Az.js: JavaScript-library for word processing in Russian
How wonderful and deep Russian Kurlyk
- Post generator
Natural language processing (NLP) is a very interesting topic, in my opinion. First, the tasks here are purely algorithmic: we take an absolutely primitive object as input, a line, and try to extract the meaning embedded in it (or at least a part of the meaning). Secondly, it is not necessary to be a professional linguist to solve these problems: it is enough to know the native language at a more or less decent level and to love it.
And with little cost, you can make some stupid chat bot - or, like here I am, the generator of posts based on what you wrote on your page on the social network. Perhaps some of you have already seen this application - it is rather stupid, most often gives a meaningless and incoherent text, but occasionally still gives reason to smile.
The incoherence of texts in the current version of “Generator” is due to the fact that it is in fact not able to produce any analysis. It is just that in some cases it "predicts" the continuation of the sentence on the collected digrams, and in others it replaces some words in the finished sentence with others that end similarly. That's the whole stuffing.
')
Of course, I want to do something more interesting. The trouble is that the fashionable neural networks are not very applicable here: they need a lot of resources, a large training sample, and in the browser the user’s social network does not have this. Therefore, I decided to study the issue of working with texts using algorithms. Unfortunately, it was not possible to find ready-made tools for working with the Russian language in JavaScript, and I decided to make my own small bicycle.

Az
I called my library Az . On the one hand, this is the first letter of the Cyrillic alphabet, “az”, and at the same time, the first and last letters of the Latin alphabet. Immediately give all the links:
- GitHub ;
- Documentation: either on the same githab , or on Doclets.io ;
- Demo .
You can install the library from both npm and bower (in both places it is called az ). At your own risk - it is not yet fully covered by tests and before the release of the first version (which will happen soon, I hope), its public APIs may change. License: MIT.
At the moment, the library can do two things: tokenization and analysis of morphology. In some distant future (but not in the first version) it is supposed to implement parsing and extracting meanings from sentences.
Az.Tokens
The essence of tokenization is very simple: as I mentioned above, we accept a string at the input - and at the output we get "tokens", groups of characters, which (probably) are separate entities in this line.
Usually, for this purpose, something like the single split call is used on a simple regular schedule, but this seemed to me a little. For example, if you divide a line by spaces, we lose the spaces themselves - sometimes it is convenient, but not always. Even worse, if we want to pre-break a line into points, interrogatives and exclamation marks (hoping to highlight sentences like this): not only do specific punctuation marks get lost, so dots actually do not always complete the sentences. And then we understand that in real texts there may be, say, links (and the points in them have absolutely no relation to punctuation) and the regular schedule becomes absolutely terrible.
Az offers its own, non-destructive, solution to this problem. It is guaranteed that after tokenization each character will belong to some token and only one. Spaces, line breaks and other invisible characters are combined into one type of token, words into another, punctuation into the third. If all the tokens are glued together - the result is exactly the original string.
At the same time, the tokenizer is smart enough to understand that the hyphen, framed by spaces, is a punctuation mark (probably, a dash was implied in its place), and pressed on at least one side of the word is part of the word itself. Or that “habrahabr.ru” is a link, and “mail@example.com” is probably an email (yes, the full support of the relevant RFC is not guaranteed). #hashtag is a hashtag, user is a mention.
And finally - since RegExp's should not be used for this purpose - Az.Tokens can parse HTML (and wiki and Markdown at the same time). More precisely, there will be no output tree structure, but all tags will be allocated to their tokens. For the <script> and <style> tags an additional exception was made: their contents will turn into one big token (you were not going to break your scripts into words?).
Here is an example of handling Markdown markup:

Note that brackets in some cases turn into punctuation (light blue rectangles), and in others - into Markdown markup (shown in green).
Naturally, filtering unnecessary tokens (for example, discard tags and spaces) is elementary. And of course, all these strange features are turned off by separate flags in the tokenizer options.
Az.Morph
After the text is broken into words (using Az.Tokens or in any other way), one can try to extract morphological attributes from them - grammes . A grammeme can be part of speech , gender or case - such grammes have meanings that are grammemes themselves, only “boolean” (for example, masculine gender , the instrumental case ). “Boolean” grammes may not refer to some parent gramme, but be present by themselves, like flags — say, litter obsolete or reflexive (verb).
A complete list of grammes can be found on the OpenCorpora project page . Almost all values used by the library correspond to the designations of this project. In addition, the analysis uses the OpenCorpora dictionary, packaged in a special format, but more on that below. In general, the creators of the OpenCorpora project are great fellows and I recommend that you not only familiarize yourself with it, but also take part in the collaborative layout of the case - this will also help other open source projects.
Each specific set of grammes in a word is called a tag . There are far fewer tags than words - so they are numbered and stored in a separate file. To be able to incline words (and Az.Morph is also able to), you need to somehow be able to change their tags. For this, there are word paradigms : they associate tags with certain prefixes and suffixes (that is, the same tag in different paradigms has different pairs of prefix + suffix). Knowing the word paradigm, it is enough to “bite off” the prefix and suffix corresponding to the current tag, and add the prefix / suffix of the tag into which we want to translate it. Like tags, there are relatively few paradigms in Russian - this allows you to store only a couple of indices for each word: the number of the paradigm and the number of the tag in it.
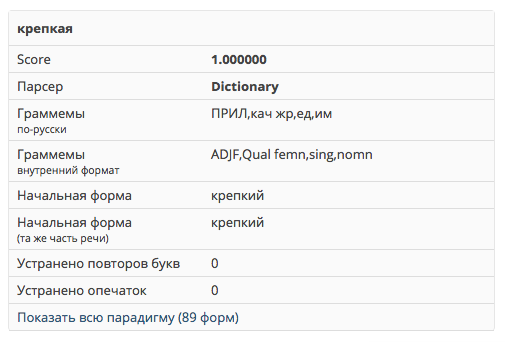
Here is an example: the word “ strong ” has a tag, in Russian briefly designated as “ ADJ, quality, units, them ” - that is, it is a qualitative adjective of the feminine singular in the nominative case . This tag (in the paradigm to which the word "strong" belongs), corresponds to an empty prefix and the suffix " -kaya ". Suppose we want to obtain from this word its comparative degree, and even not the usual one, but a special one, with the prefix “on”: “ COMP, qual srav2 ”. She has in this paradigm, as you might guess, the prefix “on” and the suffix “ -che ”. We cut off “-kay”, add “on” and “ -che ” - we get the desired form “stronger”.
Nb . As you can see, the prefixes and suffixes here are not linguistic terms, but simply substrings located at the beginning / end of words.
Such is the relatively confused description of the internal mechanism of declensions in Az.Morph. In fact, this part of the library is the port of the remarkable morphological analyzer pymorphy2 by kmike (Habré had a couple of articles about this library). In addition to the analyzer itself, I recommend reading its documentation - there is a lot of useful information that is fully applicable to Az, too. In addition, Az uses a dictionary format similar to the pymorphy2 dictionaries, with the exception of small details (which allowed the dictionary to be 25% smaller). For this reason, alas, it will not be possible to assemble them yourself - but in the future such an opportunity will, of course, appear.
As I have already mentioned, the main dictionaries are stored in a tricky DAWG format (the wiki has an article about a directed acyclic word graph , like an abstract data structure, but there is little information about the concrete implementation). Realizing his support in JS, I appreciated the pymorphy2 feature that allows you to immediately check the option with “” instead of “e” when searching for a word - this does not cause any special performance losses due to the fact that when descending the prefix tree, it is easy to bypass the branches corresponding to both letters. But this seemed to me a little, and I similarly added the possibility of a fuzzy search for words with misspellings (that is, you can set the maximum Damerau-Levenshtein distance , which should contain the search word from the given one). In addition, you can find the "stretched" words - at the request of "goool" or "go-o-o-ol" there will be a dictionary "goal". Of course, these features are also optional: if you work in “greenhouse conditions”, with literate, read texts, the search for typos should be prohibited. But for user-written records, this can be very relevant. The plans - at the same time catch and the most common errors that are not typos.
As you can see, for a given word, the library can return different parsing options from the dictionary. And this is due not only to typing errors: a classic example of grammatical homonymy is the word “ steel ”, which can be a form of both the noun “ steel ” and the verb “ become ”. To decide unequivocally (remove homonymy) - you need to look at the context, the neighboring words. Az.Morph is not able to do this yet (and this task is no longer for the morphological module), therefore it will return both options.
Moreover: even if the dictionary did not find anything suitable, the library will apply heuristics (called predictors or parsers ), which can suggest how the word leans - for example, at its end. There would be to insert a funny story about the analyzer, which considers the word “bed” as a verb, but one problem - it, of course, is in the dictionary, and only as a noun :)
However, I had my own oddities. For example, the word “ philosophical ”, among other options, had some “ philosophers ” (with a corrected typo). But most surprisingly, it turned out that the word " memes " is consistently understood as a verb (!), The infinitive of which is " memasti " (!!!). It is not immediately possible to understand how this is possible at all - but, for example, the word “graze” has the same paradigm. Well, the forms such as “memesem”, “memesemte”, “memereny”, “memeseno”, “memesshi”, in my opinion, are beautiful.
Despite these oddities, usually the results are quite adequate. This is facilitated by the fact that (as in pymorphy2) each option is assigned a rating of "credibility" and they are sorted in descending order of this assessment. So if you do the algorithm quickly - you can take the first option of the analysis, and if you want accuracy - it is worth going through everything.
Performance
As for speed, in general, everything is not very rosy here. Liba was written without emphasis on this factor. It is assumed that JS applications (especially browser-based) rarely have to deal with especially large amounts of data. If you want to quickly analyze massive collections of documents - you should pay attention to pymorphy2 (especially its optimized version that uses the C implementation to work with the dictionary).
According to my rough measurements, the specific numbers (in the Chrome browser) are approximately as follows:
- Tokenization: 0.7–1.0 million characters per second
- Morphology without typos: 210 words per second
- Mistaken Morphology: 180 words per second
However, serious benchmarks have not yet been conducted. In addition, the library lacks tests - so I invite you to drive it on the above-mentioned demo . I hope your help will bring the release of the first version :)
Future plans
The main point in the roadmap library is the parsing experiment. Having options for analyzing each word in a sentence, you can build more complex hypotheses about their relationships. As far as I know, there are very few such tools in the open source. The more difficult and interesting it will be to think about this task.
In addition, the issue of optimization is not removed - JS can hardly keep up with the C code, but you can certainly improve something.
Other plans mentioned in the article: a tool for self-assembling dictionaries, searching for words with errors (i.e., say, for words on "m (s)" returned the option with a soft sign and without, and the syntactical analyzer chose would be correct).
And, of course, I am open to your ideas, suggestions, bug reports, forks and pullrequests.
Source: https://habr.com/ru/post/303308/
All Articles