Standardization of records

I would gnaw a red tape like a wolf!
Vladimir Mayakovsky
Consider in this article the problem of standardization of records. Standardization is primarily needed when importing millions of records that have accumulated over the decades. Data that has different encoding of pages from different automated systems is collected into a single database of the information system. In this case, the appeal to the functions of reading lines on ascii, such as QRchar, does not justify itself, since the Unicode format is different from one record to another. In addition, Cyrillic in words is often mixed with numbers and Latin (for example, when '4' is written instead of 'h'). In this case, a direct cyclic replacement of numerals and Latin for Cyrillic in a line is impossible, since the numerals with Latin are found in the notation.
User directories allow you to track and record patterns of incorrect spelling of certain fragments, indicating what to change them in the overall cycle. According to the reference book of endings, one can recognize a part of speech, and by part of speech, determine the algorithm for moving a word in a line to be reduced to a template form.
')

I often encounter a similar problem when organizing thousands of records that I receive after scanning.

If you do not get rid of the unfinished format of records, defective sorting will slow down the work several times.
If the data should remain intact, I suggest using a utility that only changes the display of records.

In the intermediate tables based on MS Access, as an option, using the ADO technology, we place the same data of two types. Records are moved from the ApEx report received to the work to the backup intermediate pre-cleared ADOTableReserve table when executing a query or looping through, which is described below. We reserve in untouched form in one table ADOTableReserve. We determine the number of i_RecordCount rows and i_ColumnCount columns, as well as the column number i_String, which contains ApEx report entries to be standardized:
openDialog := TOpenDialog.Create(self); openDialog.Filter := '*.xls;*.xlsx|*.xls;*.xlsx'; if openDialog.Execute then begin ApEx := CreateOleObject ('Excel.Application'); try ApEx.Workbooks.Open(openDialog.FileName,0,true); ApEx.DisplayAlerts := false; openDialog.Free; except showmessage (' !'); end; ApEx.Workbooks.Close; ApEx.Application.quit; ApEx := Unassigned; openDialog.Free; end; for i := 1 to i_ RecordCount do begin begin ADOTableReserve.Append; for c:=1 to i_ColumnCount do begin ADOTableReserve.FieldByName('a'+inttostr(ColumnCount)).AsString:= Ap.ActiveSheet.Cells[i, ColumnCount]; end; ADOTableReserve.Post; end; NB: FieldByName passes information about the column number in MS Excel report.
In another table ADOTableDebug we reduce these entries to the template writing. Data from ADOTableReserve is moved to the previously cleaned ADOTableDebug debug table by the same principle, but with reference to the Pattern () function:
ADOTableDebug.FieldByName('a'+inttostr(ColumnCount)).AsString:= Trim(AnsiUpperCase(ADOTableReserve.FieldByName('a'+inttostr(ColumnCount)).AsString)); if ColumnCount = i_String then Pattern (); NB: The Pattern () function refers to a series of user directories and results in entries to a template form.
If the situation requires comparing records with their template writing, then the utility is supplied with a corresponding intermediate table list of templates in the utility that stores these templates:
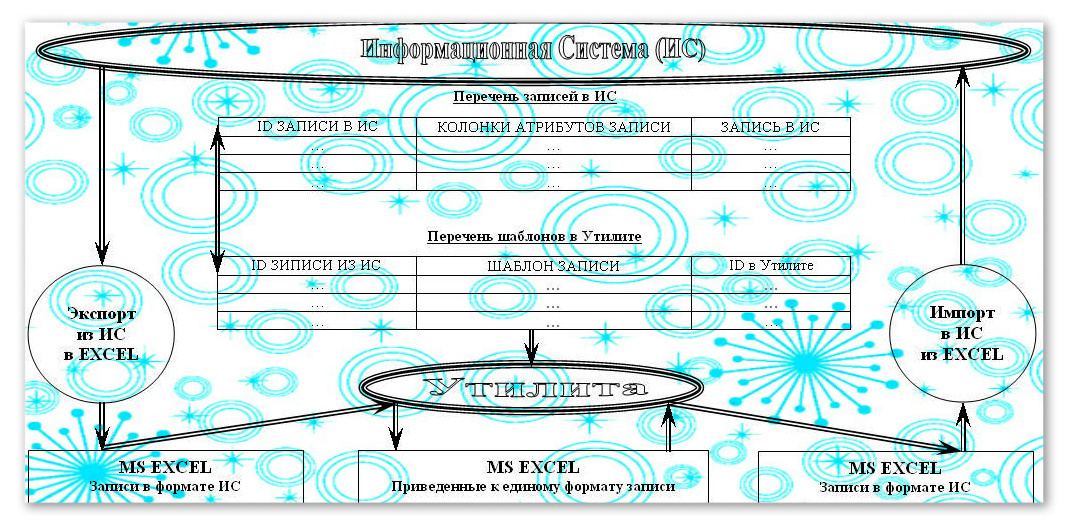
Otherwise, we determine the nouns in the directory of endings and put them forward. We change the nouns and Latin to Cyrillic. The remaining words in the entries are converted to upper case. We display both tables in screen form. We carry out the ability to sort records in the grid by clicking on the column header. We use the index search function of the active record in one table to quickly jump to the same record in another. We analyze the data, form a report in MS Excel format for further work with the data, give the report to work with the records of the template form. The report is supplemented by comments in the working columns. If necessary, add comments to the Information System database using the algorithm described above in the ADOTableDebug table and find the lines corresponding to the records in MS Excel format. The row identifiers of the intermediate tables ADOTableReserve and ADOTableDebug are the same. Update the ADOTableReserve table with comments from the ADOTableDebug table. Returning to the original form of the records, we create a report in MS Excel format for importing comments into the Information System database. If a report in MS Excel format, supplemented with comments in the working columns, can contain identifiers of rows of the Information System, then the records are not retained to their original form. Then, to import comments into the Information System database, we transmit a report with sample spelling of words.

When it is possible to reach agreement on the replacement of all records in a single database that is updated in client-server mode at the same time, then the most interesting part begins - a collective refinement of user directories used by the Pattern () function, which allows you to standardize records.
Source: https://habr.com/ru/post/304576/
All Articles