What is useful monomorphism?

Speeches and blog posts about JavaScript performance often draw attention to the importance of monomorphic code, but usually there is no clear explanation of what monomorphism / polymorphism is and why it matters. Even my own performances are often reduced to the dichotomy in the style of the Incredible Hulk: “ONE TYPE IS GOOD! TWO TYPE IS BAD! ” . It is not surprising that when people turn to me for advice on performance, they often ask to explain what monomorphism really is, where polymorphism comes from and what is wrong with it.
The situation is further complicated by the fact that the word “polymorphism” itself has many meanings. In classical object-oriented programming, polymorphism is associated with the creation of child classes, in which you can override the behavior of the base class. Programmers working with Haskell will instead think about parametric polymorphism. However, the polymorphism warned about in JavaScript performance reports is the polymorphism of function calls .
')
I explained this mechanism in so many different ways that I finally got together and wrote this article: now you can not improvise, but simply link to it.
I also tried a new way to explain things - portraying the interaction of the constituent parts of a virtual machine in the form of short comics. In addition, this article does not cover some of the details, which I considered insignificant, redundant or not directly related.
Dynamic search for dummies
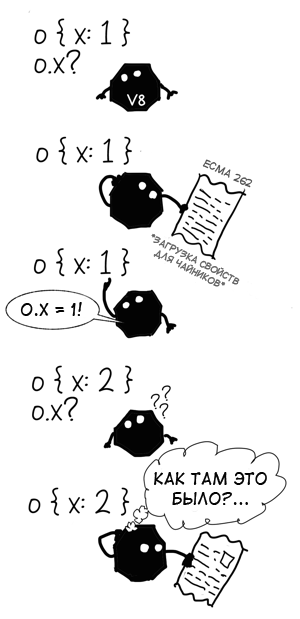
For the sake of simplicity, we will mainly consider the most elementary references to properties in JavaScript, such as
ox in the code below. At the same time, it is important to understand that everything we are talking about refers to any operation with dynamic linking , be it a property call or an arithmetic operator, and is applicable not only in JavaScript. function f(o) { return ox } f({ x: 1 }) f({ x: 2 }) Imagine for a moment that you will be interviewed for an excellent position in Interpreters LLC, and you are asked to come up with and implement a mechanism for accessing the property in a JavaScript virtual machine. What answer would be the most banal and simple?
It's hard to come up with something simpler than to take the ready-made JS semantics from the ECMAScript specification (ECMA 262) and rewrite the algorithm [[Get]] word for word from English to C ++, Java, Rust, Malbolge or any other language that you prefer for an interview.
Generally speaking, if you open a random JS interpreter, you can most likely see something like:
jsvalue Get(jsvalue self, jsvalue property_name) { // 8.12.3 [[Get]] } void Interpret(jsbytecodes bc) { // ... while (/* */) { switch (op) { // ... case OP_GETPROP: { jsvalue property_name = pop(); jsvalue receiver = pop(); push(Get(receiver, property_name)); // TODO(mraleph): strict mode, 8.7.1 3. break; } // ... } } } This is an absolutely correct way to implement property reference, but it has one significant drawback: compared to modern JS virtual machines, our implementation is very slow.
Our interpreter suffers from amnesia: every time when accessing a property, he is forced to perform the entire generalized algorithm for finding a property. He does not learn from previous attempts and is forced to pay the maximum each time. Therefore, performance-oriented virtual machines implement property access in a different way.
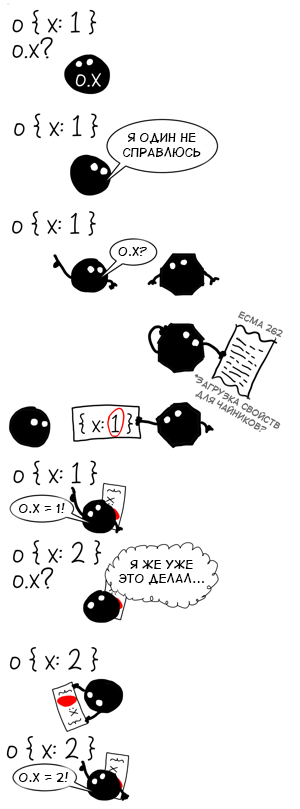
Now, if it were possible to get information about the objects that we have already seen, and apply it to similar objects! In theory, this would allow us to save a lot of time using not the general algorithm, but the most suitable for objects of a particular form .
We know that searching for a property in a random object is a time-consuming operation, so it would be nice to do it once, and cache the found path using the object's form as a key. The next time we meet an object of the same form, it will be possible to get the path from the cache much faster than calculating it from scratch.
These optimization techniques are called inline caching and I already wrote about it before . For this article, we will not go into the details of the implementation, but pay attention to two important things that I previously kept silent about: like any other cache, the inline cache has a size (the number of cached elements at the moment) and a capacity (the maximum number of elements, which can be cached).
Let's go back to the example:
function f(o) { return ox } f({ x: 1 }) f({ x: 2 }) How many entries will be in inline cache for
ox value?Since
{x: 1} and {x: 2} have the same form (it is sometimes called the hidden class ), the answer is 1. It is this cache state that we call monomorphic , because we only come across objects of the same form.Mono (“one”) + morph (“form”)
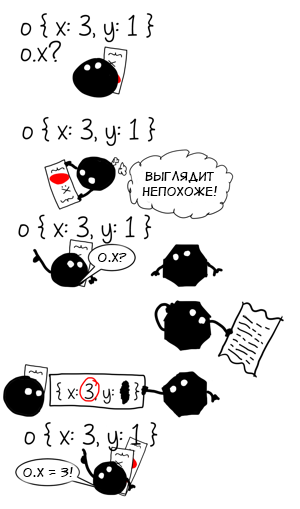
And what happens if we call the function
f with an object of another form? f({ x: 3 }) // ox f({ x: 3, y: 1 }) // ? The objects
{x: 3} and {x: 3, y: 1} have a different shape, so our cache now contains two entries: one for {x: *} and one for {x: *, y: *} . The operation became polymorphic with a polymorphism level of two.If we continue to transfer objects of various shapes to
f , the level of polymorphism will increase until it reaches the capacity limit for the inline cache (for example, in V8, to access the properties, the capacity limit will be four). After that, the cache will go to the megamorphic state. f({ x: 4, y: 1 }) // , 2 f({ x: 5, z: 1 }) // , 3 f({ x: 6, a: 1 }) // , 4 f({ x: 7, b: 1 }) // 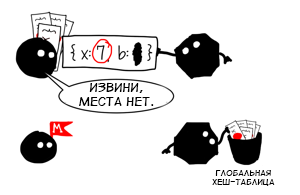
The megamorphic state is needed in order not to allow the cache to grow uncontrollably, and in fact means "There are too many forms here, it is useless to track them further." In a V8 virtual machine, caches in a megamorphic state can still continue to cache something, but not locally, but into a global hash table. It has a fixed size and overwrites values in case of collisions.
A little exercise to test understanding:
function ff(b, o) { if (b) { return ox } else { return ox } } ff(true, { x: 1 }) ff(false, { x: 2, y: 0 }) ff(true, { x: 1 }) ff(false, { x: 2, y: 0 }) - How many inline property access caches are declared in the
fffunction? - What condition are they in?
Answers
Keshes are two and both are monomorphic, since only objects of the same form fell into each of them.
Performance impact
At this stage, the performance of the various inline cache states become apparent:
- Monomorphic - the fastest if you access the value from the cache each time ( ONE TYPE IS GOOD! )
- Polymorphic - linear search among cache values
- Megamorphic - referring to the global hash table. The slowest option from cached, but still faster than cache miss
- Slip cache - referring to the field, which is not in the cache. You have to pay for the transition to runtime and the use of the most general algorithm.
In fact, this is only half the truth: in addition to direct code acceleration, inline caches also work as spies in the service of the omnipotent optimizing compiler, which sooner or later will come and speed up your code even more.
Speculation and optimization
Inline caches cannot maximize performance alone for two reasons:
- Each inline cache works independently and knows nothing about its neighbors.
- Each inline cache can miss, and then you have to use runtime: ultimately it is a generalized operation with generalized side effects, and even the type of return value is often unknown.
function g(o) { return ox * ox + oy * oy } g({x: 0, y: 0}) In the example above, there are seven inline-caches: two for
.x , two for .y , two more for * and one for + . Each acts independently, checking the object o for compliance with the cached form. The arithmetic cache of the operator + will check whether both operands are numbers, although this could be inferred from the states of the operator caches * . In addition, V8 has several internal representations for numbers, so this will also be taken into account.Some arithmetic operations in JS have a specific type inherent to them, for example
a | 0 a | 0 always returns a 32-bit integer, and +a is just a number, but for most other operations there are no such guarantees. For this reason, writing an AOT compiler for JS is an incredibly complex task. Instead of compiling the JS code in advance once, most JS virtual machines have several execution modes.For example, V8 first compiles everything with an ordinary compiler and immediately starts to execute. Later, frequently used functions are recompiled using optimizations. On the other hand, Asm.js uses implicit types of operations and with their help describes a very strictly limited Javascript subset with static typing. Such code can be optimized even before its launch, without speculations of adaptive compilation.
“Warming up” code is needed for two purposes:
- Reduces delay at start: the optimizing compiler is included only if the code has been used enough times
- Inline caches manage to collect information about the shapes of objects.
As mentioned above, JavaScript code written by people usually does not contain enough information so that it can be fully statically typed and AOT compiled. The JIT compiler has to speculate on how your program behaves and produce optimized code that is only suitable under certain assumptions. In other words, he needs to know which objects are used in the function being optimized. By a happy coincidence, this is exactly the information that inline caches collect!
- Monomorphic cache says: “I only saw type A”
- Polymorphic cache says: “I have only seen types 1 , ..., A N ”
- Megamorphic cache says: "Yes, I saw a lot of things ..."
The optimizing compiler analyzes the information collected by inline-caches and builds an intermediate representation ( IR ) on it. IR instructions are usually more specific and lower-level than operations in JS. For example, if the cache for accessing the
.x property saw only objects of the form {x, y} , then the compiler can generate an IR instruction that gets the value at a fixed offset from the pointer to the object. Of course, it’s not safe to use this optimization for any incoming object, so the compiler will also add a type check before it. Type checking compares the shape of the object with the expected one, and if they differ, the optimized code cannot be executed. Instead, the non-optimized code is called and execution continues from there. This process is called deoptimization . Type mismatch is not the only reason why de-optimization can occur. It can also happen if the arithmetic operation was “sharpened” for 32-bit numbers, and the result of the previous operation caused an overflow, or when accessing the nonexistent array index arr[idx] (out of range, sparse array with gaps, etc. .).
It becomes clear that optimization is needed to eliminate the disadvantages described above:
| Non-optimized code | Optimized code |
|---|---|
| Each operation may have unknown side effects and implements full semantics. | Code specialization eliminates or limits uncertainty, side effects are strictly known (for example, there is no property reference to a property by offset) |
| Each operation is on its own, is trained independently and does not share the experience with its neighbors. | Operations are decomposed into low-level IR instructions that are optimized together, which eliminates redundancy. |
Of course, building IR for specific forms of objects is only the first step in the optimization chain. When the intermediate representation is formed, the compiler will run over it several times, detecting invariants and cutting out the excess. This type of analysis is usually limited to the scope of the procedure and compilers are forced to take into account the worst possible side effects on each call. It should be remembered that a call can be hidden in any non-specific operation: for example, the
+ operator can call valueOf , and calling its property will call its getter method. Thus, if the operation could not be specified in the first stage, all subsequent passes of the optimizer will stumble over it.One of the most common types of redundant instructions is to continually check that the same object has the same form. This is how the initial intermediate representation might look like for the function
g from the example above: CheckMap v0, {x,y} ;; shape check v1 Load v0, @12 ;; load ox CheckMap v0, {x,y} v2 Load v0, @12 ;; load ox i3 Mul v1, v2 ;; ox * ox CheckMap v0, {x,y} v4 Load v0, @16 ;; load oy CheckMap v0, {x,y} v5 Load v0, @16 ;; load oy i6 Mul v4, v5 ;; oy * oy i7 Add i3, i6 ;; ox * ox + oy * oy Here the form of the object in the variable
v0 checked 4 times, although there are no operations between checks that could cause its change. The attentive reader will also notice that the download of v2 and v5 also redundant, since no code overwrites them. Fortunately, a subsequent pass to global numbering of values will remove these instructions: ;; CheckMap v0, {x,y} v1 Load v0, @12 i3 Mul v1, v1 v4 Load v0, @16 i6 Mul v4, v4 i7 Add i3, i6 As mentioned above, it was only possible to remove these instructions because there were no side effects operations between them. If there was a challenge between the downloads of
v1 and v2 , we would have to assume that it can change the shape of the object in v0 , and therefore the verification of the form v2 would be mandatory.If the operation is not monomorphic, the compiler cannot simply take the same bundle of “form validation and concrete operation”, as in the examples above. Inline cache contains information about several forms. If you take any of them and start only on it, then all the rest will lead to de-optimization, which is undesirable. Instead, the compiler will build a decision tree . For example, if the inline cache for accessing the
ox property met only forms A, B, and C, then the expanded structure would be similar to the following (this is pseudocode, in fact, a control flow graph will be constructed): var o_x if ($GetShape(o) === A) { o_x = $LoadByOffset(o, offset_A_x) } else if ($GetShape(o) === B) { o_x = $LoadByOffset(o, offset_B_x) } else if ($GetShape(o) === C) { o_x = $LoadByOffset(o, offset_C_x) } else { // ox A, B, C // , ** $Deoptimize() } // , o // - A, B C. , // Monomorphic references have one very useful property that polymorphic properties do not have: before the next side effect operation, there is a guarantee that the shape of the object remains unchanged. Polymorphic treatment provides only a weak guarantee “an object has one of several forms”, with which little can be optimized (at best, one could remove the last comparison and the block with deoptimization, but V8 does not do that).
On the other hand, V8 can form an effective intermediate representation if the field is located at the same offset in all forms. In this case, the polymorphic form check will be used:
// , A, B C - $TypeGuard(o, [A, B, C]) // , var o_x = $LoadByOffset(o, offset_x) If there are no side effects between two polymorphic checks, the second one can also be removed as unnecessary, as in the case of monomorphic ones.
When the inline cache transfers to the compiler information about the possible forms of the object, the compiler can calculate what to do for each of them branching in the graph is impractical. In this case, a slightly different graph will be generated, where at the end there will be not a de-optimization, but a generalized operation:
var o_x if ($GetShape(o) === A) { o_x = $LoadByOffset(o, offset_A_x) } else if ($GetShape(o) === B) { o_x = $LoadByOffset(o, offset_B_x) } else if ($GetShape(o) === C) { o_x = $LoadByOffset(o, offset_C_x) } else { // , ox . // // : o_x = $LoadPropertyGeneric(o, 'x') // ^^^^^^^^^^^^^^^^^^^^ } // "" // , // In some cases, the compiler may even abandon the idea of specifying operations:
- There is no way to effectively specify it.
- The operation is polymorphic and the compiler does not know how to build a decision tree (this used to happen with a polymorphic call to
arr[i], but it has already been fixed) - There is no information about the type by which the operation can be specified (the code was never executed, the garbage collector deleted the collected information about the forms, etc.)
In these (rather rare) cases, the compiler produces a generic version of the intermediate representation.
Performance impact
As a result, we have the following:
- Monomorphic operations are optimized most easily and give the optimizer room for action. As the Hulk would say - " ONE TYPE CLOSE TO IRON! "
- Operations with a low level of polymorphism, requiring a form check, or a decision tree, are slower than monomorphic:
- Decision trees complicate the flow of execution. It is harder for the compiler to distribute type information and remove unnecessary instructions. Conditional tree transitions can also spoil performance if they fall into a loaded cycle.
- Polymorphic forms checks do not impede optimization so much and still allow you to delete some unnecessary instructions, but still slower than monomorphic ones. The impact on performance depends on how well your processor works with conditional transitions.
- Megamorphic or highly polymorphic operations are not concretized at all, and in the intermediate representation there will be a challenge, with all the ensuing consequences for the optimization and performance of the CPU.
Translator's note: the author gave a link to the microbenchmark, but the site itself no longer works.
Undiscised
I deliberately did not go into some details of the implementation so that the article would not become too extensive.
Forms
We did not discuss how forms (or hidden classes) are structured, how they are calculated and assigned to objects. A general idea can be obtained from my previous article or speech on AWP2014 .
One need only remember that the very concept of “form” in JS virtual machines is a heuristic approximation. Even if, from the point of view of a person, the two objects have the same shape, from the point of view of the machine it may be different:
function A() { this.x = 1 } function B() { this.x = 1 } var a = new A, b = new B, c = { x: 1 }, d = { x: 1, y: 1 } delete dy // a, b, c, d - V8 Since the objects in JS are carelessly implemented as dictionaries, you can apply polymorphism by accident:
function A() { this.x = 1; } var a = new A(), b = new A(); // if (something) { ay = 2; // a b } Intentional polymorphism
, (Java, C#, Dart, C++ ..), . , — . .
, JVM -
invokeinterface invokevirtual .It should be borne in mind that some caches are not based on the forms of objects, and / or have a smaller capacity compared to others. For example, a function call inline cache can have only three states: uninitialized, monomorphic, or megamorphic. It does not have an intermediate polymorphic state, because the form of the object does not matter for the function call, and the function object is cached.
function inv(cb) { return cb(0) } function F(v) { return v } function G(v) { return v + 1 } inv(F) // - , F inv(G) // - If the function is
invoptimized and the inline cache is in a monomorphic state, the optimizer can embed the function body in the call site (which is especially important for short functions in frequently called places). If the cache is in the megamorphic state, the optimizer does not know which function body can be embedded, and therefore leaves the generalized call operator in the intermediate representation.On the other hand, calls to methods like
om(...)works similarly to accessing a property. Inline cache method calls can also have an intermediate polymorphic state. The V8 virtual machine can embed a call to such a function in a monomorphic, polymorphic, or even megamorphic form in the same way as with the property: first, a type check or a decision tree, after which the function body itself is located. There is only one limitation: the method must be in the form of an object.In fact, it
om(...)uses two inline caches at once - one to load the property, the other to directly call the function. The second has only two states, as in the example above for the function cb. Therefore, its state is ignored when optimizing a call, and only the inline cache of the property call is used. function inv(o) { return o.cb(0) } var f = { cb: function F(v) { return v }, }; var g = { cb: function G(v) { return v + 1 }, }; inv(f) inv(f) // - , // f inv(g) // , // f g It may seem surprising that in the example above
fthey ghave a different shape. This happens because when we assign a function to an object's property, V8 tries (if possible) to bind it to the form of the object, and not to the object itself. In the example above it fhas a form {c: F}, then the form itself refers to a closure. In all the examples before this form, there was only a sign of the presence of a certain property — in this case, its value is also kept, and the form becomes similar to a class from languages like Java or C ++.Of course, if you later overwrite a property with another function, V8 will consider that it no longer resembles the relationship between class and method, so the form changes:
var f = { cb: function F(v) { return v }, }; // f {cb: F} f.cb = function H(v) { return v - 1 } // f {cb: *} About how V8 builds and maintains the form of objects, it would be worth writing a separate large article.
, -
ox — , , Dictionary<Shape, int> . : , . , - , .,
o = {x: 1} , : // , o = { x: 1 } var o = { get x () { return $LoadByOffset(this, offset_of_x) }, set x (value) { $StoreByOffset(this, offset_of_x, value) } // / // JS- }; $StoreByOffset(o, offset_of_x, 1) By the way, something like this is implemented in Dart VM properties.
If you look at it this way, then the inline cache should be more likely represented as
Dictionary<Shape, Function>comparing forms with accessor functions. Unlike the naive representation with an offset, both properties from a chain of prototypes, and getters-setters, and even proxy objects from ES6 can be described.Pre-monomorphic state
Some inline caches in V8 have another state called pre-monomorphic . It serves to avoid compiling code for caches that were accessed only once. I did not mention this state, because it is a little-known feature of the implementation.
Final Performance Council
The best performance advice can be taken from the title of Dale Carnegie’s book “How to stop worrying and start living.”
Indeed, worrying about polymorphism is usually meaningless. Instead, run your code with normal data, look for bottlenecks with a profiler - and if they are related to JS, then you should look at the intermediate representation that the compiler produces.
And only then, if in the middle of your loaded cycle you see a statement called
XYZGenericor something will be marked with an attribute changes [*](that is, “changes everything”), then (and only then) you can begin to worry.
Source: https://habr.com/ru/post/303542/
All Articles