To the birthday of the Dalai Lama
Yesterday, I was walking around the city and suddenly wondered how you can implement the dividing of a string by characters using JavaScript with a regular expression and with full Unicode.
After moving from Perl to JavaScript many years ago, I still experienced some inferiority complex for my new language due to insufficient Unicode support. For all the time while JavaScript made its big leap in this direction (when moving from ES5 to ES6), I have some good articles left in my bookmarks.
Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!)
Javascript has a unicode problem
Unicode-aware regular expressions in ECMAScript 6
ES6 Strings (and Unicode) in Depth
')
The last of them offered a recipe for breaking a string into characters, taking into account Unicode with the help of a new operator

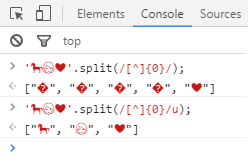
And yesterday I wondered whether it was possible to implement the same with the help of new regular expressions. A simple idea came to mind that turned out to be true:
Today I suddenly realized that yesterday was the birthday of the Dalai Lama. Therefore, it seemed to me that this note can be completed with a little jokes on JavaScript in honor of the hero of the occasion.

PS I tried to compare both methods in speed:
Node.js 6.3.0
Google Chrome Canary 54.0.2790.0
Firefox Nightly 50.0a1
In V8, the regular expression wins (twice as fast or more), in SpiderMonkey, the spread operator wins (slightly).
PPS Instead of
After moving from Perl to JavaScript many years ago, I still experienced some inferiority complex for my new language due to insufficient Unicode support. For all the time while JavaScript made its big leap in this direction (when moving from ES5 to ES6), I have some good articles left in my bookmarks.
Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!)
Javascript has a unicode problem
Unicode-aware regular expressions in ECMAScript 6
ES6 Strings (and Unicode) in Depth
')
The last of them offered a recipe for breaking a string into characters, taking into account Unicode with the help of a new operator
... For example (Habrovsky parser does not allow for some reason to enter this example with code, hiding characters above BMP):And yesterday I wondered whether it was possible to implement the same with the help of new regular expressions. A simple idea came to mind that turned out to be true:
Today I suddenly realized that yesterday was the birthday of the Dalai Lama. Therefore, it seemed to me that this note can be completed with a little jokes on JavaScript in honor of the hero of the occasion.
const nothingness = /[^]{0}/; const nothing = ''; console.log(nothing.search(nothingness)); // 0 console.log(nothing.match(nothingness)); // [ '', index: 0, input: '' ] console.log(nothing.split(nothingness)); // [] console.log(nothing.replace(nothingness, nothing)); // '' console.log(nothingness.test(nothing)); // true PS I tried to compare both methods in speed:
1. Node.js
/******************************************************************************/ 'use strict'; /******************************************************************************/ const str = '\ud83d\udc0e'.repeat(1000); const re = /[^]{0}/u; let symbols; let hrStart; let hrEnd; let i; /******************************************************************************/ hrStart = process.hrtime(); i = 100000; while (i-- > 0) symbols = [...str]; hrEnd = process.hrtime(hrStart); console.log( `${symbols.length} symbols via spread: ${(hrEnd[0] * 1e9 + hrEnd[1]) / 1e9} s` ); /******************************************************************************/ hrStart = process.hrtime(); i = 100000; while (i-- > 0) symbols = str.split(re); hrEnd = process.hrtime(hrStart); console.log( `${symbols.length} symbols via regexp: ${(hrEnd[0] * 1e9 + hrEnd[1]) / 1e9} s` ); /******************************************************************************/ 2. Browsers
/******************************************************************************/ 'use strict'; /******************************************************************************/ const str = '\ud83d\udc0e'.repeat(1000); const re = /[^]{0}/u; let symbols; let pStart; let i; /******************************************************************************/ pStart = performance.now(); i = 100000; while (i-- > 0) symbols = [...str]; console.log( `${symbols.length} symbols via spread: ${(performance.now() - pStart) / 1e3} s` ); /******************************************************************************/ pStart = performance.now(); i = 100000; while (i-- > 0) symbols = str.split(re); console.log( `${symbols.length} symbols via regexp: ${(performance.now() - pStart) / 1e3} s` ); /******************************************************************************/ Node.js 6.3.0
1000 symbols via spread: 28.284130503 s
1000 symbols via regexp: 14.887705856 sGoogle Chrome Canary 54.0.2790.0
1000 symbols via spread: 36.575210000000006 s
1000 symbols via regexp: 15.550919999999998 sFirefox Nightly 50.0a1
1000 symbols via spread: 20.392635000000002 s
1000 symbols via regexp: 26.935885000000003 sIn V8, the regular expression wins (twice as fast or more), in SpiderMonkey, the spread operator wins (slightly).
PPS Instead of
/[^]{0}/u you can use new RegExp('', 'u')Source: https://habr.com/ru/post/305096/
All Articles