ComputerVision (Ruby & OpenCV)

Author: Lyudmila Dezhkina, Senior Full Stack developer
OpenCV is a well-known open source computer vision library. I’ll tell you what you can do with OpenCV, how the library works, how to use it in Ruby. I managed to participate in two projects where it was applied. In both cases, we didn’t use Ruby in the final version, but Ruby is very convenient at the first stage when you need to create a prototype of a future system just to see how OpenCV will perform the required tasks. If everything is in order, then the application is written with the same algorithm in another language. And to use OpenCV on Ruby, there is a corresponding gem.
The main parts of the library are image interpretation and machine learning algorithms. The list of features provided by OpenCV is extensive:
')
- image interpretation;
- camera calibration by reference;
- elimination of optical distortion;
- the definition of similarity;
- analysis of the movement of the object;
- determining the shape of the object and tracking the object;
- 3D reconstruction;
- object segmentation;
- gesture recognition.
Now OpenCV is used in many areas. Here are some interesting examples:
- Google:
- Google self-driving car - in unmanned vehicles Google OpenCV is used to develop a prototype of the recognition of the environment;
(Today, the constructed system is based primarily on LIDAR - due to the difficulties of recognition in poor lighting) - Google Glass - in these glasses 3D-reconstruction of the image is built on OpenCV;
- Google Mobile;
- Google self-driving car - in unmanned vehicles Google OpenCV is used to develop a prototype of the recognition of the environment;
- Robotics and Arduino;
- Industrial production - sometimes a factory makes a part counting system or something like that on OpenCV.
Is it difficult or interesting?
Although it is sometimes difficult to say which data can be considered really “big”, in the case of OpenCV there are no such doubts: for example, self-driving car can handle about 1 Gb / s by approximate calculations, and this is really big data. For comparison, the human brain processes ~ 45 MB - 3Gb / s - it depends, in particular, on the illumination of the room.
As for the numerous OpenCV algorithms, among them are both complex and simple. There are, in particular, algorithms for filtering, tensors (in fact, one-dimensional arrays).
Also, OpenCV uses machine learning and deep learning technologies, since the recognition is partially based on neural networks. Deep learning and machine learning is a very interesting topic, which I recommend to study in courses on Coursera. Regarding the topic of computer vision in general, I recommend this book:

What does OpenCV consist of?
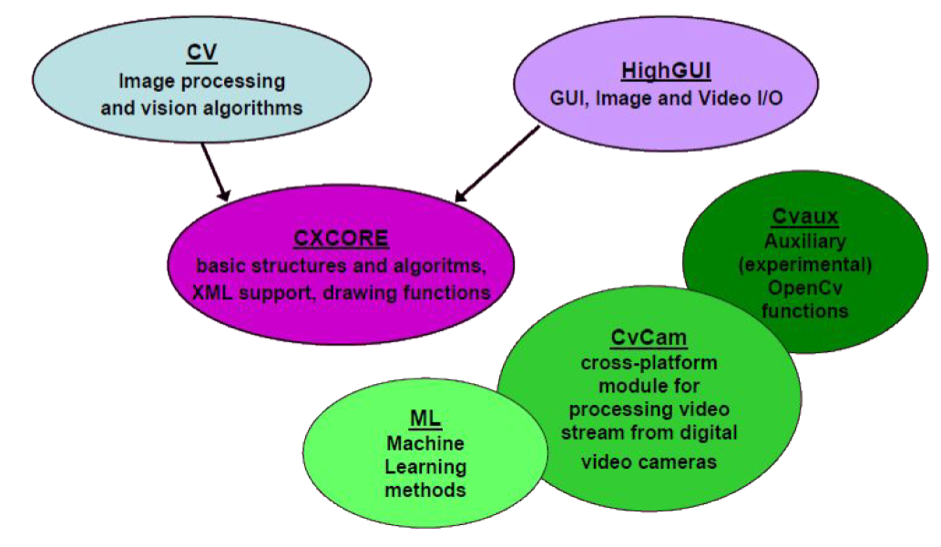
CXCORE (the core itself), oddly enough, is elementary in terms of programming. It contains the basic data structures and algorithms:
- basic operations on multidimensional numeric arrays — they allow, for example, to multiply a matrix by a vector, to multiply two matrices, and so on;
- matrix algebra, mathematical functions, random number generators - to work with it, it is enough to know the name of the desired function, and that’s all;
- writing / restoring data structures to / from XML;
- basic functions of 2D graphics - with their help you can, for example, draw a snake.
CV is a module for image processing and computer vision. It includes:
- basic operations on images (filtering, geometric transformations, transformation of color spaces, etc.);
- image analysis (selection of distinctive features, morphology, contour search, histograms);
- motion analysis, tracking objects;
- detection of objects, in particular persons;
- camera calibration and elements of spatial structure recovery.
Geometric transformations, by the way, are a very important part of the library: when you are trying to build something, you often need to take into account the rotation and angle of the camera.
HighGUI - a module for input / output of images and video, creating a user interface. The module performs the following functions:
- Capturing video from cameras and video files, reading / writing static images;
- functions for organizing a simple UI (all demo applications use HighGUI).
ML - built-in machine learning algorithms, working out of the box, although in the 3rd version they are gradually abandoned, because other companies are developing good machine learning algorithms (they will be discussed later).
CvCam - everything you can do with video (camera capture, detection, slicing, etc.)
Cvaux are experimental and outdated features:
- spatial vision: stereocalibration, self-calibration;
- search stereo, clicks in the graphs;
- finding and describing facial features.
Examples of patents or startups
A good example of one of the latest successful startups using OpenCV is the virtual fitting room from Zugara , which provides a really high conversion rate. How does she work? The algorithm is approximately as follows: it photographs the user and counts the distance to his face. Then the user enters several of their sizes, and the fitting room calculates something from the clothes the customer likes. There is, however, another significant part in this system - the AutoCAD-model: every thing before you try it on, undergoes a 3D reconstruction.
The second good example of using OpenCV is the license plate recognition system on the roads. The accuracy of such a system, however, is up to 90%, since much depends on the quality of the shooting, on the speed of the car, on how dirty the number is, etc.
Neural networks (learning mechanisms)
The second important part of OpenCV (after the one that is responsible for image processing) is machine learning. In addition to the built-in OpenCV, now there are several mechanisms for machine learning:
- Google's TensorFlow , built entirely on tensors;
- Theano , PyLearn 2 && EcoSystem is one of the largest developments, very difficult to use;
- Torch - already outdated mechanism;
- Caffe is the best system for beginners to use. By the way, it is not necessary to use it for recognition - you can apply it, for example, in the financial sphere. So, Caffe is often used to prototype banking manipulations. There are also biological systems built on it.
The difficulties of building a system
When we build a similar system (even the same virtual fitting room or number recognition system), we have to deal with at least two dilemmas:
- soft or hardware
- algorithm or neural network.
The dilemma of software and hardware is that, the worse the iron, the better the software needs to be developed in order to get a sensible result. The second dilemma is the following - what is better to use in the program part: any algorithm or a neural network? In fact, sometimes the neural network loses the algorithm. I choose between the algorithm and the neural network as follows: if the neural network takes up more space than the algorithm, I choose an algorithm. The algorithm is generally more reliable, and in simple cases I would choose it. And sometimes a neural network cannot solve even a very simple task: for example, Rosenblatt’s perceptron cannot understand whether the point is above or below the line.
Character Recognition
Let's talk a little about character recognition, which may be necessary, for example, when creating a license plate recognition system.
Tesseract OCR is open source software that automatically recognizes both a single letter and text immediately. Tesseract is convenient because it is for any operating system, it works stably and is easily trained. However, it has a significant drawback: it works very poorly with zamylennym, beaten, dirty and deformed text. Therefore, Tesseract is hardly suitable for recognizing numbers, but it will very well cope with the recognition of plain text. So h. Tesseract can be perfectly applied, for example, in document flow.
K-nearest is a very easy to understand character recognition algorithm, which, despite its primitiveness, can often defeat not the most successful implementations of SVM or neural network methods.
It works as follows:
- pre-record a decent number of images of real characters that were previously manually divided into classes;
- enter the measure of the distance between the characters (if the image is binarized, the XOR operation will be optimal);
- then, when we try to recognize a character, we alternately calculate the distance between it and all the characters in the database. Among the closest neighbors may be representatives of various classes. Representatives of which class is more among neighbors, a recognizable symbol should be attributed to that class.
OpenCV data types
It's simple.
CvPoint - point (structure of two variables (x, y))CvSize - size (structure of two variables (width, height))CvRect - rectangle (structure of 4 variables (x, y, width, height))CvScalar - scalar (4 doubles)CvArr - an array - it can be considered an “abstract base class” for CvMat and then IplImage (CvArr -> CvMat -> IplImage)CvMat - matrixIplImage - imageThat's all the data types that are in OpenCV.
Loading pictures
This is what you can do in Ruby. After you connect the library, you can upload a picture. It is important that if you want to see it, you need to remember to bring it out the window.
cvLoadImage( filename, int iscolor=CV_LOAD_IMAGE_COLOR )
//The parameters are the file name and image quality:
filename- file nameiscolor- defines how to present a pictureiscolor > 0-
iscolor == 0 - the image will be uploaded in GRAYSCALE format (grayscale)iscolor < 0 picture will be loaded as iscvNamedWindow("original",CV_WINDOW_AUTOSIZE);
//
cvShowImage("original",image);Information Available After Download
There are about 25 methods here, but I only use these:
image->nChannels // (RGB, OpenCV — BGR ) (1-4);image->depth // ( , );image->width // ;image->height // ;image->imageSize // , (==image->height*image->widthStep);image->widthStep // ( ) — .
Viola-Jones Method
This method of facial recognition, invented in 2005, is based on signs of Haar. It is used in almost all cameras to identify individuals. Here is how it works.
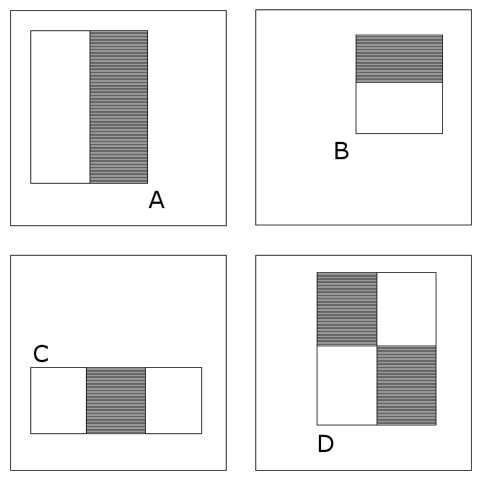
The value of each feature is calculated as the sum of pixels in white rectangles, from which the sum of pixels in black areas is subtracted. Rectangular signs are more primitive than steerable filter,
and, despite the fact that they are sensitive to the vertical and horizontal features of images, the result of their search is more rude.
And if to speak in human language, the face is taken and divided into two parts. The area near the nose and under the eyes will be darker, the cheeks lighter, and so on. Imagine that each pixel of the image is a single vector value: with this, the number of gray and white pixels is calculated. Based on this, it is concluded that it looks like a person or not.
Neural networks
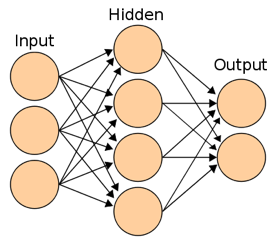
Neural networks are now divided into two types. The first type is the old two- and three-level networks. Such networks are trained by gradient methods with back propagation of errors. When working with them, you take a vector, direct the function, after which, for example, the perceptron layer goes. You have input (an image that has already been processed - for example, the necessary part of it is taken, and in the case of a number, it is cut into rectangles for each character of the number). After that each pixel - vector is displayed, and we count transitions. Actually, this is just a walk through the array. This technology is already outdated.
The newer networks of the second type are deep and convolutional, using the convolution operation. The convolution operation shows the similarity of one function with a reflected and shifted copy of another. All convolution in OpenCV occurs on a 2D filter:
cvFilter2D( src, dst, kernel, CvPoint anchor CV_DEFAULT(cvPoint(-1,-1)))Canny Boundary Detector
If we want to process images of faces or numbers, we need to calculate the boundaries of these images. This is a very difficult task to be solved in OpenCV using a very old built-in algorithm - Canny 1986.
Edges (borders) - such curves in the image, along which there is a sharp change in brightness or other types of inhomogeneities. Simply put, the edge is a sharp transition or change in brightness.
Causes of edges:
- change in light;
- color change;
- change the depth of the scene (the orientation of the surface).
To use the algorithm, you need to specify where to look for the image and the erosion threshold - this is necessary, for example, to be able to find the car on a dark road.
cvCanny( image, edges, threshold1,
threshold2, CV_DEFAULT(3) );image - single-channel image for processing (grayscale);edges - single-channel image to store the borders found by the function;threshold1 - minimum threshold;threshold2 - maximum threshold;aperture_size - size for the Sobel operator.Here's how the Canny algorithm works step by step:
- Removes noise and unnecessary details from the image.
- Calculates image gradient.
- makes the edges thin (edge thinning).
- links edge to contours (edge linking).
To those who have read this far (and I would like to believe that there are more than half of these), I want to say that the article is nothing more than an introductory character, I just wanted to share my conclusions. Since I have no technical computer education, there may be inaccuracies - I will be glad to any amendments and comments.
And I hope that the topic is relevant in connection with the advent of the era of robotics.
Source: https://habr.com/ru/post/303482/
All Articles