HL7: Your HL7 CDA document does not comply with the standard
In this short article I will try to show why your HL7 CDA document most likely does not conform to the standard, and also suggest what to do with it.
What is the Clinical Document Architecture (CDA) I already, also briefly, described in another post - habrahabr.ru/post/255879
Immediately, I note that the “full” description of CDA will occupy a whole book of 300 pages, one of the existing ones is called “ The CDA Book ”. Therefore, there is not any possibility in one article to tell about all the features of this standard.
Let me remind you, the Clinical Document Architecture is one of the 20 domains of the HL7v3 standard. If you are familiar with v3, and I hope most readers know at least a little of what it is, then you know that in this version all artifacts are based on the HL7 Reference Information Model (RIM).
To further explanation was clearer, let's see how the models are built in HL7v3. Start with RIM, which looks like this:
')
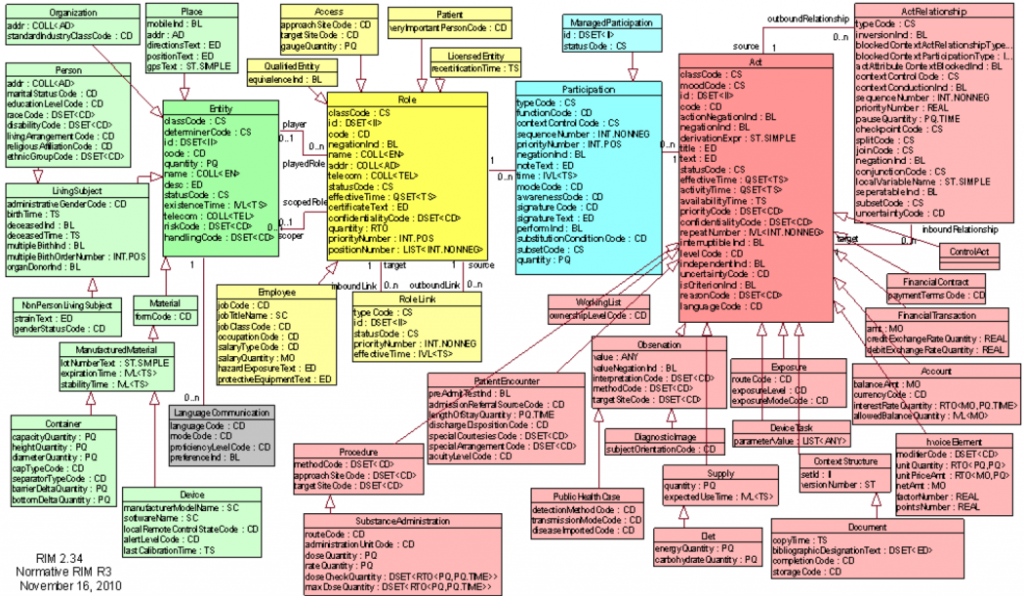
As it is not difficult to notice, RIM is based on 4 basic classes: Entity , Role , Participation and Act , and two additional classes for describing relationships: Role Link and Act Relationship . The concept of "class" for those who have ever encountered software development, certainly suggests an object-oriented structure of RIM and, I must say, this is almost true. Why almost, because RIM follows the basic principles of inheritance in the PLO. The standard clearly states:
But further discrepancies begin. To obtain the required messages, the HL7v3 uses a refinement process ( refinement process ) which leads to the creation of several Domain Message Information Model (D-MIM) for domains and a set of Refined Message Information Model (R-MIM) in each of them. From R-MIM, following the same rules, the final Hierarchical Message Descriptions (HMD) are obtained from which, in turn, messages are built.
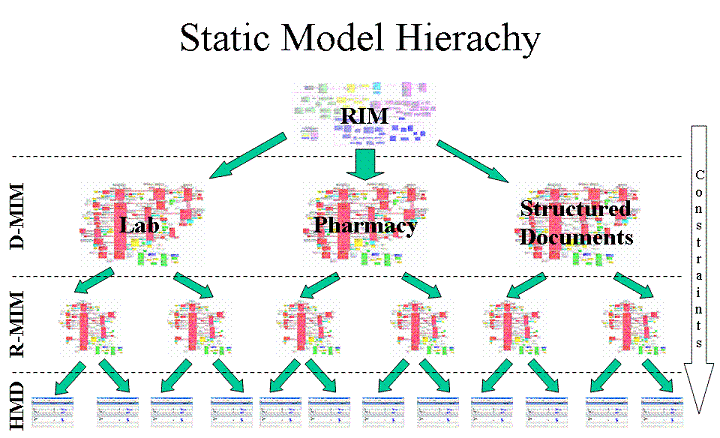
The refinement process is based on the constraint process (constraints) and the localization process . As the name implies, the process of restriction does not imply further expansion or redefinition of classes; on the contrary, the heir class may include all or some properties of its parent class, but no more. The localization process assumes that some models do not fully meet the business requirements and need to be supplemented. Such additions, most often implemented in the form of extensions (extensions) in the future, may become part of the model. Although it is much more common to hear that if you need extensions, then you are probably incorrectly describing your business processes.
And so, having a little understood in the process of implementing the HL7v3 models, let's go back to CDA, namely to CDA R-MIM, to the part that describes the body of the document.
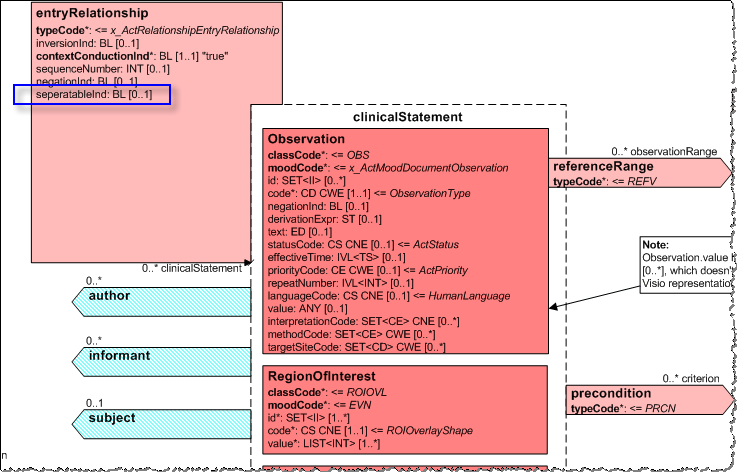
All classes for selection in clinicalStatement are inherited from the Act class. For example, for the reduced Observation class, the main description is to be found not in the Universal Domains -> Clinical Document Architecture section (although it also makes sense there, but to learn about some additional features of using this class), but in the Foundation -> Reference Information Model -> Classes -> Observation .

Similarly for entryRelationship . If we use only the description in the domain of the Clinical Document Architecture , then we can understand that “ CDA has identified and modeled various link and reference scenarios ”, as well as features of the use of entryRelationship.inversionInd and entryRelationship.contextConductionInd .
However, as you can see, entryRelationship inherits other attributes from its parent class, ActRelationship . This includes ActRelationship.seperatableInd , which defaults to “true” and is used for “ an indication that the act was intended to be interpreted. Indicates the act if it’s not necessary to meet the target act. "(Source HL7 NE)
Thus, if your CDA section template most likely uses entryRelationship to describe clinical conditions, for example: type of allergic reaction - allergic agents - allergen - degree of manifestation, then ActRelationship.seperatableInd = true by default, then all your descriptions are independent of each other. That is, the allergen exists in the document by itself, it is not associated with anyone, and does not identify anyone. As well as the "degree of manifestation" it is not clear what exists by itself in some incomprehensible conditions.
If the goal is to “ the target (for the internal class of Observation) cannot be set to“ false ”. (source "The CDA Book", with my additions in brackets)
Those. In order for all attachments to carry the meaning that was originally laid in them, in each case, there must be an entryRelationship.seperatableInd = false explicitly.
However, you can hardly find at least one example of using this attribute in a real CDA document or a CDA document template.
What to do?
The eternal question. Most likely nothing. Wait until the HL7 corrects the model, or the description in one of the following versions of the HL7v3 Normative Edition, where this attribute will be false by default.
Or you can make such corrections in the XML schema POCD_MT000040.EntryRelationship.
Or add one line to its specification denoting that by default this attribute is always false.
Update: I am glad that someone is cons. But from the fact that you are minus, this, as well as many other problems associated with the CDA conformance tests, does not disappear.
Update2: And someone noticed that C-CDA R2.1 in some cases requires (SHALL) to use the CD.qualifier element, which in the XML schema is represented as:
<xs: element name = "qualifier" type = "CR" minOccurs = "0" maxOccurs = "0" />
What is the Clinical Document Architecture (CDA) I already, also briefly, described in another post - habrahabr.ru/post/255879
Immediately, I note that the “full” description of CDA will occupy a whole book of 300 pages, one of the existing ones is called “ The CDA Book ”. Therefore, there is not any possibility in one article to tell about all the features of this standard.
Let me remind you, the Clinical Document Architecture is one of the 20 domains of the HL7v3 standard. If you are familiar with v3, and I hope most readers know at least a little of what it is, then you know that in this version all artifacts are based on the HL7 Reference Information Model (RIM).
To further explanation was clearer, let's see how the models are built in HL7v3. Start with RIM, which looks like this:
')
As it is not difficult to notice, RIM is based on 4 basic classes: Entity , Role , Participation and Act , and two additional classes for describing relationships: Role Link and Act Relationship . The concept of "class" for those who have ever encountered software development, certainly suggests an object-oriented structure of RIM and, I must say, this is almost true. Why almost, because RIM follows the basic principles of inheritance in the PLO. The standard clearly states:
- Generalization - when the heir class includes all the properties of the parent class.
- Specialization (specialization) - the class-successor redefines some functions of the parent, and also defines additional properties for even greater specialization.
But further discrepancies begin. To obtain the required messages, the HL7v3 uses a refinement process ( refinement process ) which leads to the creation of several Domain Message Information Model (D-MIM) for domains and a set of Refined Message Information Model (R-MIM) in each of them. From R-MIM, following the same rules, the final Hierarchical Message Descriptions (HMD) are obtained from which, in turn, messages are built.
The refinement process is based on the constraint process (constraints) and the localization process . As the name implies, the process of restriction does not imply further expansion or redefinition of classes; on the contrary, the heir class may include all or some properties of its parent class, but no more. The localization process assumes that some models do not fully meet the business requirements and need to be supplemented. Such additions, most often implemented in the form of extensions (extensions) in the future, may become part of the model. Although it is much more common to hear that if you need extensions, then you are probably incorrectly describing your business processes.
And so, having a little understood in the process of implementing the HL7v3 models, let's go back to CDA, namely to CDA R-MIM, to the part that describes the body of the document.
All classes for selection in clinicalStatement are inherited from the Act class. For example, for the reduced Observation class, the main description is to be found not in the Universal Domains -> Clinical Document Architecture section (although it also makes sense there, but to learn about some additional features of using this class), but in the Foundation -> Reference Information Model -> Classes -> Observation .
Similarly for entryRelationship . If we use only the description in the domain of the Clinical Document Architecture , then we can understand that “ CDA has identified and modeled various link and reference scenarios ”, as well as features of the use of entryRelationship.inversionInd and entryRelationship.contextConductionInd .
However, as you can see, entryRelationship inherits other attributes from its parent class, ActRelationship . This includes ActRelationship.seperatableInd , which defaults to “true” and is used for “ an indication that the act was intended to be interpreted. Indicates the act if it’s not necessary to meet the target act. "(Source HL7 NE)
Thus, if your CDA section template most likely uses entryRelationship to describe clinical conditions, for example: type of allergic reaction - allergic agents - allergen - degree of manifestation, then ActRelationship.seperatableInd = true by default, then all your descriptions are independent of each other. That is, the allergen exists in the document by itself, it is not associated with anyone, and does not identify anyone. As well as the "degree of manifestation" it is not clear what exists by itself in some incomprehensible conditions.
If the goal is to “ the target (for the internal class of Observation) cannot be set to“ false ”. (source "The CDA Book", with my additions in brackets)
Those. In order for all attachments to carry the meaning that was originally laid in them, in each case, there must be an entryRelationship.seperatableInd = false explicitly.
However, you can hardly find at least one example of using this attribute in a real CDA document or a CDA document template.
What to do?
The eternal question. Most likely nothing. Wait until the HL7 corrects the model, or the description in one of the following versions of the HL7v3 Normative Edition, where this attribute will be false by default.
Or you can make such corrections in the XML schema POCD_MT000040.EntryRelationship.
Or add one line to its specification denoting that by default this attribute is always false.
Update: I am glad that someone is cons. But from the fact that you are minus, this, as well as many other problems associated with the CDA conformance tests, does not disappear.
Update2: And someone noticed that C-CDA R2.1 in some cases requires (SHALL) to use the CD.qualifier element, which in the XML schema is represented as:
<xs: element name = "qualifier" type = "CR" minOccurs = "0" maxOccurs = "0" />
Source: https://habr.com/ru/post/303716/
All Articles