Recognition of the RF passport on the Elbrus platform. Part 1
In this article we will continue to talk about the adventures of our passport recognition program: now the passport will go to Elbrus!

So, what do we know about the architecture of Elbrus?
Elbrus is a high-performance and energy-efficient processor architecture, characterized by high security and reliability. Modern Elbrus architecture processors can be used as servers, desktops, and even embedded computers. They are able to meet the increased requirements for information security, the working temperature range and the duration of the product life cycle. The Elbrus architecture processors, as we are told by the MCST publications [1, 2], are intended for solving problems of signal processing, mathematical modeling, scientific calculations, as well as other tasks with increased requirements for computing power.
We in Smart Engines tried to make sure that the performance of Elbrus is true enough to realize the recognition of a passport without significant loss in speed.
Overview and narrative: architecture features Elbrus
The architecture of Elbrus belongs to the category of architectures that use the principle of a wide command word (Very Long Instruction Word, VLIW). On processors with a VLIW architecture, the compiler generates sequences of groups of commands (broad command words), in which there are no dependencies between the commands within the group and the dependencies between the commands in different groups are minimized. These groups of commands are executed in parallel, which ensures a high level of parallelism at the level of operations.

Parallelization at the command level is entirely provided by the optimizing compiler, which significantly simplifies the hardware for executing commands, since now it does not solve paralleling tasks, as is the case, for example, with the x86 architecture. The power consumption of the system is reduced: the processor is no longer required to analyze dependencies between operands or rearrange operations, since all these tasks are assigned to the compiler. The compiler has much more computational and time resources than hardware analyzers of binary code, and therefore can perform the analysis more carefully, find more independent operations, and as a result form broad command words that are executed more efficiently.
Along with the use of parallelism of operations in the Elbrus architecture, the implementation of other types of parallelism characteristic of the computational process is also laid: vector parallelism, parallelism of control flows on shared memory, task parallelism in a multi-machine complex.
In addition, the Elbrus architecture is binary compatible with the Intel x86 architecture, implemented on the basis of dynamic binary translation.
Another important feature of the Elbrus architecture is the hardware support for the protection of programs and data during execution. Programs are executed in a single virtual space implemented at the hardware level, which minimizes the possibility of executing malicious code and allows detecting errors that are difficult to be detected on other architectures.
Thus, the main features of the architecture of Elbrus processors [3, 4]:
- parallel energy efficient core architecture;
- automatic parallelization of a stream of commands using a compiler;
- increasing the reliability and security of the created software due to the presence of a protected mode;
- compatibility with common microprocessor architectures.
Our acquaintance with Elbrus
The specific machine we were working with was Elbrus 4.4, combining four 4-core Elbrus 4C processors with 3 memory controllers, 3 interprocessor exchange channels, 1 I / O channel and 8 MB of cache level 2 (2 MB per core) . The operating clock frequency of the Elbrus 4C is 800 MHz, the technological norm is 65 nm, the average power dissipation is 45 W. Operating system - OS "Elbrus", created on the basis of Linux. This is what the uname -a command displayed to us:

The optimizing compiler for Elbrus is called lcc. On our server was installed lcc version 1.20.09 dated August 27, 2015, compatible with gcc 4.4.0. lcc works with standard gcc flags, and also defines some additional ones. From the standard flags, we noticed -ffast and -ffast-math. These options are disabled by default, because they include transformations with real arithmetic, which can lead to incorrect results of programs that imply strict adherence to the IEEE or ISO standards for real operations and functions. In addition, they include some potentially dangerous optimizations, which in rare cases can lead to incorrect behavior of programs that freely juggle with pointers. Both flags additionally include -fstdlib, -faligned, -fno-math-errno, -fno-signed-zeros, -ffinite-math-only, -fprefetch, -floop-apb-conditional-loads, -fstrict-aliasing. Their use significantly affects the performance of the program.
In addition, lcc allows you to fine-tune the optimization quite fine, for example, there are a whole set of flags to configure the function substitution parameters:
Table 1. Flags lcc, allowing control of function substitution parameters.
| Lcc flag | Purpose |
|---|---|
| -finline-level = <f> | Sets the rate of substitution increase [0.1-20.0] |
| -finline-scale = <f> | Sets the rate of increase of the main resource constraints [0.1-5.0] |
| -finline-growfactor = <f> | Sets the maximum increase in the size of the procedure after substitution [1.0-30.0] |
| -finline-prog-growfactor = <f> | Specifies the maximum increase in the size of the program after substitution [1.0-30.0] |
| -finline-size = <n> | Sets the maximum size of the inline procedure. |
| -finline-to-size = <n> | Specifies the maximum size of the procedure into which substitution can be made. |
| -finline-part-size = <n> | Sets the maximum size of the probable procedure region for partial substitution |
| -finline-second-size = <n> | Specifies the maximum size of an unconditional invoked procedure |
| -flib-inline-uncond-size = <n> | Sets the maximum size of an unconditional library routine. |
| -finline-probable-calls = <f> | Prohibits the substitution of procedures, the call counter of which is less than (argument * max_call_count), where max_call_count is the maximum call operation counter for the entire task. |
| -force-inline | Enables unconditional function substitution with the inline specifier. |
| -finline-vararg | Includes the substitution of functions with a variable number of arguments. |
| -finline-only-native | Performs substitution only for functions with an explicit inline modifier |
You can also customize interprocedural optimizations, pointer analysis, data paging, etc.
For profiling on Elbrus, familiar to many perf are available, as well as the much less well-known dprof. In addition, an extension is available for dprof that allows you to convert a profile to a valgrind-compatible format.
So, our goal was to launch the console version of the passport recognition program. It is written entirely in C / C ++, sometimes using C ++ 11. Despite the fact that C ++ 11 support is not stated, in fact, lcc understands it, although very selectively. Full C ++ 11 support is planned for newer versions of lcc.
Not exactly supported:
- std :: default_random_engine. Unfortunately, here you can only advise to use third-party pseudo-random number generators.
- nullptr_t. In those cases when nullptr is really needed, you have to use some specially selected value of the object instead.
- std :: begin and std :: end. For STL objects, you can use the begin () and end () methods, but for C / C ++ objects you will have to search for addresses manually.
- std :: chrono :: steady_clock. We used std :: chrono :: high_resolution_clock instead of it, although, of course, the absence of std :: chrono :: steady_clock can introduce inaccuracies in the measurement of working time.
- The std :: string :: pop_back () method is missing. But instead you can easily use std :: string :: erase (size () - 1, 1).
- std :: to_string is not defined for a double argument. This problem is solved by converting, for example, to long double, which is supported.
- The standard STL containers do not provide specifications for std :: unique_ptr as a stored object with a move operation instead of copying, that is, for example, std :: map <int, std :: uniqie_ptr> cannot be created.
At the same time, std :: unique_ptr, std :: shared_ptr are supported by themselves.
In addition, lcc disturbs the __uint128_t gcc extension, as well as the source code files in UTF-8 with BOM.
After rewriting unsupported pieces of code, we were able to successfully compile our project. However, we simply did not succeed in simply taking and running the passport recognition program: we received an error Bus error when trying to start it. After consultation with the experts of the MCST, it was found that the problem lies in the unallocated access to the memory that occurs inside the Eigen library, which we use.
Eigen is an optimized header-only linear algebra library written in C ++ [5]. It can be used for various operations on matrices and vectors, and also includes optimizations for x86 SSE, ARM NEON, PowerPC AltiVec and even IBM S390x.
Since the Eigen developers hardly expected that their library would ever be used on Elbrus, they did not include it in the list of supported architectures, and the mode of aligned memory access was simply disabled. Our colleagues from the MCST promptly helped us fix this problem by showing how to modify:

As a result of this addition, the Eigen functionality we need has earned. It should be noted that this was the only incompatibility of Eigen with Elbrus, and it manifests itself only with the included optimizations.
However, our misadventures did not stop at this. The error Bus error has not gone away, but now it appeared when the code was already executed by our libraries. After a little research, we found that unallocated memory access periodically arose during the initialization of additional image containers in the recognition process.
When filling a 8-bit line with a fixed value, in order to accelerate, there was a part of the line that is a multiple of 4 bytes, and was filled with 32-bit values (created by copying the original 8-bit), and the rest of the line was filled with one byte. However, when allocating an 8-bit picture, alignment in the memory is guaranteed only up to one byte, and an error occurred when trying to write a 32-bit value to this address.
To solve the problem, we added in the beginning of processing the line calculation of the nearest address, which is a multiple of the required number of bytes (in the described case - four) and filling in to this address one byte, and filling in 4 bytes already done from this address.
After correcting this error, our program not only started, but also demonstrated proper operation!


It was already a small victory, but we moved on. The next step we went directly to optimizing our system. Our program can work in two modes: recognition of a randomly located passport in a photo or a scanned image (anywhere mode), and also recognition of a passport in a video clip (mobile mode). In the second case, it is assumed that the passport takes up most of the frame, from frame to frame its position changes slightly, and the processing of one frame includes significantly simplified document search algorithms.
Recognition of one test image in anywhere-mode, going to 1 stream, “out of the box” worked on Elbrus for about 100 (!) Seconds.
At first we tried to use all 16 Elbrus cores 4.4. It was possible to use all 16 flows efficiently only in about a third of our program. The remaining calculations managed to be parallelized into 2 threads. As a result, the recognition time was reduced to 7.5 seconds. Inspired, we looked at the profiler. To our surprise, we saw something like this there:

It turned out that inside the main program loop there was a wonderful place:
std::vector<Object> candidates; for (int16_t x = x_min; x < x_max; x += x_step) for (int16_t y = y_min; y < y_max; y += y_step) candidates.emplace_back(x, y, 0.0f); As a result of the repeated execution of this code, the overhead of changing the size of the vector is monstrously growing and reaches 16% of the recognition time. On other architectures, this place was not noticeable, but on Elbrus memory reallocation was unexpectedly slow. After correcting this annoying misstep, the operating time was reduced by almost 1 second.
Then we proceeded to increase the parallelism within each thread - the main “chip” of the VLIW. To do this, we used the shortest path - the EML library already optimized by the MCST specialists.
High Performance EML Library
For microprocessors of the Elbrus architecture, the EML library has been developed - a library that provides the user with a set of various functions for high-performance processing of signals, images, video, as well as mathematical functions and operations [4, 6].
EML includes the following function groups:
- Vector - functions for working with data vectors (arrays);
- Algebra - functions of linear algebra;
- Signal - signal processing functions;
- Image - image processing functions;
- Video - video processing functions;
- Volume - transformation functions of three-dimensional structures;
- Graphics - functions for drawing shapes.
The EML library is intended for use in programs written in C / C ++ languages.
Low-level image processing functions are either supported by EML directly, or representable through the basic arithmetic functions of EML on vectors (in our case, image lines).
For example, elementwise addition of two arrays of 32-bit real numbers:
for (int i = 0; i < len; ++i) dst[i] = src1[i] + src2[i]; can be performed using the EML function:
eml_Status eml_Vector_Add_32F(const eml_32f *pSrc1, const eml_32f *pSrc2, eml_32f *pDst, eml_32s len) Where
pSrc1- pointer to the vector of the first operandpSrc2- Pointer to the second operand vectorpDst-pDstvector pointerlen- The number of elements in vectors
She returns
EML_OKif the function completed successfullyEML_INVALIDPARAMETERif one of the pointers is NULL or the length of the vectors is less than or equal to 0.
The total eml_Status enumeration can take 4 values:
EML_OK- No ErrorEML_INVALIDPARAMETER-EML_INVALIDPARAMETERargument or out of rangeEML_NOMEMORY- No free memory for the operation.EML_RUNTIMEERROR- Incorrect data, error during execution
The main data types are defined:
typedef char eml_8s; typedef unsigned char eml_8u; typedef short eml_16s; typedef unsigned short eml_16u; typedef int eml_32s; typedef unsigned int eml_32u; typedef float eml_32f; typedef double eml_64f; The function for the elementwise multiplication of 32-bit real numbers is similarly arranged:
eml_Status eml_Vector_Mul_32F(const eml_32f *pSrc1, const eml_32f *pSrc2, eml_32f *pDst, eml_32s len) But for integers, only the functions of elementwise addition and multiplication with a shift are defined, which perform the following operations:
// Addition for (int i = 0; i < len; ++i) dst[i] = SATURATE((src1[i] + src2[i]) << shift); // Multiplication for (int i = 0; i < len; ++i) dst[i] = SATURATE((src1[i] * src2[i]) << shift); And the actual EML function:
// int16_t addition eml_Status eml_Vector_AddShift_16S(const eml_16s *pSrc1, const eml_16s *pSrc2, eml_16s *pDst, eml_32s len, eml_32s shift) // int32_t addition eml_Status eml_Vector_AddShift_32S(const eml_32s *pSrc1, const eml_32s *pSrc2, eml_32s *pDst, eml_32s len, eml_32s shift) // uint8_t addition eml_Status eml_Vector_AddShift_8U(const eml_8u *pSrc1, const eml_8u *pSrc2, eml_8u *pDst, eml_32s len, eml_32s shift) // int16_t multiplication eml_Status eml_Vector_MulShift_16S(const eml_16s *pSrc1, const eml_16s *pSrc2, eml_16s *pDst, eml_32s len, eml_32s shift) // int32_t multiplication eml_Status eml_Vector_MulShift_32S(const eml_32s *pSrc1, const eml_32s *pSrc2, eml_32s *pDst, eml_32s len, eml_32s shift) // uint8_t multiplication eml_Status eml_Vector_MulShift_8U(const eml_8u *pSrc1, const eml_8u *pSrc2, eml_8u *pDst, eml_32s len, eml_32s shift) Such functions can be useful, for example, for integer arithmetic.
EML defines a structure for an image:
typedef struct { void * data; /**< */ eml_image_type type; /**< */ eml_32s width; /**< , x */ eml_32s height; /**< , y */ eml_32s stride; /**< */ eml_32s channels; /**< () */ eml_32s flags; /**< */ void * state; /**< */ eml_32s bitoffset;/**< */ eml_format format; /**< */ eml_8u addition[32 - 2 * sizeof (void *)]; /**< 64 */ } eml_image; Supported eml_image_type data types for images:
- EML_BIT - 1-bit unsigned integer data
- EML_UCHAR - 8-bit unsigned integer data
- EML_SHORT - 16-bit signed integer data
- EML_INT - 32-bit signed integer data
- EML_FLOAT - 32-bit floating point data
- EML_DOUBLE - 64-bit floating point data
- EML_USHORT - 16-bit non-valid integer data
EML supports other functions needed for image processing. For example, the transposition function, which is often necessary for the effective implementation of separable filters:
eml_Status eml_Image_FlipMain(const eml_image *pSrc, eml_image *pDst) This function superimposes the center of the original image on the center of the resulting image and transposes it. Her work can be described by the formula:
dst[width_dst/2 + (y - height_src/2), height_dst/2 + (x - width_src/2)] = src[x, y], x = [0, width-1], y = [0, height-1] Images must have the same data type ( EML_UCHAR, EML_SHORT, EML_FLOAT EML_DOUBLE ) and have the same number of channels (1, 3 or 4).
Experiments and Results
Table 2 shows addition and multiplication times for different types of data. In this experiment, we measured 50 times the execution time of 1000 iterations of addition / multiplication of two arrays of length 10 5 and took the median from the obtained values. The table shows the average execution time per iteration. It can be seen that the use of EML makes it possible to significantly speed up computations in real 32-bit numbers and 8-bit unsigned integers. This is important because these types of data are very often used in an optimized image processing path.
Table 2. The execution time of addition and multiplication of arrays of numbers of length 10 5 per Elbrus 4.4.
| Addition | ||
|---|---|---|
| Data type | uint8_t | float |
| Without EML, μs | 16.7 | 148.8 |
| EML, μs | 8.0 | 83.6 |
| Multiplication | ||
|---|---|---|
| Data type | uint8_t | float |
| Without EML, μs | 31.4 | 108.9 |
| EML, μs | 27.6 | 73.5 |
Then, we decided to test how EML handles images and investigated transposition, since this is a fairly demanded operation in image processing. The dependence of the transposition time on the size for square images of different types:
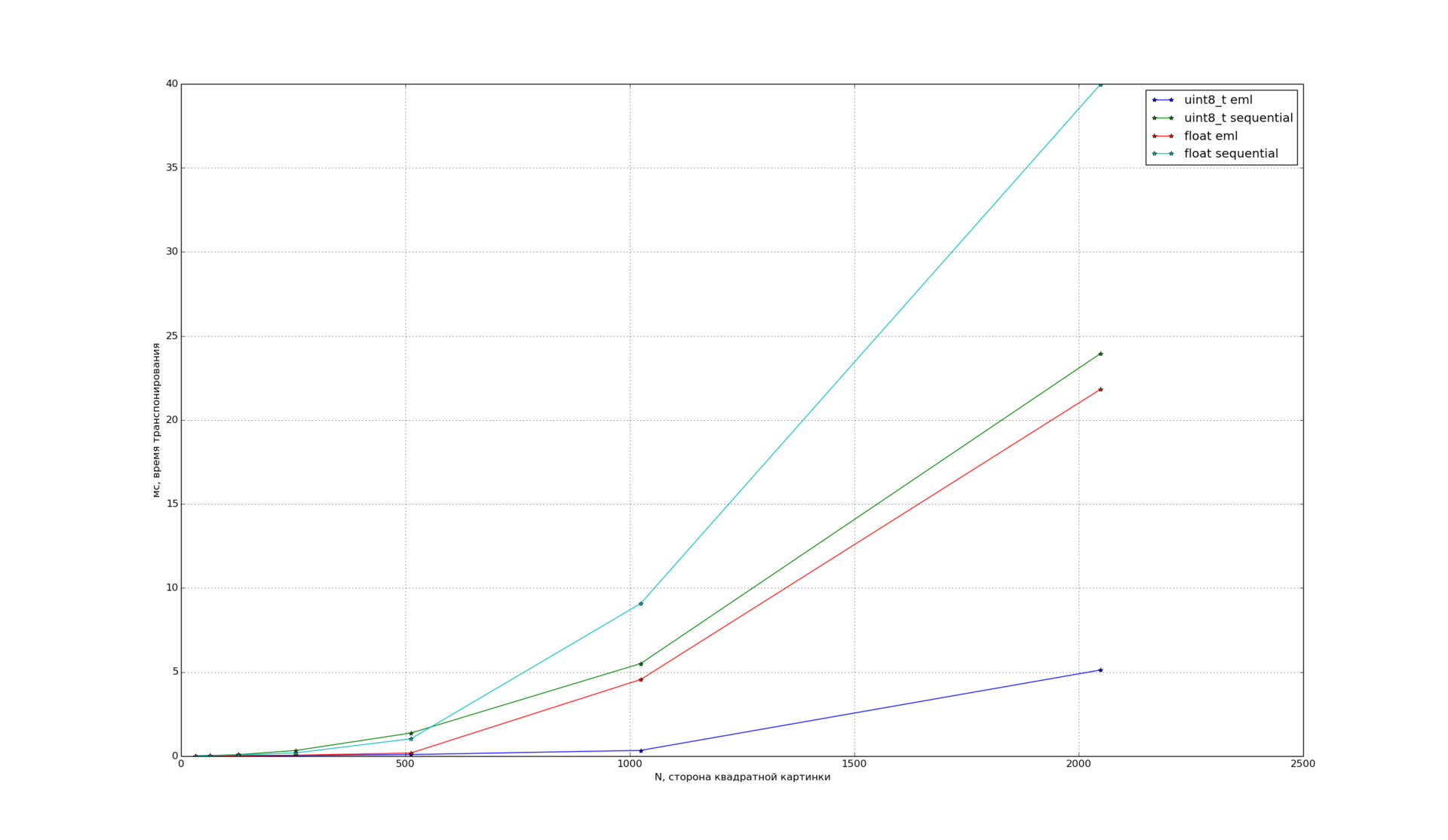
You can see that the EML demonstrates good acceleration for the uint8_t and float types.
The results of speeding up the passport recognition program (test image, anywhere mode) are shown in Table 3. They were obtained in the first 3 months of working with Elbrus and, of course, we plan to work on optimizing the system further.
Table 3. The process of optimizing the passport recognition program for Elbrus 4.4.
| Version | Work time with |
|---|---|
| 1 thread | ~ 100 |
| 16 streams, O3 | 6.2 |
| 16 streams, O4 | 5.4 |
| 16 streams, O4, transpose (EML) | 5.0 |
| 16 streams, O4, transpose, matrix operations (EML) | 4.5 |
| 16 streams, O4, transpose, matrix operations, arithmetic operations (EML) | 3.4 |
To estimate the operating time of the optimized version, we analyzed the operating time for 1000 input images for each of the modes. Table 4 shows the minimum, maximum and average recognition times for a single frame for anywhere and mobile modes.
Table 4. The time of recognition of the passport to Elbrus 4.4.
| Mode | Minimum time, c | Maximum time with | Average time, with |
|---|---|---|---|
| anywhere | 0.9 | 8.5 | 2.2 |
| mobile | 0.2 | 1.5 | 0.6 |
We did not compare performance with Intel or ARM: it took us several years to optimize our libraries for these processors and it would be incorrect to make a comparison now, after only 3 months of work.
Conclusion
In this article we tried to share our experience of porting the program to such an unusual architecture as Elbrus. “This definitely cannot happen to us!” - we thought, talking about some types of software errors, but no one is immune from silly blunders. We have to admit that working with the Elbrus platform really helped us find at least two problem areas in our code, so the manufacturer’s promises can be considered fulfilled.
In just a few months, we managed not only to achieve the correct operation of recognition, but also to significantly accelerate our system on Elbrus. Now the performance of our passport recognition program for Elbrus 4.4 and x86 is no longer an order of magnitude difference, which is a very good result. And we do not intend to stop there. We believe that it can still be significantly improved.
Well, all this means that our first steps in the journey to Elbrus can be considered quite successful!
Many thanks to the company MCST and its staff for providing the hardware platform and advice on architecture and optimization.
Used sources
[1] A.K. Kim, I.N. Bychkov et al. Elbrus architectural line today: microprocessors, computing systems, software // Modern information technologies and IT education. Collection of reports, p. 21–29.
[2] A.K. Kim Russian universal microprocessors and high performance computing systems: results and a look into the future. Issues of radio electronics series EVT, Vol. 3, c. 5–13, 2012.
[3] A.K. Kim and I.N. Bychkov. Russian technology "Elbrus" for personal computers, servers and supercomputers.
[4] V.S. Volin et al. Microprocessors and computing complexes of the Elbrus family. Tutorial. Peter, 2013.
[5] Eigen, C ++ template library for linear algebra: matrices, vectors, numerical solvers, and related algorithms, http://eigen.tuxfamily.org .
[6] P.A. Ishin, V.E. Loginov, and P.P. Vasiliev. Acceleration of calculations using high-performance mathematical and multimedia libraries for the Elbrus architecture.
')
Source: https://habr.com/ru/post/304750/
All Articles