Creating a library search by a young programmer - what is it?
The other day I came across a publication by my peer , and she prompted me to write my own story about my project, which absolutely did not help either, but only prevented me from entering the university.

One fine day I went to the library for one story. Having said the title and author of the story to the librarian, he received a stack of collections of this author. In order to find the necessary story among all this variety, we had to go through all the works. It would be much easier to “google” the desired work and get what you want in a few clicks.

')
And then I thought: “Why is there still no such thing in libraries? It's so convenient! ”. Naturally, like any decent lazy programmer, I went straight to the search engine to look for similar projects. And ran into problems. All found projects were either commercial (paid), or amateur and low-quality.
Naturally, such an injustice urgently needed to be addressed, despite the approaching USE and admission to the university.
First of all, it became clear that we cannot do without a web part. Despite my personal intolerance to web programming, I sat down with Google and began to study this issue.
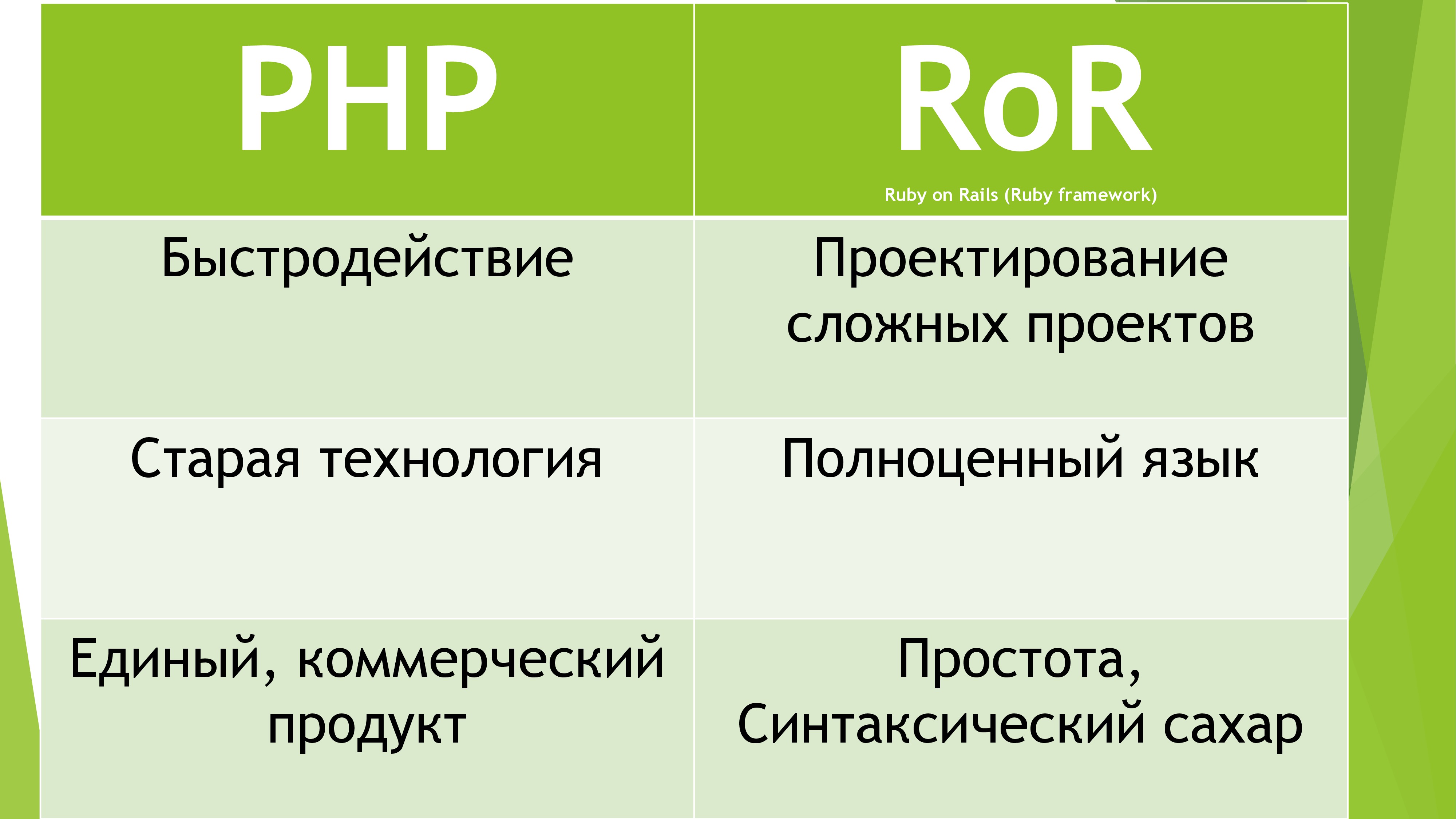
After a few hours, I finally chose the required language. More precisely not a language, but FrameWork RubyOnRails. Why he? Because it uses a full-fledged OOP language, is actively developed by a giant community and has a fast core. In addition, girls like Ruby (it is better not to speak at the presentation).
Naturally, it was based on the “beautiful” language of Ruby. Since I know Java at the Junior level, it was easy for me to learn any other OOP language. Every week I watched 2 lectures every evening and in the end could boast the necessary knowledge of Ruby syntax. And then my self-confidence was dropped ... And all because this FrameWork is so huge and extensive, that the knowledge of Ruby helped me only a little bit. Having studied the MVC technology and other ideas of the evil web programmers, I started to implement the project.
The first obstacle in my path was, oddly enough, authorization. I decided to use OAuth technology. Its principle is that tokens are used instead of passwords. Using tokens allows you not to worry that your password will be stolen, as well as to configure each token for yourself (for example, you can take one-time tokens with permissions for only one operation). At first I decided to use MD5 encryption to store passwords on the server side, but after reading about it on the Internet, I decided that this method was outdated. Hacking on new computers is carried out in just 1 minute. Therefore, I decided to use bCrypt, which provides almost 100% protection against password decryption in the database. Since I decided to make a similar system myself, I had to think about optimization. First of all, the tokens had to be transferred from a string to a numeric value, so that a DB could be searched for by a binary search.

It would seem that the complex can be in the simplest school project with authorization? Let's start with the fact that the authorization window I did for 20 hours. And let's continue with the fact that my project is completely OpenSource and runs on the local network, which means that it is enough to deploy your server on the mobile in order to intercept the tokens. Therefore, I came up with my own server validation system. With each token, the server returns two values. ID in the database and a unique small identifier. Every time a client wants to check the validity of the server, he sends the ID to the server, and the server returns the identifier to him. And only then the client sends a token to the server. It turns out the authorization from two sides.
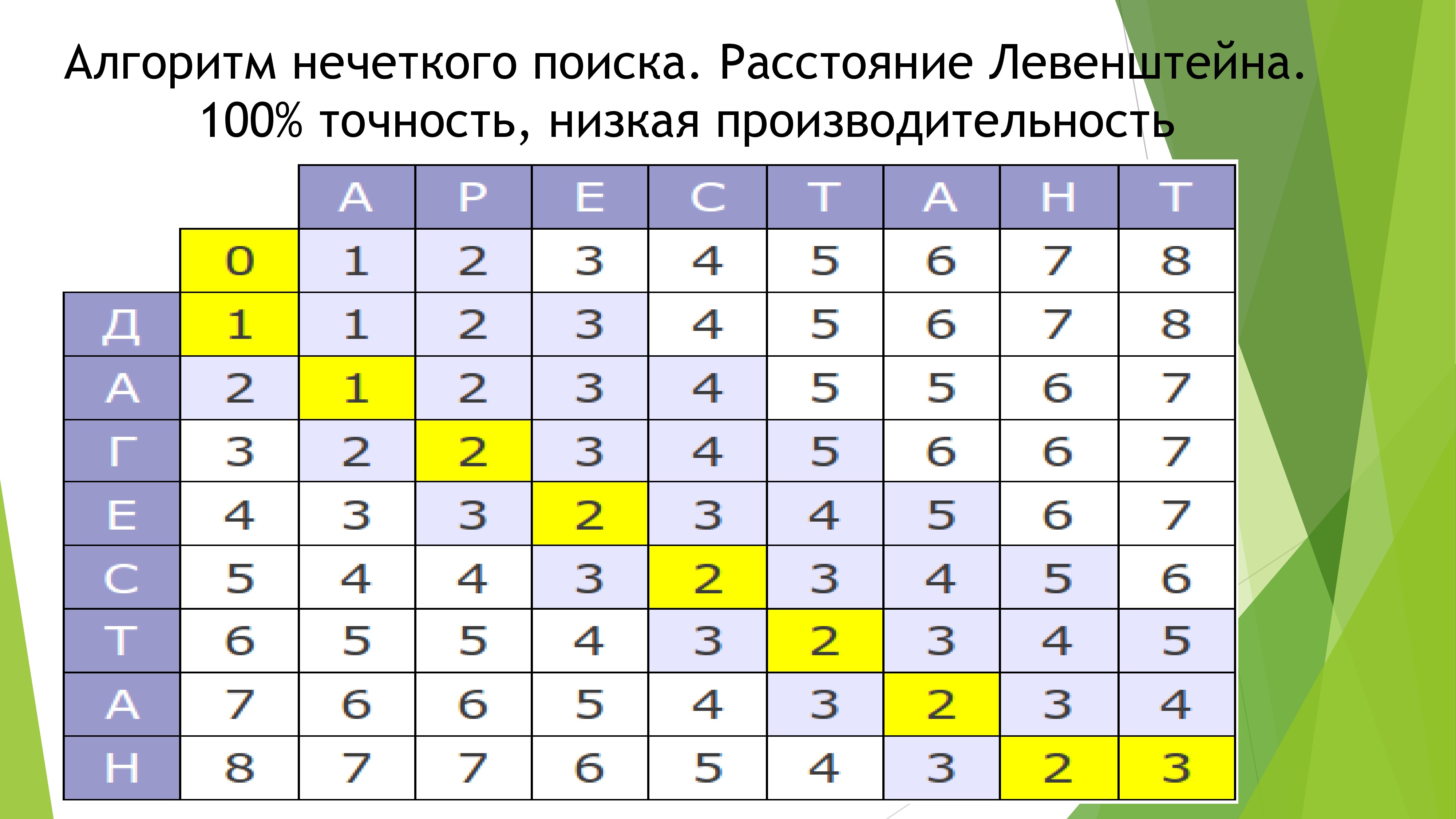
In all such projects, the weak side is search. I would not want such a flaw to be present in my project. The use of ready-made solutions is completely dismissed due to the fact that all large search engines require an Internet connection. Therefore, I approached this issue with all seriousness. After reading the book about algorithms, I decided that it is better to use the Damerau-Levenshtein distance algorithm for comparing lines, since it has maximum accuracy at the expense of performance, which is most important for the project. But there was a problem comparing whole sentences. First, I used a similar algorithm, spreading the comparison table on a tree of graphs. For a long time I was tormented by this, but in the end I got the wrong result. Therefore, all demolished and inserted another algorithm in the comparison of sentences. His principle is simple to madness. If the word has less than 3 errors, take it for the correct and add 1 point to the final index. If two correct words go in a row, add another 1 point. And so on.
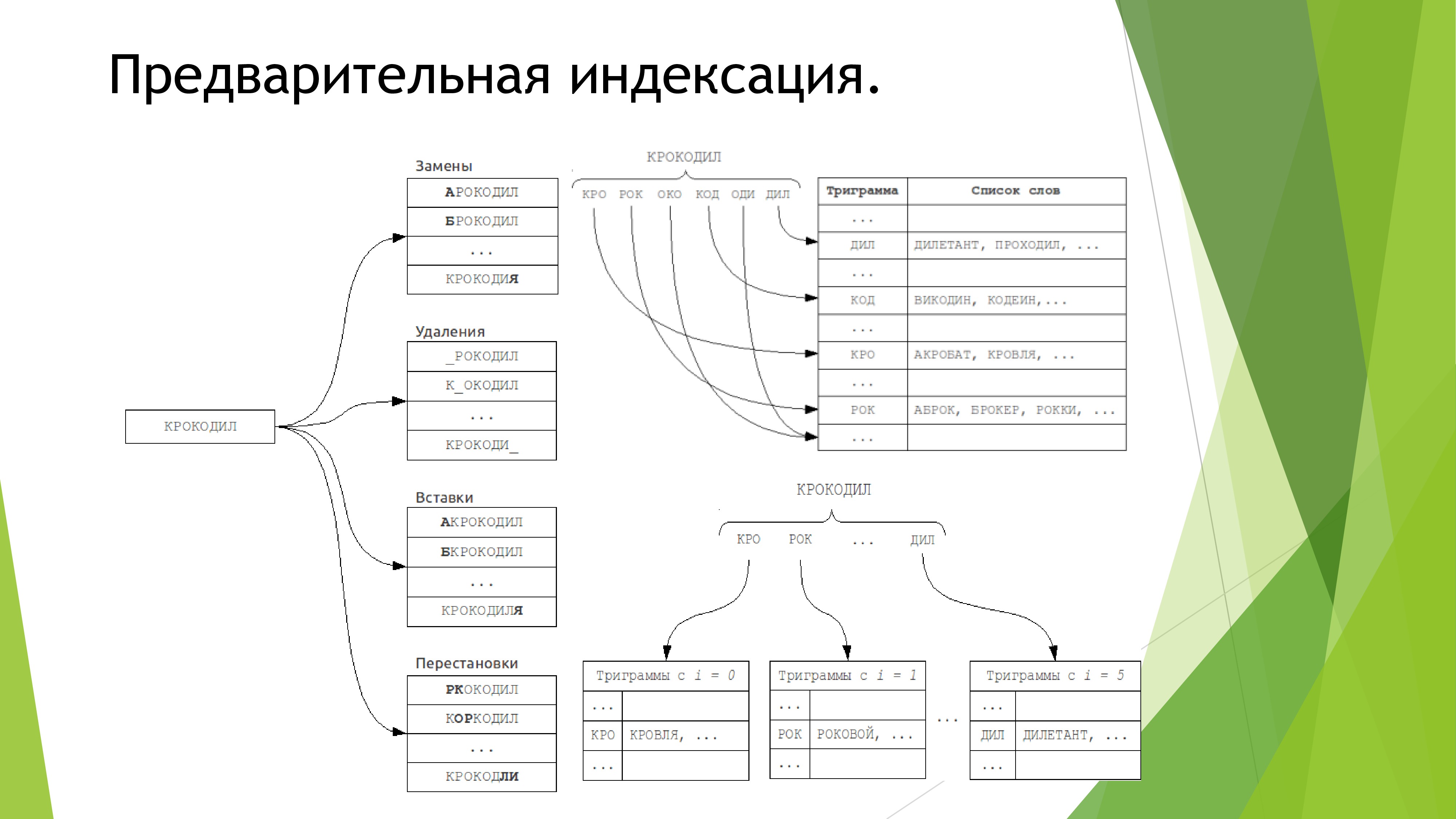
Since the search is very hard set, use the syntactic meaning of the sentence does not make sense. Therefore, in the future we plan to add a phonetic search and continue to work towards improving the self-learning system and centralizing all data.

Another way to improve the quality of the search was self-study. The fact is that each request is recorded in the database and, if necessary, it is possible to issue add points to popular books. Let's say the user “Gosh” loves fiction. We understood this by the fact that the number of books found on fiction far exceeds other genres. Therefore, afterwards, when the search results are displayed, the search system will add additional points to the user of Gosh for books on fiction. In addition, such a large amount of statistical research is useful.
Naturally, this algorithm then acquired various optimizations, but more on that another time. I decided to implement such a resource-intensive algorithm in C ++ and make a bridge from Ruby using the Rice plugin. Here is another illustrative example of why I chose RubyOnRails and did not regret it.
To solve the problem of fast library digitization, only the text recognition mechanisms in the picture will help. Since it is rather stupid to bring the image to the PC webcam for reading, it was decided to develop a mobile application for smartphones. Writing the base application took about a week because Smartphones actively use multithreading and fairly stringent criteria for application design.
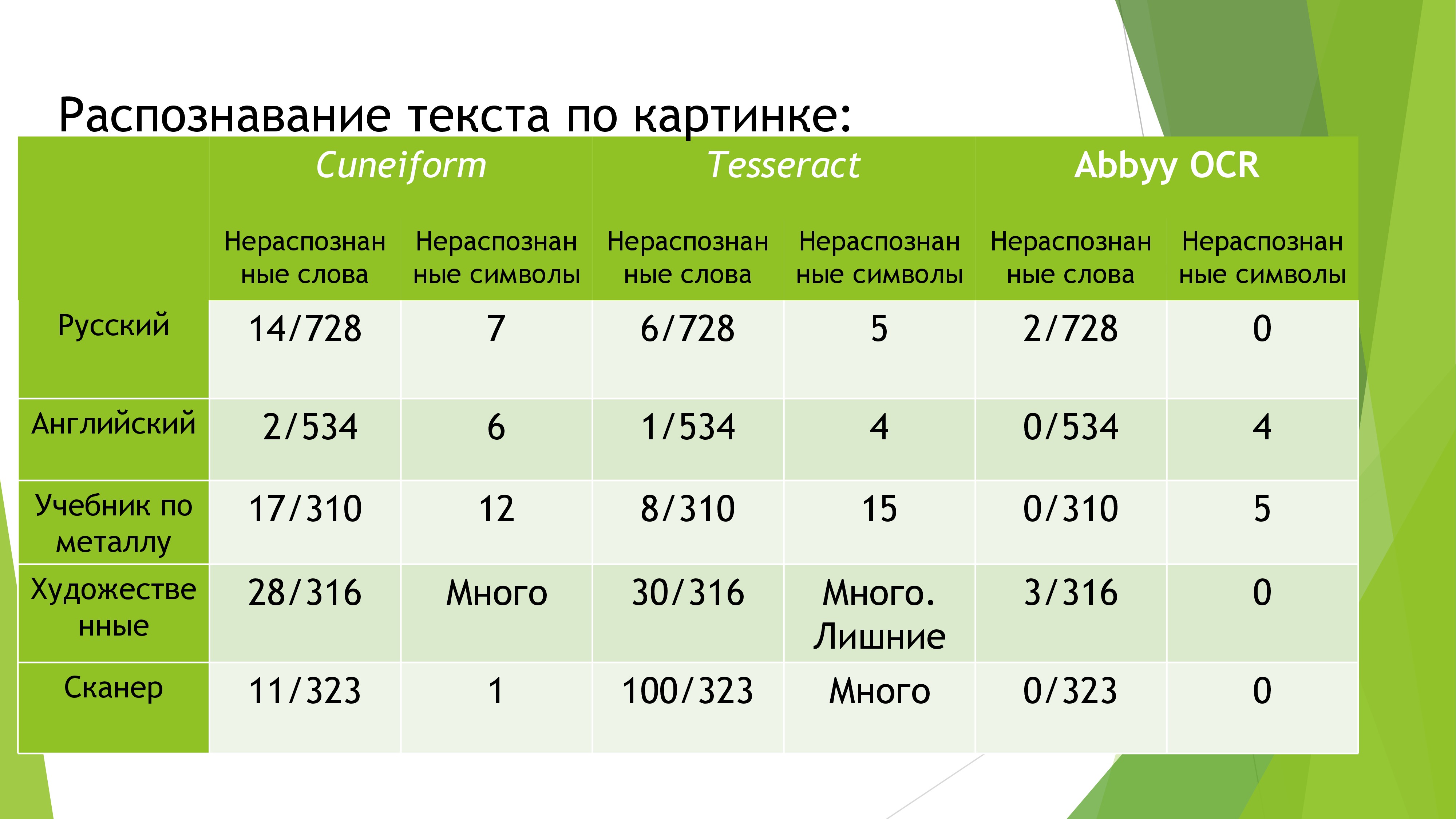
After doing a deep analysis of existing solutions, I chose Tessaract as the best free open-source product based on OCR technology. In addition, actively supported by Google. Having tried to play with him, I realized that such a result is no good. For accurate recognition, you would have to work with image preprocessing for quite a long time. In addition, in the source code of this project, I found a couple of gross algorithmic errors, the correction of which can be delayed for a long time. Therefore, with sadness in my voice, I went to ask for a temporary license from Abbyy. After two weeks of daily calls, I received it. I can not fail to note that the documentation and the Java wrapper are very well written and it was a pleasure to work with such a product. However, the recognition mechanism is far from 100% accurate. So I had to do autocorrection. For several hours I wrote a bot that downloaded the entire database of books from the popular site labirint.ru. Using a similar database and the aforementioned search algorithm, the accuracy of book recognition has increased significantly.

Despite the obvious ease of use of reading books, I decided to use autocomplete fields through the ISBN. Since it’s foolish to download the whole database of ISBN books, I decided to use Google Book Api to search the ISBN. Also, offline maze database is still available with> 200,000 Russian-language books. In addition, it is easy to implement a barcode scanner of books (on the same Abbyy API) and then adding books will only be fun.

I thought it would be nice to take a picture of the shelf and add all the books to the electronic catalog. Implementing this is easily possible only with the use of the free OpenCV library and with an integrated Kenny boundary detector . In addition, you will need to write your own algorithm for a more serious analysis of the main lines of books and send each spine to the Abbyy API and receive the necessary text, process it through the maze database and display the elements of interaction with the UI on top of the photographed image. (Unfortunately, I never got around to finish this functionality in my head. There is no time)

The low cost of the project and an extensive technological base allows access to high and convenient technologies even for pupils in ordinary municipal schools. Please take the fact for attention that the product is absolutely open and works great without access to the Internet. In addition, the resource intensity of the project allows you to start the server even on the Raspberry PI , costing $ 20.
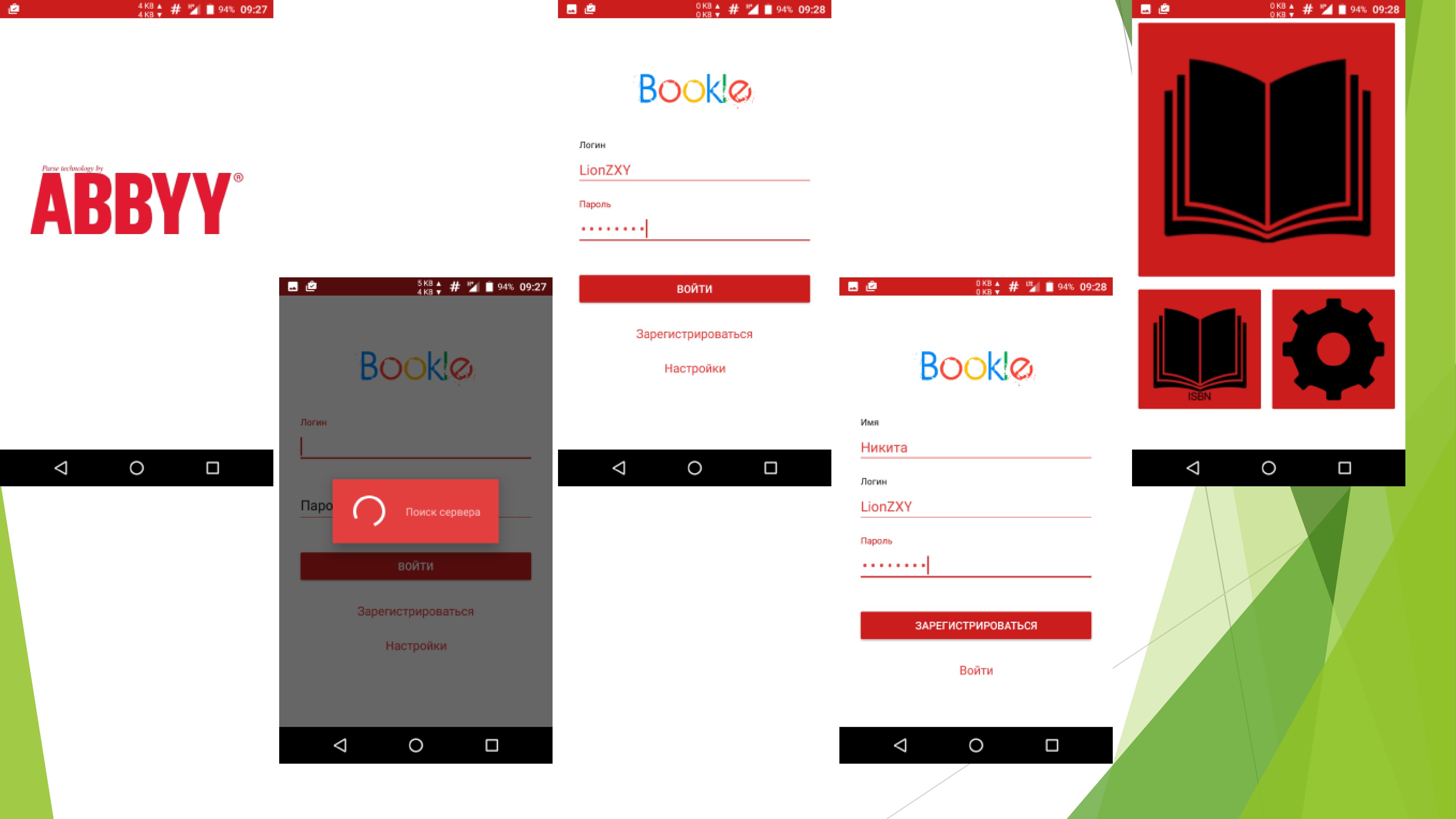
Despite the fact that this did not help me in my life, I gained valuable experience in developing a full-fledged website and application and it was wildly interesting to me. Well, a couple of screenshots:

Introduction
One fine day I went to the library for one story. Having said the title and author of the story to the librarian, he received a stack of collections of this author. In order to find the necessary story among all this variety, we had to go through all the works. It would be much easier to “google” the desired work and get what you want in a few clicks.
')
And then I thought: “Why is there still no such thing in libraries? It's so convenient! ”. Naturally, like any decent lazy programmer, I went straight to the search engine to look for similar projects. And ran into problems. All found projects were either commercial (paid), or amateur and low-quality.
Naturally, such an injustice urgently needed to be addressed, despite the approaching USE and admission to the university.
Language selection
First of all, it became clear that we cannot do without a web part. Despite my personal intolerance to web programming, I sat down with Google and began to study this issue.
After a few hours, I finally chose the required language. More precisely not a language, but FrameWork RubyOnRails. Why he? Because it uses a full-fledged OOP language, is actively developed by a giant community and has a fast core. In addition, girls like Ruby (it is better not to speak at the presentation).
Naturally, it was based on the “beautiful” language of Ruby. Since I know Java at the Junior level, it was easy for me to learn any other OOP language. Every week I watched 2 lectures every evening and in the end could boast the necessary knowledge of Ruby syntax. And then my self-confidence was dropped ... And all because this FrameWork is so huge and extensive, that the knowledge of Ruby helped me only a little bit. Having studied the MVC technology and other ideas of the evil web programmers, I started to implement the project.
Authorization
The first obstacle in my path was, oddly enough, authorization. I decided to use OAuth technology. Its principle is that tokens are used instead of passwords. Using tokens allows you not to worry that your password will be stolen, as well as to configure each token for yourself (for example, you can take one-time tokens with permissions for only one operation). At first I decided to use MD5 encryption to store passwords on the server side, but after reading about it on the Internet, I decided that this method was outdated. Hacking on new computers is carried out in just 1 minute. Therefore, I decided to use bCrypt, which provides almost 100% protection against password decryption in the database. Since I decided to make a similar system myself, I had to think about optimization. First of all, the tokens had to be transferred from a string to a numeric value, so that a DB could be searched for by a binary search.
It would seem that the complex can be in the simplest school project with authorization? Let's start with the fact that the authorization window I did for 20 hours. And let's continue with the fact that my project is completely OpenSource and runs on the local network, which means that it is enough to deploy your server on the mobile in order to intercept the tokens. Therefore, I came up with my own server validation system. With each token, the server returns two values. ID in the database and a unique small identifier. Every time a client wants to check the validity of the server, he sends the ID to the server, and the server returns the identifier to him. And only then the client sends a token to the server. It turns out the authorization from two sides.
Search algorithm
In all such projects, the weak side is search. I would not want such a flaw to be present in my project. The use of ready-made solutions is completely dismissed due to the fact that all large search engines require an Internet connection. Therefore, I approached this issue with all seriousness. After reading the book about algorithms, I decided that it is better to use the Damerau-Levenshtein distance algorithm for comparing lines, since it has maximum accuracy at the expense of performance, which is most important for the project. But there was a problem comparing whole sentences. First, I used a similar algorithm, spreading the comparison table on a tree of graphs. For a long time I was tormented by this, but in the end I got the wrong result. Therefore, all demolished and inserted another algorithm in the comparison of sentences. His principle is simple to madness. If the word has less than 3 errors, take it for the correct and add 1 point to the final index. If two correct words go in a row, add another 1 point. And so on.
Since the search is very hard set, use the syntactic meaning of the sentence does not make sense. Therefore, in the future we plan to add a phonetic search and continue to work towards improving the self-learning system and centralizing all data.
Another way to improve the quality of the search was self-study. The fact is that each request is recorded in the database and, if necessary, it is possible to issue add points to popular books. Let's say the user “Gosh” loves fiction. We understood this by the fact that the number of books found on fiction far exceeds other genres. Therefore, afterwards, when the search results are displayed, the search system will add additional points to the user of Gosh for books on fiction. In addition, such a large amount of statistical research is useful.
Naturally, this algorithm then acquired various optimizations, but more on that another time. I decided to implement such a resource-intensive algorithm in C ++ and make a bridge from Ruby using the Rice plugin. Here is another illustrative example of why I chose RubyOnRails and did not regret it.
Image recognition
To solve the problem of fast library digitization, only the text recognition mechanisms in the picture will help. Since it is rather stupid to bring the image to the PC webcam for reading, it was decided to develop a mobile application for smartphones. Writing the base application took about a week because Smartphones actively use multithreading and fairly stringent criteria for application design.
After doing a deep analysis of existing solutions, I chose Tessaract as the best free open-source product based on OCR technology. In addition, actively supported by Google. Having tried to play with him, I realized that such a result is no good. For accurate recognition, you would have to work with image preprocessing for quite a long time. In addition, in the source code of this project, I found a couple of gross algorithmic errors, the correction of which can be delayed for a long time. Therefore, with sadness in my voice, I went to ask for a temporary license from Abbyy. After two weeks of daily calls, I received it. I can not fail to note that the documentation and the Java wrapper are very well written and it was a pleasure to work with such a product. However, the recognition mechanism is far from 100% accurate. So I had to do autocorrection. For several hours I wrote a bot that downloaded the entire database of books from the popular site labirint.ru. Using a similar database and the aforementioned search algorithm, the accuracy of book recognition has increased significantly.
ISBN
Despite the obvious ease of use of reading books, I decided to use autocomplete fields through the ISBN. Since it’s foolish to download the whole database of ISBN books, I decided to use Google Book Api to search the ISBN. Also, offline maze database is still available with> 200,000 Russian-language books. In addition, it is easy to implement a barcode scanner of books (on the same Abbyy API) and then adding books will only be fun.
Algorithm of ultrafast library digitization
I thought it would be nice to take a picture of the shelf and add all the books to the electronic catalog. Implementing this is easily possible only with the use of the free OpenCV library and with an integrated Kenny boundary detector . In addition, you will need to write your own algorithm for a more serious analysis of the main lines of books and send each spine to the Abbyy API and receive the necessary text, process it through the maze database and display the elements of interaction with the UI on top of the photographed image. (Unfortunately, I never got around to finish this functionality in my head. There is no time)
Conclusion
The low cost of the project and an extensive technological base allows access to high and convenient technologies even for pupils in ordinary municipal schools. Please take the fact for attention that the product is absolutely open and works great without access to the Internet. In addition, the resource intensity of the project allows you to start the server even on the Raspberry PI , costing $ 20.
Despite the fact that this did not help me in my life, I gained valuable experience in developing a full-fledged website and application and it was wildly interesting to me. Well, a couple of screenshots:
Information sources
- Many thanks to the English-speaking audience of the site www.stackoverflow.com
- Many thanks to habrahabr.ru ntz for a series of the smartest fuzzy search articles.
- Also in the project materials were used www.wikipedia.org
- Many thanks to my classmate Evgenia Lendrasova for beautiful and bright logos.
- Giant thanks to my teacher for support in my endeavors.
- Thanks ABBYY for providing OCR for text recognition. Without it, I would not be able to implement this project.
Source: https://habr.com/ru/post/303912/
All Articles