Classifier word2vec
After a recent dialogue, the question arose of searching for classifiers capable of working with texts in Russian without crutches in the form of an assembly of the watson NLC and bing translator. It was decided to compact the layout. The basis is taken word2vec to get a vector representation of the examples and user input. More examples of working with him can be found, for example - here . By the way, the question is more experienced - is there a more suitable alternative? It is not planned to classify volume texts. Let me remind you that word2vec allows you to get a vector representation of the transmitted word (you can apply addition / subtraction and multiplication by a numerical coefficient to the vectors obtained). At the same time, the vector will be in a space in which “linked” words are used as axes.
The code is at https://github.com/alex4321/word2vec-nlc . Written using gensim . This model was used (working with English) GoogleNews-vectors-negative300.bin.gz .
For example - the original phrase - I have a dog, the result of vectorization - (yes, obviously there is rubbish) -
For the
')
The following algorithm is used for classification:
When testing with such data:
Classes -
Input - 'Do you had a dog?'
It turns out the following list:
Those. it is possible to determine what is entered closer to the dog class than to the computer.
PS about working with the Russian language - I mean that technically it is not a problem to assemble the word2vec model working with it. In general, there were even a few - but they seemed rather small (although, perhaps - suitable for practical use)
The code is at https://github.com/alex4321/word2vec-nlc . Written using gensim . This model was used (working with English) GoogleNews-vectors-negative300.bin.gz .
For example - the original phrase - I have a dog, the result of vectorization - (yes, obviously there is rubbish) -
{'SheldenWilliams_@': 0.5255231261253357, "have't": 0.5583386421203613, 'personnaly': 0.5540199875831604, 'havent': 0.597449541091919, 'happening_Truver': 0.5273309946060181, 'Durcinka': 0.5368120670318604, 'wouldnt': 0.5314139723777771, 'whine_nag': 0.5264301300048828, "I'v": 0.532825231552124, 'dogs': 0.5436486601829529, 'i_realy': 0.5310240983963013, "'ve": 0.549283504486084, 'theyd': 0.5327804684638977, 'coz_i': 0.5257705450057983, 'love_veronica_Mars': 0.5656633973121643, 'LOVE_YOU_ALL': 0.5473299622535706, 'JeremyShockey_@': 0.5405183434486389, 'i_havnt': 0.5311092138290405, 've': 0.5290054678916931, 'Reputable_breeders': 0.5303832292556763, 'samantharonson_@': 0.542853593826294, 'hadnt': 0.5852461457252502, 'Er_um': 0.5257833003997803, 'couldve': 0.529604434967041, 'that.I': 0.5449035167694092, 'ive': 0.5347827672958374, "were'nt": 0.5263391733169556, 'i_havent': 0.545918345451355, "havn't": 0.6071761846542358, 'wouldve': 0.556045651435852} ': 0.5257705450057983, 'love_veronica_Mars': 0.5656633973121643,' LOVE_YOU_ALL ': 0.5473299622535706,' JeremyShockey_ @ ': 0.5405183434486389,' i_havnt ': 0.5311092138290405,' ve ': 0.5290054678916931,' Reputable_breeders': 0.5303832292556763, ' {'SheldenWilliams_@': 0.5255231261253357, "have't": 0.5583386421203613, 'personnaly': 0.5540199875831604, 'havent': 0.597449541091919, 'happening_Truver': 0.5273309946060181, 'Durcinka': 0.5368120670318604, 'wouldnt': 0.5314139723777771, 'whine_nag': 0.5264301300048828, "I'v": 0.532825231552124, 'dogs': 0.5436486601829529, 'i_realy': 0.5310240983963013, "'ve": 0.549283504486084, 'theyd': 0.5327804684638977, 'coz_i': 0.5257705450057983, 'love_veronica_Mars': 0.5656633973121643, 'LOVE_YOU_ALL': 0.5473299622535706, 'JeremyShockey_@': 0.5405183434486389, 'i_havnt': 0.5311092138290405, 've': 0.5290054678916931, 'Reputable_breeders': 0.5303832292556763, 'samantharonson_@': 0.542853593826294, 'hadnt': 0.5852461457252502, 'Er_um': 0.5257833003997803, 'couldve': 0.529604434967041, 'that.I': 0.5449035167694092, 'ive': 0.5347827672958374, "were'nt": 0.5263391733169556, 'i_havent': 0.545918345451355, "havn't": 0.6071761846542358, 'wouldve': 0.556045651435852} {'SheldenWilliams_@': 0.5255231261253357, "have't": 0.5583386421203613, 'personnaly': 0.5540199875831604, 'havent': 0.597449541091919, 'happening_Truver': 0.5273309946060181, 'Durcinka': 0.5368120670318604, 'wouldnt': 0.5314139723777771, 'whine_nag': 0.5264301300048828, "I'v": 0.532825231552124, 'dogs': 0.5436486601829529, 'i_realy': 0.5310240983963013, "'ve": 0.549283504486084, 'theyd': 0.5327804684638977, 'coz_i': 0.5257705450057983, 'love_veronica_Mars': 0.5656633973121643, 'LOVE_YOU_ALL': 0.5473299622535706, 'JeremyShockey_@': 0.5405183434486389, 'i_havnt': 0.5311092138290405, 've': 0.5290054678916931, 'Reputable_breeders': 0.5303832292556763, 'samantharonson_@': 0.542853593826294, 'hadnt': 0.5852461457252502, 'Er_um': 0.5257833003997803, 'couldve': 0.529604434967041, 'that.I': 0.5449035167694092, 'ive': 0.5347827672958374, "were'nt": 0.5263391733169556, 'i_havent': 0.545918345451355, "havn't": 0.6071761846542358, 'wouldve': 0.556045651435852} .For the
{'psn': 0.5582104325294495, '•_vaibhav_sir': 0.5425109267234802, 'theyve': 0.5318623781204224, 'love_veronica_Mars': 0.564369261264801, 'receive_MacMall_Exclusive': 0.5217918157577515, 'havnt': 0.517998456954956, 'gfx_card': 0.5196627378463745, 'macbook_pro': 0.5703814029693604, 'droid_x': 0.5607396364212036, 'dell_laptop': 0.5578193664550781, "'ve": 0.5209441184997559, 'Arrendondo_cook': 0.5448468923568726, "I'v": 0.5355654358863831, 'lenovo': 0.5266544222831726, 'reinstall_XP': 0.537743091583252, 'wifi_adapter': 0.5497201085090637, 'havent': 0.5768314003944397, 'LOVE_YOU_ALL': 0.5329291820526123, 'haha_i': 0.5369561314582825, 'computers': 0.5202767252922058, 'automaticly': 0.523144543170929, 'hadnt': 0.5282260775566101, 'ive': 0.5156651735305786, 'google_docs': 0.5261930227279663, 'google_chrome': 0.5319492816925049, 'i_havent': 0.5323601961135864, "havn't": 0.593987226486206, 'mainframes_minicomputers': 0.5255732536315918, 'Ive': 0.518458902835846, 'cect_u##_china': 0.5316625237464905}
{'psn': 0.5582104325294495, '•_vaibhav_sir': 0.5425109267234802, 'theyve': 0.5318623781204224, 'love_veronica_Mars': 0.564369261264801, 'receive_MacMall_Exclusive': 0.5217918157577515, 'havnt': 0.517998456954956, 'gfx_card': 0.5196627378463745, 'macbook_pro': 0.5703814029693604, 'droid_x': 0.5607396364212036, 'dell_laptop': 0.5578193664550781, "'ve": 0.5209441184997559, 'Arrendondo_cook': 0.5448468923568726, "I'v": 0.5355654358863831, 'lenovo': 0.5266544222831726, 'reinstall_XP': 0.537743091583252, 'wifi_adapter': 0.5497201085090637, 'havent': 0.5768314003944397, 'LOVE_YOU_ALL': 0.5329291820526123, 'haha_i': 0.5369561314582825, 'computers': 0.5202767252922058, 'automaticly': 0.523144543170929, 'hadnt': 0.5282260775566101, 'ive': 0.5156651735305786, 'google_docs': 0.5261930227279663, 'google_chrome': 0.5319492816925049, 'i_havent': 0.5323601961135864, "havn't": 0.593987226486206, 'mainframes_minicomputers': 0.5255732536315918, 'Ive': 0.518458902835846, 'cect_u##_china': 0.5316625237464905}
')
The following algorithm is used for classification:
- before vectorization, the too common ones are cut off from the set of words (both examples and user input)
- vectorization of the provided examples (in the vector example_i)
- on the basis of the coordinates obtained in the last step - the center of the cluster corresponding to the class is calculated
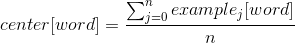
- vectorized user input
- we get records like [(class_name, length (input_vector - class_center)])
the resulting array is sorted by the distance between the cluster center and user input (thus, the first one is the class closest to the user input vector)
When testing with such data:
Classes -
{
'computer': ['I have a computer', 'You have a laptop'],
'dog': ['I have a dog', 'Have you a dog?']
} {
'computer': ['I have a computer', 'You have a laptop'],
'dog': ['I have a dog', 'Have you a dog?']
}Input - 'Do you had a dog?'
It turns out the following list:
dog 3.204362832876183 0
computer 3.577504792988848 0
dog 3.204362832876183 0
computer 3.577504792988848 0
Those. it is possible to determine what is entered closer to the dog class than to the computer.
PS about working with the Russian language - I mean that technically it is not a problem to assemble the word2vec model working with it. In general, there were even a few - but they seemed rather small (although, perhaps - suitable for practical use)
Source: https://habr.com/ru/post/304672/
All Articles