Accelerate stencil computing: building and running YASK on Intel processors
Stencil computing is widely used in scientific and technical applications. They are used to solve differential equations by the method of finite differences, in problems of computational mechanics.
High performance computing (HPC, High Performance Computing), whether it's about a supercomputer, or a system built on one or two multi-core processors, is parallel computing. If the algorithm can be broken down into blocks that can be processed at the same time, this means that it can be effectively executed in a parallel environment. But not only this is important: do not forget about code optimization, which takes into account, among other things, the peculiarities of working with data at the level of individual types of memory available to processors. In particular, we are talking about efficient work with cache memory.

')
Other things being equal, the parallelized algorithm that best takes into account the peculiarities of the cache memory will work faster than others. And, of course, if we talk about computing speed, then the code that most fully utilizes the capabilities of a particular platform, at the level of instructions and processor architecture, will benefit. There are specialized software packages for the preparation of such code. One of them is YASK.
YASK , or Yet Another Stencil Kernel is a set of tools for developing applications using stencil computing, designed to facilitate the research and design of HPC computational cores and their optimization. YASK uses such techniques as vector folding, splitting cycles into blocks to increase the efficiency of using cache memory, controlling data placement in memory, adjusting the structure of cycles, temporal splitting calculations into blocks of waves, and others.
YASK contains a specialized translator that converts a regular C ++ stencil program into SIMD-optimized code.
Here we talk about configuring the cores for Intel Xeon Phi and Intel Xeon processors. Namely, this setting can make the code on Xeon Phi work up to 2.8 times faster than on Intel Xeon.
The performance advantages of Intel Xeon Phi can be attributed to the higher bandwidth of its memory subsystem and 512-bit SIMD instructions.
A very important area of high performance computing is the use of stencil computing for working with temporal and spatial data values. For example, the core of a typical three-dimensional iterative Jacobi stencil algorithm can be shown in the following pseudocode, which bypasses points in the three-dimensional grid:
Here T is the number of steps in the time parameter, Dx, Dy, and Dz are the dimensions of the problem space and S (t, i, j, k) is the stencil function.
In the case of very simple one-dimensional and two-dimensional stencil computations, modern compilers are often able to recognize data access patterns and optimize the generated code so that it can take advantage of the features of vector registers, take into account the length of cache lines. But, for more complex computations that are planned to be performed on modern processors equipped with several cores using common memory, most compilers cannot cope with the task of producing optimal code.
YASK is a tool that allows a programmer to experiment with various ways of distributing data in memory, including convolving vectors and optimizing loop structures, which can lead to more productive code than the one obtained after normal compiler optimizations. Currently, YASK focuses on optimization within a single OpenMP compute node.
This is what a typical YASK model looks like.
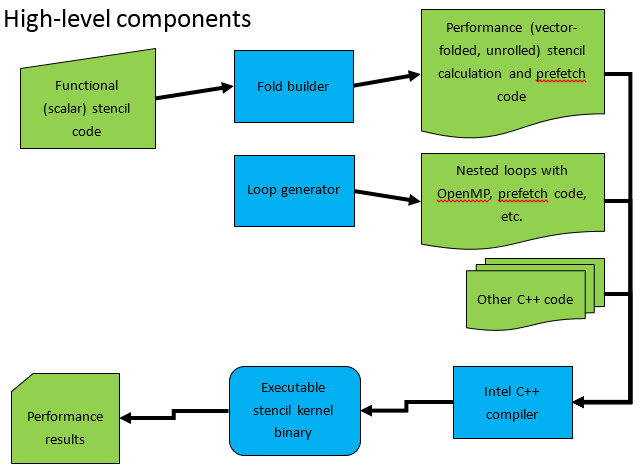
High-level model of work with YASK
A complete guide to working with YASK can be found on the YASK website . Here we look at building and running YASK tasks on Intel Xeon Phi and Intel Xeon, but first we’ll talk about some of the optimization techniques used in this toolkit.
Multidimensional vectorization, or vector folding, is the process of filling vector registers with data blocks, and the blocks are not necessarily arranged in the order in which they follow in the source data. This is needed to optimize data reuse and cache contents. Here is a material from which you can find out details about multidimensional vectorization and its application in stencil calculations. Manual convolution of vectors is a complex task, fraught with errors. YASK, on the other hand, offers a software tool for converting standard code, which provides for sequential execution of operations, into a new code, which, after compilation, allows for faster and more efficient calculations.
In combination with vector convolution, using multiple threads to execute loops provides an additional increase in computation performance. YASK, allowing the programmer to experiment with the structure of the loop using OpenMP tools, provides another way to optimize the code: optimization of loops.
There are three main approaches to setting cycles:
Here we look at two examples of assembling and running YASK cores on Intel Xeon and Intel Xeon Phi processors.
The system on Intel Xeon uses a dual socket Intel Xeon E5-2697 v4 2.3 GHz processor with Turbo mode enabled. There are 18 cores per one socket, in total there are 36 cores in the system (72 threads, HT mode is enabled). The test platform is equipped with 128 GB DDR4 memory (2400 MHz), it is running Red Hat Enterprise Linux Server 7.2.
The system on Intel Xeon Phi uses an Intel Xeon Phi 7250 processor (68 cores, 272 threads). The core frequency is 1,400 MHz, the frequency of the processor's auxiliary systems is 1,700 MHz. There is 16 GB MCDRAM, 7.2 Gt / s (Flat mode is used). The system has 96 GB DDR4 memory (2400 MHz), using quad cluster mode. The BIOS version is 86B.0010.R00, the installed OS is Red Hat Enterprise Linux Server 6.7.
The code, instructions for building and running which we consider below, can be downloaded from here .
One of the computational stencil cores included in YASK is awp-odc . It uses a grid with a double system of nodes, the kernel implements the finite-difference method used for the approximate solution of three-dimensional dynamic equations of the theory of elasticity. Applications that use this core simulate the effect of earthquakes, which helps to design structures at risk. The task space consists of 1024 * 384 * 768 grid nodes. Using an Intel Xeon Phi 7250 processor to solve this problem gives an increase in performance up to 2.8 times compared to the Intel Xeon E5-2697 v4 processor.
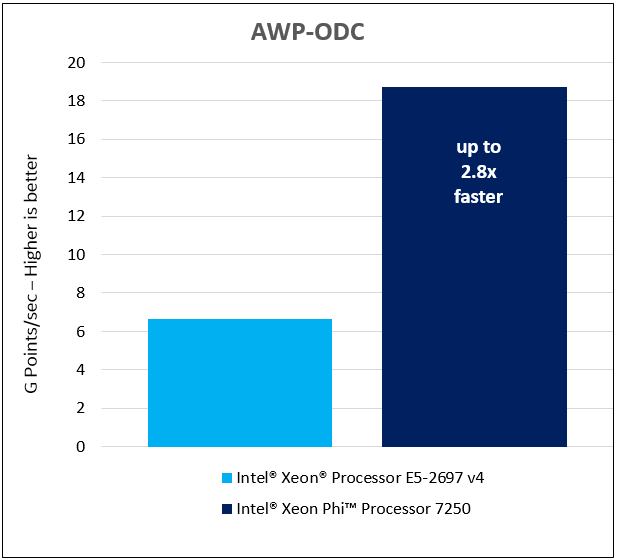
Test results on the AWP-ODC task
This is how this test was conducted.
On the Intel Xeon system, the following commands must be executed:
On an Intel Xeon Phi system, this is done like this:
Another stencil core included in YASK is iso3dfd. It is engaged in solving an acoustic isotropic wave equation of the 16th order of discretization in space and the 2nd order of discretization in time. Such calculations are used in seismic imaging applications used by seismic companies when searching for oil and gas fields. The task space consists of 1536 * 1024 * 768 grid nodes. The use of the Intel Xeon Phi 7250 processor in this task can improve performance by up to 2.6 times compared to the Intel Xeon E5-2697 v4.

Test results on the ISO3DFD task
Here is how we performed this test.
The system based on Intel Xeon uses the following commands:
On a platform equipped with Intel Xeon Phi , the following command sequence is used:
High performance computing is an area where the best results can be achieved by combining several factors. Among them - the correct selection of algorithms, their optimization, the use of powerful modern platforms for carrying out calculations.
The YASK toolkit and the Intel Xeon Phi 7250 processor are capable of giving science and business everything they need to quickly solve complex practical problems.
High performance computing (HPC, High Performance Computing), whether it's about a supercomputer, or a system built on one or two multi-core processors, is parallel computing. If the algorithm can be broken down into blocks that can be processed at the same time, this means that it can be effectively executed in a parallel environment. But not only this is important: do not forget about code optimization, which takes into account, among other things, the peculiarities of working with data at the level of individual types of memory available to processors. In particular, we are talking about efficient work with cache memory.
')
Other things being equal, the parallelized algorithm that best takes into account the peculiarities of the cache memory will work faster than others. And, of course, if we talk about computing speed, then the code that most fully utilizes the capabilities of a particular platform, at the level of instructions and processor architecture, will benefit. There are specialized software packages for the preparation of such code. One of them is YASK.
What is YASK
YASK , or Yet Another Stencil Kernel is a set of tools for developing applications using stencil computing, designed to facilitate the research and design of HPC computational cores and their optimization. YASK uses such techniques as vector folding, splitting cycles into blocks to increase the efficiency of using cache memory, controlling data placement in memory, adjusting the structure of cycles, temporal splitting calculations into blocks of waves, and others.
YASK contains a specialized translator that converts a regular C ++ stencil program into SIMD-optimized code.
Here we talk about configuring the cores for Intel Xeon Phi and Intel Xeon processors. Namely, this setting can make the code on Xeon Phi work up to 2.8 times faster than on Intel Xeon.
The performance advantages of Intel Xeon Phi can be attributed to the higher bandwidth of its memory subsystem and 512-bit SIMD instructions.
About stencil computing
A very important area of high performance computing is the use of stencil computing for working with temporal and spatial data values. For example, the core of a typical three-dimensional iterative Jacobi stencil algorithm can be shown in the following pseudocode, which bypasses points in the three-dimensional grid:
for t = 1 to T do for i = 1 to Dx do for j = 1 to Dy do for k = 1 to Dz do u(t + 1, i, j, k) ← S(t, i, j, k) end for end for end for end for Here T is the number of steps in the time parameter, Dx, Dy, and Dz are the dimensions of the problem space and S (t, i, j, k) is the stencil function.
In the case of very simple one-dimensional and two-dimensional stencil computations, modern compilers are often able to recognize data access patterns and optimize the generated code so that it can take advantage of the features of vector registers, take into account the length of cache lines. But, for more complex computations that are planned to be performed on modern processors equipped with several cores using common memory, most compilers cannot cope with the task of producing optimal code.
YASK is a tool that allows a programmer to experiment with various ways of distributing data in memory, including convolving vectors and optimizing loop structures, which can lead to more productive code than the one obtained after normal compiler optimizations. Currently, YASK focuses on optimization within a single OpenMP compute node.
This is what a typical YASK model looks like.
High-level model of work with YASK
Beginning of work
A complete guide to working with YASK can be found on the YASK website . Here we look at building and running YASK tasks on Intel Xeon Phi and Intel Xeon, but first we’ll talk about some of the optimization techniques used in this toolkit.
Multidimensional vectorization
Multidimensional vectorization, or vector folding, is the process of filling vector registers with data blocks, and the blocks are not necessarily arranged in the order in which they follow in the source data. This is needed to optimize data reuse and cache contents. Here is a material from which you can find out details about multidimensional vectorization and its application in stencil calculations. Manual convolution of vectors is a complex task, fraught with errors. YASK, on the other hand, offers a software tool for converting standard code, which provides for sequential execution of operations, into a new code, which, after compilation, allows for faster and more efficient calculations.
Fine-tuning the structure of cycles
In combination with vector convolution, using multiple threads to execute loops provides an additional increase in computation performance. YASK, allowing the programmer to experiment with the structure of the loop using OpenMP tools, provides another way to optimize the code: optimization of loops.
There are three main approaches to setting cycles:
- “Rank” - the task is divided into OpenMP areas.
- “Region” - OpenMP domains are divided into cache blocks.
- “Block” - a passage is made for each vector cluster in the cache block.
Computation Performance Study
Here we look at two examples of assembling and running YASK cores on Intel Xeon and Intel Xeon Phi processors.
The system on Intel Xeon uses a dual socket Intel Xeon E5-2697 v4 2.3 GHz processor with Turbo mode enabled. There are 18 cores per one socket, in total there are 36 cores in the system (72 threads, HT mode is enabled). The test platform is equipped with 128 GB DDR4 memory (2400 MHz), it is running Red Hat Enterprise Linux Server 7.2.
The system on Intel Xeon Phi uses an Intel Xeon Phi 7250 processor (68 cores, 272 threads). The core frequency is 1,400 MHz, the frequency of the processor's auxiliary systems is 1,700 MHz. There is 16 GB MCDRAM, 7.2 Gt / s (Flat mode is used). The system has 96 GB DDR4 memory (2400 MHz), using quad cluster mode. The BIOS version is 86B.0010.R00, the installed OS is Red Hat Enterprise Linux Server 6.7.
The code, instructions for building and running which we consider below, can be downloaded from here .
AWP-ODC Task
One of the computational stencil cores included in YASK is awp-odc . It uses a grid with a double system of nodes, the kernel implements the finite-difference method used for the approximate solution of three-dimensional dynamic equations of the theory of elasticity. Applications that use this core simulate the effect of earthquakes, which helps to design structures at risk. The task space consists of 1024 * 384 * 768 grid nodes. Using an Intel Xeon Phi 7250 processor to solve this problem gives an increase in performance up to 2.8 times compared to the Intel Xeon E5-2697 v4 processor.
Test results on the AWP-ODC task
This is how this test was conducted.
On the Intel Xeon system, the following commands must be executed:
make stencil=awp arch=hsw cluster=x=2,y=2,z=2 fold=y=8 omp_schedule=guided mpi=1 ./stencil-run.sh -arch hsw -ranks 2 -bx 74 -by 192 -bz 20 -pz 2 -dx 512 -dy 384 -dz 768 On an Intel Xeon Phi system, this is done like this:
make stencil=awp arch=knl INNER_BLOCK_LOOP_OPTS='prefetch(L1,L2)' ./stencil-run.sh -arch knl -bx 128 -by 32 -bz 32 -dx 1024 -dy 384 -dz 768 ISO3DFD task
Another stencil core included in YASK is iso3dfd. It is engaged in solving an acoustic isotropic wave equation of the 16th order of discretization in space and the 2nd order of discretization in time. Such calculations are used in seismic imaging applications used by seismic companies when searching for oil and gas fields. The task space consists of 1536 * 1024 * 768 grid nodes. The use of the Intel Xeon Phi 7250 processor in this task can improve performance by up to 2.6 times compared to the Intel Xeon E5-2697 v4.
Test results on the ISO3DFD task
Here is how we performed this test.
The system based on Intel Xeon uses the following commands:
make stencil=iso3dfd arch=hsw mpi=1 ./stencil-run.sh -arch hsw -ranks 2 -bx 256 -by 64 -bz 64 -dx 768 -dy 1024 -dz 768 On a platform equipped with Intel Xeon Phi , the following command sequence is used:
make stencil=iso3dfd arch=knl ./stencil-run.sh -arch knl -bx 192 -by 96 -bz 96 -dx 1536 -dy 1024 -dz 768 Results
High performance computing is an area where the best results can be achieved by combining several factors. Among them - the correct selection of algorithms, their optimization, the use of powerful modern platforms for carrying out calculations.
The YASK toolkit and the Intel Xeon Phi 7250 processor are capable of giving science and business everything they need to quickly solve complex practical problems.
Source: https://habr.com/ru/post/305128/
All Articles