How I accelerated strstr
It took me recently to write an analogue of the function strstr (search for a substring in a string). I decided to speed it up. The result is an algorithm. I did not find it on the first links in the search engine, but there are a bunch of other algorithms, so I wrote it.
The graph comparing the speed of my algorithm, with the function strstr on 600 kb text of a Russian book, when searching for strings ranging in size from 1 to 255 bytes:

The idea behind the algorithm is as follows. First designations:
S - The string in which the search will be performed will be called
P - the string we are looking for will be called
sl - string length S
pl - the length of the string P
PInd - plate compiled in the first stage.
So the idea is this: If in the line S we choose elements with indices equal: pl 1, pl 2, ..., pl J, ..., pl (sl / pl), then if in the segment pl (J-1) .. .pl (J + 1) includes the search string P, then the selected element must belong to the string P. Otherwise the string would not fit in length.
The picture where it is drawn up to where P falls in, pl * 3:
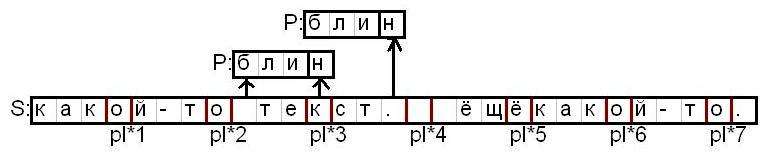
And again, since the selected element is included in the P line, usually a small number of times, then only these occurrences can be checked, not the entire range.
Total algorithm is as follows:
Stage 1. Sorting P
For all elements (characters) of the string P, we sort the indices of these elements by the value of these elements. That is, we do so that all the numbers of all elements equal to some value can be quickly obtained. This label will continue to be called PInd:
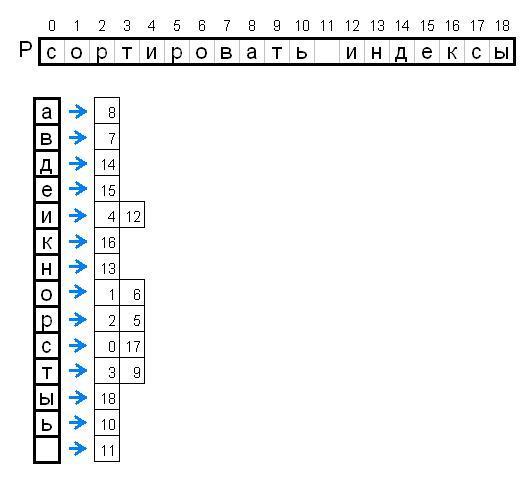
As can be seen from this table, when searching in step 2 with the search string P equal to "sort indexes" we will need to check a maximum of 2 variants of substrings in S.
First, I used quick sorting and some other sorting to compile this label, and then I realized that since the elements of the string are single-byte, you can use bitwise.
Stage 2. Search
We pass through the line to the line S in jumps equal to pl, choosing the corresponding elements. For each selected item, check if it is included in the string P.
If it is included, then for all indexes from the PInd of the corresponding element, we check whether the substring S coincides with the beginning of the corresponding index from the PInd offset relative to the selected element and the search string P.
If matched, then return the result, if not, continue.
The worst case for this algorithm depends on how the strings are compared in the second stage. If a simple comparison, then sl * pl + pl, if some more, then another. I used a simple comparison, as in the usual strstr.
Due to the fact that the algorithm jumps through the pl elements and checks only possible lines, it works faster.
The best option is when the algorithm skips the entire string S and does not find the text or finds it the first time, then spends approximately sl / pl.
Average speed, I do not know how to count.
Here is one of my implementations of this algorithm, based on which the graph was built in the C language. Here pl is limited, that is, the PInd table is built by the prefix P of length max_len, and not across the entire line. That it was used in the construction of the schedule:
char * my_strstr(const char * str1, const char * str2,size_t slen){ unsigned char max_len = 140; if ( !*str2 ) return((char *)str1); // unsigned char index_header_first[256]; unsigned char index_header_end[256]; unsigned char last_char[256]; unsigned char sorted_index[256]; memset(index_header_first,0x00,sizeof(unsigned char)*256); memset(index_header_end,0x00,sizeof(unsigned char)*256); memset(last_char,0x00,sizeof(unsigned char)*256); memset(sorted_index,0x00,sizeof(unsigned char)*256); // 1. char *cp2 = (char*)str2; unsigned char v; unsigned int len =0; unsigned char current_ind = 1; while((v=*cp2) && (len<max_len)){ if(index_header_first[v] == 0){ index_header_first[v] = current_ind; index_header_end[v] = current_ind; sorted_index[current_ind] = len; } else{ unsigned char last_ind = index_header_end[v]; last_char[current_ind] = last_ind; index_header_end[v] = current_ind; sorted_index[current_ind] = len; } current_ind++; len++; cp2++; } if(len > slen){ return NULL; } // 2. unsigned char *s1, *s2; // S+pl-1 unsigned char *cp = (unsigned char *) str1+(len-1); unsigned char *cp_end= cp+slen; while (cp<cp_end){ unsigned char ind = *cp; // P if( (ind = index_header_end[ind]) ) { do{ // unsigned char pos_in_len = sorted_index[ind]; s1 = cp - pos_in_len; if((char*)s1>=str1) { // s2 = (unsigned char*)str2; while ( *s2 && !(*s1^*s2) ) s1++, s2++; if (!*s2) return (char*)(cp-pos_in_len); } } while( (ind = last_char[ind]) ); } // pl cp+=len; } return(NULL); } Update: This is really not a direct replacement for strstr, since it requires an additional parameter - the length of the string S.
')
Source: https://habr.com/ru/post/303830/
All Articles