A little bit about improving database performance: Practical advice

/ photo by Ozzy Delaney CC
In 1cloud we talk a lot about our own experience of working with a virtual infrastructure provider and the intricacies of organizing internal processes. Today we decided to talk a little about database optimization.
')
Many DBMS can not only store and manage data, but also execute code on the server. An example of this is stored procedures and triggers. However, only one data modification operation can trigger several triggers and stored procedures, which, in turn, will “wake up” a couple more. As an example, cascading deletes in SQL databases, when the exclusion of a single row in a table changes many other related entries.
Obviously, you should use the extended functionality carefully so as not to burden the server, because all this may affect the performance of client applications using this database.
Take a look at the chart below. It shows the results of performing load testing of the application, when the number of users (blue graph) working with the database gradually increases to 50. The number of requests (orange) that the system can cope with quickly reaches its maximum and stops growing, while the response time (yellow) gradually increases.
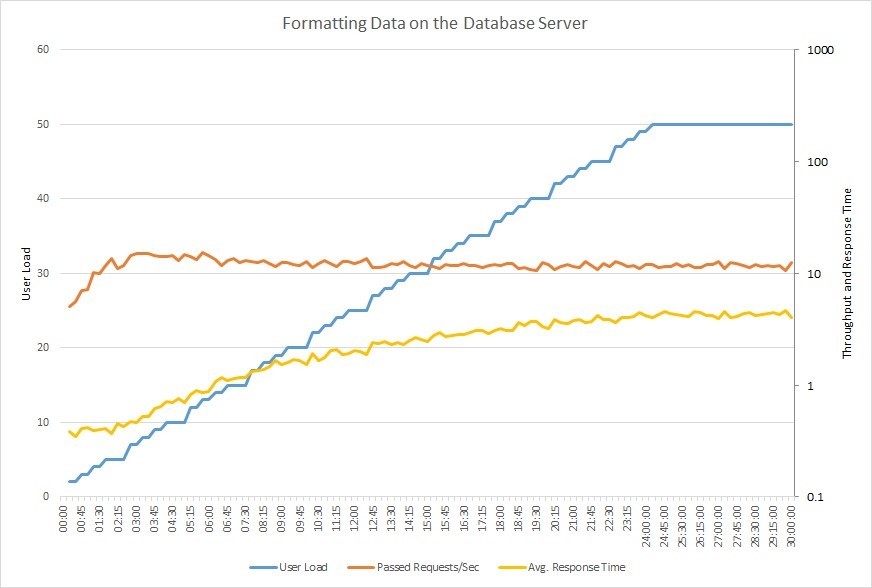
When working with large databases, even the slightest change can have a serious impact on performance, both in a positive and negative direction. In medium and large organizations, the administrator is engaged in setting up databases, but often these tasks fall on the shoulders of developers. Therefore, below we will give some practical tips to help improve the performance of SQL databases.
Use indexes
Indexing is an effective way to set up a database, which is often neglected during development. The index speeds up queries by providing quick access to the rows of data in the table, just as the index in the book helps you quickly find the desired information.
For example, if you create an index on a primary key, and then search for a row with data using the values of the primary key, the SQL server first finds the index value and then uses it to quickly find the row with the data. Without an index, a full scan of all rows of the table will be performed, and this is a waste of resources.
However, it should be noted that if your tables are “bombarded” with INSERT, UPDATE and DELETE methods, you should be careful about indexing - it can lead to performance degradation , since after performing the above operations all indexes should be changed.
Moreover, when you need to add a large number of rows to a table (for example, more than a million) at once, database administrators often drop indexes to speed up the insertion process (after insertion, indexes are recreated again). Indexing is an extensive and interesting topic, for which a brief description is not enough. More information on this topic can be found here .
Do not use cycles with a large number of iterations.
Imagine a situation where 1000 queries consistently arrive at your database:
for (int i = 0; i < 1000; i++) { SqlCommand cmd = new SqlCommand("INSERT INTO TBL (A,B,C) VALUES..."); cmd.ExecuteNonQuery(); } Such cycles are not recommended . The example above can be redone using one INSERT or UPDATE with several parameters:
INSERT INTO TableName (A,B,C) VALUES (1,2,3),(4,5,6),(7,8,9) UPDATE TableName SET A = CASE B WHEN 1 THEN 'NEW VALUE' WHEN 2 THEN 'NEW VALUE 2' WHEN 3 THEN 'NEW VALUE 3' END WHERE B in (1,2,3 ) Ensure that the WHERE operation does not overwrite the same values. Such a simple optimization can speed up the execution of a SQL query, reducing the number of rows to be updated from thousands to hundreds. Test example:
UPDATE TableName SET A = @VALUE WHERE B = 'YOUR CONDITION' AND A <> @VALUE – VALIDATION Avoid correlating subqueries
A correlated subquery is a subquery that uses the values of the parent query. It is executed line by line , once for each row returned by an external (parent) query, which reduces the speed of the database. Here is a simple example of a correlating subquery:
SELECT c.Name, c.City, (SELECT CompanyName FROM Company WHERE ID = c.CompanyID) AS CompanyName FROM Customer c The problem here is that the inner query (SELECT CompanyName ...) is executed for each row that the outer query returns (SELECT c.Name ...). To improve performance, you can rewrite the subquery via JOIN:
SELECT c.Name, c.City, co.CompanyName FROM Customer c LEFT JOIN Company co ON c.CompanyID = co.CompanyID Try not to use SELECT *
Try not to use SELECT *! Instead, you should connect each column separately. It sounds simple, but at this moment many developers stumble. Imagine a table with hundreds of columns and millions of rows. If your application only needs a few columns, there is no point in querying the entire table - this is a big waste of resources.
For example, which is better: SELECT * FROM Employees or SELECT FirstName, City, Country FROM Employees?
If you really need all the columns, specify each explicitly. This will help to avoid errors and additional database settings in the future. For example, if you use INSERT ... SELECT ... and a new column appears in the source table, errors may occur, even if this column is not needed in the final table:
INSERT INTO Employees SELECT * FROM OldEmployees Msg 213, Level 16, State 1, Line 1 Insert Error: Column name or number of supplied values does not match table definition. To avoid such errors, you need to prescribe each column:
INSERT INTO Employees (FirstName, City, Country) SELECT Name, CityName, CountryName FROM OldEmployees However, it is worth noting that there are situations in which the use of SELECT * is permissible. An example would be temporary tables.
Use temporary tables wisely
Temporary tables most often complicate the query structure. Therefore, it is better not to use them if it is possible to issue a simple request.
But if you are writing a stored procedure that performs some actions with data that cannot be processed in a single query, then use temporary tables as “intermediaries” to help get the final result.
Suppose you need to make a selection with conditions from a large table. To increase the performance of the database, you should transfer your data to a temporary table and perform the JOIN already with it. The temporary table will be smaller than the original, so the join will occur faster.
It is not always clear what the difference is between temporary tables and subqueries. Therefore, we give an example: imagine a table of customers with millions of records, from which you need to make a selection by region. One of the implementation options is to use SELECT INTO followed by merging into a temporary table:
SELECT * INTO #Temp FROM Customer WHERE RegionID = 5 SELECT r.RegionName, t.Name FROM Region r JOIN #Temp t ON t.RegionID = r.RegionID But instead of temporary tables, you can use a subquery:
SELECT r.RegionName, t.Name FROM Region r JOIN (SELECT * FROM Customer WHERE RegionID = 5) AS t ON t.RegionID = r.RegionID In the previous paragraph, we discussed that we only need to write in the subquery columns we need, therefore:
SELECT r.RegionName, t.Name FROM Region r JOIN (SELECT Name, RegionID FROM Customer WHERE RegionID = 5) AS t ON t.RegionID = r.RegionID Each of the three examples will return the same result, but in the case of temporary tables, you get the opportunity to use indexing. For a more complete understanding of how temporary tables and subqueries work, you can read the topic on Stack Overflow.
When working with a temporary table is finished, it is better to delete it and release tempdb resources than to wait until automatic deletion occurs (when your connection to the database server is closed):
DROP TABLE #temp Use EXISTS ()
If it is necessary to check the existence of a record, it is better to use the EXISTS () operator instead of COUNT (). While COUNT () passes through the entire table, EXISTS () stops working after finding the first match. This approach improves performance and improves code readability:
IF (SELECT COUNT(1) FROM EMPLOYEES WHERE FIRSTNAME LIKE '%JOHN%') > 0 PRINT 'YES' or
IF EXISTS(SELECT FIRSTNAME FROM EMPLOYEES WHERE FIRSTNAME LIKE '%JOHN%') PRINT 'YES' Instead of conclusion
Application users love when they do not need to look at the download icon for a long time, when everything is working clearly and quickly. Using the techniques described in this material will allow you to improve database performance, which will have a positive impact on user experience.
I would like to summarize and repeat the key points described in the article:
- Use indexes to speed up searching and sorting.
- Do not use loops with a large number of iterations to insert data - use INSERT or UPDATE.
- Avoid correlated subqueries.
- Limit the number of parameters of the SELECT statement - specify only the necessary tables.
- Use temporary tables only as “intermediaries” to merge large tables.
- To check for the presence of a record, use the EXISTS () operator, which terminates after determining the first match.
If you are interested in the topic of database performance, then there is a discussion on the Stack Exchange in which a large number of useful resources are collected - you should pay attention to it. You can also read our material about how large world companies work with data.
Fresh materials from our blog on Habré:
Source: https://habr.com/ru/post/304642/
All Articles