Dream job and free cluster on 1 million meta data
Good day!
We decided to give public access to the archive of 1 million social media messages rich in data (several hundred sources, including posts and comments on social networks, blogs, forums, media, etc.).
We offer to try our hand at creating various heuristics that are laid in the classic SMA-systems (Social Media Analytics). The more heuristics you come up with and can implement, the higher your class in Data Scientist . Perhaps a real pro lives in you: Data Scientist is one of the coolest professions of the near future!
For accomplished pro fans, it is an opportunity to test and demonstrate their abilities, as well as, with mutual desire and joy, to get a one-year contract for $ 30,000 - $ 50,000 .
')
More under the cut
Strategic Situational Level:
- Every day, humanity generates dozens (30-40) billion online messages, of which 5-7% are public.
- Russian-language messages make up 2-3% of the world flow, i.e. ~ 100 million per day.
- Unlike structured data (checks in the store, information about calls, electronic payments, etc.) Unstructured data requires other tools for creating analytical systems and approaches to analyzing data by analysts: high-speed linguistics, fuzzy meta-data, “spread” geolocation, identifying and counteracting "alien reason" (bots), etc., etc.
Tactical level:
- Humanity is practically "over" - the rate of increase in online and content generation is a natural percentage.
- Platforms for data collection, as well as primary analysis (SMA - Social Media Analytics), including linguistic modules (usually the slowest processes) have reached the industrial level, coping with the current data generation flows.
- Now it's up to the "brains" - which (adaptive) AI algorithms (AI, artificial intelligence or machine self-learning) will be created, developed and used to solve real problems of human society.
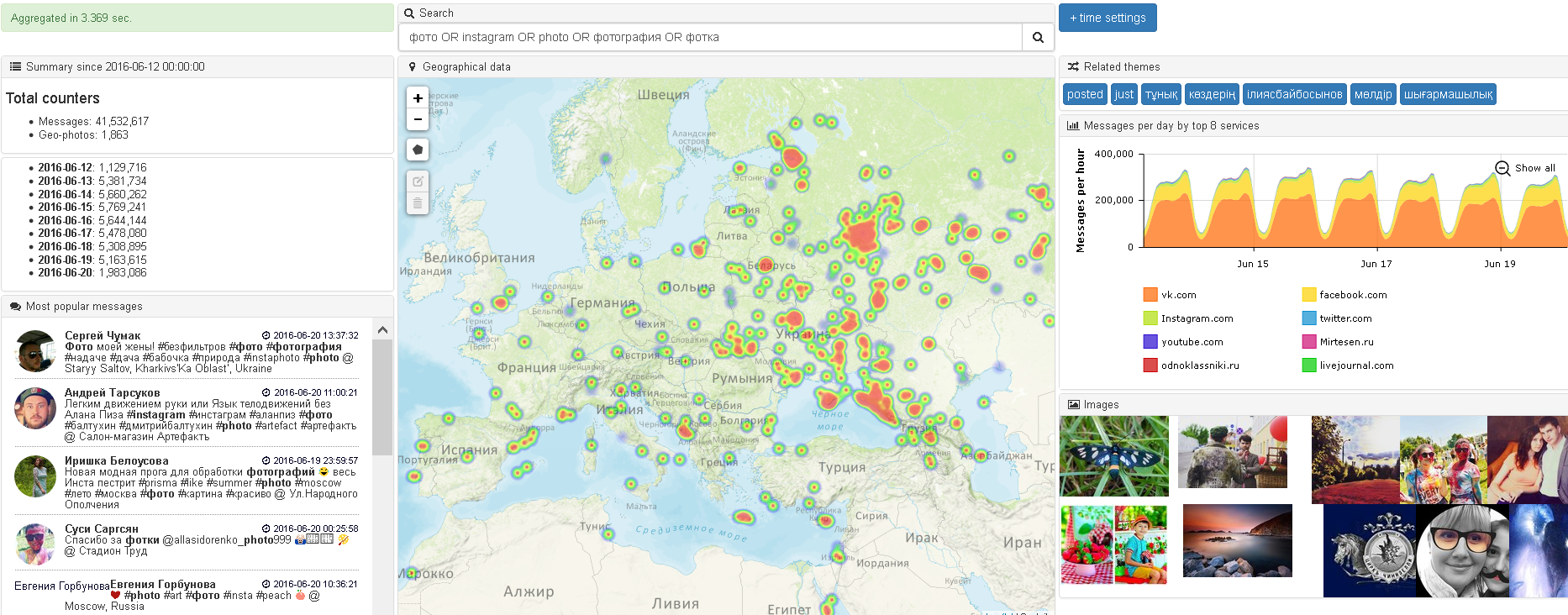
Conceptual example (see picture above):
There is a set of rich social data messages, as well as a standard set of heuristics developed by analysts for clients over several years, for example: the number of messages (sometimes broken down by period), monitoring by communication channels, etc. If messages are supplemented with “indirect” information with meta-data that is not in the original message (i.e., “brains and memory” are used), then you can add the gender for the tweets (the missing field in the account), and for example, geo on the phrase "I support our in Paris." Then you can create a NEW heuristics - show messages on the map, updating such attributes as concentration and geo-dynamics of the event.
Saturation and expansion of meta-data is an interesting task in itself, which is already partially and with varying degrees of success solved in large companies (IBM, Google, MS), and social networks (Facebook, Twitter, LinkedIn). For these processes, most often involve emerging technologies - for example, identifying people from photographs, or accessing data on the physical movements of people (telecom tags).
The moment comes when technologies and tasks reach the next level of “brainy” - when the systems INDEPENDENTly find new patterns and make a forecast about the development of events and situations.
For example, automated financial robots went through similar phases of development: various models and heuristics were built on the analysis of past data, which then automatically work and earn (at least, the developers of these robots).
The Data Scientist profession involves a certain centaur: a mixture of a programmer and an analyst. What is more in a centaur is important, but secondary, the main thing is the result of a specialist’s activity. According to forecasts of research agencies, the DS requirement in the USA alone will be 180.000 people.
Specificity:
1. 1 million + public messages with meta-data laid out in public access:
CSV , 55 mb
JSON , 350 Mb (traditional json. One array with 1 million + objects)
JSON , 415 mb (One json-object for 1 line, separator LF ("\ n"))
The data is a sample of ~ 6 hours of one day.
2. For those who are interested and who want to try their hand at their abilities and capabilities, try to “repeat” the simplest heuristics that are included in the classic SMA systems. The more heuristics you come up with (look) and you can implement, the higher your class in DS. Without fail, find the criterion for sampling this 1 million messages. Let me remind you that according to statistics, the daily set of the Russian-speaking stream is ~ 100 million, which means there would have to be 10-15 million in a few hours, and only 1 million in the sample. What could be the criterion of the sample? A small hint - usually simple samples are made by words (“keywords”).
3. At Habré, posts on analyzing unstructured data periodically appear; it is quite possible that some of the pro fans will agree to participate in our new R & D spinoff on an ongoing basis (one-year contract, $ 30-50 thousand). It does not matter gender, age, education, place of residence, only the result that needs to be implemented on this data set, and the desire to create and create NEW heuristics, is important.
What is the result of the pros:
- Standard statistics SMA - data fields in the meta-data is enough for understanding.
- Expansion of new meta-data, due to the collection of additional data on the authors of a set of social networks, for example: married / single, studying / working, children / parents.
- “Intelligent” meta-data is a very strong plus. For example: the dynamics of the tonality of statements, or the clustering of interests.
- And, of course, NEW heuristics, which only come to mind.
If something interesting happens, send it to sz@palitrumlab.ru.
Code is not necessary to send! Only signs or pictures with the results.
PS To the existing SDS Data Platform and the EurekaEngine linguistic platform, we are currently developing the Meta-Data Platform. We hope that by the end of the year we will be able to provide access to all Platforms for developers of different levels, as well as groups and teams, in order to create third-party solutions and systems for which work it is necessary to obtain open data from social media and public data sets.
UPD: in less than an hour, the first “pictures” with heuristics “What kind of sample” came:


UPD2: Dropbox closed access after a couple of thousand downloads, CSV and JSON is available on Ya.Disk. At the same time, a version of JSON with one object per line is posted.
We decided to give public access to the archive of 1 million social media messages rich in data (several hundred sources, including posts and comments on social networks, blogs, forums, media, etc.).
We offer to try our hand at creating various heuristics that are laid in the classic SMA-systems (Social Media Analytics). The more heuristics you come up with and can implement, the higher your class in Data Scientist . Perhaps a real pro lives in you: Data Scientist is one of the coolest professions of the near future!
For accomplished pro fans, it is an opportunity to test and demonstrate their abilities, as well as, with mutual desire and joy, to get a one-year contract for $ 30,000 - $ 50,000 .
')
More under the cut
Strategic Situational Level:
- Every day, humanity generates dozens (30-40) billion online messages, of which 5-7% are public.
- Russian-language messages make up 2-3% of the world flow, i.e. ~ 100 million per day.
- Unlike structured data (checks in the store, information about calls, electronic payments, etc.) Unstructured data requires other tools for creating analytical systems and approaches to analyzing data by analysts: high-speed linguistics, fuzzy meta-data, “spread” geolocation, identifying and counteracting "alien reason" (bots), etc., etc.
Tactical level:
- Humanity is practically "over" - the rate of increase in online and content generation is a natural percentage.
- Platforms for data collection, as well as primary analysis (SMA - Social Media Analytics), including linguistic modules (usually the slowest processes) have reached the industrial level, coping with the current data generation flows.
- Now it's up to the "brains" - which (adaptive) AI algorithms (AI, artificial intelligence or machine self-learning) will be created, developed and used to solve real problems of human society.
Conceptual example (see picture above):
There is a set of rich social data messages, as well as a standard set of heuristics developed by analysts for clients over several years, for example: the number of messages (sometimes broken down by period), monitoring by communication channels, etc. If messages are supplemented with “indirect” information with meta-data that is not in the original message (i.e., “brains and memory” are used), then you can add the gender for the tweets (the missing field in the account), and for example, geo on the phrase "I support our in Paris." Then you can create a NEW heuristics - show messages on the map, updating such attributes as concentration and geo-dynamics of the event.
Saturation and expansion of meta-data is an interesting task in itself, which is already partially and with varying degrees of success solved in large companies (IBM, Google, MS), and social networks (Facebook, Twitter, LinkedIn). For these processes, most often involve emerging technologies - for example, identifying people from photographs, or accessing data on the physical movements of people (telecom tags).
The moment comes when technologies and tasks reach the next level of “brainy” - when the systems INDEPENDENTly find new patterns and make a forecast about the development of events and situations.
For example, automated financial robots went through similar phases of development: various models and heuristics were built on the analysis of past data, which then automatically work and earn (at least, the developers of these robots).
The Data Scientist profession involves a certain centaur: a mixture of a programmer and an analyst. What is more in a centaur is important, but secondary, the main thing is the result of a specialist’s activity. According to forecasts of research agencies, the DS requirement in the USA alone will be 180.000 people.
Specificity:
1. 1 million + public messages with meta-data laid out in public access:
CSV , 55 mb
JSON , 350 Mb (traditional json. One array with 1 million + objects)
JSON , 415 mb (One json-object for 1 line, separator LF ("\ n"))
The data is a sample of ~ 6 hours of one day.
2. For those who are interested and who want to try their hand at their abilities and capabilities, try to “repeat” the simplest heuristics that are included in the classic SMA systems. The more heuristics you come up with (look) and you can implement, the higher your class in DS. Without fail, find the criterion for sampling this 1 million messages. Let me remind you that according to statistics, the daily set of the Russian-speaking stream is ~ 100 million, which means there would have to be 10-15 million in a few hours, and only 1 million in the sample. What could be the criterion of the sample? A small hint - usually simple samples are made by words (“keywords”).
3. At Habré, posts on analyzing unstructured data periodically appear; it is quite possible that some of the pro fans will agree to participate in our new R & D spinoff on an ongoing basis (one-year contract, $ 30-50 thousand). It does not matter gender, age, education, place of residence, only the result that needs to be implemented on this data set, and the desire to create and create NEW heuristics, is important.
What is the result of the pros:
- Standard statistics SMA - data fields in the meta-data is enough for understanding.
- Expansion of new meta-data, due to the collection of additional data on the authors of a set of social networks, for example: married / single, studying / working, children / parents.
- “Intelligent” meta-data is a very strong plus. For example: the dynamics of the tonality of statements, or the clustering of interests.
- And, of course, NEW heuristics, which only come to mind.
If something interesting happens, send it to sz@palitrumlab.ru.
Code is not necessary to send! Only signs or pictures with the results.
PS To the existing SDS Data Platform and the EurekaEngine linguistic platform, we are currently developing the Meta-Data Platform. We hope that by the end of the year we will be able to provide access to all Platforms for developers of different levels, as well as groups and teams, in order to create third-party solutions and systems for which work it is necessary to obtain open data from social media and public data sets.
UPD: in less than an hour, the first “pictures” with heuristics “What kind of sample” came:
UPD2: Dropbox closed access after a couple of thousand downloads, CSV and JSON is available on Ya.Disk. At the same time, a version of JSON with one object per line is posted.
Source: https://habr.com/ru/post/303702/
All Articles