Analytics, VK, Target@mail.ru and other channels. They even caught Begun and the times when he was relevant :)

During this time we faced a lot of pitfalls and surprises associated with the feature of advertising sites, their API, and the unusual tasks of the advertisers themselves - and managed to gain a lot of experience! To tell about everything in one article will not work, so if there is interest, we will write a series of articles in which I will try to share the knowledge gained.
In this article, I want to tell the key things about the Atuko architecture and infrastructure - and why we did it this way, and not otherwise.
From our past experience, we have, among other things, learned the following important lessons:
Now I will tell how we tried to foresee these moments in the Atuko architecture.
The general scheme of the project can be represented as:

First of all, we decided to build everything on microservices. Each microservice provides the HTTP API and can be implemented on any technology stack. This gives us the opportunity to scale each service imperceptibly to others, since the HTTP API can hide either one copy of the service or the whole cluster with its balancer.
In addition, each microservice is simple enough so that it can be understood without complete immersion into the project as a whole, which simplifies development, and in extreme cases - rewrite the service from scratch in a relatively short period of time.
Thus, we also gain independence from the technologies used, and even if the microservice framework is outdated, we can transfer the microservice to a new technology. And of course, we can use another programming language if we realize that this problem is solved better on it.
One of the common questions that arise when using microservices is how to divide the functionality into microservices. For ourselves, we decided that we allocate some functional unit into separate microservices, which does not make sense to divide into smaller parts.
Let me give an example: Atuko has the opportunity to create a large number of advertising campaigns and announcements on the advertising platform by downloading a specially crafted Excel file. In addition to the interface, three microservices are involved in this process:
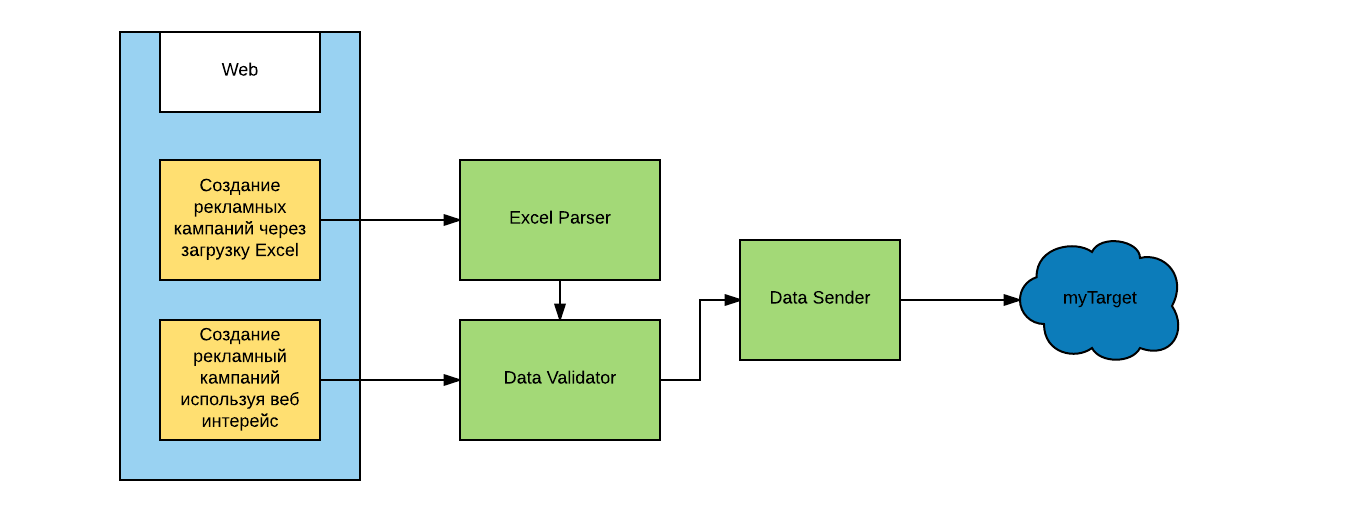
At the same time, the last two services - checking the correctness of data and sending data to the advertising platform - are also used in other Atuko work scenarios (for example, ads can be created not only through Excel, but also through a browser). At the same time, services do not care where they get data from - they just do their job and pass the result on.
But with the division into microservices come new problems. In particular, debugging becomes more difficult, because several services are involved in one action and it becomes more difficult to find the culprit.
Testing is also changing somewhat and the importance of integration testing is greatly increasing, since “In vacuum” services can work, but together they have to fail.
In the design also appear additional requirements. In particular, it is necessary to ensure that the result of the service really went further. And, of course, well-built monitoring is very important. However, any of these points is a topic for at least a separate article, or even a whole book.
Understanding that the number of microservices will grow very quickly, we saw the potential problem of communication between services. If services communicate directly with each other, it will be difficult to get a complete picture of their interaction, and this will lead to problems in the future modification of services. To reduce their connectivity, we decided to introduce a central microservice responsible for communicating the rest - the dispatcher.
Each microservice, by the results of its work, sends an event to the dispatcher with the results, and the dispatcher, in turn, sends the event to the subscribing services. Thus, each microservice does not need knowledge of the external environment. Instead, it is enough for him to subscribe to certain events in the dispatcher, and based on the results of the work, send events to the same dispatcher.
Introduction of the dispatcher solves one of our other tasks - the creation of customized functionality for a specific client. This is possible due to the introduction of units - each unit is a combination of the dispatcher and microservices working with it.
Consider the case when one of the clients needs to download conversions from their own CRM system in a unique format that requires unique processing.
This task can be solved if different users will “serve” different microservices. We run 2 units: each of them has its own dispatcher, and its own set of services. In this case, in one of the units, the services operate in the usual way, while in the other they are replaced by services that process conversions from the client's CRM.
However, some things will never be duplicated in different units - for example, interaction with external systems. In the case of Atuko, for example, there are limits on the use of the myTarget API - and therefore external communication goes through one microservice that controls the frequency of requests.
By the way, inside the unit we can change not only the work of individual services, but also the number of services - for example, adding new steps to the data processing or verification procedure.
By launching additional units, we also simplify scaling across servers, and maintenance is greatly simplified - instead of several copies of the system, only individual elements are duplicated.

Of course, with this approach there are some nuances. For example, the dispatcher will be a very busy service that handles all communication between system nodes. You also need to immediately take into account that not all events are equivalent, and you need to handle different events with different priorities - otherwise many irrelevant events can slow down the processing of others that require immediate response. For example, if a user sent a command to stop a campaign, then this task should be performed immediately, but background statistics update can wait.

In general, the approach described above allowed us to prepare for possible difficulties. But another task arose, connected not so much with the development process as with the operation process. How to manage all this economy? Each microservice can be implemented using any technology, on any framework, and have its own dependencies on different libraries. For example, at the moment we have microservices both on golang, and on python, and on php.
And to solve this problem, we use Docker . A docker image (image) is created on the basis of each microservice, on the basis of which an unlimited number of services can already be launched. At the same time, they can be located on different machines, which also simplifies scaling.
All calls go through reverse proxy. This makes it possible to simply add the necessary entry to the desired upstream when lifting another container with the service, and reverse proxy will distribute the traffic itself.
We now use nginx as a reverse proxy - but we continue to consider other options.
In addition, for deployment, we use the Blue-Green Deployment technique - this means that services can work simultaneously with both new and old functionality. And in this case, the reverse proxy again helps, providing the opportunity to distribute traffic in the right proportions between the two versions, and finally move to a new one, just making sure that it is fully operational.
When we started development, Docker didn’t have enough advanced networking capabilities. At the same time, we wanted convenient access to microservices, the inaccessibility of the backend from the outside, and the removal of each unit in its subnet.
Therefore, we resolved this issue on our own by raising our internal DNS. Now a call to a specific service occurs simply by its name and the name of the unit. At the moment, we continue to use DNS, but at the same time we are considering other options, which now appear more and more.
This, by the way, is another plus of microservice architectures - it is quite easy to implement new tools that can make our lives easier, speed up the release of new functionality, or increase reliability. It also ensures that we will not have legacy code problems - outdated services can be replaced quite easily with their current versions.
I want to say about the results of applying this approach.
After a year of working with such an architecture, we are still satisfied with the chosen approach using microservices. Despite the difficulties that we faced, and new problems that weren't there before, the approach as a whole justified itself and solved the tasks.
And of course, Docker’s life is much easier for us - for us this is a great tool for packaging and delivery. I can safely recommend it to everyone. And combining an approach based on microservices with Docker provides a number of advantages in development, testing, and even more so in operation.
Observing the rapid growth in the number of articles, reports and videos on the subject of microservices and Docker, I understand that we made the right choice in due time — at least at that moment it seemed like a new and untested approach. Therefore, I recommend everyone who starts a new project or wants to modify the old one, to think about using microservices, Docker and dividing into units.
If we are interested, we are ready to continue to share the knowledge that we have acquired during this time: about golang microservices, monitoring and testing, an interface based on ReactJS + Flux and much more.
This is a mobile advertising management system designed for professionals.
At Atuko, we focused on managing one traffic channel — myTarget , the main Mail.ru advertising system, combining advertising on Odnoklassniki, VK mobile and some other Mail.ru resources, and covering> 90% of Runet’s audience. And of course, advertisers need tools to create campaigns, analyze results and manage.
We want to tell you exactly how we approached the creation of these tools and the system architecture.
')
For our team this is not the first project in the field of advertising technologies. We have been developing advertising management systems since 2009, creating tools for Yandex.Direct, Google Adwords, Google Analytics, VK, Target@mail.ru and other channels. They even caught Begun and the times when he was relevant :)
During this time we faced a lot of pitfalls and surprises associated with the feature of advertising sites, their API, and the unusual tasks of the advertisers themselves - and managed to gain a lot of experience! To tell about everything in one article will not work, so if there is interest, we will write a series of articles in which I will try to share the knowledge gained.
In this article, I want to tell the key things about the Atuko architecture and infrastructure - and why we did it this way, and not otherwise.
Past experience and important lessons
From our past experience, we have, among other things, learned the following important lessons:
- You need flexible scaling in all nodes of the system. It is impossible to predict in advance which part of the system the load will grow: analysis, creation, viewing, etc.
I will give a small example. When managing contextual advertising (Yandex.Direct and Google AdWords), everything went well at first, growth was smooth. At some point, a truly large client appears - and for the implementation of its tasks, 9 million keywords are required to be managed - and this is many times more than other clients combined. Some parts of the system (for example, receiving conversions from Google Analytics) quietly coped with the increase in load, but others (for example, obtaining statistics on all keywords) required strong optimization. And the most unpleasant thing is that the volumes of this client affected the work of the entire system as a whole - and, accordingly, on other clients.
This taught us the isolation and flexibility of individual parts of the system, and the ability to isolate customers from each other. - Necessary to configure the functionality for a specific client.
Often, individual clients have their own unique requirements, and it is sometimes difficult or impossible to combine the tasks of different clients in one universal solution - and customization of the functionality for a particular client is a more effective solution. In this case, of course, this customization should not affect other users.
Thus, we need the ability to run the modified functionality for individual clients, and at the same time - not to raise a separate copy of the entire system for each client. - Minimizing the dependency on frameworks and programming languages.
For example, one of the projects created by us exists longer than the framework on which it is built - the support and development of the framework have stopped. In addition, the assignment of the entire project to one programming language reduces efficiency - there is no possibility to use the optimal language for each task, and there is no possibility to use new programming languages.
Now I will tell how we tried to foresee these moments in the Atuko architecture.
The general scheme of the project can be represented as:
Microservices
First of all, we decided to build everything on microservices. Each microservice provides the HTTP API and can be implemented on any technology stack. This gives us the opportunity to scale each service imperceptibly to others, since the HTTP API can hide either one copy of the service or the whole cluster with its balancer.
In addition, each microservice is simple enough so that it can be understood without complete immersion into the project as a whole, which simplifies development, and in extreme cases - rewrite the service from scratch in a relatively short period of time.
Thus, we also gain independence from the technologies used, and even if the microservice framework is outdated, we can transfer the microservice to a new technology. And of course, we can use another programming language if we realize that this problem is solved better on it.
One of the common questions that arise when using microservices is how to divide the functionality into microservices. For ourselves, we decided that we allocate some functional unit into separate microservices, which does not make sense to divide into smaller parts.
Let me give an example: Atuko has the opportunity to create a large number of advertising campaigns and announcements on the advertising platform by downloading a specially crafted Excel file. In addition to the interface, three microservices are involved in this process:
- parsing an Excel file and creating a dataset for loading into myTarget
- checking the data set for compliance with the rules of the advertising platform
- send data to myTarget
At the same time, the last two services - checking the correctness of data and sending data to the advertising platform - are also used in other Atuko work scenarios (for example, ads can be created not only through Excel, but also through a browser). At the same time, services do not care where they get data from - they just do their job and pass the result on.
But with the division into microservices come new problems. In particular, debugging becomes more difficult, because several services are involved in one action and it becomes more difficult to find the culprit.
Testing is also changing somewhat and the importance of integration testing is greatly increasing, since “In vacuum” services can work, but together they have to fail.
In the design also appear additional requirements. In particular, it is necessary to ensure that the result of the service really went further. And, of course, well-built monitoring is very important. However, any of these points is a topic for at least a separate article, or even a whole book.
Dispatcher
Understanding that the number of microservices will grow very quickly, we saw the potential problem of communication between services. If services communicate directly with each other, it will be difficult to get a complete picture of their interaction, and this will lead to problems in the future modification of services. To reduce their connectivity, we decided to introduce a central microservice responsible for communicating the rest - the dispatcher.
Each microservice, by the results of its work, sends an event to the dispatcher with the results, and the dispatcher, in turn, sends the event to the subscribing services. Thus, each microservice does not need knowledge of the external environment. Instead, it is enough for him to subscribe to certain events in the dispatcher, and based on the results of the work, send events to the same dispatcher.
Units
Introduction of the dispatcher solves one of our other tasks - the creation of customized functionality for a specific client. This is possible due to the introduction of units - each unit is a combination of the dispatcher and microservices working with it.
Consider the case when one of the clients needs to download conversions from their own CRM system in a unique format that requires unique processing.
This task can be solved if different users will “serve” different microservices. We run 2 units: each of them has its own dispatcher, and its own set of services. In this case, in one of the units, the services operate in the usual way, while in the other they are replaced by services that process conversions from the client's CRM.
However, some things will never be duplicated in different units - for example, interaction with external systems. In the case of Atuko, for example, there are limits on the use of the myTarget API - and therefore external communication goes through one microservice that controls the frequency of requests.
By the way, inside the unit we can change not only the work of individual services, but also the number of services - for example, adding new steps to the data processing or verification procedure.
By launching additional units, we also simplify scaling across servers, and maintenance is greatly simplified - instead of several copies of the system, only individual elements are duplicated.
Of course, with this approach there are some nuances. For example, the dispatcher will be a very busy service that handles all communication between system nodes. You also need to immediately take into account that not all events are equivalent, and you need to handle different events with different priorities - otherwise many irrelevant events can slow down the processing of others that require immediate response. For example, if a user sent a command to stop a campaign, then this task should be performed immediately, but background statistics update can wait.
Docker
In general, the approach described above allowed us to prepare for possible difficulties. But another task arose, connected not so much with the development process as with the operation process. How to manage all this economy? Each microservice can be implemented using any technology, on any framework, and have its own dependencies on different libraries. For example, at the moment we have microservices both on golang, and on python, and on php.
And to solve this problem, we use Docker . A docker image (image) is created on the basis of each microservice, on the basis of which an unlimited number of services can already be launched. At the same time, they can be located on different machines, which also simplifies scaling.
Reverse proxy
All calls go through reverse proxy. This makes it possible to simply add the necessary entry to the desired upstream when lifting another container with the service, and reverse proxy will distribute the traffic itself.
We now use nginx as a reverse proxy - but we continue to consider other options.
In addition, for deployment, we use the Blue-Green Deployment technique - this means that services can work simultaneously with both new and old functionality. And in this case, the reverse proxy again helps, providing the opportunity to distribute traffic in the right proportions between the two versions, and finally move to a new one, just making sure that it is fully operational.
DNS
When we started development, Docker didn’t have enough advanced networking capabilities. At the same time, we wanted convenient access to microservices, the inaccessibility of the backend from the outside, and the removal of each unit in its subnet.
Therefore, we resolved this issue on our own by raising our internal DNS. Now a call to a specific service occurs simply by its name and the name of the unit. At the moment, we continue to use DNS, but at the same time we are considering other options, which now appear more and more.
This, by the way, is another plus of microservice architectures - it is quite easy to implement new tools that can make our lives easier, speed up the release of new functionality, or increase reliability. It also ensures that we will not have legacy code problems - outdated services can be replaced quite easily with their current versions.
Conclusion
I want to say about the results of applying this approach.
After a year of working with such an architecture, we are still satisfied with the chosen approach using microservices. Despite the difficulties that we faced, and new problems that weren't there before, the approach as a whole justified itself and solved the tasks.
And of course, Docker’s life is much easier for us - for us this is a great tool for packaging and delivery. I can safely recommend it to everyone. And combining an approach based on microservices with Docker provides a number of advantages in development, testing, and even more so in operation.
Observing the rapid growth in the number of articles, reports and videos on the subject of microservices and Docker, I understand that we made the right choice in due time — at least at that moment it seemed like a new and untested approach. Therefore, I recommend everyone who starts a new project or wants to modify the old one, to think about using microservices, Docker and dividing into units.
If we are interested, we are ready to continue to share the knowledge that we have acquired during this time: about golang microservices, monitoring and testing, an interface based on ReactJS + Flux and much more.
Source: https://habr.com/ru/post/305272/
All Articles