Very simple and fast HTML-> TEXT

Everyone has seen the html file viewer in TotalCommander. I got an idea to write a simple and very small text browser for my operating system. At first, I looked in the direction of asm-xml - an excellent parser, but well, very big (my limit is 64 kilobytes, not technical, just the principle). The following describes a very simple way to get text from html.
')
At once I will make a reservation that I need the code to be independent, (for my OS), therefore all ready-made libraries disappear immediately. Why assembler? - just because everything in my OS is written on it. But the method can be moved to any language ...
So, since the small size of the code is important - I decided to abandon the classical parser with the construction of the tree, by parsing the hierarchical structure. I went to the forehead.
Actually, the process consists of several stages.
First you need to get rid of the contents of the script tags - only those where the code is written directly, and not where external scripts are connected. Why? I just came by experience when I discovered that some very large scripts break the logic of my parser)
Next comes the main loop. Step by step (more precisely, byte by byte) we go through all the tags (we are looking for opening and closing the tag). Those. we end up with not a tag tree, but a list consisting of strings prepared with dword headers.
If the text does not fall under the tag - then write it simply as text.
The structure of the temporary looks like this (the headers are highlighted - tags designation):
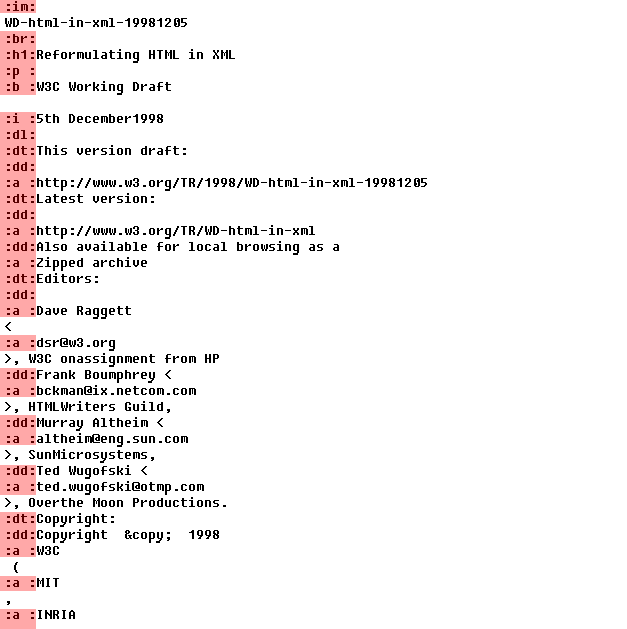
I will explain the moment. It would seem more logical for each tag to give the corresponding hash or identifier. But, for this you need to parse all kinds of tags, for example: <p and <p style = ... - you need to check separately. And we have the same - just pass to the file with the comparison through each byte of four bytes:
inc esi
cmp byte[esi + 0], '<'
If this is the opening tag, then <p class ... turn into: p:
This, of course, is laziness, govnokod, etc., but it is quick, short and effective!
Well, then we actually take the resulting list and line by line, depending on the type of tag, we return for processing the corresponding processing procedure, which is already written to the output buffer. (There are more aesthetic trifles - we remove the repetition of gaps, hyphens, etc.)
I look forward to comments like: “govnokod”, “learn materiel”, etc. Therefore, let me say straight away: the code (at the end of the article is a link) is just a prototype written “on the knee”, and about the “algorithm” - I agree, it is difficult to call it an algorithm, but it works! Only 4Kb program!
According to the link, a working example (also checked on the source code html of the main page of the habr - the screen below) - everything works. The only thing is that the file size is limited (I just didn’t add memory allocation yet, I use 3 64 KB of uninitialized buffers). After work, the program will issue two files - in one list a temporary one, in the second - the finished text. Note that in the text hyphenation is 0x0A, so we are looking at TotalCommander in text mode.
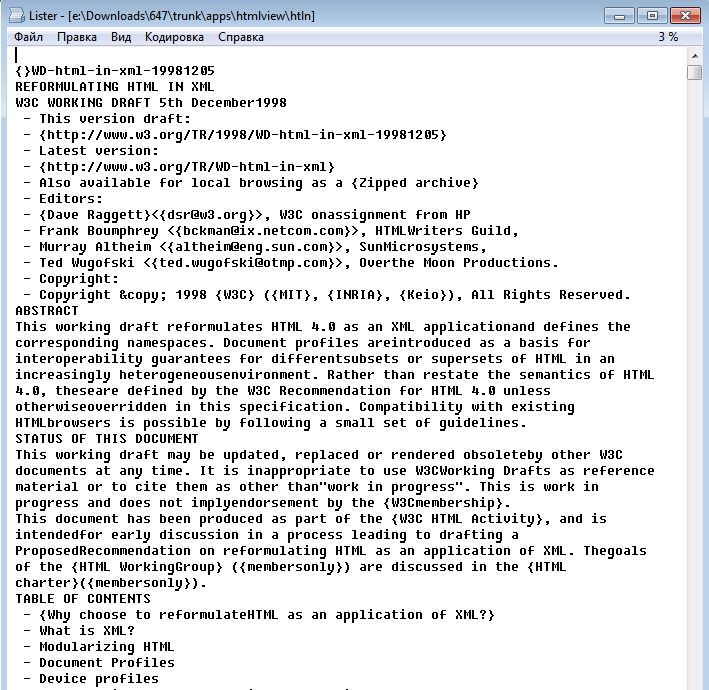
Test on W3C Reformulating HTML in XML:
Test on the main page of Habrakhabr:

Source code + win32binary
And now the question: who will get less than 4Kb?
Source: https://habr.com/ru/post/304428/
All Articles