We are looking for vulnerabilities in code: theory, practice and prospects of SAST
 It would not be a big exaggeration to say that the market of static application protection testing tools (Static Application Security Testing, SAST) is experiencing a real boom in our time. Not a couple of months pass between the publication of the next research papers on this topic, every year more and more new static security analysis tools are brought to the market, and the SAST site in the software development process is assigned whole sections at international information security conferences. In the context of continuous informational pressure from the suppliers of the SAST toolkit, it is not easy to understand what is true and what is nothing more than marketing tricks that hardly correlate with reality. Let's try to understand what SAST tools really can do and how to deal with the fact that they are too tough. To do this, we will have to dive a bit into the theory that underlies the modern means of static code security analysis.
It would not be a big exaggeration to say that the market of static application protection testing tools (Static Application Security Testing, SAST) is experiencing a real boom in our time. Not a couple of months pass between the publication of the next research papers on this topic, every year more and more new static security analysis tools are brought to the market, and the SAST site in the software development process is assigned whole sections at international information security conferences. In the context of continuous informational pressure from the suppliers of the SAST toolkit, it is not easy to understand what is true and what is nothing more than marketing tricks that hardly correlate with reality. Let's try to understand what SAST tools really can do and how to deal with the fact that they are too tough. To do this, we will have to dive a bit into the theory that underlies the modern means of static code security analysis.Turing, Rice - these are all
TL / DR: the problem of static software security testing is algorithmically unsolvable.
')
Imagine a set of completely abstract programs P, which only know how to hang on some sets of input data and stop after a certain number of operations on others. Obviously, the class P covers any theoretically possible programs, since this property can be attributed to any of them.
Now imagine that one of these programs (let's call it h) is an analyzer that can answer a simple question: does an arbitrary program p from the set P hang on a given data set n? Obviously, h will be able to answer this question only by completing its work and thereby reporting that p hangs on n. In other words, if p (n) does not stop, then h (p (n)) should complete its work in a finite number of steps, and if p (n) stops, then h (p (n)) should hang.
Well, now imagine what will happen if we try to answer with the help of such an analyzer the question: will it hang itself as a result of the analysis of itself analyzing itself (after all, p can be any program from P, then it can also be h) In this case, it turns out that if h (h (n)) stops, then the analysis h (n) hangs, and if h (h (n))) hangs, then the analysis h (n) stops. But h is precisely h (n), and, therefore, we have a contradiction here and an analyzer like h has no right to exist.
Described is a free presentation of the proof of the Break Theorem, formulated by Allan Turing (the founder of modern theoretical informatics) in the distant 1936th. This theorem states that there is no such program that could analyze another program and answer the question whether it will stop at a given set of input data. Well, but can we build such a program that gives an answer to the question about any other properties of the programs?
Since the set P includes all possible programs, we can always divide it into two classes (let it be A and B) on the basis of the fact that programs have any non-trivial invariant property. By a non-trivial invariant property is meant a property that any program of the set P either has or does not have and at the same time all functionally identical programs (which give the same output data sets with the same input data sets), or all have this property, or all together do not possess.
Let's imagine that there is some analyzer q that takes an arbitrary program p of the set P as input and stops if p belongs to one of the classes. Let, for definiteness, this will be class A. Let pa be a program belonging to class A and looping at any input. We also choose from the class B an arbitrary program pb. For each program p, we define a program p ', which receives the x data and performs the following algorithm:
1. p(p) 2. pb(x) Now we will build a program q ', which receives an arbitrary program p as an input, builds p' for it and calculates q (p ').
If p 'hangs in the first step, then p' is functionally identical to pa (and belongs to class A), and, therefore, q 'should stop immediately. If p 'passes the first step, then p' is functionally identical to pb (and belongs to the class B), and, therefore, q 'should hang. Thus, for any program p, q '(p) stops when p (p) does not stop. But q 'itself may also play the role of p, therefore p (p) stops only when p (p) does not stop. Again came to a contradiction.
The statement that there is no such program that could answer the question about the presence of any non-trivial invariant properties of an arbitrarily taken program was proved by the scientist Henry Rice in 1953. In fact, his work generalizes the Break Theorem, since the property of stopping on a given data set is nontrivial and invariant. Rice's theorem has an infinite number of practical meanings, depending on the properties under consideration: “it is impossible to classify the algorithm implemented by another program using the program”, “it is impossible to prove using the program that two other programs implement the same algorithm”, “it is impossible using programs to prove that another program on any data sets is not included in any state ... ", etc. And here it is worth stopping at the last example.
At the time of execution of any (both abstract and real) algorithm by some kind of universal executing program (for example, a virtual machine emulating a full-fledged computer with an installed OS), you can take a snapshot of this machine, including the state of the executable program itself in the address space of the machine and its external environment such as disk drives, the status of external devices, etc. and later, restoring it, continue with the program from the same place. In fact, the entire process of executing any program is a series of alternating states, the sequence of which is determined by its code. At the same time, if there are any errors in the configuration or implementation of both the program and the machine running it, there is a high probability that the execution process will enter a state that was not originally intended by the developers.
And what is the vulnerability? This is an opportunity with the help of input data to make the execution process enter into a state that will lead to the realization of any threats to the information processed by the process. Consequently, it is possible to define the security property of any program, as its ability to remain at each moment of time, regardless of the initial input data, within a predetermined set of admissible states determining its security policy. At the same time, the task of analyzing the security of a program obviously comes down to analyzing the impossibility of its transition to any state not resolved by the security policy on an arbitrary set of input data. That is, to the very problem, the algorithmic unsolvability of which was long ago proved by Henry Rice.
So it turns out, well ... the whole SAST tool market is the deception industry? In theory - yes, in practice, everything is as usual - options are possible.
SAST theory in practice
Even staying in the theoretical field, it is quite possible to do a few easing to Rice's statement for real programs running in real environments. First, in theoretical informatics, a “program” means a mathematical abstraction equivalent to a Turing machine (MT) —the most powerful computer machine. However, in real programs, not every fragment of their code is equivalent to MT. Below the hierarchy of computing power are linearly-limited, stack and finite automata. Security analysis of the last two is quite possible, even within the framework of the theoretical theory itself.
Secondly, the distinctive feature of MT is that it has a memory of infinite size. It is from this feature that the impossibility of obtaining all possible states of the computational process — their simply infinite number — follows. However, in real computers, memory is far from infinite. More importantly, in real programs, the number of states of interest from the point of view of the security analysis task is also of course (although it is indecently large).
Thirdly, the calculation of the Rice program properties is a solvable problem for a number of small MTs with a small number of states and possible transitions between them. It is difficult to imagine a real program with 2 to 4 states. However, such a * fragment * of the program is much easier to imagine.
Consequently, it is possible to efficiently analyze individual fragments of program code that fall under the listed criteria. In practice, this means that:
- the code fragment without cycles and recursion can be comprehensively analyzed, since equivalent to the state machine;
- a fragment with cycles or recursion, the exit condition of which does not depend on the input data, can be analyzed as a finite or stack automaton;
- if the conditions for exit from a cycle or recursion depend on the input data, the length of which is limited to some reasonable threshold, then in some cases such fragment can be analyzed as a system of linearly bounded automata or small MTs.
But everything else - alas and ah - cannot be analyzed with a static approach. Moreover, the development of a source code security analyzer is a direction in which engineers encounter EXPPACE <-> EXPTIME every day, and, reducing even particular cases to a subexponent, are as happy as children because it is really cool. Think about what will be the power of the set of values of the variable parm1 at the last execution point?
var parm1 = Request.Params["parm1"]; var count = int.Parse(Request.Params["count"]); for (var i = 0; i < count; i++) { i % 2 == 0 ? parm1 = parm1 + i.ToString(): parm1 = i.ToString() + parm1; } Response.Write(parm1); That's why you can not worry too much about theoretical limitations, because it will be extremely difficult to rest on them with current computing power. However, the listed relaxations of these restrictions set the right direction for the development of modern static analyzers, so it’s worth keeping them in mind.
DAST, IAST and all-all-all
In contrast to the static approach that works with the program code without actually executing it, dynamic (Dynamic Application Security Testing, DAST) implies the presence of a deployed application execution environment and its run on the most interesting from the point of view of the analysis of the input data sets. Simplifying, it can be described as the method of "conscious scientific typing" ("let's give the program such data that is typical for such an attack and see what comes of it"). Its drawbacks are obvious: it is not always possible to quickly deploy the system being analyzed (and often just to assemble), the transition of the system to any state may be a consequence of processing previous data sets, and for a comprehensive analysis of the behavior of a real system, the number of input data must be so great that one can speak only theoretically about his limbs.
Relatively recently, an approach that combines the advantages of SAST and DAST - an interactive analysis (Interactive ..., IAST) was considered promising. A distinctive feature of this approach is that SAST is used to form input data sets and templates of expected results, and DAST performs system testing on these sets, optionally involving a human operator in ambiguous situations in the process. The irony of this approach is that it has absorbed both the advantages and disadvantages of SAST and DAST, which could not but affect its practical applicability.
But who said that in the case of dynamic analysis you need to perform the entire program entirely? As was shown above, it is quite realistic to analyze a significant part of the code using a static approach. What prevents to analyze with the help of dynamic only the remaining fragments? Sounds like a plan ...
And inside her neonka
There are several traditional approaches to static analysis, differing by model, on the basis of which the analyzer derives certain properties of the code under study. The most primitive and obvious is the signature search, based on the search for the occurrence of a pattern in the syntax model of the code representation (as a rule, this is either a stream of tokens or an abstract syntax tree). Separate implementations of this approach use slightly more complex models (a semantic tree, its mapping of individual data streams to a graph, etc.), but in general this approach can be considered solely as an auxiliary, allowing to isolate suspicious places in the code for linear time. manual verification. We will not dwell on it in more detail; those interested can turn to the series of articles by Ivan Kochurkin devoted to him.
More complex approaches operate with models of execution (rather than representations or semantics) of the code. Such models, as a rule, allow to get an answer to the question “can externally controlled data flow reach any point of execution at which this will lead to the emergence of a vulnerability?”. In most cases, the model here is a variation on the theme of execution flow and data flow graphs, or a combination of them (for example, a graph of code properties ). The lack of such approaches is also obvious - in any non-trivial code, the answer to this question alone is not sufficient for successful detection of vulnerability. For example, for a fragment:
var requestParam = Request.Params["param"]; var filteredParam = string.Empty; foreach(var symbol in requestParam) { if (symbol >= 'a' && symbol <= 'z') { filteredParam += symbol; } } Response.Write(filteredParam); such an analyzer will deduce from the constructed model an affirmative answer about data reachability by `Request.Params [" param "]` execution point `Response.Write (filteredParam)` and the existence of XSS at this point. At that time, as a matter of fact, this stream is effectively filtered and cannot be the carrier of the attack vector. There are many ways to cover the special cases associated with preprocessing data streams, but they all ultimately boil down to a reasonable balance between the false positives of the first and second types.

How can I minimize the occurrence of both types of errors? To do this, it is necessary to take into account the conditions of reachability of both potentially vulnerable execution points and sets of values of data streams arriving at such points. Based on this information, it becomes possible to build a system of equations, the set of solutions of which will give all possible sets of input data necessary to come to a potentially vulnerable point of the program. The intersection of this set with the set of all possible attack vectors will give the set of all sets of input data that bring the program into a vulnerable state. It sounds great, but how to get a model that contains all the necessary information?
Abstract interpretation and symbolic calculations
Suppose we are faced with the task of determining the number with which sign defines the expression `-42 / 8 * 100500`. The easiest way is to evaluate this expression and make sure that a negative number is obtained. The calculation of an expression with the well-defined values of all its arguments is called a concrete calculation. But there is another way to solve this problem. Let's imagine for a second that for some reason we cannot specifically calculate this expression. For example, if the variable `-42 / 8 * 100500 * x` was added to it. We define abstract arithmetic, in which the result of operations on numbers is determined solely by the sign rule, and the values of their arguments are ignored:
(+a) = (+) (-a) = (-) (-) * (+) = (-) (-) / (+) = (-) ... (-) + (+) = (+-) ... Interpreting the original expression within the framework of this semantics, we get: `(-) / (+) * (+) * (+)` -> `(-) * (+) * (+)` -> `(-) * ( +) `->` (-) `. This approach will give an unequivocal answer to the task before the addition or subtraction operations appear in the expression. Let's add our arithmetic so that the values of the arguments of operations are also taken into account:
(-a) * (+b) = (-c) (-a) / (+b) = (-c) ... (-a) + (+b) = a <= b -> (+) a > b -> (-) ... Interpreting the expression `-42 / 8 * 100500 + x` in the new semantics we get the result` x> = -527625 -> (+), x <-527625 -> (-) `.
The approach described above is called abstract interpretation and is formally defined as a stable approximation of the semantics of expressions, based on monotone functions over ordered sets. In simpler language, it is the interpretation of expressions without their specific calculation in order to collect information within a given semantic field. If we smoothly move from interpreting individual expressions to interpreting program code in any language, and as a semantic field we define the semantics of the language itself, supplemented by the rule to operate with all input data as unknown variables (symbolic values), then we get an approach called symbolic the implementation and underlying of the most promising areas of static code analysis.
It is with the help of symbolic calculations that it becomes possible to build a contextual graph of symbolic calculation (alternative name: calculation flow graph) - a model that comprehensively describes the process of calculating the program under study. This model was considered in the report “Automatic generation of patches for source code” , and its application for analyzing code security in the article “On the analysis of source code and automatic generation of exploits” . It hardly makes sense to consider them again in the framework of this article. It is only necessary to note that this model allows us to obtain reachability conditions for any point in the execution flow, as well as for the sets of values of all arguments arriving in it. That is - exactly what we need to solve our problem.
Search for vulnerabilities in the computation flow graph
Having formalized the criteria of vulnerability to one or another class of attacks in terms of the calculation flow graph, we will be able to implement code security analysis by resolving the properties of a particular model obtained as a result of abstract interpretation of the code under study. For example, the criteria for vulnerability to attacks of any injection (SQLi, XSS, XPATHi, Path Traversal, etc.) can be formalized like this:
Let C be the computation flow graph of the code under study.
Let pvf (t) be the reachable vertex of the control flow on C, which is a call to the function of direct or indirect interpretation of the text t corresponding to the formal grammar G.
Let e be the input argument stream in C.
Let De be the set of data streams on C generated by e.
Then the application is vulnerable to injection attacks at the pvf (t) call point, if t belongs to De and the set of De values includes at least one pair of elements in which, as a result of their syntactic analysis according to the grammar G, they are not isomorphic to each other. friend trees
In a similar way, vulnerabilities to other classes of attacks are formalized. However, it should be noted here that not all types of vulnerabilities can be formalized within the framework of a model that is derived only from the analyzed code. In some cases, additional information may be required. For example, to formalize vulnerabilities to attacks on business logic, it is necessary to have formalized application domain rules, to formalize vulnerabilities to attacks on access control — a formalized policy of access control, etc.
Ideal spherical code security analyzer in vacuum
Let us now briefly digress from the harsh reality and dream a little bit about what functionality the core of the hypothetical Ideal Analyzer should have (let's call it “IA”)?
First, it must incorporate the advantages of SAST and DAST, not including their disadvantages. From this, in particular, it follows that IA should be able to work exclusively with the existing application code (source or binary), without requiring its completeness or application deployment in the runtime environment. In other words, it should support the analysis of projects with missing external dependencies or any other factors hindering the assembly and deployment of the application. At the same time, work with code fragments that have links to missing dependencies should be implemented to the fullest extent possible in each particular case. On the other hand, IA should be able to effectively “dodge” not only the theoretical limitations imposed by the turing computation model, but also scan in a reasonable time, consuming a reasonable amount of memory and adhering to the subexponential “weight category” as far as possible.
Secondly, the probability of occurrence of errors of the first kind should be minimized by constructing and solving systems of logical equations and generating a working attack vector at the output, allowing the user to confirm the existence of a vulnerability in a single action.
Third, IA must effectively deal with errors of the second kind, allowing the user to manually check all potentially vulnerable points of the flow of execution, the vulnerability of which IA itself could neither confirm nor deny.
The use of a model based on symbolic calculations allows all these requirements to be realized, which is called “by-design”, except for the part that concerns theoretical limitations and the subexponent. And here, as it is impossible by the way, we will have our plan - to use dynamic analysis where static has failed.
Partial calculations, inverse functions and delayed interpretation
Imagine that IA contains a certain knowledge base describing the semantics of the input data conversion functions implemented in the standard library of the language or application environment, the most popular frameworks and CMS. For example, that the functions Base64Decode and Base64Encode are mutually inverse, or that each call to a StringBuilder.Append adds a new string to the one already stored in the intermediate battery variable of this class, etc. Possessing such knowledge, IA will be spared the need to “fall through” into the library code, the analysis of which also falls under all computational limitations:
// cond2 if (Encoding.UTF8.GetString(Convert.FromBase64String(cond2)) == "true") { var sb = new StringBuilder(); sb.Append(Request.Params["param"]); // sb.ToString StringBuilder, Response.Write(sb.ToString()); } But what to do if the code contains a function call that is not described in the IA knowledge base? Let's imagine that at the disposal of IA there is a kind of virtual sandbox environment that allows you to run an arbitrary fragment of the analyzed code in a given context and get the result of its execution. Let's call this a "partial calculation." Then, before you honestly “fall” into an unknown function and begin to interpret it abstractly, IA can try a trick called “partial fuzzing”. His general idea is to prepare the knowledge base for library transforming functions and combinations of their successive calls on previously known sets of test data. With such a database, you can perform an unknown function on the same data sets and compare the results with samples from the knowledge base.If the results of executing an unknown function coincide with the results of executing a known chain of library functions, then this will mean that IA is now known semantics of the unknown function and its interpretation is not necessary.
If for some of the known sets of values of all data streams coming into this fragment, and the fragment itself does not contain dangerous operations, then IA can simply execute it on all possible data streams and use the results instead of abstract interpretation of this fragment of code. Moreover, this fragment can belong to any class of computational complexity and this does not affect the results of its implementation. Moreover, even if the sets of data stream values arriving in the fragment are unknown in advance, the IA may postpone the interpretation of this fragment until the solution of the equation for the particular dangerous operation begins. At the decision stage, an additional restriction is imposed on the set of input data values on the presence of vectors of various attacks in the input data.which may also suggest the set of values of the input data coming in the pending fragment and, thereby, partially calculate it at this stage.
Moreover, at the decision stage, nothing prevents IA from taking the final reachability formula of a dangerous point and its arguments (which is easiest to build in the syntax and semantics of the same language on which the analyzed code is written) and “profazz” it with all known vectors for obtaining their subsets passing through all filtering functions of the formula:
// Response.Write, , parm1 XSS Response.Write(CustomFilterLibrary.CustomFilter.Filter(parm1)); The approaches described above allow you to cope with the analysis of a significant part of the turing-full code fragments, but they require significant engineering work, both in terms of filling the knowledge base and optimizing the emulation of the semantics of standard types, as well as in implementing the sandbox for partial code execution (no one wants The analysis process suddenly performed something like File.Delete (in a loop), as well as supporting the fuzzing of n-local unknown functions, integrating the concept of partial computation with an SMT solver, etc. However, there are no significant restrictions on their implementation, in contrast to the rake of the classic SAST.
When the ugly duck-typing becomes a swan

Imagine that we need to analyze the following code:
var argument = "harmless value"; // UnknownType - , UnknownType.Property1 = parm1; UnknownType.Property2 = UnknownType.Property1; if (UnknownType.Property3 == "true") { argument = UnknownType.Property2; } Response.Write(argument); A person can easily see the achievable vulnerability to XSS here. But most of the existing static analyzers will safely miss it due to the fact that they do not know anything about the UnknownType type. However, all that is required from IA is to forget about static typing and go to duck. The semantics of the interpretation of such constructions should completely depend on the context of their use. Yes, the interpreter knows nothing about what the `UnknownType.Property1` is - a property, a field, or even a delegate (a reference to a method in C #). But since operations with it are carried out as with a variable variable of some type, nothing prevents the interpreter from processing them in this way. And if, for example, the construction of the `UnknownType.Property1 ()` is encountered further along the code, then nothing prevents to interpret the call of that method,reference to which Property1 was previously assigned. And so on, in the best traditions of duck champion breeders.
Summing up
Of course, there is a mass of marketing whistles, which one analyzer supposedly compares favorably with the other, from the point of view of the party that sells it. But, you see, there is no good in them if the core of the product is not able to provide the basic functionality for which it will be used. And in order to provide it, the analyzer is obliged to strive in its capabilities to the described IA. Otherwise, there can be no talk of any real security on the projects processed by him.
A few years ago, one of our clients turned to us for an analysis of the security of the system developed by them. Among the input data, he provided a report on the analysis of the code of their project by a product, which at that time was the market leader in the SAST toolkit. The report contained about two thousand records, most of which ended up with positive-false positives for verification. But the worst was what was not in the report. As a result of manual code analysis, we discovered dozens of vulnerabilities missed during scanning. The use of such analyzers does more harm than good, both taking the time needed to parse all the false-positive results, and creating the illusion of security due to false-negative. This case, by the way,became one of the reasons for the development of our own analyzer.
“Talk is cheap. Show me the code. ”
It would be strange not to complete the article with a small example of code that allows you to check the degree of ideality of a particular analyzer in practice. Voila - below is the code that includes all the base cases covered by the described approach to abstract interpretation, but not covered by more primitive approaches. Each case is implemented as trivially as possible and with a minimum number of language instructions. This is an example for C # / ASP.Net WebForms, but does not contain any specifics and can be easily translated into code in any other OOP-language and under any web framework.
var parm1 = Request.Params["parm1"]; const string cond1 = "ZmFsc2U="; // "false" base64- Action<string> pvo = Response.Write; // False-negative // , , pvo(parm1); // , , #region var argument = "harmless value"; UnknownType.Property1 = parm1; UnknownType.Property2 = UnknownType.Property1; UnknownType.Property3 = cond1; if (UnknownType.Property3 == null) { argument = UnknownType.Property2; } // False-positive // , , Response.Write(argument); #endregion // False-positive // , , if (cond1 == null) { Response.Write(parm1); } // False-positive // , , Response.Write(WebUtility.HtmlEncode(parm1)); // False-positive // , , // (CustomFilter.Filter `s.Replace("<", string.Empty).Replace(">", string.Empty)`) Response.Write(CustomFilterLibrary.CustomFilter.Filter(parm1)); if (Encoding.UTF8.GetString(Convert.FromBase64String(cond1)) == "true") { // False-positive // , , Response.Write(parm1); } var sum = 0; for (var i = 0; i < 10; i++) { for (var j = 0; j < 15; j++) { sum += i + j; } } if (sum != 1725) { // False-positive // , , Response.Write(parm1); } var sb = new StringBuilder(); sb.Append(cond1); if (sb.ToString() == "true") { // False-positive // , , Response.Write(parm1); } The result of the analysis of this code should be a message about the only vulnerability to XSS attacks in the expression `pvo (parm1)`. You can enter and compile with a scan-ready project here .
But, as they say, “it’s better to see once ...” and, first of all, we checked for compliance with the IA analyzer we are developing, by chance called AI :
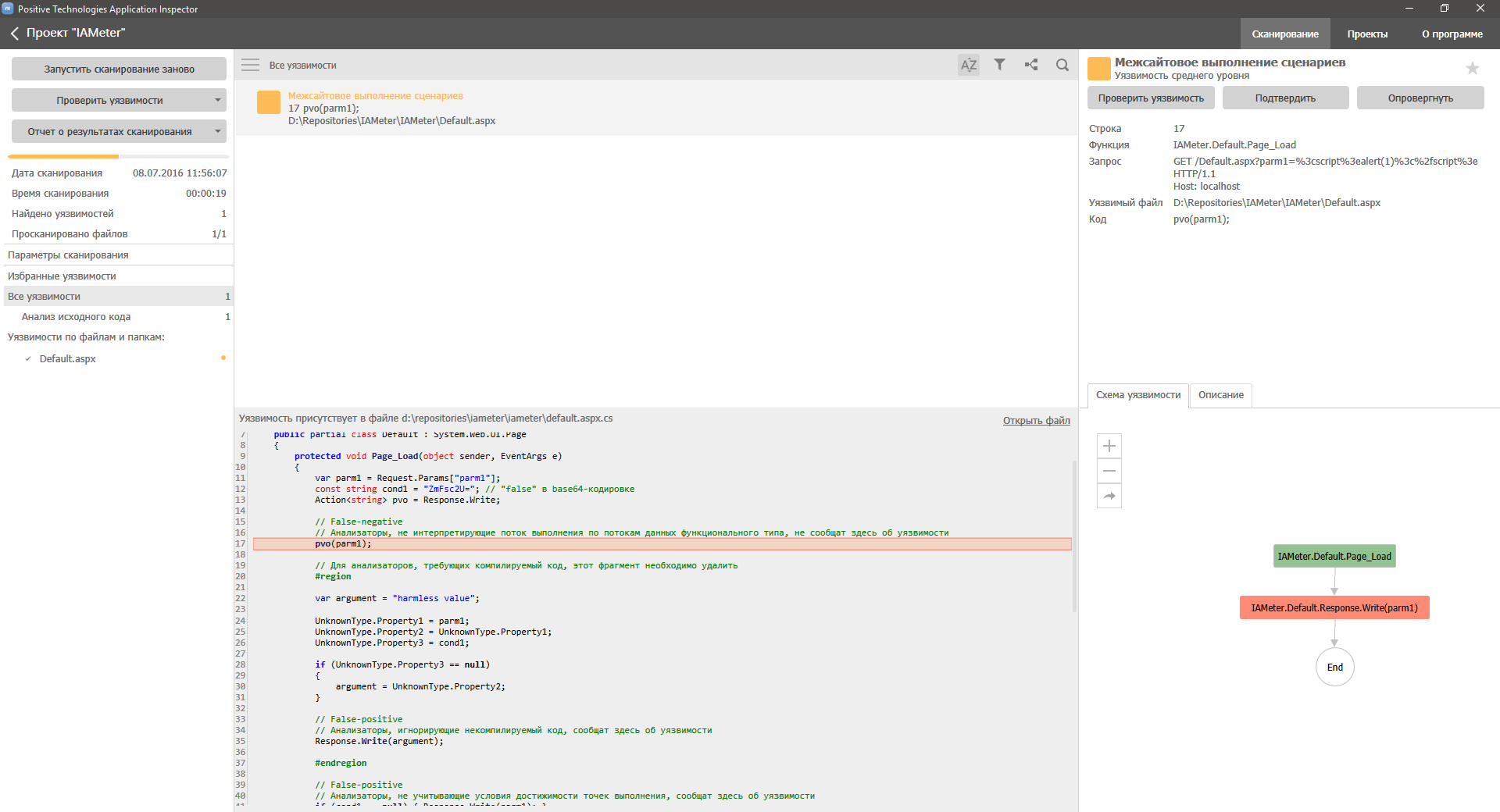
Have you already checked yours? ;)
As a bonus for reading to the end:
We are launching a public alpha testing of the free utility Approof. It does not include code analysis functionality and does not use all the above-described mastaphic hardcore, but includes functionality for detecting vulnerable external components in projects, configuration-sensitive data disclosures, as well as embedded web shells and malicious code:
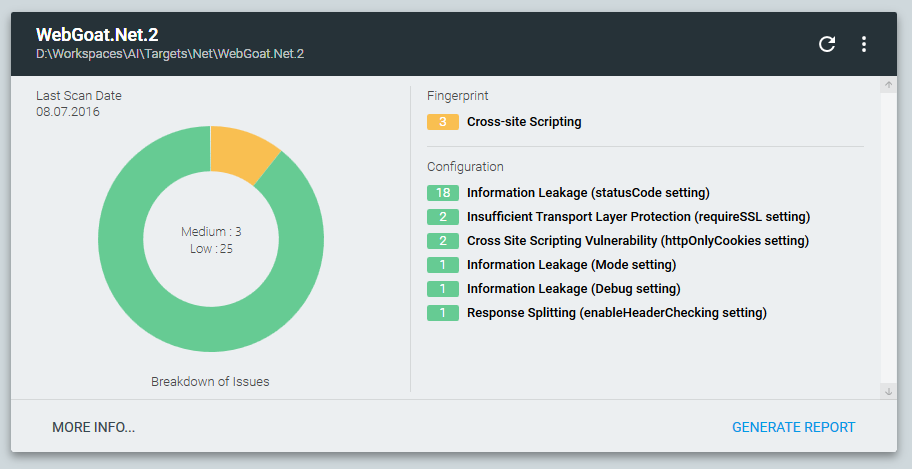
You can download the utility on the official website . Before using it, be sure to read the license agreement. During the analysis, Approof collects non-confidential project statistics (CLOC, file types, frameworks, etc.) and, optionally, sends it to the PT server. You can disable sending statistics or familiarize yourself with the raw json containing the collected data in the About section of the application.
Source: https://habr.com/ru/post/305000/
All Articles