Azure Service Fabric: Second Steps

Charlie Chaplin again in the factory in the film "New Times"
Continuing the conversation about Azure Service Fabric. In the previous article, I mentioned plans to write first about stateful services, and then go to the model of actors in ASF. The concept has changed - I thought that it would be nice for examples to use, if not a production-solution, then something close, so that there would be a theoretical advantage and practical meaning. It is possible to combine all the components of ASF in one bottle - so that the cows feed, and the amusement park, and Winnie the Pooh and everything. It was with such thoughts that I went to the cemetery of home projects in search of a candidate for animation.
The living Dead
And there was such a candidate. How they like to write in “iron” articles, “digging into the boxes with spare parts” fished out the once-unfinished library of working with the Advanced Direct Connect protocol. “It’s awful, terrible inside”, however, having cleaned the dust with a file, he was convinced that life was still warm inside. The library was once intended for an unwritten ADC client, but why not write an ADC hub based on it? Here is an idea, fresh and original - you can try.
The ADC protocol appeared more than 10 years ago, in 2004 (the latest version 1.0.3 in 2013) as the successor of NMDC (it’s also just DC). As in NMDC, ADC network nodes exchange simple text commands. There are only two types of nodes - this is the central node (hub) and end clients that join the hub and each other. Through the hub, clients can chat (chat) and search for the necessary files, while data transfer is carried out directly between clients, bypassing the hub. Roughly speaking, the hub serves to authenticate clients, store their list and send commands between clients. The only existing transport I know is TCP, adc: // addressing scheme, the port is not defined by the standard, but in practice the usual DC 411 is used. Clients have their own Private ID, but more importantly, each connected client is first issued a SID (session identifier) by which his (client) and other clients.
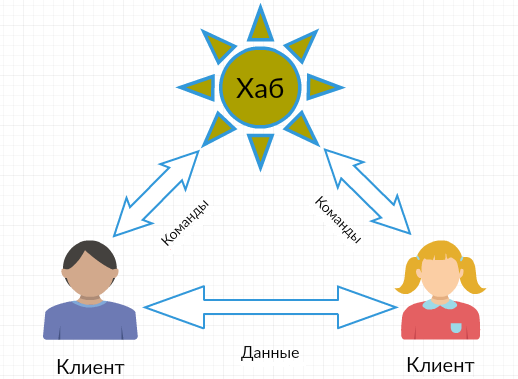
Typical P2P connections are valid for ADC
The protocol is extensible - you can add both completely new commands and parameters to existing commands. The list of supported features each hub / client is announced when establishing a connection. Mandatory support for basic ADC features for the hub and client, plus TCPx / UDPx for the client for file sharing. Extensions are quite a powerful mechanism for increasing the capabilities of the protocol - for example, extensions include both a few additional hashing functions (the coordination of the function used is in the basic capabilities at the client-hub connection installation stage) and the secure ADCS connection.
With regard to the current state of affairs, then, oddly enough, the P2P area is still alive (of course, I do not consider torrents that are always well-known). Both hubs and heirs of StrongDC ++ (I used to use this client myself) are still being developed, so the problem to be solved has not completely lost its applied meaning, going into the category of academic ones.
Unfortunately, the ADC specification leaves room for imagination - not exactly “the music for the game is written by professional programmers,” but also, say, RFC accuracy or W3C standards are far away from it. Because of this, along the way, we had to clarify the details of the existing ADC implementations (ADCH ++, AirDC ++, etc.).
Model to build
I will begin, as usual, with a general architectural estimate. For simplicity, the hub will be open, that is, users can log in without registration and passwords, but their names must be unique. As you go, you can see three logical parts of the overall picture - this is a TCP connection server, then objects that implement ADC to exchange with clients, one for each client (I will call them users) and, finally, a general catalog of all active clients.
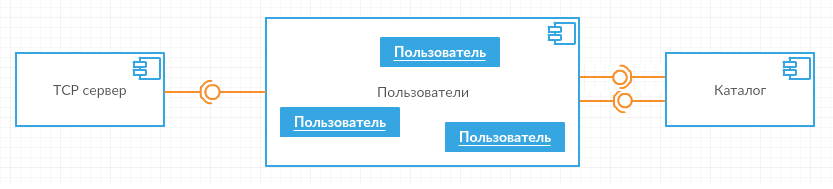
The TCP server will establish TCP connections and exchange serialized ADC messages with the client, users are responsible for correctly implementing the protocol according to the specification, and the catalog has the task of maintaining a list of active clients (including issuing their identifiers) and broadcasting messages. Here from this stove and I will dance.
Snapping to the terrain
Now each logical part must find a match among the components of the ASF. The main limitation is the minimum of the self-written code and the maximum of the existing capabilities in ASF.
TCP server
The TCP server does not have a status and needs one instance on each node of the ASF cluster - obviously, this is a stateless service (described in the previous article, so I will not repeat).
Users
I will try to entrust the exchange of ADC teams with clients to the actors .
Actors
The model of actors (actor model) appeared, oddly enough, from the scientific community (however, in 1973, for the then computer science, this is not surprising). According to this model, an entity is called an entity, which (as a rule) has a state, functions independently of other actors, can asynchronously send and receive messages, as well as create other actors. The aggregate (or system) of actors can unite actors of different types. For a message exchange, each actor has a special address (usually, numeric or text). It is important to understand that all the actors operate in parallel, the message exchange is asynchronous, but the processing of these messages goes sequentially - the actor is “single-threaded”, serves as a synchronization point and processes at most one message at a time.
This speculative model can be implemented differently - I am aware of three implementations of the actors Akka.NET , Orleans and ASF actors. In Akka.NET, the creation of an actor, its deletion from the system, and sending messages to it are explicitly highlighted. Akka.NET actors form a hierarchy, so that “parents” can follow the behavior of “children.” In Orleans and ASF, they chose a different path - they adopted a flat model of distributed virtual actors , in which all actors always exist, but until the first call in an implicit state. When called, the actor is created and then its state is maintained between reboots. Asynchronous message passing is modeled by C # interface calls, and for complete “galvanic isolation” Orleans contains persistent Streams that implement Pub-Sub. There is no ASF Streams, but there are actor events that you can also subscribe to. And (as in Akka.NET) there is the removal of the actor and the clearing of its state - after the removal, the actor goes back to the “world of shadows” before the next call. As you can see, in all implementations there are both similar and different features.
Oddly enough, quite often the question is - how does an ASF actor differ from an ASF service? See for yourself - a service instance is created once at the cluster start, then it works until the ASF stops or restarts, it has external and / or internal communication points. Actors instances are created and deleted by external queries, and their number is limited only by the physical capabilities of the cluster. Therefore, if it is necessary to implement a collection of objects (possibly of different types), which should dynamically change in the course of work, these are actors. If you need to create a known number of objects in advance, especially if these objects implement external communications or internal functionality, these are services. And it is important to remember that the actors process calls to them sequentially, and services in parallel.
User Directory
Coming back to our components - for the directory of active clients it is logical to choose a stateful service.
Stateful services
In short, stateful services are the same as stateless, but with state. And indeed, their life cycle is similar - the same OnOpen, OnClose and RunAsync. There are also listeners for communications, ASF Remoting, etc. is also possible. However, the presence of the state introduces noticeable differences. First of all, there are differences in terminology - if it makes sense for stateless services to talk about instances, then stateful services have replicas. Replicas are combined into replica sets (replica set), each set of replicas has its own state, independent of the other sets in this service. In each set, only one replica is primary, and the rest are secondary — only the primary replica can change the state (and only for it the life-cycle functions are called), all other states only read. If the service is partitioned, then each partition is such a set of replicas and, accordingly, has its own separate state. Both partitions and the number of replicas in them are set — again, as for stateless services — through the application configuration. In the event of a primary replica falling down, one of the secondary ones assumes this role, therefore, for reliability, the ASF scatters all the replicas of one set across the cluster nodes, and the state of the service is replicated between the nodes. Only objects originating from the IReliableState interface can be stored. By itself, the interface resembles a marker; it is impossible to implement it properly, so out of the box there are actually only two reliable objects: ReliableDictionary and ReliableQueue (dictionary and FIFO queue). You can use transactions to synchronize changes in several reliable-objects.
Total goes:
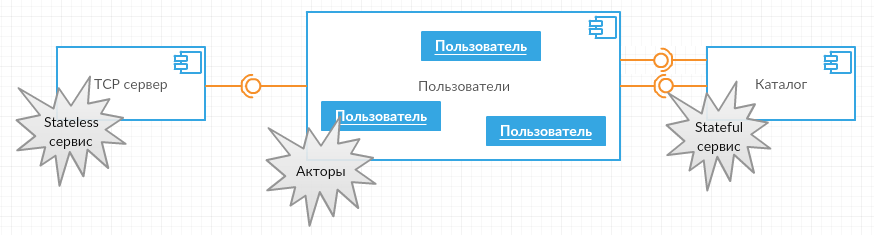
The devil is in the details
Brainstorming is over and it's time to move on to the implementation of all the above. Here I will try to avoid going into technical details, limited to a general description and subtle places; if necessary, an inquisitive reader can refer directly to the source code (there is a link at the end of the article).
So, in order.
TCP server
For a TCP server, you can use standard TcpListener / TcpClient, which is wrapped in a non-standard TcpCommuncationListener. TcpListener runs on OpenAsync, stops on CloseAsync. and the TcpCommuncationListener itself is created in CreateServiceInstanceListeners.
In the configuration there is a small detail - for local debugging in Local.xml I put
<Parameter Name = "TcpServer_InstanceCount" Value = "1" />, and in parameters for Azure will be
<Parameter Name = "TcpServer_InstanceCount" Value = "- 1" />This is because the nodes of the debug cluster run locally on the same computer and cannot divide the 411 port among themselves; therefore, only one instance of the service is needed. '-1' means that one instance of the service must be running on each node of the ASF cluster — in Azure, the ASF nodes are located on different VMs and each has its own 411 port.
How to contact the right actor and what is his general address? This will be discussed further in the implementation of actors, but for now the first problem (however predictable) is the installation of a TCP connection, which created an instance of TcpClient, tightly pinning it to the cluster node with which the client connected. The actor can move through the nodes, but it is easy to call him - he is addressing, but how to call TcpClient from the actor? After all, messages must be both received and sent. Through the stateless service itself it is impossible - it is not known which of the instances of the service is the desired TcpClient. And then the events of the actors come to the rescue - TcpClient can subscribe to the events of “its” actor and receive outgoing messages through them (I would prefer streams, but I try to do what is).
Users
The actor has only two functions - to receive and process the next message, and send a message to the client. Nevertheless, this is the most confusing part of the hub, since it is up to the actor to support the protocol. Not the binomial of Newton, but there is also something to think about. First you need to choose what to address the actor. In the protocol, the client addresses the SID that is issued by the hub - why not use this SID as the address of the ASF actor? Further, the ADC assumes four protocol states for the hub - PROTOCOL (negotiation of connection parameters), IDENTIFY (client information), VERIFY (password check), NORMAL (normal operation). Since the hub is open, there are no passwords and VERIFY is not required. And since the actor in ASF is virtual, it makes sense to add the state UNKNOWN for an actor who seems to be alive, but still / is not connected anywhere.
As soon as there are states, the state machine immediately appears - the incoming ADC commands will be processed by the current state and serve as triggers for the transition between states. ASF is asynchronous through and through, so the state machine needs asynchronous. The search for ready-made libraries produced not so many options. Stateless behind the authorship of the notorious Nicholas Blumhardt (he is the author of Autofac and Serilog) and Appcelerate (nee bbv.Common) were considered as applicants. Both did not fit, because they are perfectly synchronous. There is also an asynchronous heir to stateless LiquidState , but it was not suitable for lack of functionality. I really do not like to write bicycles, but then I had to, it is easy. Based on the description of the UML State Machine (by the way, I recommend - this is a good formal model, including machines Miles and Mura).
In this part of the development problems arose as many as two. The first and main thing is the “one-threading” of the actor. Formally, this means that it is possible to call another object from the actor, but from this call, the actor cannot be called back. In fact, ASF does support the actor's reentrancy , but only if the call chain started from him. Moreover, such a resolution only concerns calls between actors - to call, say, the service from the actor and call the actor back again is impossible. And such functionality is needed, for example, for broadcasting, which the actor initiates, and executes the directory, and the message must go away to the newsletter himself. I did not find a good solution, so I simply divided the actor into two parts - one main, receiving messages from the client and managing the state of the actor, and the second additional one, which simply sends messages to the client. As a result, we have two actors, through which unidirectional data flows go. The types of actors are different, so you can address them equally through the SID (in ASF, the type of actor is in its address, so even for identical SIDs, the addresses of the actors will be different).
The second problem is the connection setup time (in terms of ADC, this is a transition to the NORMAL state). It makes sense to limit it, and the situation is aggravated by the fact that the progenitor DC uses the same port, and the hub sends the first message to DC. As a result, DC clients, having connected, will wait for a response before the second coming. It's time to apply timers and reminders ASF.
Timers and Reminders
Timers and reminders in ASF are, as their name implies, alarm clocks. They are similar, but only in that they call specified functions according to specified intervals. The timer is a more lightweight object that exists only with the active actor, and disappears when the actor is deactivated. The reminder is stored and works separately from the actor, so that it can even activate the deactivated actor. The calls of the actor's methods for timers and reminders, like all the others, are performed all the same “in a single thread”, but the call from the reminder is considered a “full-fledged” call, which is taken into account when deactivating inactive actors. A call from a timer using an actor is not considered, so it is impossible to keep the actor from deactivating with a timer.
To limit the connection time, the easiest way is to use a one-time reminder, who sends a pseudo ADC command ConnectionTimedOut - the NORMAL state simply swallows it, and all others will break the connection according to the protocol.
User Directory
The service does not have external communications and is intended solely for performing internal tasks, so it is logical to use Remoting to communicate with it. There is no special reason to partition the catalog - the state of the service stores a collection of identifiers, and the service itself implements operations on it as a whole. However, broadcasting can create a load for which one primary replica of the service may not be enough. And here you can take advantage of the curious feature of stateful services - they can open listeners even on secondary replicas, but only for reading. Since mailings in the state of the directory do not change anything, nothing prevents them from using all the replicas of the service.
The list of current SIDs is stored in the ReliableDictionary dictionary - it can be enumerated as part of a transaction, and information about the user (name, supported client capabilities, etc.) is stored in the key values. A separate ReliableDictionary must also be used to verify the uniqueness of the client's name — simply as a unique key with no values. There was no specific rake in the development of the catalog, but there is a nuance associated with disconnecting the client.
There are only two reasons for the client to disconnect - this is an error in the communication channel (the source is a TCP server) and an error in the protocol (the source is an actor). Both errors will be considered fatal and break the connection with the client. I would like to handle errors in a centralized way, and it is logical to do this in the actor, as responsible for the protocol. To do this, you can do the same as with the reminder - add another pseudo ADC message DisconnectOccured and include it in the state machine of the actor. For a full cleanup, it would be good to completely remove the actor, but how to do this if the actor is the initiator of the shutdown? This functionality can be transferred to the directory in which to use ReliableQueue — the SID of clients to be disconnected is added to this queue, and in the RunAsync catalog this queue is processed in an infinite loop that receives identifiers from the queue and deletes the corresponding actors.
Here is such a state:
And in general, development has come to an end. In testing on a local cluster, two ADC clients (I used AirDC ++) connected to the newly-baked hub “saw” each other and were able to exchange files. Still not a bang, but you can already try to deploy a hub in Azure.
Deploy to Azure
The most boring part of the story, since the deployment went like a note. For deployment I used Free Trial subscription, ASF control is available from the new portal . First, the cluster name, RDP user data, resource group, and location are selected. For the number of cluster nodes, I chose three, because “Choosing less than 5”, I could not find out what a test cluster is, but the portal itself writes this recommendation. In custom endpoints, you need to remember to put 411 so that the load balancer will let connections through this port. For test purposes, it is easier to create an unsecure cluster - that's basically it. Despite the apparent simplicity of the ASF cluster, Azure creates a whole range of resources:
The list includes vhd storage for VMs (it's unclear why there are 5, not 3), storage for Azure Diagnostics logs and information, a set of virtual machines that are connected in a VPN, and covering all of this load balancer with its public IP address.
Deploying to Azure did reveal one problem that I left unresolved. It seems that Azure checks the availability of port 411, creating and immediately terminating TCP connections over it. The TCP server immediately after the occurrence of the connection creates a SID, which immediately turns out to be unnecessary. Theoretically, this is the correct behavior - the server may be full (in the ADC there is a limit on the number of users for one hub), but in practice this approach fails. On the other hand, for simple testing, these empty connections are too frequent - in general, while this is a mystery covered in darkness.
However, this does not affect the functioning, so again the test, again two ADC clients, again file sharing - everything seems to be working. Now, absolutely cheers.
Conclusion
In general, the idea justified itself - it was possible to walk through the entire ASF, and if not use it, then at least get acquainted with the various possibilities and details of its functioning. And although not everything went smoothly at ASF, the end result is not so bad for a test project. I hope that the readers were curious. The source code of the entire project can be found on GitHub - we say goodbye to new articles.
')
Source: https://habr.com/ru/post/304236/
All Articles