Moving responsibility of the repository pattern
During many discussions about the applicability of the Repository pattern, I noticed that people are divided into two camps. Within the framework of this text, I, conditionally, will call them abstractionists and concreters. The difference between them lies in how they relate to the value of the pattern. The first believe that the repository is worth having, because he allows to abstract from details of data storage. The latter believe that we cannot completely abstract away from these details, therefore the very idea of a repository is meaningless, and its use is a waste of time. The dispute between them usually turns into holivar.
What's wrong with the repository? Obviously, everything is fine with the pattern itself, but the difference is in its understanding by the developers. I tried to investigate it and came across two main points that, in my opinion, are the cause of a different attitude towards it. One of these is the “moving” responsibility of the repository, and the other is associated with underestimating unit testing. Under the cut, I will explain the first.
When it comes to building the application architecture, everyone in the head immediately gets an idea of three layers: Presentation Layer, Business Layer, and Data Layer ( see MSDN ). In such systems, business logic objects use repositories to retrieve data from physical repositories. Repositories return business entities instead of raw record sets. This is very often justified by the fact that if we had to replace the type of physical storage (base, file, or service), we would create an abstract class of the repository and implement the storage specific to us. It looks like this:
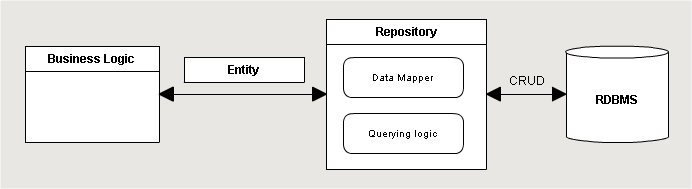
')
About the same division says Martin Fowler and MSDN . As usual, the description is just a simplified model. Therefore, although it looks right for a small project, it is misleading when you try to transfer this pattern to a more complex one. Existing ORMs are even more confusing, because implement many things out of the box. But imagine that a developer only knows how to use the Entity Framework (or another ORM) only to get data. Where, for example, should it put a second-level cache, or logging all business operations? In an attempt to do this, it is obvious that he will try to separate the modules according to their functionality, follow the SPR from SOLID, and build a composition of them, which may look like this:

Does the repository perform the same role as before? The obvious answer is "NO", because now it does not retrieve data from the repository. This responsibility has been transferred to another object. On this basis, the first discrepancy arises between the camps of abstractionists and concreters.
If we accept the rule that all terms should retain their meaning, regardless of code modifications, then it would be correct at the first stage not to call an object that simply returns data a repository. This is a pure DAO pattern, because its task is to hide a specific data access interface (ling, ADO.NET, or something else). At the same time, the repository may not know anything at all about such details, gathering all the data access subsystems in a single composition.
Do you think that such a problem exists?
What's wrong with the repository? Obviously, everything is fine with the pattern itself, but the difference is in its understanding by the developers. I tried to investigate it and came across two main points that, in my opinion, are the cause of a different attitude towards it. One of these is the “moving” responsibility of the repository, and the other is associated with underestimating unit testing. Under the cut, I will explain the first.
Repository Slip Responsibility
When it comes to building the application architecture, everyone in the head immediately gets an idea of three layers: Presentation Layer, Business Layer, and Data Layer ( see MSDN ). In such systems, business logic objects use repositories to retrieve data from physical repositories. Repositories return business entities instead of raw record sets. This is very often justified by the fact that if we had to replace the type of physical storage (base, file, or service), we would create an abstract class of the repository and implement the storage specific to us. It looks like this:
')
About the same division says Martin Fowler and MSDN . As usual, the description is just a simplified model. Therefore, although it looks right for a small project, it is misleading when you try to transfer this pattern to a more complex one. Existing ORMs are even more confusing, because implement many things out of the box. But imagine that a developer only knows how to use the Entity Framework (or another ORM) only to get data. Where, for example, should it put a second-level cache, or logging all business operations? In an attempt to do this, it is obvious that he will try to separate the modules according to their functionality, follow the SPR from SOLID, and build a composition of them, which may look like this:
Does the repository perform the same role as before? The obvious answer is "NO", because now it does not retrieve data from the repository. This responsibility has been transferred to another object. On this basis, the first discrepancy arises between the camps of abstractionists and concreters.
Instead of analyzing
If we accept the rule that all terms should retain their meaning, regardless of code modifications, then it would be correct at the first stage not to call an object that simply returns data a repository. This is a pure DAO pattern, because its task is to hide a specific data access interface (ling, ADO.NET, or something else). At the same time, the repository may not know anything at all about such details, gathering all the data access subsystems in a single composition.
Do you think that such a problem exists?
Source: https://habr.com/ru/post/304824/
All Articles